







记录一些sas学习过程
文章目录
一、初始化变量
1.直接输入变量
如果数据不是数值,在变量名后面空一格加$
data mylib.rate;
input year $ rate;
cards;
2018年1月 11.2
2018年2月 11
2018年3月 10.4
2018年4月 10.1
2018年5月 9.6
2018年6月 10
2018年7月 13.3
2018年8月 13.1
2018年9月 11.2
2018年10月 9.8
2018年11月 10
;
print:
proc print;
run;
2.从Excel文件中导入数据
FILENAME REFFILE
"D:\2022autumn\data_analysis\data2.xlsx"
TERMSTR=CR;
PROC IMPORT DATAFILE=REFFILE
DBMS=XLSX
OUT=WORK.IMPORT;
GETNAMES=YES;
SHEET='sheet1'
RUN;
PROC PRINT DATA=WORK.IMPORT;
二、描述性统计分析量
如平均数,方差,标准差,极差等。
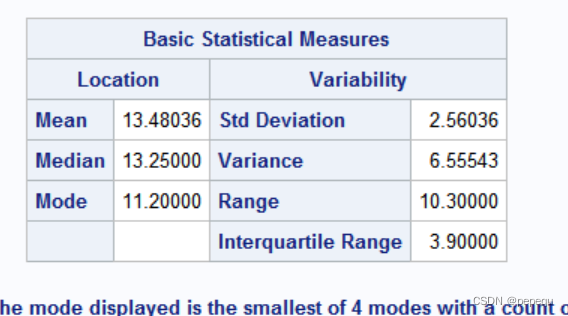
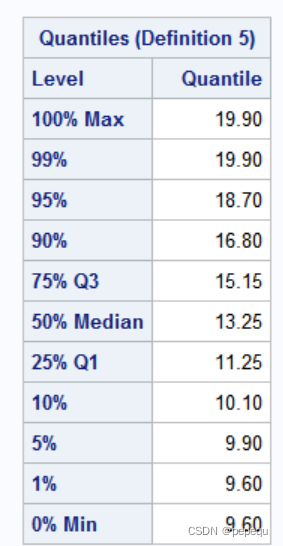
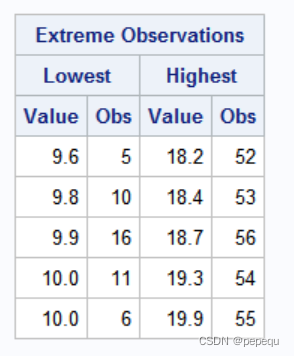
1. univariate过程
计算数字特征及分位数,并作正态性检验
proc univariate data = mylib.rate;
var rate;/*分析对象*/
proc univariate plot normal;
2.mean过程
PROC MEAN options;
PROC MEANS 过程必需语句.“options”主要包括
①DATA = SAS data set:要分析的 SAS 数据集名称.
②关键词:主要有
N — 观测值个数 MEAN — 均值
STD — 标准差 VAR — 方差
MIN — 最小值 MAX — 最大值
RANGE — 极差 SKEWNESS —偏度
KURTOSIS — 峰度
(2)VAR variables;指出要计算的变量名称
PROC MEAN data=
3 CORR过程
计算协方差、相关系数
PROC CORR options;
“options”主要包括:
① DATA = SAS data set
② PEARSON:输出Pearson相关矩阵.
③ SPEARMAN:输出Spearman相关矩阵.
④ COV:计算协方差矩阵.
(2) Var variables;
指出要计算相关矩阵或协方差矩阵的变量名称.
