






项目介绍
此项目使用jetson nano和STM32开发板完成,jetson nano通过摄像头获取垃圾图像,并使用AI模型进行推理,得到推理结果,发送指令控制STM32操作对应类别的舵机,从而打开对应垃圾类别的垃圾桶
硬件准备
硬件材料准备
- Nvidia Jetson nano开发板 4GB内存
- STM32F103C8T6开发板
- 鼠标
- 键盘
- 显示器
- CSI摄像头
- SD卡与读卡器
- MG90舵机(4个)
- 超声波测距传感器HC-SR04
- 迷你垃圾桶(4个)
- 杜邦线若干
硬件连接简图
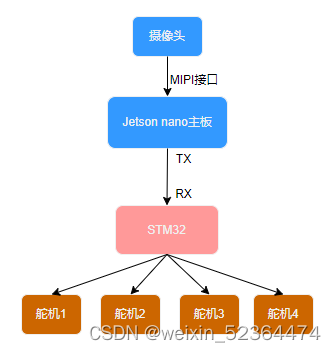
环境搭建
系统烧录与初始化设置
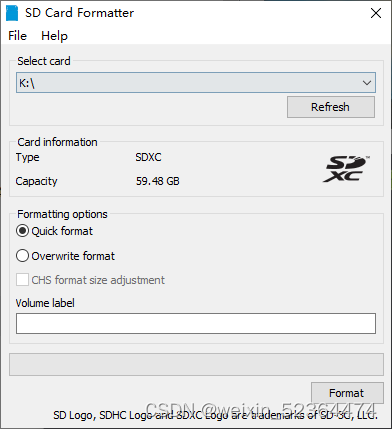
首先,我们需要准备好我们的SD卡和读卡器,将其插入我们的PC端,使用SD Card Formatter将其初始化
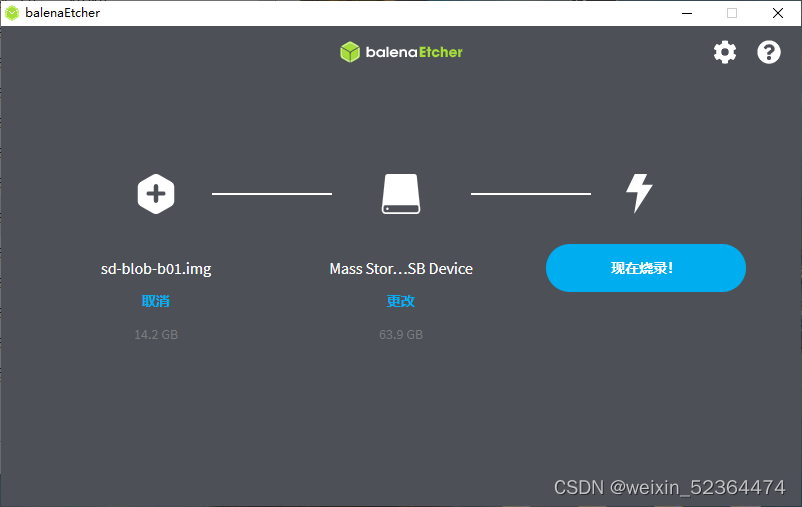
再使用belenaEtcher将我们从英伟达官网下载的系统镜像下载至SD卡
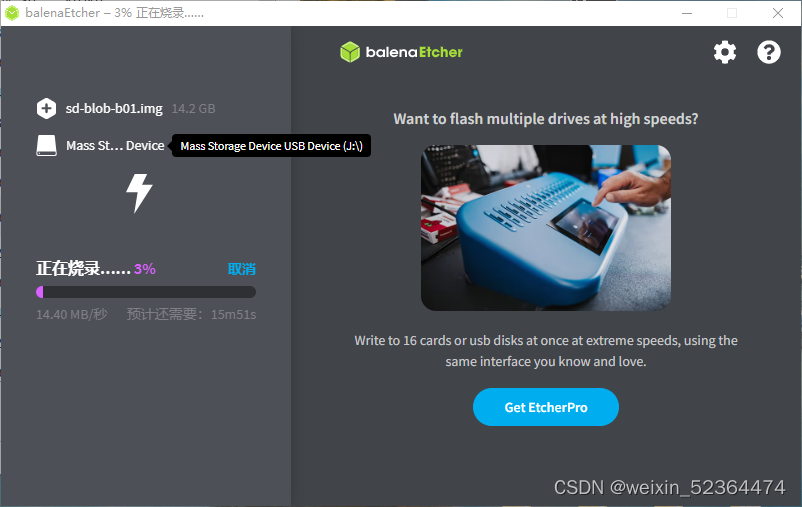
此过程耗时较长,请耐心等待
注:在烧录完成以后,会有验证过程,在验证过程中,你的电脑不断出现新的磁盘,提示你进行格式化,直接点击取消即可,烧录到最后,烧录软件会提示你烧录失败,但实际上已经烧录成功了,不必在意提示
此系统镜像的链接如下:https://developer.nvidia.com/embedded/jetpack-sdk-44-archive
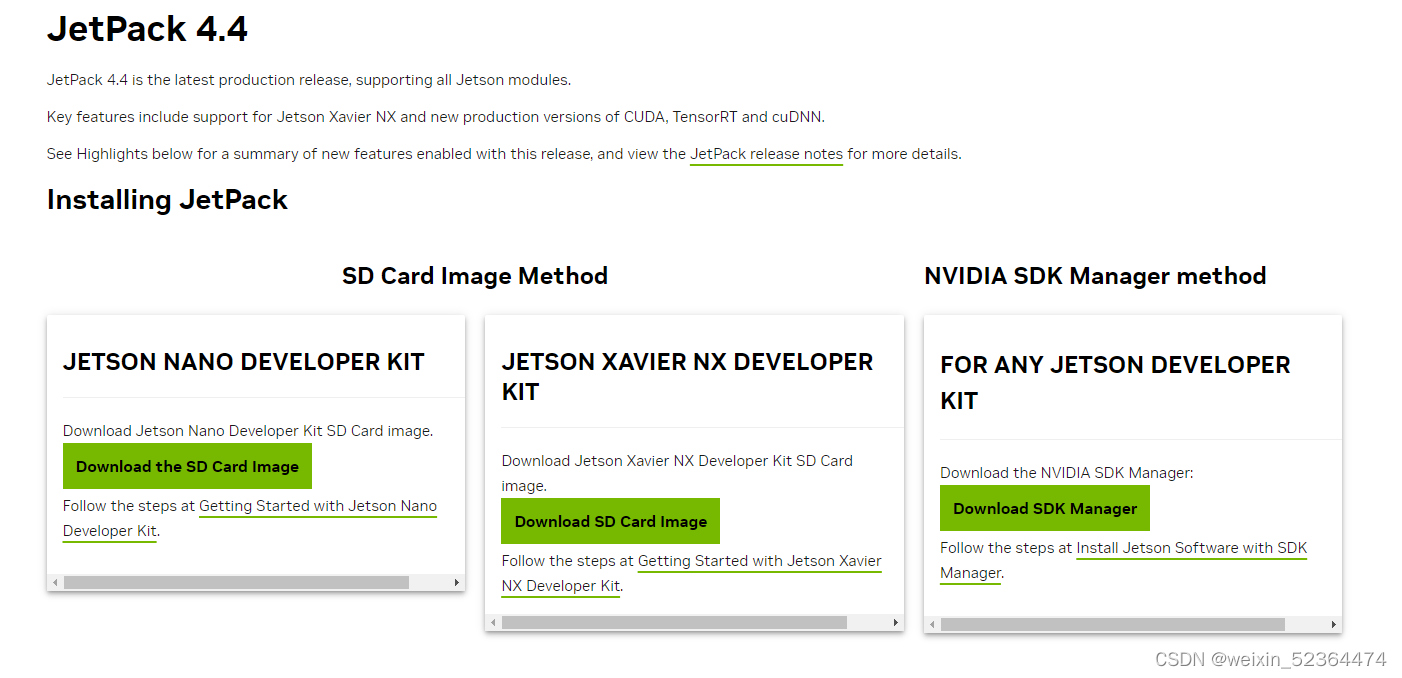
点击最左边框中“Download the SD Card Image“即可下载,本项目使用的是JetPack4.4,如果你要下载其他版本的镜像,可在如下链接中寻找自己想要的版本:https://developer.nvidia.com/embedded/jetpack-archive
将SD插入卡槽,将Jetson nano与键盘,鼠标和显示器相连接,插上电源,启动系统,开机以后要求填入用户名,设置密码等初始化操作,直接按部就班完成即可,设置完成以后系统会自动重启,至此完成了系统安装
jupyter-lab与相关依赖安装
首先需要安装nodejs和npm:
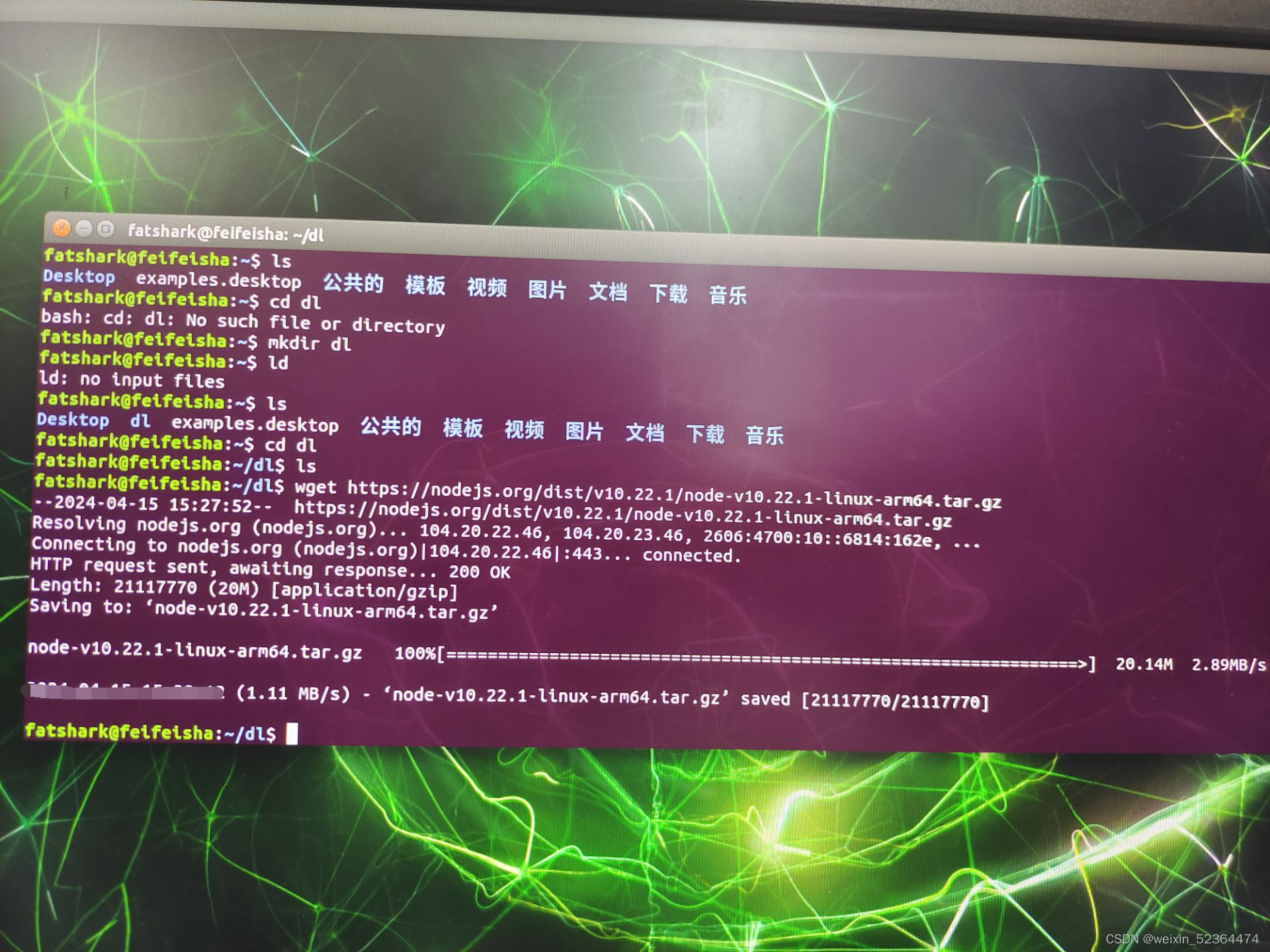
如果要安装其他版本的nodejs,可自行前往官网选择:https://nodejs.org/dist/
安装好以后node 以后,使用软链接将node和npm链接至系统的bin目录下,查看Node版本:
sudo ln -s /usr/local/"你下载的node所在文件夹的名称"/bin/node /usr/local/bin
sudo ln -s /usr/local/"你下载的node所在文件夹的名称"/bin/npm /usr/local/bin
node -v
由于下载的版本不同,保存node所在的文件夹名称也有所不同,这里根据你自己下载的版本来确定,
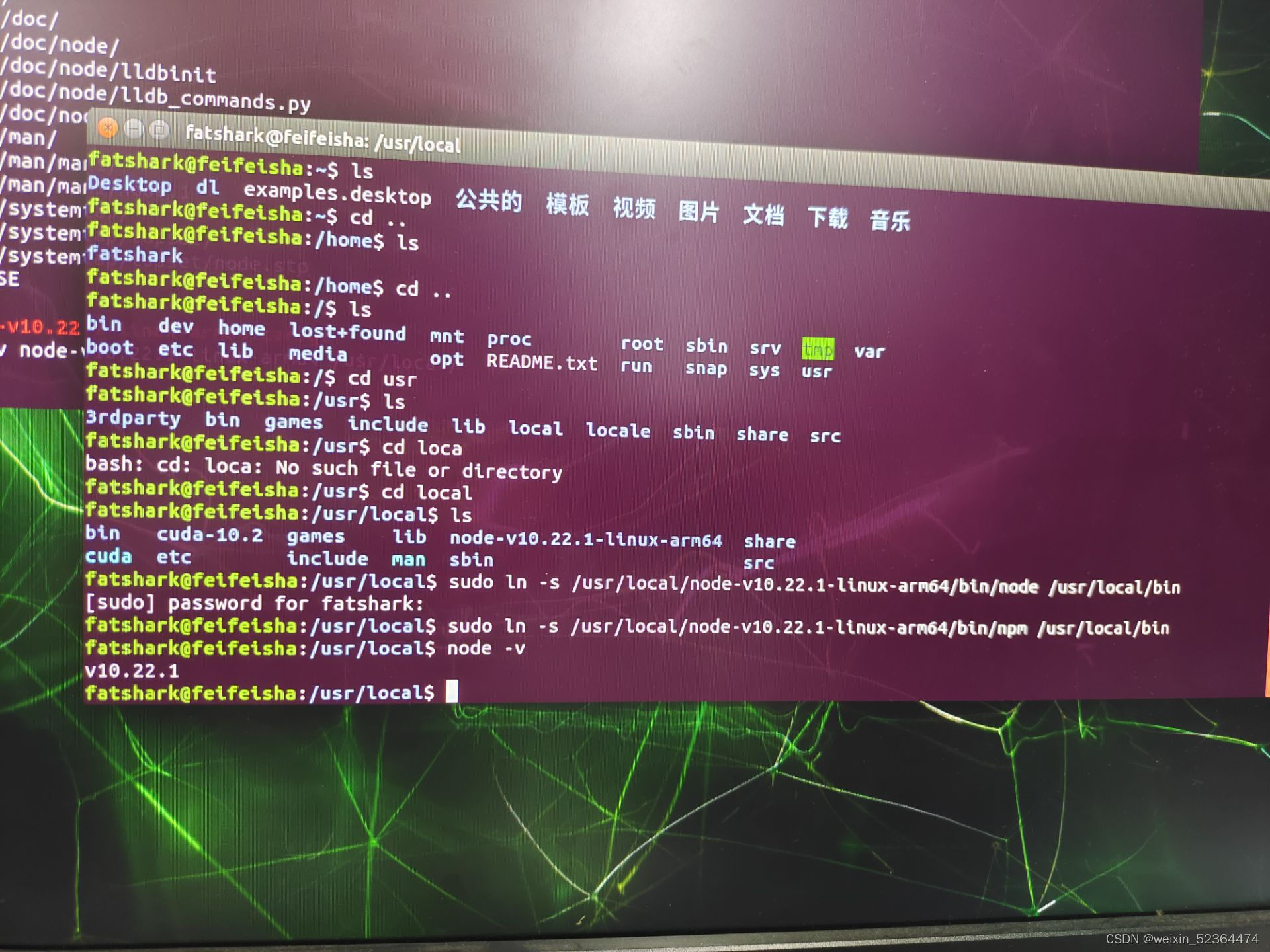
安装Node成功
安装libffi-dev:
sudo apt-get install libffi-dev
安装packaging:
pip3 install packaging
安装setuptools:
pip3 install setuptools
