






目录
第一步正向化:将原始矩阵正向化处理(将所有的指标类型统一转换为极大型指标)
TOPSIS算法原理
1.模型介绍
C.L.Hwang 和 K.Yoon 于1981年首次提 TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution),可翻译为逼近理想解排序法,国内常简称为优劣解距离法。
TOPSIS 法是一种常用的综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。
基本过程为先将原始数据矩阵统一指标类型(一般正向化处理)得到正向化的矩阵,再对正向化的矩阵进行标准化处理以消除各指标量纲的影响,并找到有限方案中的最优方案和最劣方案,然后分别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。该方法对数据分布及样本含量没有严格限制,数据计算简单易行
1.2.TOPSIS法的适用条件
(1) 比较的对象一般要远大于两个
(2)比较的指标不只一个方面
(3)有很多指标不存在理论上的最大值和最小值,例如GDP增长值
特别的:TOPSIS法 特别适合具有多组评价对象时,要求通过检测评价对象与最优解、最劣解的距离来进行排序
2.算法步骤
第一步正向化:将原始矩阵正向化处理(将所有的指标类型统一转换为极大型指标)
最常见的有四个指标:
| 指标名称 | 指标特点 | 例子 |
| 极大型(效益型)指标 | 越大(多)越好 | 成绩、GDP增速、企业利润 |
| 极小型(成本型)指标 | 越小(少)越好 | 费用、坏品率、污染程度 |
| 中间型指标 | 越接近某个值越好 | 水质量评估时的PH值 |
| 区间型指标 | 落在某个区间最好 | 体温、水中植物性营养物量 |
极小型转化为极大型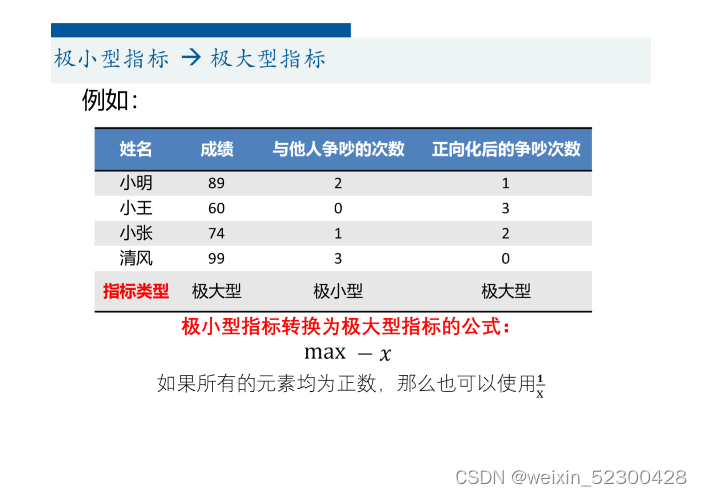
这个例子中,与他人争吵的次数为极小型指标,怎么转化为极大型的呢,首先找到该指标中的最大值,也就是3,然后拿最大值减去指标中的每一个值(3-2,3-0...),这样我们就得到了极大型指标
中间型转化为极大型

