






存在共享投入的两阶段博弈交叉DEA模型
今天推出的是存在共享投入的两阶段博弈交叉DEA模型。
网络 DEA 博弈交叉效率模型不仅适用于基本两阶段网络结构,还适用于多种网络结构,本文进一步将模型拓展为存在共享投入的两阶段DEA 博弈交叉效率模型。 存在共享投入的两阶段网络结构中,假设有 n 个 DMU;在第一阶段, D M U j ( j = 1 , 2 , . . . , n ) DMU_j(j=1,2,...,n) DMUj(j=1,2,...,n)用 m 种共享比例分别为 α i j ( i = 1 , 2 , . . . , m ) \alpha_{ij}(i=1,2,...,m) αij(i=1,2,...,m)的外源投入 x i j ( i = 1 , 2 , . . . , m ) x_ij(i=1,2,...,m) xij(i=1,2,...,m)产生 q 种产出 z p j ( p = 1 , 2 , . . . , q ) ; z_pj(p=1,2,...,q); zpj(p=1,2,...,q); 在第二阶段, D M U j ( j = 1 , 2 , . . . , n ) DMU_{j}(j=1,2,...,n) DMUj(j=1,2,...,n)用 m 种共享比例分别为的外源投入 ( 1 − α i i ) (1-\alpha_{i_{i}}) (1−αii), x i j ( i = 1 , 2 , . . . . , m ) x_{ij}(i=1,2,....,m) xij(i=1,2,....,m)和第一阶段的 q 种产出 z p j ( p = 1 , 2 , . . . , q ) z_{pj}(p=1,2,...,q) zpj(p=1,2,...,q)产生 S 种产出 y r j ( r = 1 , 2 , . . . . , s ) y_{rj}(r=1,2,....,s) yrj(r=1,2,....,s),这 S 种产出离开系统。其中,共享比例 α i i ( i = 1 , 2 , . . . , m ) \alpha_{i_i}(i=1,2,...,m) αii(i=1,2,...,m)是未知参数,管理者可根据现实情况设置共享比例的下界 L i j L_{ij} Lij 和上界 U i j U_{ij} Uij。
其模型最终的规划式如下:
max
E
d
k
(
g
)
=
∑
r
=
1
s
μ
r
k
d
(
g
)
y
r
k
+
∑
p
=
1
q
ω
p
k
d
(
g
)
z
p
k
s.t.
∑
i
=
1
m
v
i
k
d
(
g
)
x
i
k
+
∑
p
=
1
q
ω
p
k
d
(
g
)
z
p
k
=
1
,
∑
p
=
1
q
ω
p
k
d
(
g
)
z
p
j
−
∑
i
=
1
m
β
i
j
d
(
g
)
x
i
j
≤
0
,
j
=
1
,
…
,
n
,
∑
r
=
1
s
μ
r
k
d
(
g
)
y
r
j
−
∑
i
=
1
m
ν
i
k
d
(
g
)
x
i
j
+
∑
i
=
1
m
β
i
j
d
(
g
)
x
i
j
−
∑
p
=
1
q
ω
p
k
d
(
g
)
z
p
j
≤
0
,
j
=
1
,
…
,
n
E
d
(
g
−
1
)
∑
i
=
1
m
v
i
k
d
(
g
)
x
i
d
+
(
E
d
(
g
−
1
)
−
1
)
∑
p
=
1
q
ω
p
k
d
(
g
)
z
p
d
−
∑
r
=
1
s
μ
r
k
d
(
g
)
y
r
d
≤
0
,
L
i
j
ν
i
k
d
(
g
)
≤
β
i
j
d
(
g
)
≤
U
i
j
ν
i
k
d
(
g
)
,
i
=
1
,
…
,
m
;
j
=
1
,
…
,
n
,
v
i
k
d
(
g
)
,
ω
p
k
d
(
g
)
,
μ
r
k
d
(
g
)
≥
0
,
i
=
1
,
…
,
m
;
p
=
1
,
…
,
q
;
r
=
1
,
…
,
s
.
