







1.tensorboard的使用
###代码:
导入需要的包
from tensorboardX import SummaryWriter
创建数据编写器
w=SummaryWriter()
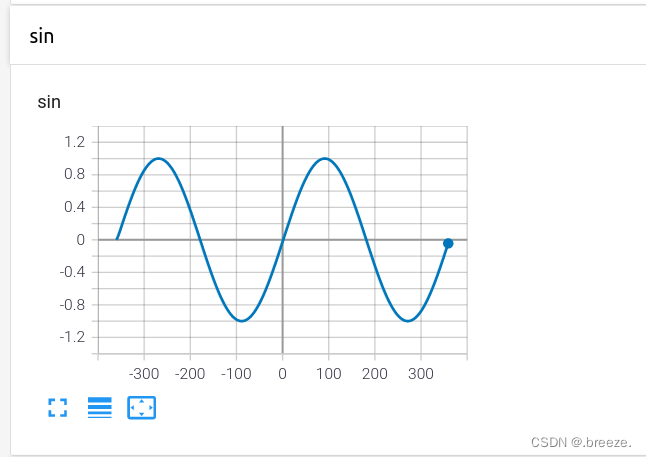
定义需要可视化的函数
这里使用sin函数(import math)
for angle in range(-360,360):
x=angle*math.pi/180
y=math.sin(x)
w.add_scalar("sin",y,angle)
结束之后一定要关掉编写器否则仍会定期更新
w.close()
###命令:
先是运行py代码,随后tensorboard --logdir runs
点开出现的链接即可看到
2.将GAN应用于Atari图像
一个训练GANs生成各种Atari游戏屏幕截图的思路
有两个网络,一个充当判别器,一个充当生成器。两个网络相互竞争,生成器试图伪造数据
使其与原数据集难以区分开,判别器负责检测生成的数据样本
#包装器:图像尺寸210*160-->64*64正方形,图像的颜色平面从最后一个位置移到第一个位置,
以满足卷积层约定,bytes转换为float
需要定义一个函数:得到一组真实的游戏图像作为true数据
#训练思路:
判别器:给真实数据附上true标签,生成器生成的false数据附上假标签开始训练
(记得带上detach()函数防止此次训练的梯度流入生成器模型),计算损失,
做梯度下降....
生成器:将生成器之前生成的假数据应用于判别器模型得到的值附上真标签进行训练,
此次不带detach()函数,训练生成器,向生成可欺骗判别器的样本的方向发展
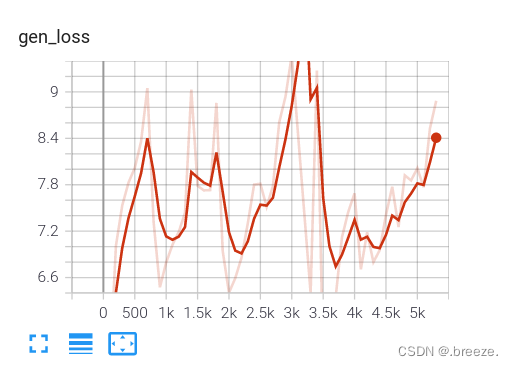
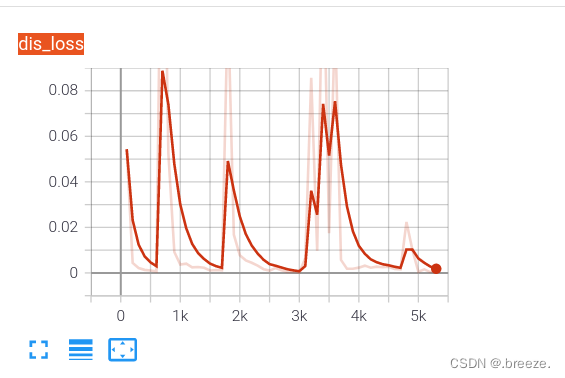
过程中持续记录损失和生成的图像在tensorboard
在cpu上训练很漫长。。。如下是生成器和判别器的loss图,图像还需等待一段时间。
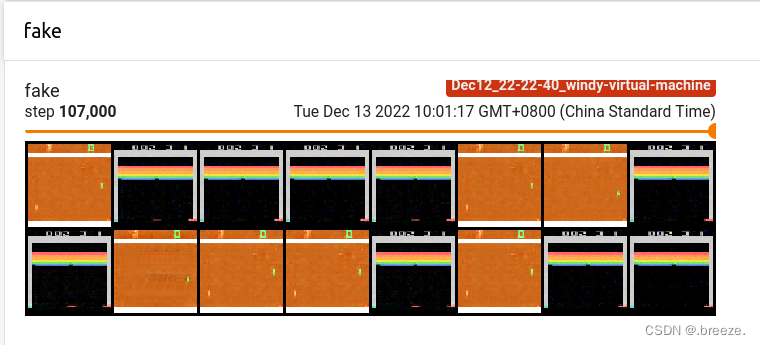
writer.add_image("fake", vutils.make_grid(
gen_output_v.data[:64], normalize=True), iter_no)
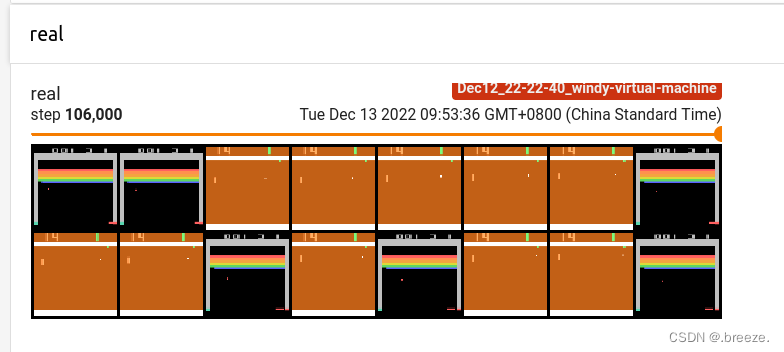
writer.add_image("real", vutils.make_grid(
batch_v.data[:64], normalize=True), iter_no)
以上是将图片加入tensorboard的代码,涉及到两个函数,make_grid和add_image
前者用于制作网格并显示
后者是将图片加入tensorboard
大体上的的思路就是创建engine实例,将之前需要for循环反复运行的过程内容包装成一个函数,然后作为处理函数传入engine实例。其优势还在于:比如希望在每n次iteration的时候将某个指标记录到Tensorboard中,又或者是在每n次iteration时做一些什么特定的动作。都可以通过将想做的事情包装成一个函数传入engine实例。
源代码如下:
#!/usr/bin/env python
import random
import argparse
import cv2
import torch
import torch.nn as nn
import torch.optim as optim
from tensorboardX import SummaryWriter
import torchvision.utils as vutils
import gym
import gym.spaces
import numpy as np
log = gym.logger
log.set_level(gym.logger.INFO)
LATENT_VECTOR_SIZE = 100
DISCR_FILTERS = 64
GENER_FILTERS = 64
BATCH_SIZE = 16
# dimension input image will be rescaled
IMAGE_SIZE = 64
LEARNING_RATE = 0.0001
REPORT_EVERY_ITER = 100
SAVE_IMAGE_EVERY_ITER = 1000
class InputWrapper(gym.ObservationWrapper):
"""
Preprocessing of input numpy array:
1. resize image into predefined size
2. move color channel axis to a first place
"""
def __init__(self, *args):
super(InputWrapper, self).__init__(*args)
assert isinstance(self.observation_space, gym.spaces.Box)
old_space = self.observation_space
self.observation_space = gym.spaces.Box(
self.observation(old_space.low),
self.observation(old_space.high),