安装jupyter-lab,我安装的版本是2.2.6,注意,此处不要安装最新版本的jupyter-lab,因为最新版本的jupyter-lab要求nodejs版本>=12.x.x,而此版本的nodejs又会要求ubuntu系统给glibc版本为2.28,而JetPack为我们提供的系统镜像为ubuntu 18.04,glibc版本最高为2.27,而升级此系统库容易使系统崩溃,从而导致系统重装,为了避免出现某些奇怪报错,建议所有软件版本严格参考此博客进行下载
pip3 install jupyter-lab=2.2.6
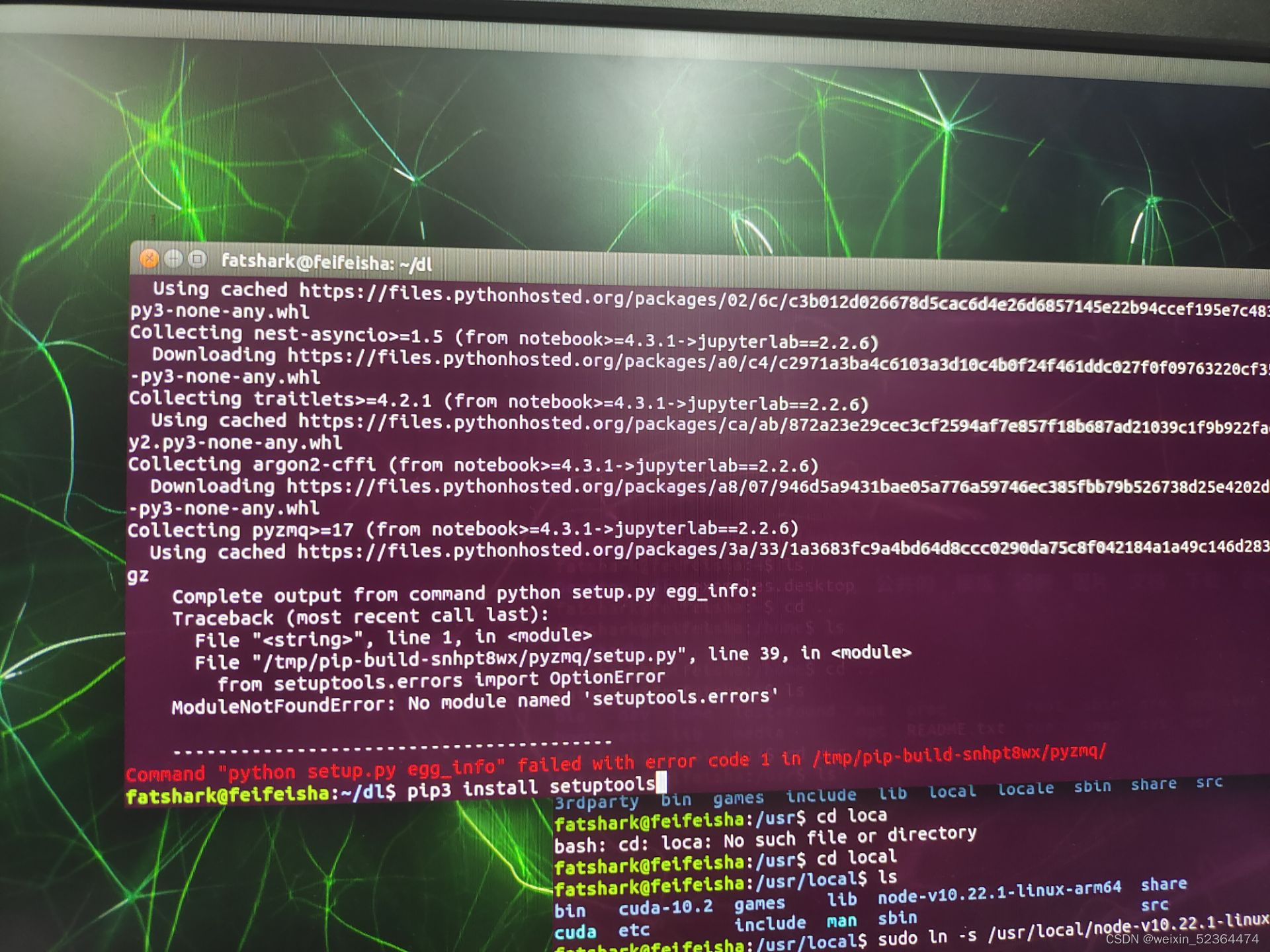
出现报错,经尝试,解决方案使升级pip,
python3 -m pip install --upgrade pip
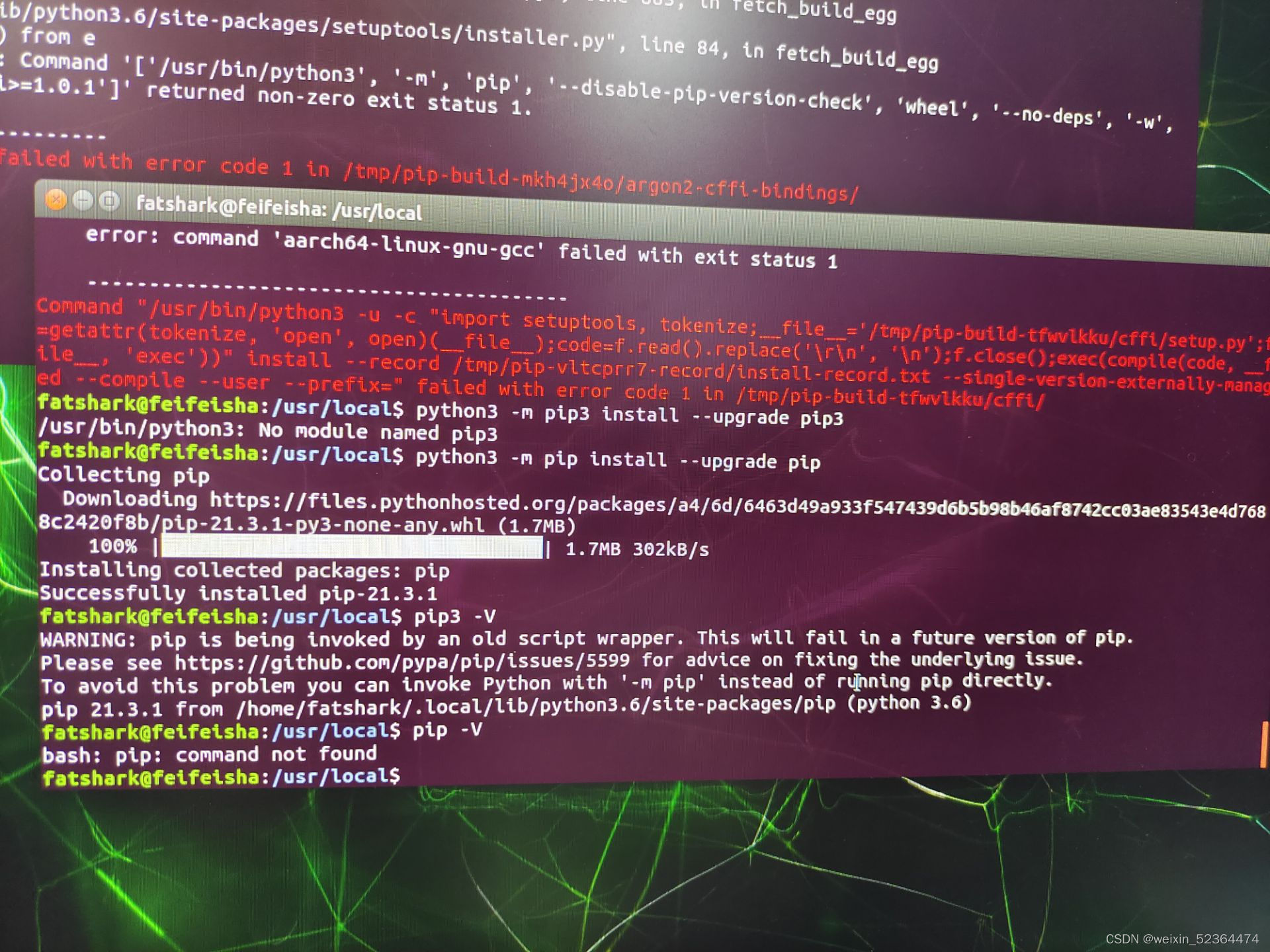
升级完成,再次安装Jupyter-lab,成功
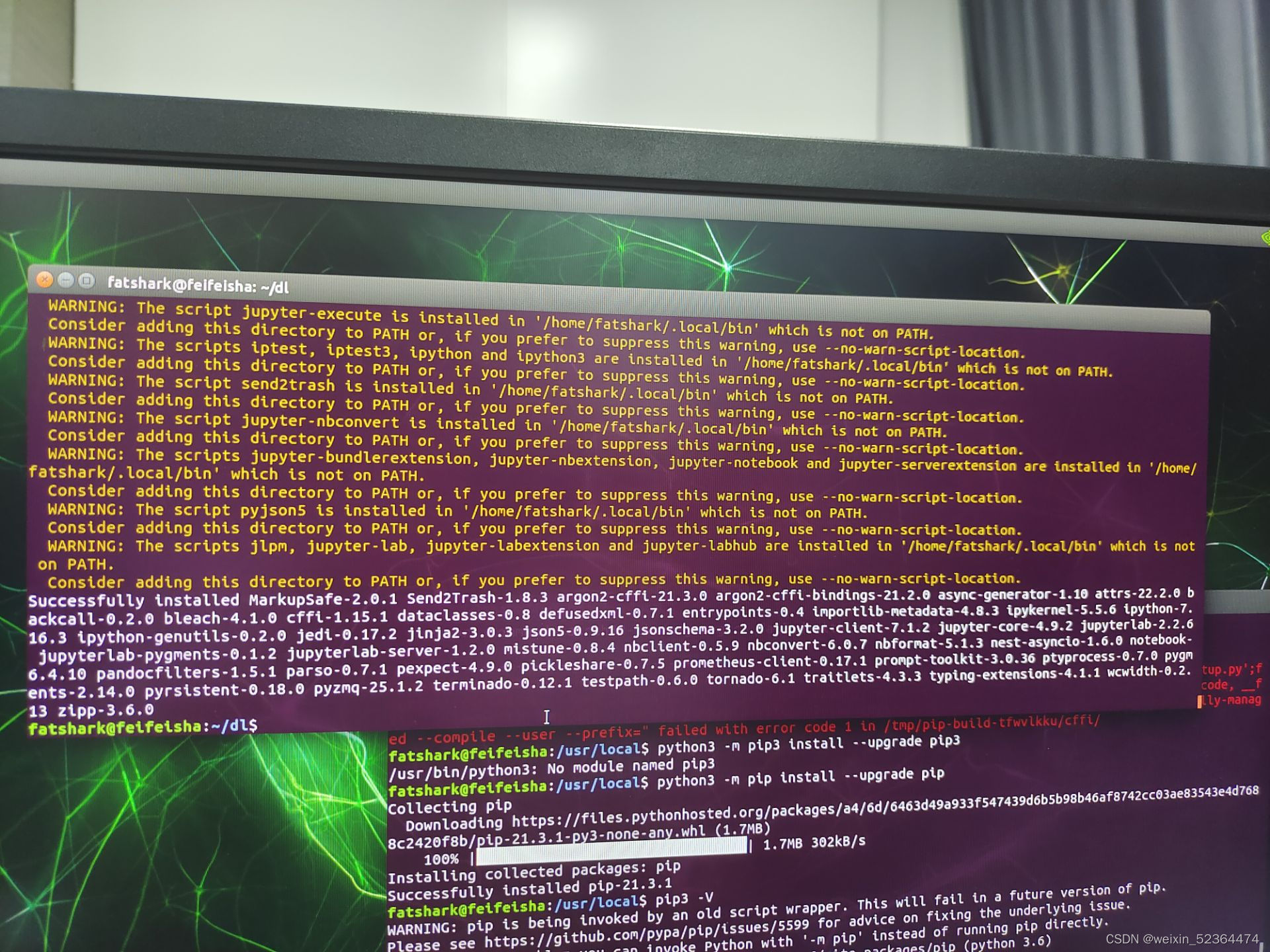
查看jupyter --version
发现还有部分依赖,如ipywidgets,jupyter_server等没有安装,直接使用Pip无脑安装即可
安装完成以后如下:
安装完成以后,还需要对jupyter lab进行设置,首先启用拓展
jupyter nbextension enable --py widgetsnbextension
jupyter labextension install @jupyter-widgets/jupyterlab-manager
安装完成以后,使用命令生成配置文件
jupyter lab --generate-config
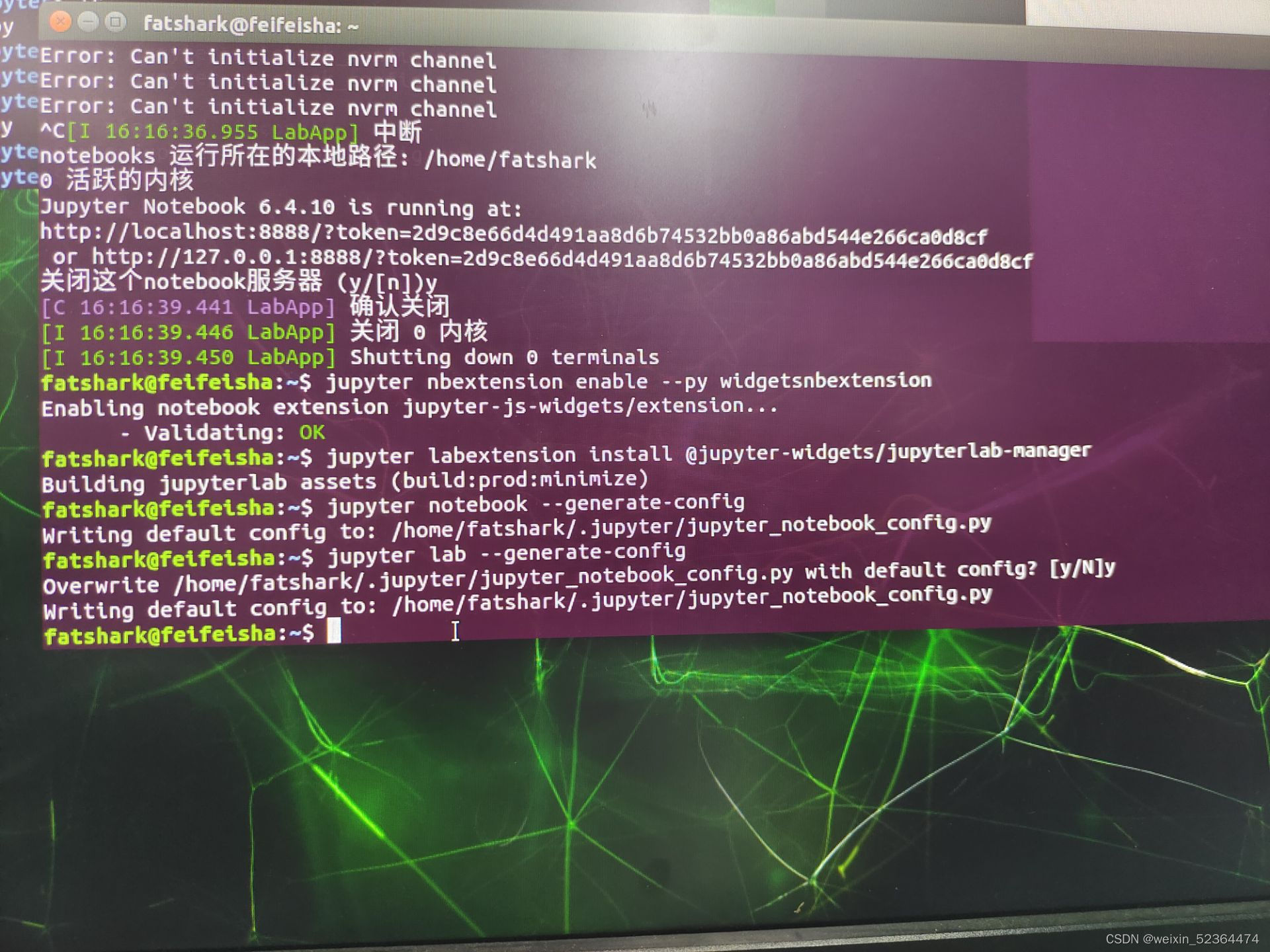
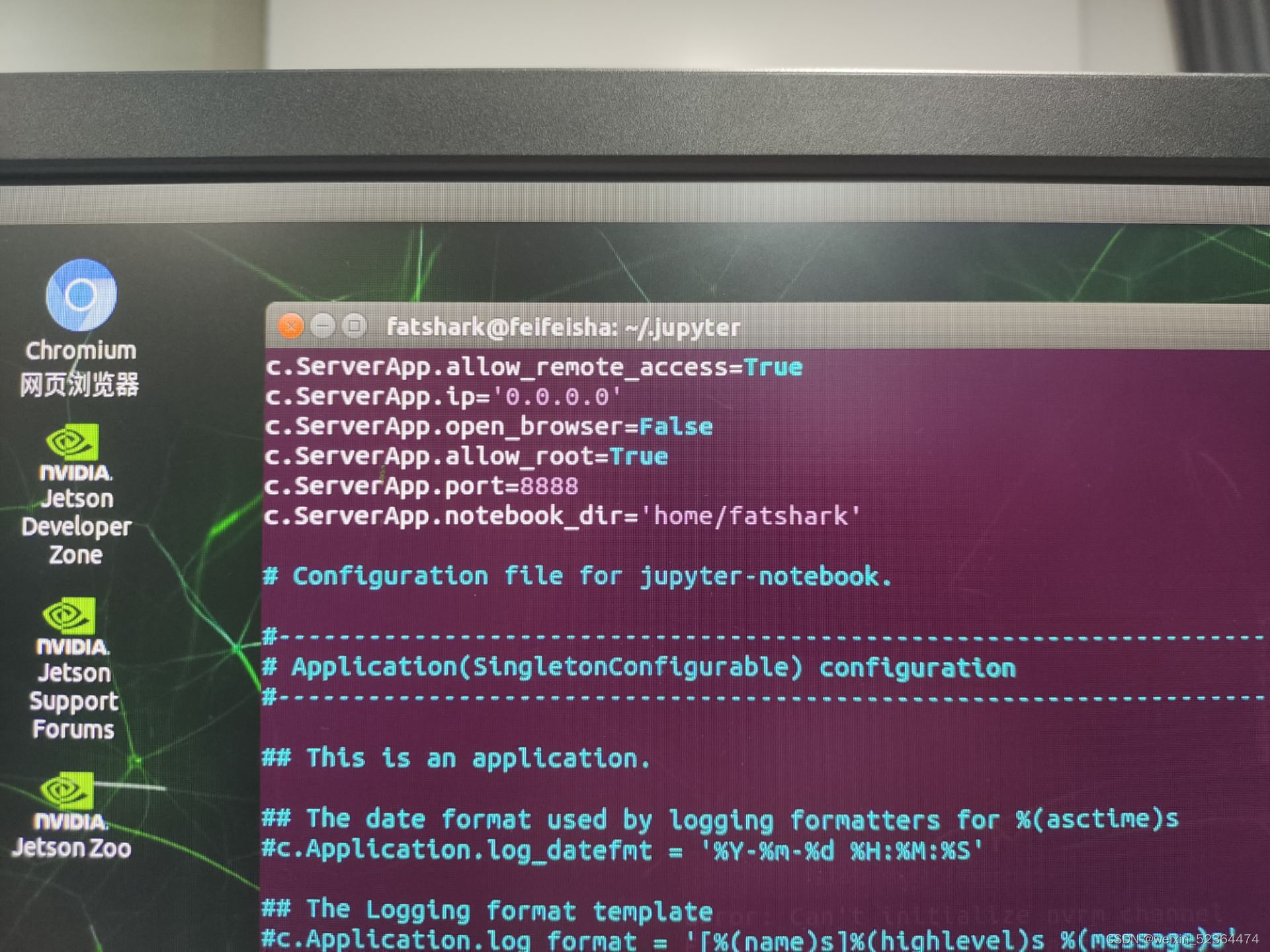
找到相关目录下的配置文件,使用vim 编辑器打开jupyter_notebook_config.py文件,添加以下内容
c.ServerApp.allow_remote_access=True //允许远程访问
c.ServerApp.ip='0.0.0.0' //允许所有IP访问
c.ServerApp.open_browser=False //默认不打开浏览器
c.ServerApp.allow_root=True //允许使用root用户运行jupyterlab
c.ServerApp.port=8888 //设置端口
c.ServerApp.notebook_dir='home/fatshark'//设置工作目录
在终端输入命令,运行jupyter lab
jupyter lab
打开浏览器,输入localhost:8888
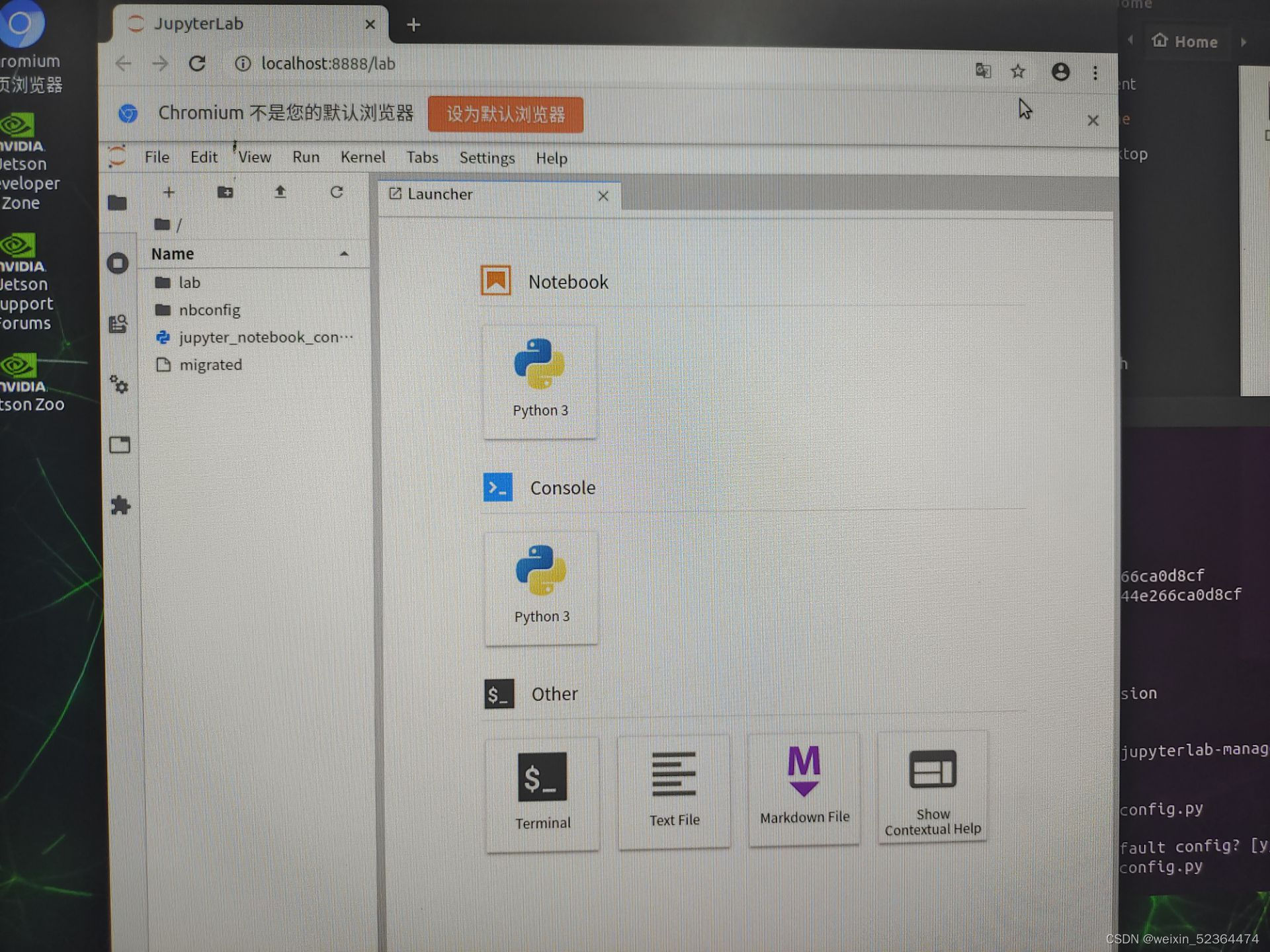
如果要远程登录,可以在其他主机浏览器中输入IP地址:端口号即可
pytorch安装
在Jetson nano上面安装的pytorch与我们平常在PC端主机安装的pytorch不同,因为Jetson nano是ARM架构的,pytorch官网提供的均是x86架构的,所以要参考Nvidia官网提供的指示来安装ARM架构的pytorch
链接如下https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
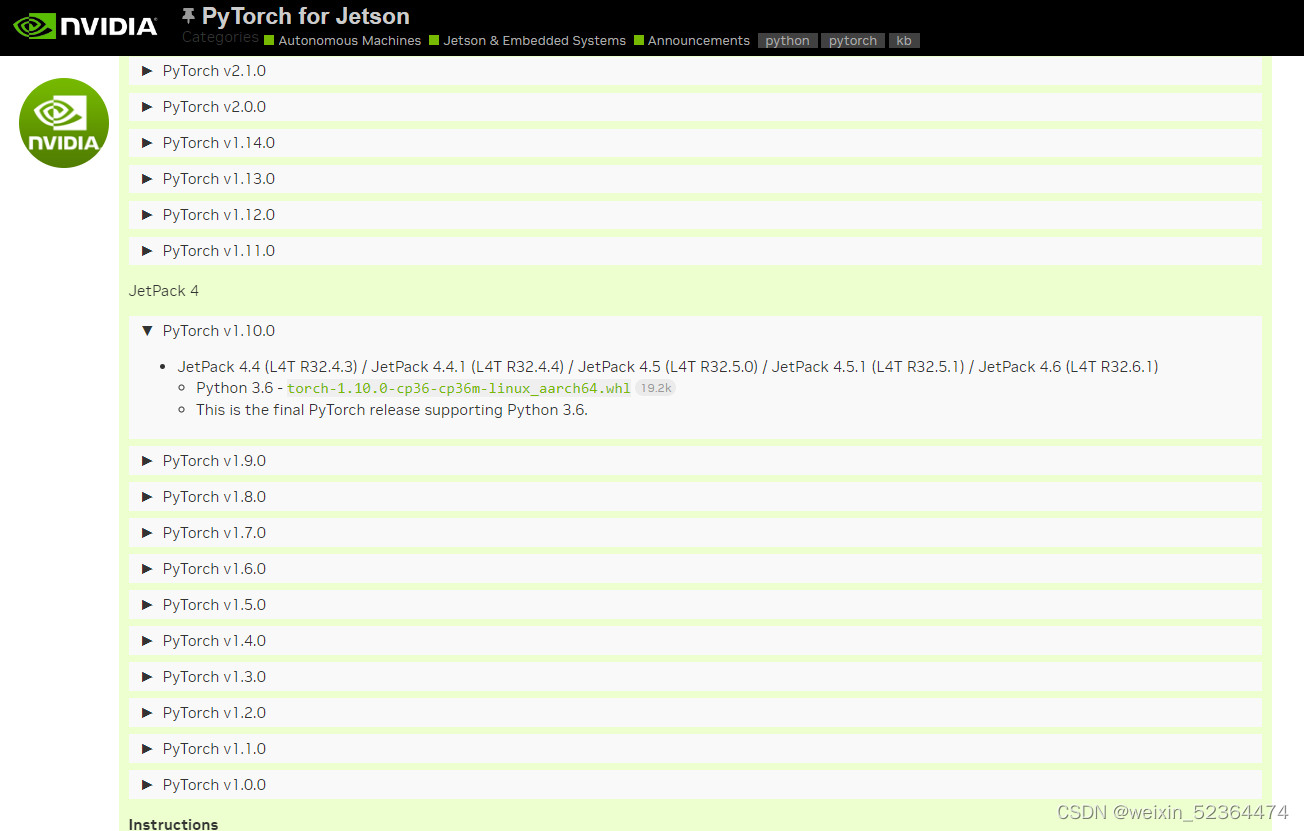
主页有很多版本的PyTorch,针对JetPack4.4,我们选择v1.10.0