\begin{array}{ll}\max & E_{d k}^{(g)}=\sum_{r=1}^{s} \mu_{r k}^{d(g)} y_{r k}+\sum_{p=1}^{q} \omega_{p k}^{d(g)} z_{p k} \\\text { s.t. } & \sum_{i=1}^{m} v_{i k}^{d(g)} x_{i k}+\sum_{p=1}^{q} \omega_{p k}^{d(g)} z_{p k}=1, \\& \sum_{p=1}^{q} \omega_{p k}^{d(g)} z_{p j}-\sum_{i=1}^{m} \beta_{i j}^{d(g)} x_{i j} \leq 0, j=1, \ldots, n, \\& \sum_{r=1}^{s} \mu_{r k}^{d(g)} y_{r j}-\sum_{i=1}^{m} \nu_{i k}^{d(g)} x_{i j}+\sum_{i=1}^{m} \beta_{i j}^{d(g)} x_{i j}-\sum_{p=1}^{q} \omega_{p k}^{d(g)} z_{p j} \leq 0, j=1, \ldots, n \\& E_{d}^{(g-1)} \sum_{i=1}^{m} v_{i k}^{d(g)} x_{i d}+\left(E_{d}^{(g-1)}-1\right) \sum_{p=1}^{q} \omega_{p k}^{d(g)} z_{p d}-\sum_{r=1}^{s} \mu_{r k}^{d(g)} y_{r d} \leq 0, \\& L_{i j} \nu_{i k}^{d(g)} \leq \beta_{i j}^{d(g)} \leq U_{i j} \nu_{i k}^{d(g)}, i=1, \ldots, m ; j=1, \ldots, n, \\& v_{i k}^{d(g)}, \omega_{p k}^{d(g)}, \mu_{r k}^{d(g)} \geq 0, \quad i=1, \ldots, m ; p=1, \ldots, q ; r=1, \ldots, s .\end{array}
max s.t. Edk(g)=∑r=1sμrkd(g)yrk+∑p=1qωpkd(g)zpk∑i=1mvikd(g)xik+∑p=1qωpkd(g)zpk=1,∑p=1qωpkd(g)zpj−∑i=1mβijd(g)xij≤0,j=1,…,n,∑r=1sμrkd(g)yrj−∑i=1mνikd(g)xij+∑i=1mβijd(g)xij−∑p=1qωpkd(g)zpj≤0,j=1,…,nEd(g−1)∑i=1mvikd(g)xid+(Ed(g−1)−1)∑p=1qωpkd(g)zpd−∑r=1sμrkd(g)yrd≤0,Lijνikd(g)≤βijd(g)≤Uijνikd(g),i=1,…,m;j=1,…,n,vikd(g),ωpkd(g),μrkd(g)≥0,i=1,…,m;p=1,…,q;r=1,…,s.
两阶段博弈DEA模型,由于需要大量计算,如有N个DMU,那么需要进行G*N^2次的线性规划,为了加快运行速度,在计算式采用文献中提供的新的算法设计。其具体思路如下:
第一步:将 g=1 时每个 DMU 博弈前的平均整体交叉效率设置为 0.001,即令 g=1 时(式 3.7)中
E
d
(
0
)
=
0.001
E_d^{( \mathbf{0} ) }= 0. 001
Ed(0)=0.001
(
d
=
1
,
2
,
.
.
.
,
n
)
( d= 1, 2, . . . , n)
(d=1,2,...,n),并求解(式 3.7)至(式 3.11),计算
D
M
U
k
(
k
=
1
,
2
,
.
.
.
,
n
)
DMU_k(k=1,2,...,n)
DMUk(k=1,2,...,n)第 1 次博弈后的平均整体交叉效率
E
k
(
l
)
E_k^{(\mathrm{l})}
Ek(l)、平均第一阶段交叉效率
E
k
l
(
l
)
E_k^{\mathrm{l}(\mathrm{l})}
Ekl(l)以及平均第二阶段交叉效率
E
k
2
(
l
)
;
E_k^{2(\mathrm{l})};
Ek2(l);
第二步:当 g=2 时,求解(式 3.7)至(式 3.11),计算
D
M
U
k
(
k
=
1
,
2
,
.
.
.
