







上一篇:没有啦!
下一篇:什么你还不知道招聘信息,小唐来教你——最新2021爬取拉勾网招聘信息(二)
前言
有是小唐的数据分析作业,快别说,这真的历经千辛万苦,我一开始的时候,就真的想着,直接用一个请求然后去前程无忧网爬取,看来网页结构之后,就是两层url,这不对小唐来说just so so,结果,笑死一个是直接给我显示加载中(可以去我的提问那里看),原来是通过js代码读取外部json数据来动态更新的。requests只能获取网页的静态源代码,动态更新的内容取不到。用requests只是获取网页的静态源代码。不会执行页面中的js代码,你用time.sleep()等待是没有用的。只有用selenium 打开真正的浏览器。 才会执行页面中的js代码,用time.sleep()等待才有用。还有就是后面的滑动验证,我直接???,获取数据及其不稳定(主要是他还禁我ip,但是我ip池还不会用呜呜呜呜),后来还是我们的拉勾网香
拉钩网
一、准备我们的库
import re
import xlwt
import requests
from lxml import etree
from xlrd import open_workbook
from xlutils.copy import copy
二、分析分析
对于网站网址的充分了解有利于更加快速的去获取我们所需内容。我们选取的对象是拉钩网(https://www.lagou.com/)进行的数据收集和分析。通过对于网站的分析,本次文章所需的网址结构如下:
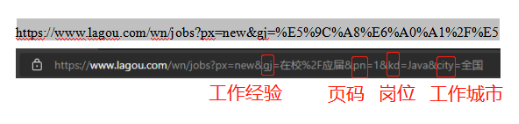
这下就好办了,我们看后面固定的网络结构,页面的话只有我们的pn在改变,其他都不要动
City:代表所要工作的城市
Kd: 代表所要选取的行业职位,将选取C/C++开发工程师、Java开发工程师、Python开发工程师、Web、HTML5开发工程师
Gj: 代表所在页面经验
再来看看我们的网页结构
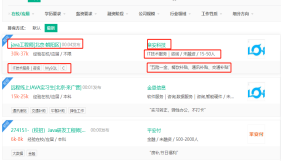
这些就是我们要获取的结构,直接F12,送他回家