具体安装可以查看Instructions
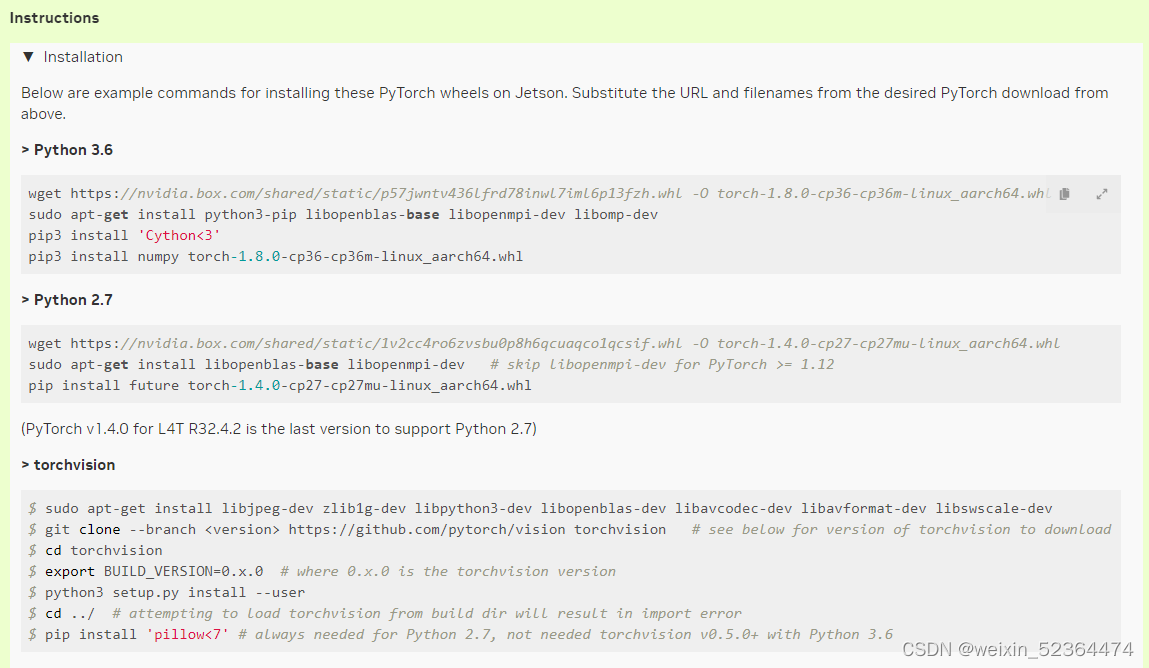
针对Python3.6,在命令行终端输入以下命令即可
注意,上图中只是给了示例,其中显示的版本号不一定是我们需要的,我们需要将命令中的版本改为自己实际需要的版本,上图中安装的版本是1.8.0,我们实际安装的是1.10.0,注意区别,torchvision的安装也同理
安装pytorch,注意版本为1.10.0
wget https://nvidia.box.com/shared/static/p57jwntv436lfrd78inwl7iml6p13fzh.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev libomp-dev
pip3 install 'Cython<3'
pip3 install numpy torch-1.10.0-cp36-cp36m-linux_aarch64.whl
安装torchvision,注意版本为0.11.1
$ sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libopenblas-dev libavcodec-dev libavformat-dev libswscale-dev
$ git clone --branch <version> https://github.com/pytorch/vision torchvision # see below for version of torchvision to download
$ cd torchvision
$ export BUILD_VERSION=0.11.1 # where 0.x.0 is the torchvision version
$ python3 setup.py install --user
$ cd ../ # attempting to load torchvision from build dir will result in import error
$ pip install 'pillow<7' # always needed for Python 2.7, not needed torchvision v0.5.0+ with Python 3.6
安装完成以后,在终端输入python3,尝试import torch和torchvision,同时打印出对应的版本
python3
>>> import torch
>>> import torchvision
>>> print(torch.__version__)
>>> print(torchvision.__version__)
如果能出现版本号,则证明已经安装成功
STM32开发环境搭建
STM32的开发需要用到Keil和STM32CubeMx,
因涉及到软件版权问题,Keil和STM32CubeMX的安装过程,此博客不做详细介绍,可以自行阅读其他博客进行学习
使用jupyter-lab创建交互界面
在jupyter-lab中创建交互界面,主要是使用ipywidgets组件来完成,其中主要使用到的有Button,IntText,Dropdown等组件
catgo_widget = ipywidgets.Dropdown(options=CATEGORIES, description = 'category')
add_data_btn = ipywidgets.Button(description='add img')
