







一、Chatterbox TTS 介绍
Resemble AI 推出了 Chatterbox,这是该公司首个生产级开源文本转语音(TTS)模型。它采用 MIT 许可证,与像 ElevenLabs 这样的封闭源系统相比,在对比评估中更受青睐。Chatterbox 适用于制作模因、视频、游戏或 AI 代理等多种应用场景,它是首个支持情感夸张控制的开源 TTS 模型,能让声音更具特色。
二、关键特点
以下是 Chatterbox TTS 的主要特点:
-
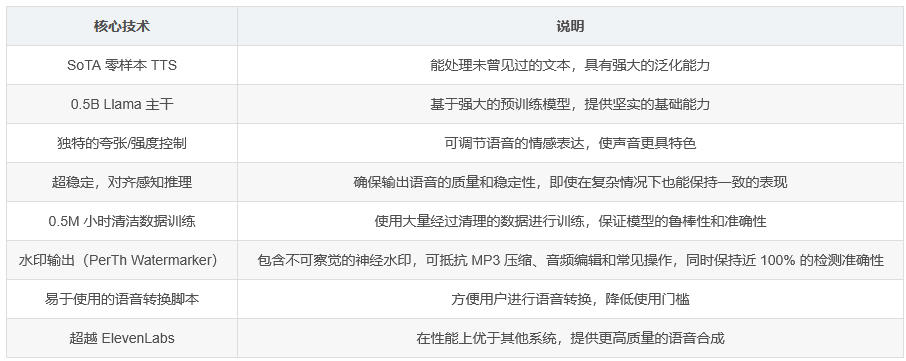
SoTA 零样本 TTS:能够处理未曾见过的文本。
-
0.5B Llama 主干:基于强大的预训练模型。
-
独特的夸张/强度控制:可调节语音的情感表达。
-
超稳定,具有对齐感知推理:确保输出语音的质量和稳定性。
-
在 0.5M 小时的清洁数据上训练:庞大的数据集支持。
-
水印输出:包含感知阈值水印(PerTh Watermarker)。
-
易于使用的语音转换脚本:方便用户进行语音转换。
-
超越 ElevenLabs:在性能上优于其他系统。
三、使用建议
一般使用(TTS 和语音代理):
-
默认设置(夸张度=0.5,cfg=0.5)适用于大多数提示。
-
如果参考说话者语速较快,可将 cfg 降低到约 0.3 以改善节奏。
表达性或戏剧性语音:
-
尝试降低 cfg 值(例如约 0.3)并增加夸张度到 0.7 或更高。
-
较高的夸张度会加快语速;降低 cfg 可以通过更慢、更谨慎的节奏进行补偿。
四、安装与使用
安装:
pip install chatterbox-tts
使用示例
import torchaudio as ta
from chatterbox.tts import ChatterboxTTS
model = ChatterboxTTS.from_pretrained(device="cuda")
text = "Ezreal and Jinx teamed up with Ahri, Yasuo, and Teemo to take down the enemy's Nexus."
wav = model.generate(text)
ta.save("test-1.wav", wav, model.sr)
# 如果要使用不同的声音合成,指定音频提示
AUDIO_PROMPT_PATH = "YOUR_FILE.wav"
wav = model.generate(text, audio_prompt_path=AUDIO_PROMPT_PATH)
ta.save("test-2.wav", wav, model.sr)
可查看 example_tts.py 获取更多示例。
五、致谢与免责声明
-
致谢:Cosyvoice、HiFT-GAN、Llama 3。
-
免责声明:不要使用该模型做有害的事情。提示来自互联网上可自由获取的数据。
六、核心技术汇总表


















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