首先我们求M,M等于指标中的每一个值减去最佳值(7)的绝对值的最大值,然后代入上方正向化公式即可
区间型转化为极大型

同理我们先求M,首先我们找到指标中的最小值(35.2),同理最大值(38.4),上面的例子a为下界(36),上界b(37),然后代入求M的公式求得M,然后对指标中的每个数进行区间判断,代入正向化的分段公式中。经过以上处理我们得到正向化矩阵,接下来我们进行标准处理,来消除不同量纲的影响
第二步标准化
第三步计算得分
我们先举个例子
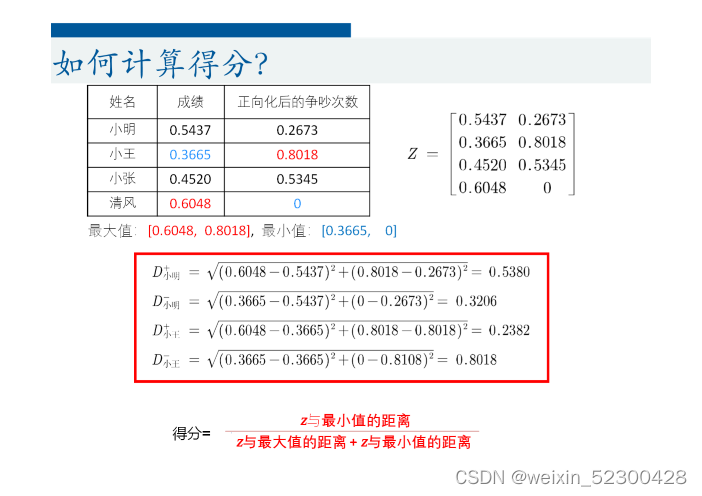
首先我们找到每个指标的最大值(0.6048,0.8018),最小值(0.3665,0),然后求评价对象与每个指标最大值的距离,以及最小值的距离。得分等于最小值距离除以最大值距离加最小值距离。
具体公式如下图