,
n
)
DMU_k(k=1,2,...,n)
DMUk(k=1,2,...,n)第 g 次博弈后的平均整体交叉效率
E
k
(
2
)
E_k^{(2)}
Ek(2)、平均第一阶段交叉效率
E
k
1
(
2
)
E_k^{1(2)}
Ek1(2)以及平均第二阶段交叉效率
E
k
2
(
2
)
E_k^{2( 2) }
Ek2(2) ;
第三步:当 g=3 时,令 E k ( 3 ) = E k ( 1 ) + E k ( 2 ) 2 ( k = 1 , 2 , . . . , n ) E_k^{(3)}=\frac{E_k^{(1)}+E_k^{(2)}}2(k=1,2,...,n) Ek(3)=2Ek(1)+Ek(2)(k=1,2,...,n)、 E k 1 ( 3 ) = E k 1 ( 1 ) + E k 1 ( 2 ) 2 E_k^{1(3)}=\frac{E_k^{1(1)}+E_k^{1(2)}}2 Ek1(3)=2Ek1(1)+Ek1(2)
( k = 1 , 2 , . . . , n ) (k=1,2,...,n) (k=1,2,...,n)和 E k 2 ( 3 ) = E k 2 ( 1 ) + E k 2 ( 2 ) 2 ( k = 1 , 2 , . . . , n ) ; E_{k}^{2(3)}=\frac{E_{k}^{2(1)}+E_{k}^{2(2)}}{2}\left(k=1,2,...,n\right); Ek2(3)=2Ek2(1)+Ek2(2)(k=1,2,...,n);
第四步:当
g
≥
4
g\geq4
g≥4时,求解(式 3.7)至(式 3.11),计算
D
M
U
k
(
k
=
1
,
2
,
.
.
.
,
n
)
DMU_k(k=1,2,...,n)
DMUk(k=1,2,...,n)第 g 次博弈后的平均整体交叉效率
E
k
(
g
)
E_k^{(\mathrm{g})}
Ek(g)、平均第一阶段交叉效率
E
k
1
(
s
)
E_k^{1(\mathrm{s})}
Ek1(s)以及平均第二阶段交叉效率
E
k
2
(
g
)
;
E_k^{2(g)};
Ek2(g);
第五步:判断第四步每个
D
M
U
k
(
k
=
1
,
2
,
.
.
.
,
n
)
DMU_k(k=1,2,...,n)
DMUk(k=1,2,...,n)的计算结果是否满足
∣
E
k
(
g
+
1
)
−
E
k
(
g
)
∣
≤
ε
,
∣
E
k
l
(
g
+
1
)
−
E
k
l
(
g
)
∣
≤
ε
,
∣
E
k
2
(
g
+
1
)
−
E
k
2
(
g
)
∣
≤
ε
(
k
=
1
,
2
,
.
.
.
,
n
)
\left|E_k^{(\mathrm{g}+1)}-E_k^{(\mathrm{g})}\right|\leq\varepsilon,\left|E_k^{\mathrm{l}(\mathrm{g}+1)}-E_k^{\mathrm{l}(\mathrm{g})}\right|\leq\varepsilon,\left|E_k^{2(\mathrm{g}+1)}-E_k^{2(\mathrm{g})}\right|\leq\varepsilon(k=1,2,...,n)
Ek(g+1)−Ek(g)
≤ε,
Ekl(g+1)−Ekl(g)
≤ε,
Ek2(g+1)−Ek2(g)
≤ε(k=1,2,...,n),若存在 DMU 不满足此三个不等式中的任一不等式则重复第四步,直到所有 DMU 都满足上述不等式。
关于该模型,使用matlab和julia分别完成了模型建模,均能得到和论文相同的结果(指总效率,分阶段效率有差异,但是排名与论文中的结果近似。这是由于最优解不唯一造成的。)
对比如下:
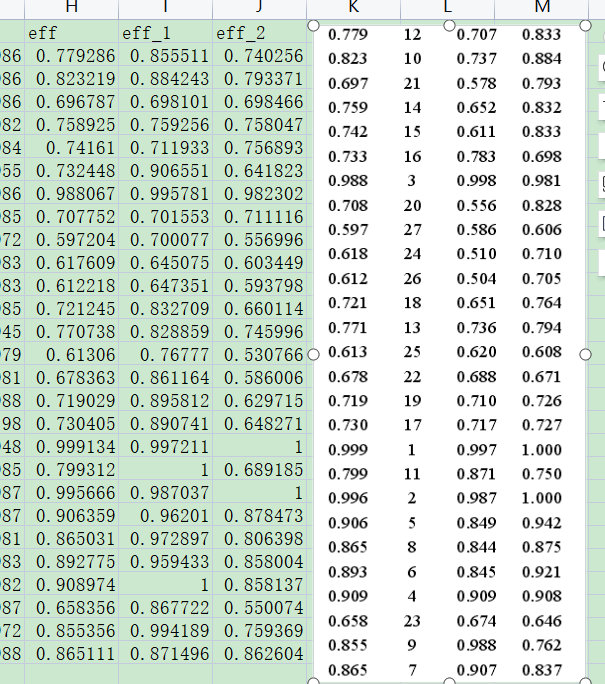
参考文献:《网络DEA中的交叉效率及其应用研究》
有需要的同学可以联系微信: canglang12002















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









