







文章目录
词法分析的任务:
从左到右逐个字符地对源程序进行扫描,产生一个个的单词符号,把由字符串组成的源程序改造成单词符号串的中间程序。
执行词法分析的程序称为词法分析器。
一、对于词法分析器的要求
1.词法分析器的功能和输出形式
词法分析器的功能:输入源程序,输出单词符号。
单词符号是一个程序语言的基本语法符号。程序语言的单词符号分类:
(1)关键字(for while)
(2)标识符 (x1 xname)
(3)运算符( + * )
(4)界符 ({ } 😉
(5)常数 (23 “abcdf”)
一个程序语言的关键字、运算符和界符都是确定的。但对于标识符和常数的使用是灵活的。
词法分析器所输出的单词符号形式:
(单词种别,属性值)
单词种别通常用整数编码。
属性值是反映单词符号特性或特征的值。
二、词法分析器的设计
1.输入、预处理
词法分析器的第一步工作是输入源程序文本到一个输入缓冲区中。
这样,词法分析的工作可以直接在这个缓冲区中进行。 在许多情况下,常常把输入串预处理一下 ,目的是为了方便单词符号的识别。
预处理的工作是将源程序中多余的空白符、跳格符、回车符、换行符等编辑性字符以及注释部分剔除掉,并将结果存入扫描缓冲区中。
2.状态转换图
状态转换图是设计词法分析程序的一个好途径。转换图是一张有限的有向图。
结点代表状态,用圆圈表示,状态之间用箭弧连接。
箭弧上的标记代表在射出结点状态下可能出现的输入字符或字符类。
一张转换图只能含有有限个状态,其中一个被认为是初态,可以有一个或多个终态(双圈)。
例如:


三、正规表达式与有限自动机
1.正规式与正规集
对于字母表∑,我们感兴趣的是它的一些特殊字集,即正规集。我们将使用正规式这个概念来表示正规集。下面是正规式和正规集的递归定义:
1)ε和Φ都是∑上的正规式,它们所表示的正规集分别为{ε}和Φ;
2)任何a∈∑,a是∑上的一个正规式,它所表示的正规集为{a};
3)假定U和V都是∑上的正规式,它们所表示的正规集分别记为L(U)和L(V),
那么,(U|V)、(U·V)和(U)也都是正规式。它们所表示的正规集分别为L(U)∪L(V)、L(U)·L(V)(连接积)和(L(U))(闭包)。
仅由有限次使用上述三步骤而得到的表达式才是∑上的正规式。仅由这些正规式所表示的字集才是∑上的正规集。
算符的优先顺序:先“*”,次“·”,后“|”。
正规式的等价性:若两个正规式所表示的正规集相同,则称两者等价。
2.确定的有限自动机(DFA)

一个DFA可用一个矩阵表示,该矩阵的行表示状态,列表示输入字符,矩阵元素表示δ(s, a) 的值。这个矩阵称为状态转换矩阵。

3.非确定的有限自动机(NFA)




NFA与DFA等价



将 NFA M’ 进一步变换成等价的DFA M”