PROC CORR options;
VAR variables;
三、绘图
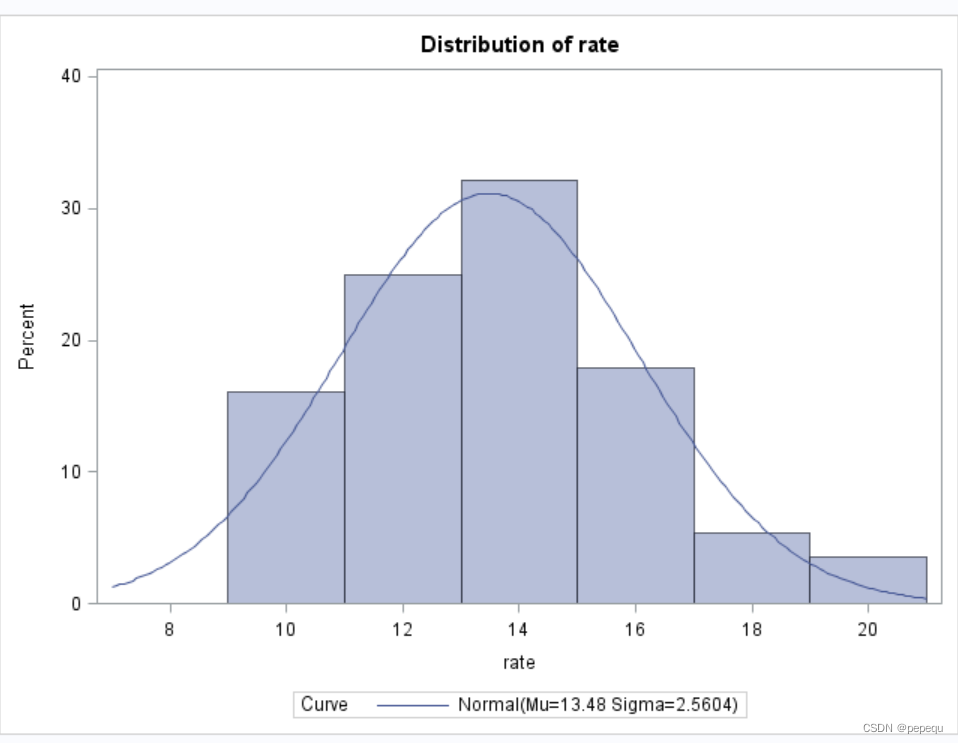
1.直方图、经验分布函数图、QQ图
1)直方图
PROC CAPABILITY options;
“options”主要包含:
① DATA = SAS data set.
② NOPRINT:取消描述性统计量输出
2) HISTOGTAM variable/options;
“variable”给定作直方图的变量.
“options”中包括:
NORMAL、LOGNORMAL、GAMMA、WEIBULL、BETA、EXPOENTIAL:此选项要求拟合指定分布的密度曲线.
2)经验分布曲线
语句形式 PROC CAPABILITY options;
CDFPLOT variable/options;
其中第2句中“options”部分给拟合的分布曲线的分布名称,与(1)相同.
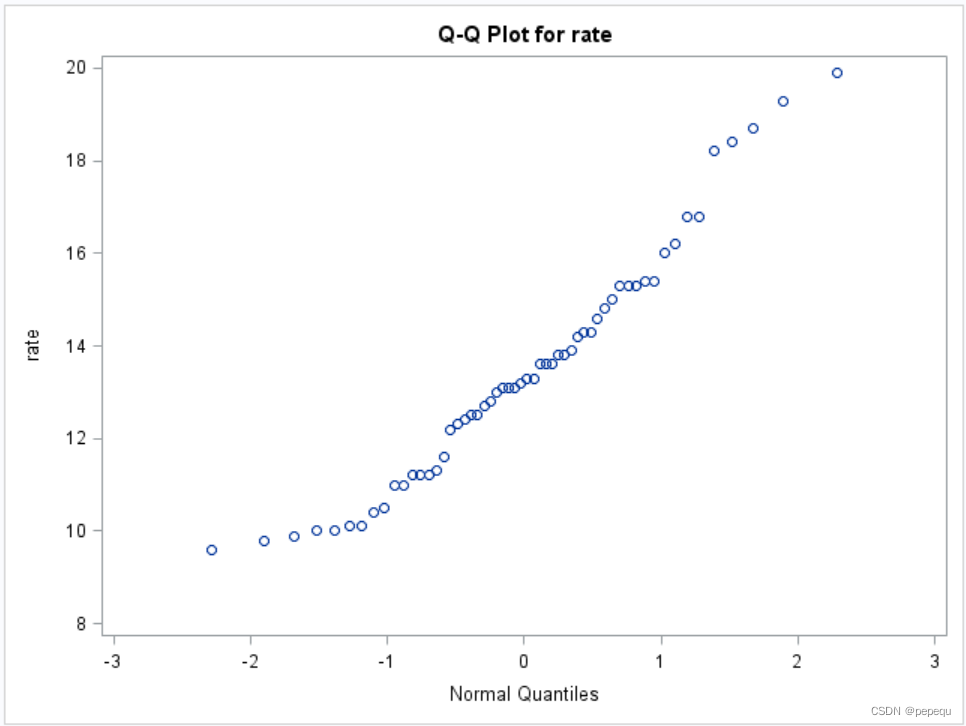
3)QQ图
语句形式 PROC CAPABILITY options;
QQPLOT variable/options;
其中第2句中“options”部分指定作 QQ 图的分布名称.