delete_data_btn = ipywidgets.Button(description='del imgs')
count_widget = ipywidgets.IntText(description = 'count:',value=0,disabled = True)
count_widget.value = datasets.get_count(catgo_widget.value)
# 得到数据集中,每一个类别的数据集大小
def cat_count(c):
count_widget.value = datasets.get_count(catgo_widget.value)
catgo_widget.observe(cat_count,names='value')
# 往数据集中添加图像
def add_images(c):
datasets.save_entry(camera.value,catgo_widget.value)
count_widget.value = datasets.get_count(catgo_widget.value)
add_data_btn.on_click(add_images)
#删除图像
def del_images(c):
datesets.delete_imgs(catgo_widget.value)
delete_data_btn.on_click(del_images)
data_collection_widget = ipywidgets.VBox([
ipywidgets.HBox([image_widget]), catgo_widget, count_widget, add_data_btn,delete_data_btn
])
对于Button组件,主要使用on_click方法来触发回调函数,进行操作,对于Dropdown(下拉菜单),主要使用observe方法对其中的属性值进行监听。此代码块仅为交互界面部分代码,详细内容见文末
此交互界面最终完整效果如下:
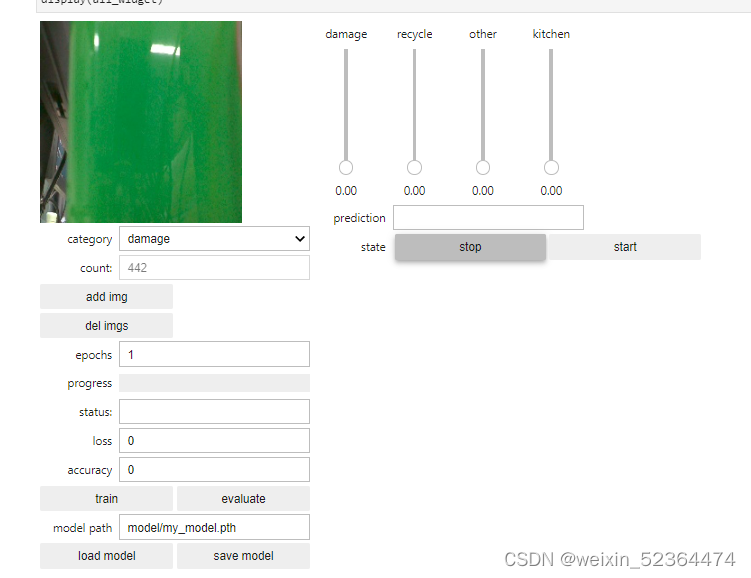
此交互界面主要包括摄像头实时画面,数据集添加界面,模型训练界面,模型保存和读取界面以及模型推理界面
模型训练
我们使用预训练的模型resnet-18来作为图像识别要用到的模型
引入模型:
import torch
import torchvision
device = torch.device('cuda')# 使用cuda
# RESNET 18
model = torchvision.models.resnet18(pretrained=True)# 预训练
model.fc = torch.nn.Linear(512, len(datasets.categories))
model = model.to(device)
训练和评估模型:
def train_eval(is_training):
global BATCH_SIZE, LEARNING_RATE, MOMENTUM, model, datasets, optimizer, eval_button, train_button, accuracy_widget, loss_widget, progress_widget, state_widget,info_widget# 一些全局变量
try:
train_loader = torch.utils.data.DataLoader(
datasets,