代码实现
这里以20条河流的水质情况数据为例
题目:评价下表中20条河流的水质情况。
注:含氧量越高越好(极大型);PH值越接近7越好(中间型);细菌总数越少越好(极小型);植物性营养物量介于10‐20之间最佳(区间型),超过20或低于10均不好
| 河流 | 含氧量(ppm) | PH值 | 细菌总数(个/mL) | 植物性营养物量(ppm) |
| A | 4.69 | 6.59 | 51 | 11.94 |
| B | 2.03 | 7.86 | 19 | 6.46 |
| C | 9.11 | 6.31 | 46 | 8.91 |
| D | 8.61 | 7.05 | 46 | 26.43 |
| E | 7.13 | 6.5 | 50 | 23.57 |
| F | 2.39 | 6.77 | 38 | 24.62 |
| G | 7.69 | 6.79 | 38 | 6.01 |
| H | 9.3 | 6.81 | 27 | 31.57 |
| I | 5.45 | 7.62 | 5 | 18.46 |
| J | 6.19 | 7.27 | 17 | 7.51 |
| K | 7.93 | 7.53 | 9 | 6.52 |
| L | 4.4 | 7.28 | 17 | 25.3 |
| M | 7.46 | 8.24 | 23 | 14.42 |
| N | 2.01 | 5.55 | 47 | 26.31 |
| O | 2.04 | 6.4 | 23 | 17.91 |
| P | 7.73 | 6.14 | 52 | 15.72 |
| Q | 6.35 | 7.58 | 25 | 29.46 |
| R | 8.29 | 8.41 | 39 | 12.02 |
| S | 3.54 | 7.27 | 54 | 3.16 |
| T | 7.44 | 6.26 | 8 | 28.41 |
这里以python实现代码(使用工具Jupyter Notebook):
#导入分析库
import pandas as pd
import numpy as np
##导入数据
df = pd.read_excel(r'./20条河流的水质情况数据.xlsx')
df.head(5) #查看头5条数据
#极小型指标 -> 极大型指标
def Mintomax(datas):
return np.max(datas) - datas
df['细菌总数(个/mL)'] = Mintomax(df['细菌总数(个/mL)']) #极小型指标 -> 极大型指标
df.head() #查看#中间型指标 -> 极大型指标
def Midtomax(datas,x_best):
temp_datas = datas - x_best
M = np.max(abs(temp_datas))
answer_datas = 1 - abs(datas - x_best) / M
return answer_datas
df['PH值'] = Midtomax(df['PH值'],7) #中间型指标 -> 极大型指标 7为最佳值#区间型指标 -> 极大型指标
def Intertomax(datas,x_min,x_max):
M = max(x_min - np.min(datas) , np.max(datas) - x_max)
answer_list = []
for i in datas:
if(i < x_min):
answer_list.append(1 - (x_min - i) / M)
elif (i > x_max):
answer_list.append(1 - (i - x_max) / M)
else:
answer_list.append(1)
return np.array(answer_list)
df['植物性营养物量(ppm)'] = Intertomax(df['植物性营养物量(ppm)'],10,20) #区间型指标 -> 极大型指标 10为下界,20为上界#正向化矩阵标准化(去除量纲影响)
def Standard(datas):
k = np.power(np.sum(pow(datas,2) , axis = 0) , 0.5)
for i in range(len(k)):
datas[:,i] = datas[:,i] / k[i]
return datas
label_need = df.keys()[1:]
data = df[label_need].values #刨除变量名后的数据值
sta_data = Standard(data) #正向化矩阵标准化(去除量纲影响)#计算得分并归一化
def Score(sta_data):
z_max = np.amax(sta_data,axis=0)
z_min = np.amin(sta_data,axis=0)
#计算每一个样本点与最大值的距离
tmpmaxdist = np.power(np.sum(np.power((z_max - sta_data) , 2) , axis = 1) , 0.5)
tmpmindist = np.power(np.sum(np.power((z_min - sta_data) , 2) , axis = 1) , 0.5)
score = tmpmindist / (tmpmindist + tmpmaxdist)
score = score / np.sum(score) # 归一化处理
return score
sco = Score(sta_data) #计算得分
#将计算得到的得分与源数据一起进行整理,形成dataframe
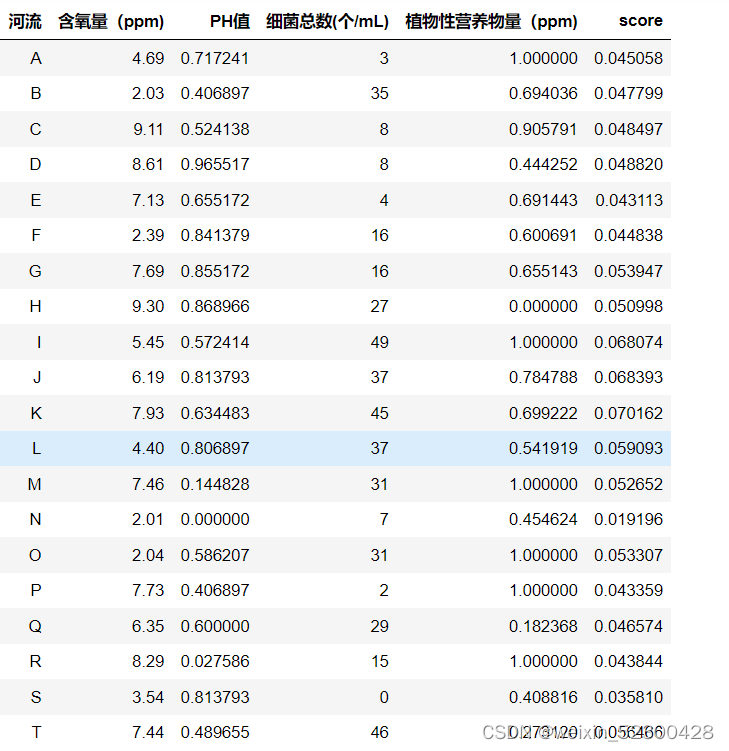
df['score'] = sco处理后的结果如下:
模型优化

前面的步骤相同,计算评价对象与最大值,最小值距离时加上每个指标的权重即可。
模型的优缺点
Topsis法 的优点:
(1) 避免了数据的主观性,不需要目标函数,不用通过检验,而且能够很好的刻画多个影响指标的综合影响力度。
(2) 对于数据分布及样本量、指标多少无严格限制,既适于小样本资料,也适于多评价单元、多指标的大系统,较为灵活、方便。
Topsis法 的缺点:
(1) 需要的每个指标的数据,对应的量化指标选取会有一定难度。
(2) 不确定指标的选取个数为多少适宜,才能够去很好刻画指标的影响力度。
(3) 必须有两个以上的研究对象才可以进行使用。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