proc capability graphics;
histogram rate/normal;/*直方图,/normal表示绘制正态分布曲线*/
cdfplot rate/normal;/*经验分布图*/
qqplot;

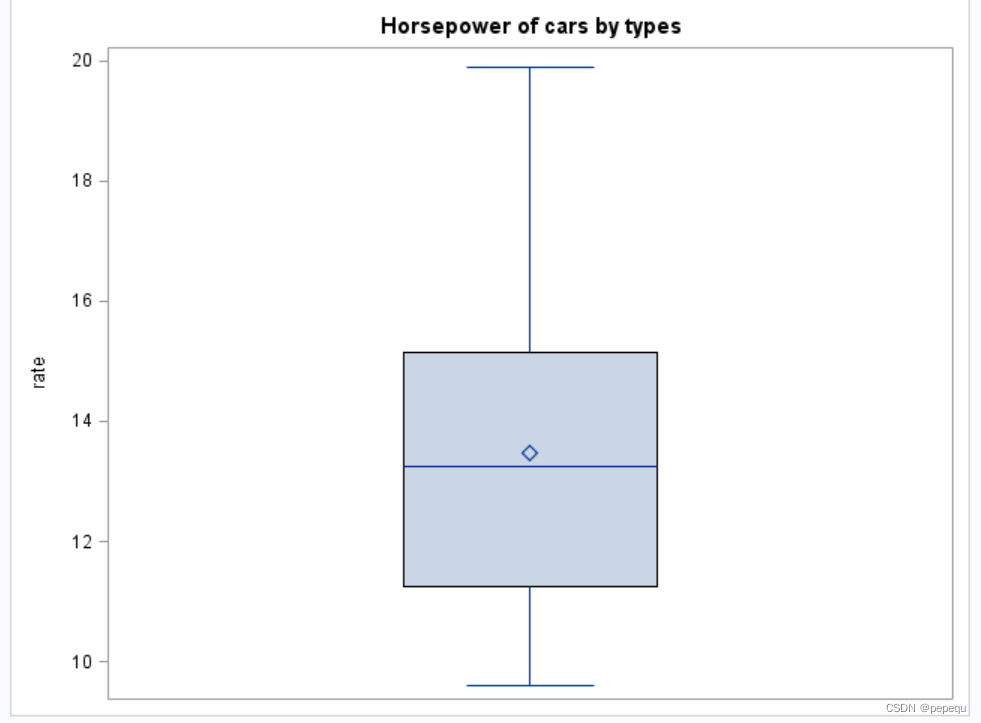
2.绘制箱线图
绘制每个type对应的箱线图:
PROC SGPLOT DATA=WORK.IMPORT;
VBOX rate
/ category = type;
RUN;
绘制一个type的箱线图:
PROC SGPLOT DATA=WORK.IMPORT;
VBOX rate
/ category = year;
RUN;
四、非参数秩检验
1.NPARIWAY 过程
(1) PROC NPAR1WAY options;
“options”主要包括:
① DATA = SAS data set.
② WILCOXON:进行 Wilcoxon 秩和检验.当有两种处理方法时,即 Wilcoxon 秩和检验;当多于两种处理方法时,即进行 Kruskall-Wallis检验.
③ EDF;进行基于样本检验分布函数的非参数检验,包括 Smirnov 检验.
(2) CLASS variable;
指定数据集中各处理方法的分类变量名称.
(3) EXACT;
要求对(1)中选择的检验方法作精确检验,给出检验的精确p值.
(4) VAR variables;
指定要分析处理的变量名称.
PROC NPAR1WAY options;
CLASS variable;
EXACT;
VAR variables;
proc npar1way data=TUMOR wilcoxon;/*TUMOR:数据集 wilcoxon:检验方法*/
class GROUP; /*分类标签*/
var Rate;/*进行秩和检验的变量值*/
exact wilcoxon;
title "wilcoxon";
run;
五、聚类分析
1.cluster过程
(1) PROC CLUSTER options;
“options”包含:
1) DATA=SAS data set,当数据集是距离矩阵时,加“(TPPE=DISTANCE)”.
2) OUTTREE=SAS data set:用于画谱系图的输出数据集.
3) METHOD=name.“name”主要有
SINGLE— 最短距离法
COM— 最长距离法
AVERAGE— 类平均法
CEN— 重心法
4) NOSQUARE:在 MWETHOD=AVERAGE 等时,阻止将输入距离平方.
5) NONORM:阻止将距离规范化
(2) VAR variables;
列出聚类分析的变量名称.
(3) ID variable;
表示各变量的名称.