batch_size=BATCH_SIZE,# BATCH_SIZE为8
shuffle=True
)
state_widget.value = 'stop'
train_button.disabled = True
eval_button.disabled = True
time.sleep(1)
if is_training:
model = model.train()
else:
model = model.eval()
while epochs_widget.value > 0:
i = 0
sum_loss = 0.0
error_count = 0.0
for images, labels in iter(train_loader):
# 将数据传输到GPU上
images = images.to(device)
labels = labels.to(device)
if is_training:
# 将梯度清0
optimizer.zero_grad()
# 进行推理,得到结果
outputs = model(images)
# 计算误差
loss = F.cross_entropy(outputs, labels)
if is_training:
# 进行反向传播
loss.backward()
# 调整权重
optimizer.step()
# 对推理结果进行统计,计算准确率
error_count += len(torch.nonzero(outputs.argmax(1) - labels).flatten())
count = len(labels.flatten())
i += count
sum_loss += float(loss)
progress_widget.value = i / len(datasets)
loss_widget.value = sum_loss / i
accuracy_widget.value = 1.0 - error_count / i
if is_training:
epochs_widget.value = epochs_widget.value - 1
else:
break
except e:
info_widget.value='an error occured'
model = model.eval()
此代码为训练时运行的核心代码,train_eval为主要函数,train_eval中会接收一个参数,用于确认此次执行的行为是训练模型还是评估模型,在训练时,会根据结果进行反向传播,调整权重,评估模型时仅仅计算误差与准确率。
STM32相关驱动
在STM32部分,需要用到的硬件有USART和PWM接口,此外还需要两根引脚用于驱动超声波测距模块,PWM信号的输出我们计划使用TIM1的CH1,CH2,CH3,CH4通道,USART使用USART2->RX和USART3->TX(之所以不直接使用同一个USART的RX和TX,单纯是因为硬件接线不方便,所以这里使用了两个USART的不同功能引脚)
此外,对于超声波传感器,使用PA0和PA1作为驱动接口,PA0使用TIM2_CH1作为获取传感器数据的引脚,PA1作为触发超声波传感器工作的引脚
解释一下为什么使用超声波传感器,在此项目中,AI模型要解决的问题是一个四分类问题,那么意味着,我们获取到的图像中,无论是否存在垃圾桶,AI模型都会进行推理并得到一个结果,这明显不符合系统的工作逻辑,我们希望添加一些限制条件,才会触发AI模型进行推理,所以,我们使用超声波传感器,只有当垃圾在摄像头前一定距离的时候,我们才进行推理
