




DL-DRL: A double-level deep reinforcement learning approach for large-scale task scheduling of multi-UAV论文阅读。
为了降低大规模多无人机任务调度问题的计算复杂度,本文提出了一种基于分治框架(DCF)的方法,将原问题分解为任务分配子问题和无人机路径规划子问题。
分治框架通过将复杂问题分解为多个相对简单的子问题,在上层,设计了一个任务分配DRL模型,任务被分配给上层的不同无人机,为每个给定的任务选择合适的无人机。在下层,设计了一个路线规划DRL模型,为每架无人机构建路线,目标是在无人机的最大飞行距离下,最大限度地执行任务数量。两个模型相互交互,上层模型将分配的任务作为输入传递给下层模型,而上层模型的奖励则依赖于下层模型的输出。
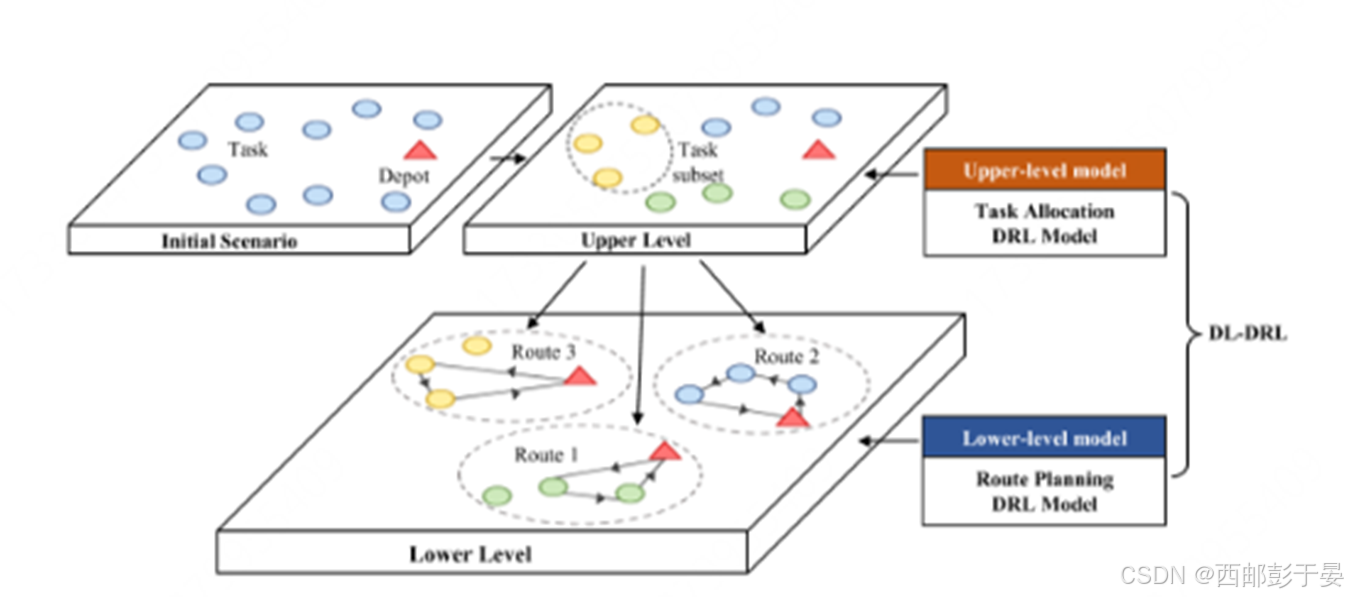
初始场景(Initial Scenario):
图片左上角展示了初始场景,包括多个任务(Task)和一个仓库(Depot)。任务以蓝色圆圈表示,仓库以红色三角形表示。
上层模型(Upper Level):
上层模型负责任务分配(Task Allocation),即决定哪些任务由哪些无人机执行。
该模型是一个深度强化学习(DRL)模型,用于将任务分配给不同的无人机。
在图片中,上层模型将任务分配给不同的无人机(黄色、绿色和蓝色圆圈),形成不同的任务子集(Task subset)。
下层模型(Lower Level):
下层模型负责路径规划(Route Planning),即规划每架无人机执行其分配任务的具体路径。
该模型也是一个深度强化学习(DRL)模型,用于构建每架无人机的飞行路线,以最大化执行任务的数量。
在图片中,下层模型为每架无人机规划了不同的路线(Route 1、Route 2 和 Route 3),每条路线连接了无人机需要执行的任务和仓库。
DL-DRL方法:
整个框架构成了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2141
2141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