PROC CLUSTER options;
VAR variables
ID variable;
画谱系图过程
“options”可包含:
① HORIZONTAL:画水平谱系图.
② SPACES=m:各ID变量的间隔单位,m是正整数.
③ NCLSTERS=m:指定分类个数.
④ OUT=SAS data set:输出分类结果.
PROC TREE options;
ID variable;
proc cluster data=data_1 method=average outtree=tree standard nonorm rsquare ccc;
/*其中,standard表示将原始数据标准化,nonorm表示不将类间距离进行标准化;*/
var cha chb chc chd che chf chg chh;
id name;
run;
2.Fastclus过程
(1) PROC FASTCLUS options.“options”主要包括:
① DATA=SAS data set.
② MAXC=n:指定最大分类个数.
③ OUT=SAS data set:输出 SAS 数据集.
④ CLUSTER=name:给出分类名称.
⑤ LIST:列出所有观测的分类.
⑥ LEAST=m:表明用 准则进行聚类. 是绝对距离 LEAST=MAX 是Chebyshev距离.
(2)“VAR variables”和“ID Variable”语句与 PROC CLUSTER 过程相应语句用法相同.
PROC FASTCLUS options;
VAR variables;
ID variable;
PROC fastclus data=data_1 maxc=6 drift list;
var cha chb chc chd che chf chg chh; /*变量*/
id name;
RUN;
六、主成分分析和因子分析
1.主成分分析
(1) PROC PRINCOMP options;
“options”主要包括:
① DATA = SAS data set:
② OUT = SAS data set:输出的 SAS 数据集,包含原始数据及各主成分得分.
③ COV:从协方差矩阵出发作主成分分析
④ N=n:指定在计算的主成分个数n.
(2) VAR variables;
列出参与主成分分析的变量名称.
PROC PRINCOMP options;
VAR variables;
2.因子分析
(1) PROC FACTOR options;
“options”主要包括
① DATA=SAS data set 当输入数据集是相关矩阵时,加“(type=Corr)”;输入协方差矩阵时,加“(type=Cov)”.
② OUT=SAS data set:输出的 SAS 数据集.
③ METHOD=name.“name”可取为:
PRIN— 主分量法 ML— 极大似然法
PTINIT— 迭代主因子分析 ULS— 最小二乘因子分析
④ NFACTORS=n:分析因子数
⑤ ROTATE=name.“name”可取为
VARIMAX— 方差最大旋转.
PROC FACTOR options;
VAR variables;
proc factor data=rank method=principal rotate=varimax /*factor 表示调用因子分析模块*/
percent=0.8
score outstat=ex1;
var cha chb chc chd che chf chg chh;
run;
proc score data=rank score=ex1 out=ex2;
var cha chb chc chd che chf chg chh;
run;
七、回归分析
1.REG过程
(1) PROC REG options;
“options”包含“DATA=SAS data set”.
(2) MODEL dependent=regressors/options;
“MODEL”之后,指出因变量(denpendent).自变量(regressors)一个或多个.“options”部分主要包括:
1)模型选择方法语句: SELECTION = name.
“name”可选:
① FORWARD:向前选择法
② BACLWARD:向后删除法
③ STEPWISE:逐步回归法
2)对模型细节的选项
NOINT:拟合过原点的回归方程
3)对估计细节内容选择
① CORRB:打印估计参数的相关矩阵
② COVB:打印估计参数的协方差矩阵
③ P:打印拟合值
④ R:打印残差
(3) ID = variable; 指定次序变量.
(4)OUTPUT OUT = SAS data set keyword = name…;
“keyword = name…”部分可选择
P = name, P— 因变量拟合值
R = name, R— 残差
STUDENT = name, STUDENT — 标准化残差
L95 = name, L95— 95%置信区间的下限
U95 = name, U95— 95%置信区间的上限.
PROC REG options;
MODEL dependent=regressors/options;
ID variable;
OUTPUT OUT=SAS data set keyword=name…;
PROC REG data = QS2 PLOTS(ONLY) = (DIAGNOSTICS FITPLOT);
model score = y1 y2 y3 y4 y5 /r clm cli dw;
title 'Results of Regression Analysis';
run;
2.Logist过程
PROC LOGISTIC options;
MODEL response=regressors/options;
OUTPUT OUT=SAS data set keyword=name--/options;
八、数值计算
factor是train6中的变量。
DATA d1;
set WORK.train6;
f1=1*factor1;
f2=1*factor2;
f3=1*factor3;
f4=1*factor4;
score = score;
proc print data=d1;
run;
















 2715
2715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