根据超声波模块的工作原理图:
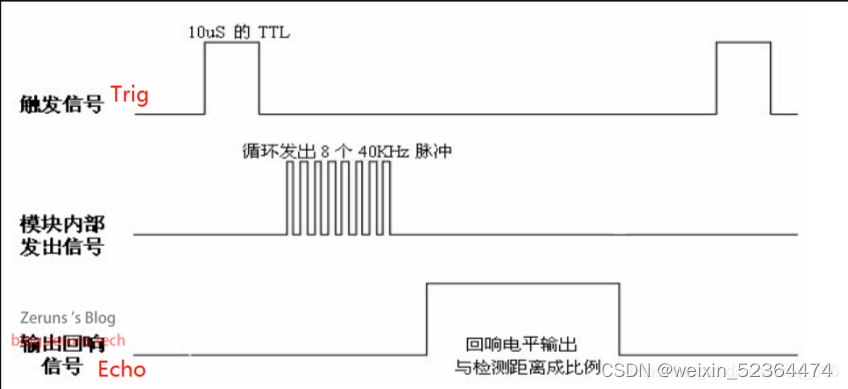
这里Trig为PA1,Echo为PA0
超声波驱动代码如下:
void HC_Start(void)//启动传感器进行一次测距
{
HAL_GPIO_WritePin(GPIOA,GPIO_PIN_1,GPIO_PIN_SET);
Delay(1000);
HAL_GPIO_WritePin(GPIOA,GPIO_PIN_1,GPIO_PIN_RESET);
Delay(100000);
}
uint32_t Distance=0;
void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef *htim)
{
if(htim->Instance==TIM2)
{
if(htim->Channel==HAL_TIM_ACTIVE_CHANNEL_1)//捕获到上升沿时,清空CNT
{
__HAL_TIM_SetCounter(htim,0);
}
if(htim->Channel==HAL_TIM_ACTIVE_CHANNEL_2)
{
Distance = HAL_TIM_ReadCapturedValue(htim,TIM_CHANNEL_2);//捕获到下降沿时,读取捕获值
}
HAL_TIM_IC_Start(htim,TIM_CHANNEL_1);
HAL_TIM_IC_Start(htim,TIM_CHANNEL_2);
}
}
在获取echo值时,我们使用到了TIM2_CH1的输入捕获功能,在第一次捕获到上升沿时,将CNT清0,那么在第二次捕获到下降沿时,就可以直接得到高电平的持续时间,从而方便地算出距离
主函数核心代码如下:
HAL_TIM_PWM_Start(&htim1, TIM_CHANNEL_1);//开启PWM输出
HAL_TIM_PWM_Start(&htim1, TIM_CHANNEL_2);
HAL_TIM_PWM_Start(&htim1, TIM_CHANNEL_3);
HAL_TIM_PWM_Start(&htim1, TIM_CHANNEL_4);
HAL_UARTEx_ReceiveToIdle_IT(&huart2,(uint8_t *)Motor_Cmd,10);//使用串口接收推理数据
HAL_TIM_IC_Start_IT(&htim2,TIM_CHANNEL_1);//开启输入捕获
HAL_TIM_IC_Start_IT(&htim2,TIM_CHANNEL_2);
__HAL_TIM_SetCompare(&htim1,TIM_CHANNEL_1,CLOSE);//初始化时,先关闭垃圾桶
__HAL_TIM_SetCompare(&htim1,TIM_CHANNEL_2,CLOSE);
__HAL_TIM_SetCompare(&htim1,TIM_CHANNEL_3,CLOSE);
__HAL_TIM_SetCompare(&htim1,TIM_CHANNEL_4,CLOSE);
/* USER CODE END 2 */
/* Infinite loop */
/* USER CODE BEGIN WHILE */
uint32_t sum=0;//进行均值滤波的中间变量
uint8_t motor_flag=0;//用于判断是否接收到推理结果
while (1)
{
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
uint8_t i=10;
while(i--)
