







5-1-KNN聚类的原理和实现
KNN(K- Nearest Neighbor)——K最邻近法
如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别
算法原理
K近邻算法:给定一个训练数据集,对新的的输入实例,在训练数据集中找到与该实例最邻近的的K个实例,这K个实例的多数属于某个类,就把该实例分为这个类。
K近邻算法的三个基本要素:
- K值选择
- 距离度量
- 分类决策
K值选择案例

图中有两个类型的样本,蓝色的正方形和红色的三角形。绿色圆形是待分类数据。
如果K=3,离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
因此K值的选择对分类的结果有很大的影响。
常用的距离量算方法
1. 欧式距离(Euclidean Distance)
欧式距离是我们在直角坐标系中最常用的距离量算方法,例如小时候学的“两点之间的最短距离是连接两点的直线距离。”这就是典型的欧式距离量算方法。
通常这这个距离的获取是基于我们熟悉的“勾股定理”,解算三角形斜边得到的。


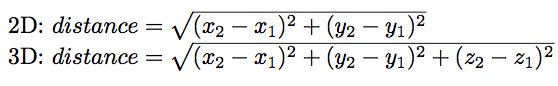
2. 曼哈顿距离(Manhattan Distance)
曼哈顿距离是与欧式距离不同的一种丈量方法,两点之间的距离不再是直线距离,而是投影到坐标轴的长度之和。
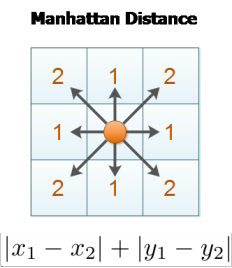

图中绿色的线为欧式距离的丈量长度,红色的线即为曼哈顿距离长度,蓝色和黄色的线是这两点间曼哈顿距离的等价长度。
想想我们下象棋的时候,车炮兵之类的,是不是要走曼哈顿距离?

在道路上会像这样是很多的规则的网格状,从A到B通常无法去沿直线行走,而是会避开建筑物,走几个街区到达。
图中蓝色的线即为曼哈顿距离的典型应用场景。
3. 切比雪夫距离(Chebyshev distance)
数学上,切比雪夫距离是将2个点之间的距离定义为其各坐标数值差的最大值。
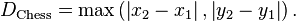
代码
import csv
import random
# 读取
# 'r'以文本读取方式打开文件
with open('Prostate_Cancer.csv', 'r') as file:
reader = csv.DictReader(file) # 以字典方式读取文件
dates = [row for row in reader]
# for row in reader:
# print(row)
# print(dates)
# 分组
# 测试集和训练集
random.shuffle(dates) # 打乱数据
n = len(dates) // 3 # // 整除
test_set = dates[0:n]
train_set = dates[n:]
# knn
# 欧几里得距离
def distance(d1, d2):
res = 0
for key in ("radius", "texture", "perimeter", "area", "smoothness", "compactness", "symmetry", "fractal_dimension"):
res = res + (float(d1[key]) - float(d2[key])) ** 2
return res ** 0.5
def knn(date):
# 1.距离
res = [
{"result": train['diagnosis_result'], "distance": distance(date, train)}
for train in train_set
]
# 2.排序
res = sorted(res, key=lambda item: item['distance'])
# 3.取前k个
res2 = res[0:K]
# 4.加权平均
result = {'B': 0, 'M': 0}
# 计算总距离
sum_ = 0
for r in res2:
sum_ += r['distance']
for r in res2:
result[r['result']] += 1 - r['distance'] / sum_
if result['B'] > result['M']:
return 'B'
else:
return 'M'
K = 5
# 测试
correct = 0
for test in test_set:
rl_result = test['diagnosis_result'] # 真实结果
pd_result = knn(test) # 预测结果
if rl_result == pd_result:
correct += 1
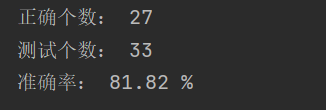
print("正确个数:", correct)
print("测试个数:", len(test_set))
print("准确率:", round(100 * correct / len(test_set), 2), "%")
# 保留两位小数
运行结果
数据集地址:
链接:https://pan.baidu.com/s/11alflmPFAzoeRvz6-1bH3Q
提取码:1234















 2257
2257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