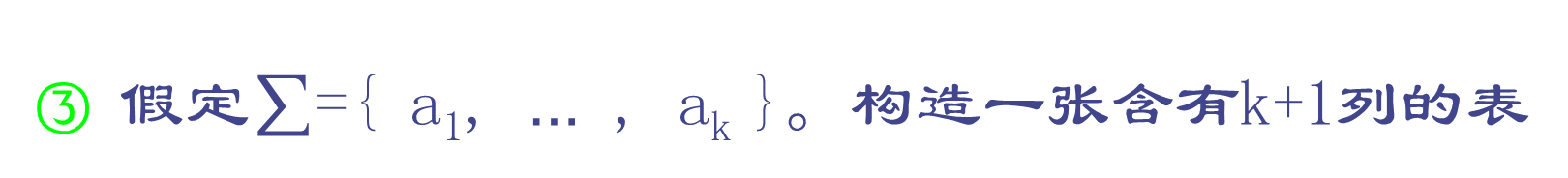


例如:正规式(a|b) * (aa|bb)(a|b) *
求对应的NFA M,并转换出等价的DFA M’。




4.正规文法与有限自动机的等价性
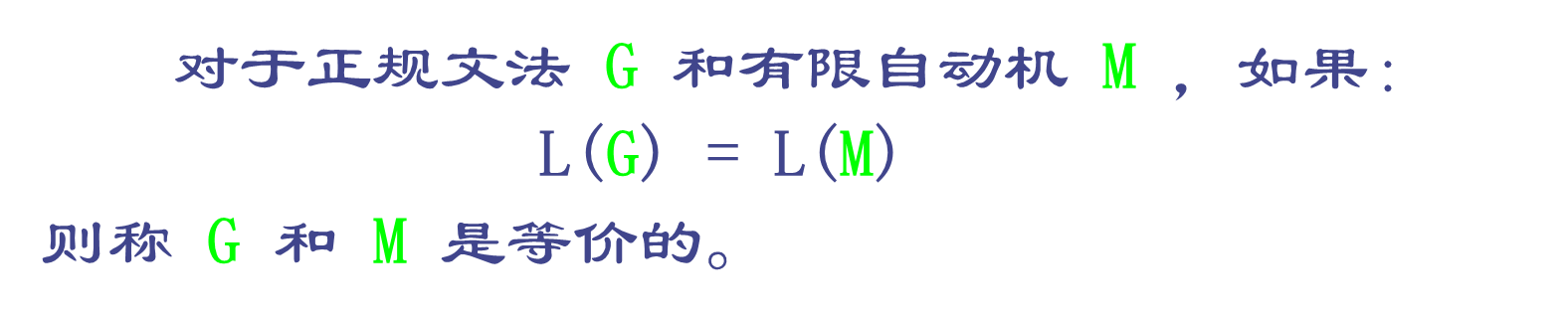







5.正规式与有限自动机的等价性



6.确定有限自动机的化简
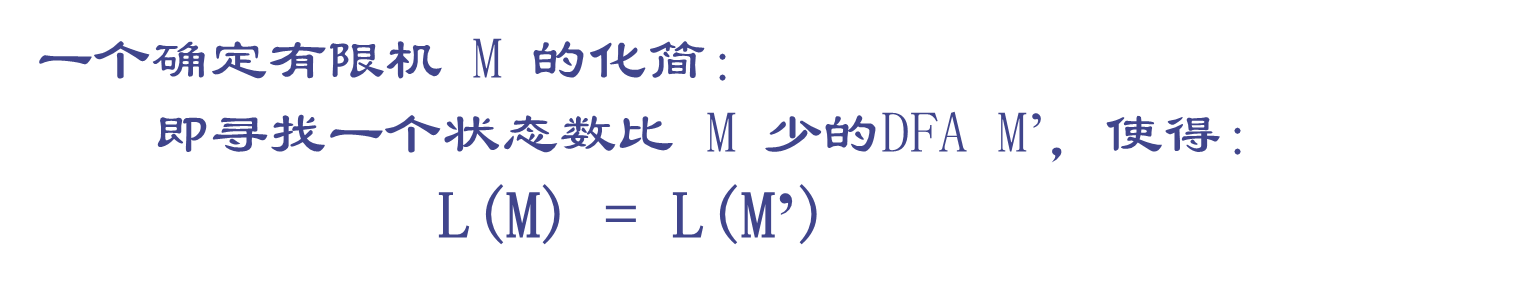




将DFA最小化的方法



四、词法分析器的自动产生
LEX语言:是专门描述词法分析器的语言。
一个LEX源程序主要包括两部分: 正规定义式和识别规则。
(1)∑上的正规定义式为:
d1 → r1
……
di → ri
其中 di 表示不同的名字,
ri 是∑ ∪ {d1 ,…, di-1}上的正规式。
(2)识别规则是如下一串LEX语句:
P1 { A1 }
……
Pm { Am }
其中 Pi 是一个正规式,称为词形,
Ai 是一小段程序代码。
分析器L只能识别具有词形P1,……, Pm的单词符号,它指明在识别出词型为Pi的单词后,词法分析器应采取动作Ai。
分析器L一般是返回Pi的种别编码和属性值。
















 3580
3580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