{
HC_Start();//激活HC传感器进行测量
HAL_Delay(10);
sum+=Distance;
}
sum=sum/10;
if(sum<350)//垃圾距离足够近,才开启系统工作
{
motor_flag=1;
}
else if(sum>450)//距离太远,整个系统不工作
{
motor_flag=0;
}
sum=0;
HAL_Delay(400);
if(motor_flag==1)//垃圾在合适的距离内才进行推理
{
if(Serial_flag==1)
{
Motor_Ctrl();//根据推理结果控制对应垃圾桶开关
for(uint8_t i=0 ; i < 10; i++ )
{
Motor_Cmd[i]='\0';
}
Serial_flag=0;
}
HAL_UART_Transmit(&huart3, (uint8_t *)"start", 5, 50);//开启
}
else//距离过远,停止推理,同时垃圾桶关闭
{
HAL_UART_Transmit(&huart3, (uint8_t *)"stop", 5, 50);//关闭
__HAL_TIM_SetCompare(&htim1,TIM_CHANNEL_1,CLOSE);
__HAL_TIM_SetCompare(&htim1,TIM_CHANNEL_2,CLOSE);
__HAL_TIM_SetCompare(&htim1,TIM_CHANNEL_3,CLOSE);
__HAL_TIM_SetCompare(&htim1,TIM_CHANNEL_4,CLOSE);
}
在控制舵机的核心代码中,我们需要根据超声波得到的距离来判断我们是否应该打开垃圾桶,只有距离小于一定值时,我们才会执行推理,控制垃圾桶开关,否则垃圾桶应一直保持关闭状态
功能集成
在搞定了AI模型以及STM32相关驱动后,我们将进行功能集成,把各个组件全部连接,进行测试
在功能集成部分,需要使用到Jetson nano的串口功能,我们需要使用串口将我们的推理结果发送至STM32,从而确定打开哪一个垃圾桶,同时,Jetson nano也应该接收来自STM32的距离信息,根据距离信息判断是否进行推理,
在发送推理结果时,我们会发送一个字符串,该字符串由四个为’0’或’1’的字符构成,分别代表了四个舵机的开关状态,如果发送的字符串是’0100’,表明我们应该打开二号舵机,STM32在接收到此字符串后,会进行解析,并打开对应舵机。
同时,我们也应该使用STM32发送超声波传感器的距离信息,从而确认是否进行推理,如下图:
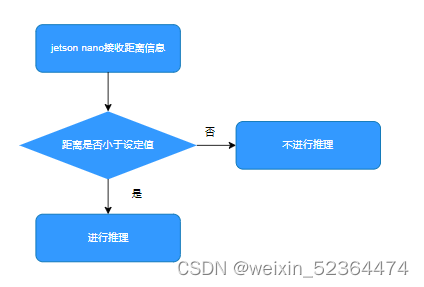
核心代码如下:
import threading
import time
from utils import preprocess
import torch.nn.functional as F
import serial as ser
#my code begin:
se = ser.Serial("/dev/ttyTHS1",9600,timeout=50)
motor_cmd=['0','0','0','0']
# new:
dis_cmd=b'123'
def ser_func():#串口接收信息
global dis_cmd
while True:
time.sleep(0.1)
if se.in_waiting>0:
dis_cmd = se.read_all()
ser_thread = threading.Thread(target=ser_func)
