






# 导入需要用到的库 import numpy as np import matplotlib.pyplot as plt # 定义存储输入数据(x)和目标数据(y)的数组 x, y = [], [] # 遍历数据集,变量sample对应的正是一个个样本 for sample in open("C:\\Users\\dell\\Desktop\\house_prices.txt", 'r'): _x, _y = sample.split(",") # 将字符串数据转化为浮点数 x.append(float(_x)) y.append(float(_y)) # 读取完数据后,将他们转化为Numpy数组以方便进一步的处理 x, y = np.array(x), np.array(y) # 标准化 x = (x - x.mean()) / x.std() # 将原始数据集以散点的形式画出 plt.figure() plt.scatter(x, y, c="g", s=6) plt.show() # (-2,4)这个区间上取100个点作为画图的基础 x0 = np.linspace(-2, 4, 100) # 利用Numpy的函数定义训练并返回多项式回归模型的次数 # deg参数代表着模型参数中的n,即模型中多项式的次数 # 返回的模型能够根据输入的x(默认是x0),返回预测的y def get_model(deg): return lambda input_x=x0: np.polyval(np.polyfit(x, y ,deg), input_x) # 根据参数n、输入的x,y返回相对应的损失 def get_cost(deg, input_x,input_y): return 0.5 * ((get_model(deg)(input_x) - input_y) ** 2).sum() # 定义测试函数集并根据它进行各种实验 test_set = (1, 4, 10) for d in test_set: # 输出损失 print(get_cost(d, x, y)) # 画出相应的图像 plt.scatter(x, y, c="g", s=20) for d in test_set: plt.plot(x0, get_model(d)(), label="degree = {}".format(d)) # 将横轴和纵轴的范围分别限制在(-2,4)和(10^5,10^6) plt.xlim(-2, 4) plt.ylim(1e5, 1e6) # 调用legend方法使曲线对应的label正确显示 plt.legend() plt.show()
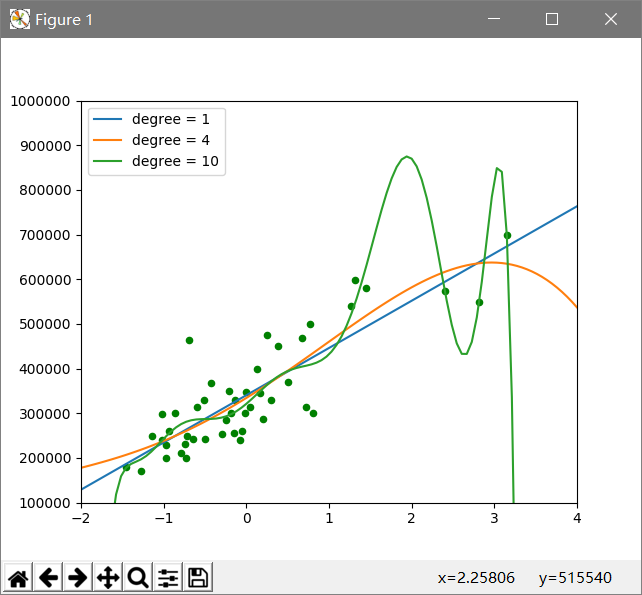
过程:
- 读取数据并转化为numpy数组,后将数据标准化,使得结果准确;
- 设置损失函数进行模型选择;
- 上述设置n为1,4,10分别进行损失函数的计算,并画出相应的图形;
- 由于n=4和10的时候出现了过拟合,为使之后的预测结果准确,选择n=1.
- 数据标准化:
将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
mean()函数的参数:dim=0,按列求平均值,返回的形状是(1,列数);dim=1,按行求平均值,返回的形状是(行数,1),默认不设置dim的时候,返回的是所有元素的平均值。
mean函数中的参数dim代表在第几维度求平均数。
公式为:(X-X_mean)/X_std
将数据按其属性(每列)减去其均值,除以其方差,最后得到的结果是对每个属性/每列来说所有的数据都聚集在0附近,方差值为1。计算时对每个属性/每列分别进行。
方法一:使用sklearn.preprocessing.scale()函数
说明:x_mean(axis=0)计算X每个特征的平均值
x_std(axis=0)计算X每个特征的方差
preprocessing.scale(x)直接标准化X
- plt.scatter()函数
plt.scatter()函数用于生成一个scatter散点图。
matplotlib.pyplot.scatter(x,
y,
s=20,
c='b',
marker='o',
cmap=None,
norm=None,
vmin=None,
vmax=None,
alpha=None,
linewidths=None,
verts=None,
hold=None,
**kwargs)
参数:
- x,y:表示的是shape大小为(n,)的数组,也就是我们即将绘制散点图的数据点,输入数据。
- s:表示的是大小,是一个标量或者是一个shape大小为(n,)的数组,可选,默认20。
- c:表示的是色彩或颜色序列,可选,默认蓝色’b’。但是c不应该是一个单一的RGB数字,也不应该是一个RGBA的序列,因为不便区分。c可以是一个RGB或RGBA二维行数组。
- marker:MarkerStyle,表示的是标记的样式,可选,默认’o’。
- cmap:Colormap,标量或者是一个colormap的名字,cmap仅仅当c是一个浮点数数组的时候才使用。如果没有申明就是image.cmap,可选,默认None。
- norm:Normalize,数据亮度在0-1之间,也是只有c是一个浮点数的数组的时候才使用。如果没有申明,就是默认None。
- vmin,vmax:标量,当norm存在的时候忽略。用来进行亮度数据的归一化,可选,默认None。
- alpha:标量,0-1之间,可选,默认None。
- linewidths:也就是标记点的长度,默认None。
lambda函数:
lambda 函数是匿名的:
所谓匿名函数,通俗地说就是没有名字的函数。lambda函数没有名字。
lambda 函数有输入和输出:
输入是传入到参数列表argument_list的值,输出是根据表达式expression计算得到的值。
lambda 函数拥有自己的命名空间:
不能访问自己参数列表之外或全局命名空间里的参数,只能完成非常简单的功能。
polyval函数:
利用numpy自带的polyfit和polyval函数进行回归分析















 3187
3187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