小家伙们藏在这里呀。我们可以很清楚的看到,我们的所有的招聘集合是处于class="list__YibNq"之下的,通过Xpath的查找功能可以很方便的帮我们的定位到对应的位置,再在每一条招聘集合中抽丝剥茧,找到对应元素位置,将其整合成数据集。
这样一分析下来,我们的数据获取是不是巨巨巨巨简单!!!,然后在把我们的数据放到Exel里面。把我们的代码加上一点带细节就完成了
三、 代码
import re
import xlwt
import requests
from lxml import etree
from xlrd import open_workbook
from xlutils.copy import copy
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'}
# url_q="https://www.lagou.com/wn/jobs?px=new&gj=%E5%9C%A8%E6%A0%A1%2F%E5%BA%94%E5%B1%8A&pn="
# url_h="&kd=Java&city=%E5%85%A8%E5%9B%BD"
# url_q="https://www.lagou.com/wn/jobs?px=new&gj=%E5%9C%A8%E6%A0%A1%2F%E5%BA%94%E5%B1%8A&pn="
# url_h="&kd=Python&city=%E5%85%A8%E5%9B%BD"
# url_q="https://www.lagou.com/wn/jobs?px=new&gj=%E5%9C%A8%E6%A0%A1%2F%E5%BA%94%E5%B1%8A&pn="
# url_h="&kd=C%2B%2B&city=%E5%85%A8%E5%9B%BD"
# url_q="https://www.lagou.com/wn/jobs?px=new&gj=%E5%9C%A8%E6%A0%A1%2F%E5%BA%94%E5%B1%8A&pn="
# url_h="&kd=html5&city=%E5%85%A8%E5%9B%BD"
url_q="https://www.lagou.com/wn/jobs?px=new&gj=%E5%9C%A8%E6%A0%A1%2F%E5%BA%94%E5%B1%8A&pn="
url_h="&kd=Python&city=%E5%85%A8%E5%9B%BD"
wb_name='Python.xls'
def spider(base_url,headers):
response = requests.get(base_url, headers)#构建服务器
response.encoding = response.apparent_encoding#获取编码格式
response_text = response.text # txt化页面内容
selector = etree.HTML(response_text)#html化
try:
job_list=selector.xpath("//div[@class='list__YibNq']/div")
print(job_list)
try:
for job in job_list:
#岗位
job_name=job.xpath("//div[@class='p-top__1F7CL']/a/text()[1]")
# print(job_name)
#位置
job_add=job.xpath("//div[@class='p-top__1F7CL']/a/text()[2]")
# print(job_add)
#公司名
job_cp=job.xpath("//div[@class='company-name__2-SjF']/a/text()")
# print(job_cp)
#公司现状
job_cpinfo=job.xpath("//div[@class='industry__1HBkr']/text()")
# print(job_cpinfo)
#钱
job_money=job.xpath("//div[@class='p-bom__JlNur']/span/text()")
# print(job_money)
#学历
job_xl=job.xpath("//div[@class='p-bom__JlNur']/text()")
# print(job_xl)
#描述
job_mess=job.xpath("//div[@class='il__3lk85']/text()")
# print(job_mess)
# 需求
job_ir= job.xpath("//div[@class='ir___QwEG']/span/text()")
print("解析成功——————开始存储数据")
save(job_name,job_add,job_cp,job_cpinfo,job_money,job_xl,job_mess,job_ir)
except BaseException as e:
print(e)
print(e.__traceback__.tb_lineno)
print("本条解析失败,跳过")
except BaseException as e:
print(e)
print(e.__traceback__.tb_lineno)
print("本页爬取失败,跳过")
def save(name,add,cp,cpinfo,money,xl,mess,ir):
try:
r_xls = open_workbook(wb_name) # 读取excel文件
except BaseException as e:
print(e)
print(e.__traceback__.tb_lineno)
#没有读取到我们就创建
file = xlwt.Workbook()
sheet1 = file.add_sheet(u'表1', cell_overwrite_ok=True)
sheet1.write(0, 0, "岗位")
sheet1.write(0, 1, "位置")
sheet1.write(0, 2, "公司名")
sheet1.write(0, 3, "公司现状")
sheet1.write(0, 4, "工资")
sheet1.write(0, 5, "学历")
sheet1.write(0, 6, "描述")
sheet1.write(0, 7, "需求")
file.save(wb_name)
try:
r_xls = open_workbook(wb_name)
row = r_xls.sheets()[0].nrows # 获取已有的行数
excel = copy(r_xls) # 将xlrd的对象转化为xlwt的对象
worksheet = excel.get_sheet(0) # 获取要操作的sheet
for i in range(0, len(name)):
worksheet.write(row + i, 0, name[i])
worksheet.write(row + i, 1, add[i])
worksheet.write(row + i, 2, cp[i])
worksheet.write(row + i, 3, cpinfo[i])
worksheet.write(row + i, 4, money[i])
worksheet.write(row + i, 5, xl[i])
worksheet.write(row + i, 6, mess[i])
worksheet.write(row + i, 7, ir[i])
excel.save(wb_name)
print("存储成功")
except BaseException as e:
print(e)
print(e.__traceback__.tb_lineno)
print("存储失败")
def run():
for page in range(1,31):
print("正在解析"+str(page)+"页")
url=url_q+str(page)+url_h
print(url)
spider(url, headers)
run()
四、数据展示

小唐的心路历程
这个是真的,小唐第一次遇到这种网站,之前的51,是真的有被离谱到,给大家看看,我一开始的时候真的以为是显式等待和隐式等待的问题结果。。

就是这个网站或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。在页面上点击右键,右键菜单中选 “查看网页源代码”。
本来以为成功了

结果。。。(禁我ip,欺负我不会用ip池)

不过好在问题都解决了,也获得了自己想要的信息,啊哈哈哈哈,爬出来的那一刻真的超级有成就感!!!















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