ser_thread.start()
#my code end
state_widget = ipywidgets.ToggleButtons(options=['stop', 'start'], description='state', value='stop')
prediction_widget = ipywidgets.Text(description='prediction')
score_widgets = []
for category in datasets.categories:
score_widget = ipywidgets.FloatSlider(min=0.0, max=1.0, description=category, orientation='vertical')
score_widgets.append(score_widget)
def live(state_widget, model, camera, prediction_widget, score_widget):
global datasets,motor_cmd, score_widgets,dis_cmd
print("we are in the live")
while state_widget.value == 'start':
if dis_cmd==b'start':#距离小于一定值,开始推理
image = camera.value
preprocessed = preprocess(image)
output = model(preprocessed)
output = F.softmax(output, dim=1).detach().cpu().numpy().flatten()
category_index = output.argmax()
#my code:
time.sleep(0.01)
for i in range(0,4):
if(category_index==i):
motor_cmd[i]='1'
else:
motor_cmd[i]='0'
new = ''.join(motor_cmd)
se.write(new.encode("GBK"))# 发送推理信息,确认打开对应舵机
prediction_widget.value = datasets.categories[category_index]
for i, score in enumerate(list(output)):
score_widgets[i].value = score
else:
se.write("0000".encode("GBK"))# 距离太远,所有舵机均为关闭
score_widgets[0].value=0.0
score_widgets[1].value=0.0
score_widgets[2].value=0.0
score_widgets[3].value=0.0
se.write("0000".encode("GBK"))# 停止状态,关闭所有舵机
score_widgets[0].value=0.0
score_widgets[1].value=0.0
score_widgets[2].value=0.0
score_widgets[3].value=0.0
此代码块主要解决了串口信息的收发,以及对推理结果的处理
完整工程代码详见github链接:















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









