




一、概述
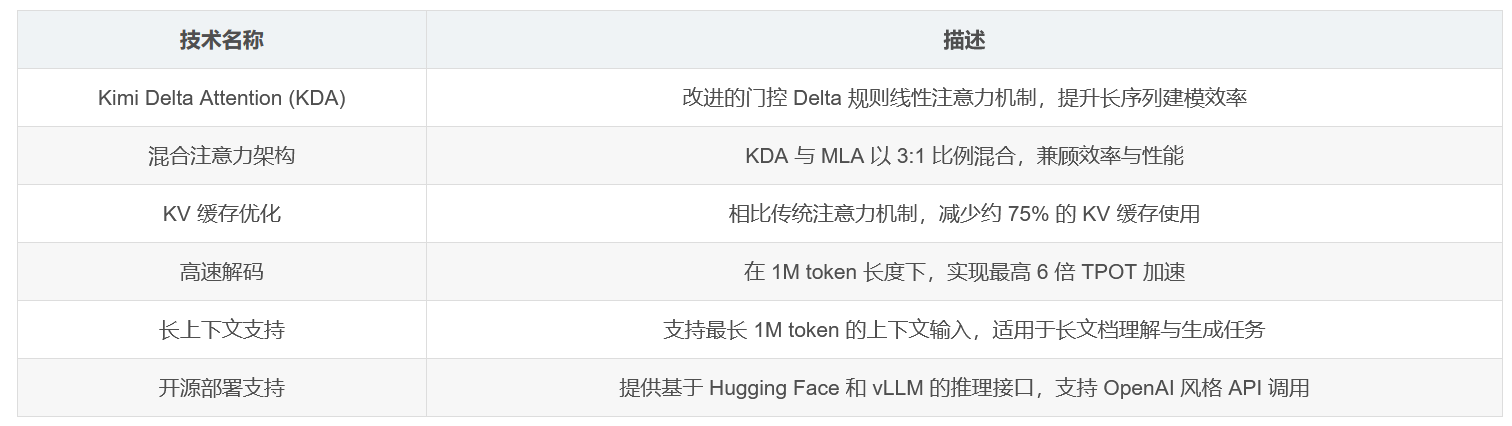
本文介绍了由 Moonshot AI 提出的 Kimi Linear 模型,这是一种混合线性注意力架构,在短文本、长文本以及强化学习(RL)等多种任务场景中,均优于传统的全注意力机制。Kimi Linear 的核心是 Kimi Delta Attention(KDA),一种基于门控 Delta 规则的线性注意力机制,具备更高的效率和更强的长上下文处理能力。
该模型在 1.4T token 上训练,支持最长 1M 的上下文长度,显著降低了 KV 缓存使用量(减少约 75%),并在解码速度上实现了最高 6 倍 的提升。
二、模型架构与核心机制
-
Kimi Delta Attention(KDA)
-
是对 Gated DeltaNet 的改进,采用更精细的门控机制。
-
实现了线性注意力计算,适用于长序列建模。
-
在保持性能的同时,显著降低计算和内存开销。
-
-
混合架构设计
-
采用 3:1 的 KDA 与全局 MLA(Multi-head Latent Attention)混合比例。
-
在减少内存占用的同时,维持甚至超越全注意力模型的性能。
-
-
高效推理与部署
-
支持在 Hugging Face Transformers 和 vLLM 上部署。
-
提供 OpenAI 兼容的 API 接口,便于集成与使用。
-
三、性能表现
-
在 MMLU-Pro(4k 上下文) 上,Kimi Linear 达到 51.0 的性能,与全注意力模型相当。
-
在 RULER(128k 上下文) 上,取得 84.3 的 Pareto 最优性能,并实现 3.98 倍加速。
-
在超长文本(1M token)场景下,Kimi Linear 的 TPOT(Time Per Output Token) 比 MLA 快 6.3 倍。
四、开源与使用
-
模型已开源,包含两个版本:
-
Kimi-Linear-Base:基础模型,适用于通用任务。
-
Kimi-Linear-Instruct:指令微调版本,适用于对话与指令跟随任务。
-
-
提供基于
fla-core的推理支持,兼容transformers和vLLM。 -
示例代码展示了如何加载模型并进行推理。
五、核心技术汇总表
如需进一步了解模型细节或下载使用,可访问 Hugging Face 页面:moonshotai/Kimi-Linear-48B-A3B-Instruct



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