dtype=np.float32)
def observation(self, observation):
# resize image
new_obs = cv2.resize(
observation, (IMAGE_SIZE, IMAGE_SIZE))
# transform (210, 160, 3) -> (3, 210, 160)
new_obs = np.moveaxis(new_obs, 2, 0)
return new_obs.astype(np.float32)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
# this pipe converges image into the single number
self.conv_pipe = nn.Sequential(
nn.Conv2d(in_channels=input_shape[0], out_channels=DISCR_FILTERS,
kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=DISCR_FILTERS, out_channels=DISCR_FILTERS*2,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(DISCR_FILTERS*2),
nn.ReLU(),
nn.Conv2d(in_channels=DISCR_FILTERS * 2, out_channels=DISCR_FILTERS * 4,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(DISCR_FILTERS * 4),
nn.ReLU(),
nn.Conv2d(in_channels=DISCR_FILTERS * 4, out_channels=DISCR_FILTERS * 8,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(DISCR_FILTERS * 8),
nn.ReLU(),
nn.Conv2d(in_channels=DISCR_FILTERS * 8, out_channels=1,
kernel_size=4, stride=1, padding=0),
nn.Sigmoid()
)
def forward(self, x):
conv_out = self.conv_pipe(x)
return conv_out.view(-1, 1).squeeze(dim=1)
class Generator(nn.Module):
def __init__(self, output_shape):
super(Generator, self).__init__()
# pipe deconvolves input vector into (3, 64, 64) image
self.pipe = nn.Sequential(
nn.ConvTranspose2d(in_channels=LATENT_VECTOR_SIZE, out_channels=GENER_FILTERS * 8,
kernel_size=4, stride=1, padding=0),
nn.BatchNorm2d(GENER_FILTERS * 8),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=GENER_FILTERS * 8, out_channels=GENER_FILTERS * 4,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(GENER_FILTERS * 4),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=GENER_FILTERS * 4, out_channels=GENER_FILTERS * 2,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(GENER_FILTERS * 2),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=GENER_FILTERS * 2, out_channels=GENER_FILTERS,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(GENER_FILTERS),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=GENER_FILTERS, out_channels=output_shape[0],
kernel_size=4, stride=2, padding=1),
nn.Tanh()
)
def forward(self, x):
return self.pipe(x)
def iterate_batches(envs, batch_size=BATCH_SIZE):
batch = [e.reset() for e in envs]
env_gen = iter(lambda: random.choice(envs), None)
while True:
e = next(env_gen)
obs, reward, is_done, _ = e.step(e.action_space.sample())
if np.mean(obs) > 0.01:
batch.append(obs)
if len(batch) == batch_size:
# Normalising input between -1 to 1
batch_np = np.array(batch, dtype=np.float32) * 2.0 / 255.0 - 1.0
yield torch.tensor(batch_np)
batch.clear()
if is_done:
e.reset()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--cuda", default=False, action='store_true',
help="Enable cuda computation")
args = parser.parse_args()
device = torch.device("cuda" if args.cuda else "cpu")
envs = [
InputWrapper(gym.make(name))
for name in ('Breakout-v0', 'AirRaid-v0', 'Pong-v0')
]
input_shape = envs[0].observation_space.shape
net_discr = Discriminator(input_shape=input_shape).to(device)
net_gener = Generator(output_shape=input_shape).to(device)
objective = nn.BCELoss()
gen_optimizer = optim.Adam(
params=net_gener.parameters(), lr=LEARNING_RATE,
betas=(0.5, 0.999))
dis_optimizer = optim.Adam(
params=net_discr.parameters(), lr=LEARNING_RATE,
betas=(0.5, 0.999))
writer = SummaryWriter()
gen_losses = []
dis_losses = []
iter_no = 0
true_labels_v = torch.ones(BATCH_SIZE, device=device)
fake_labels_v = torch.zeros(BATCH_SIZE, device=device)
for batch_v in iterate_batches(envs):
# fake samples, input is 4D: batch, filters, x, y
gen_input_v = torch.FloatTensor(
BATCH_SIZE, LATENT_VECTOR_SIZE, 1, 1)
gen_input_v.normal_(0, 1)
gen_input_v = gen_input_v.to(device)
batch_v = batch_v.to(device)
gen_output_v = net_gener(gen_input_v)
# train discriminator
dis_optimizer.zero_grad()
dis_output_true_v = net_discr(batch_v)
dis_output_fake_v = net_discr(gen_output_v.detach())
dis_loss = objective(dis_output_true_v, true_labels_v) + \
objective(dis_output_fake_v, fake_labels_v)
dis_loss.backward()
dis_optimizer.step()
dis_losses.append(dis_loss.item())
# train generator
gen_optimizer.zero_grad()
dis_output_v = net_discr(gen_output_v)
gen_loss_v = objective(dis_output_v, true_labels_v)
gen_loss_v.backward()
gen_optimizer.step()
gen_losses.append(gen_loss_v.item())
iter_no += 1
if iter_no % REPORT_EVERY_ITER == 0:
log.info("Iter %d: gen_loss=%.3e, dis_loss=%.3e",
iter_no, np.mean(gen_losses),
np.mean(dis_losses))
writer.add_scalar(
"gen_loss", np.mean(gen_losses), iter_no)
writer.add_scalar(
"dis_loss", np.mean(dis_losses), iter_no)
gen_losses = []
dis_losses = []
if iter_no % SAVE_IMAGE_EVERY_ITER == 0:
writer.add_image("fake", vutils.make_grid(
gen_output_v.data[:64], normalize=True), iter_no)
writer.add_image("real", vutils.make_grid(
batch_v.data[:64], normalize=True), iter_no)
3.PyTorch Ignite
DL训练过程中的主要部分的详尽列表:
数据准备和转换 批次(batch)的生成
计算训练的指标:损失值,精度,FI分数(统计学中用来衡量二分类模型精确度的一种指标)
周期性地测试模型和验证数据集在模型中的效果
模型经过一定迭代达到期待标准
将指标输入Tensorboard等监控工具
超参数比如学习率随着时间进行变化
控制台输出训练过程进度等的信息
这些任务可以用Pytorch库实现但是需要编写大量代码(标准Pytorch太过于底层了,所以需要你手写一遍一遍的相同的代码)
于是Pytorch有多个库可以简化日常任务,(ptlearn,fastai,ignite等)
为了减少DL样板代码数量,可以学习使用Pytorch Ignite库,接下来通过使用此库重写Ttari GAN代码来加深对Ignite的认识:
ignite核心部分为Engine类,这个类遍历数据源,并将处理函数应用于数据批。具体可以看官方文档,https://pytorch.org/ignite
代码如下:
#!/usr/bin/env python
import random
import argparse
import cv2
import torch
import torch.nn as nn
import torch.optim as optim
from ignite.engine import Engine, Events
from ignite.metrics import RunningAverage #ignite metrics 包含与训练过程的性能指标有关的类
from ignite.contrib.handlers import tensorboard_logger as tb_logger #ignite contrib包中导入Tensorboard记录器
import torchvision.utils as vutils
import gym
import gym.spaces
import numpy as np
log = gym.logger
log.set_level(gym.logger.INFO)
LATENT_VECTOR_SIZE = 100
DISCR_FILTERS = 64
GENER_FILTERS = 64
BATCH_SIZE = 16
# dimension input image will be rescaled
IMAGE_SIZE = 64
LEARNING_RATE = 0.0001
REPORT_EVERY_ITER = 100
SAVE_IMAGE_EVERY_ITER = 1000
class InputWrapper(gym.ObservationWrapper):
"""
Preprocessing of input numpy array:
1. resize image into predefined size
2. move color channel axis to a first place
"""
def __init__(self, *args):
super(InputWrapper, self).__init__(*args)
assert isinstance(self.observation_space, gym.spaces.Box)
old_space = self.observation_space
self.observation_space = gym.spaces.Box(self.observation(old_space.low), self.observation(old_space.high),
dtype=np.float32)
def observation(self, observation):
# resize image
new_obs = cv2.resize(observation, (IMAGE_SIZE, IMAGE_SIZE))
# transform (210, 160, 3) -> (3, 210, 160)
new_obs = np.moveaxis(new_obs, 2, 0)
return new_obs.astype(np.float32)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
# this pipe converges image into the single number
self.conv_pipe = nn.Sequential(
nn.Conv2d(in_channels=input_shape[0], out_channels=DISCR_FILTERS,
kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=DISCR_FILTERS, out_channels=DISCR_FILTERS*2,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(DISCR_FILTERS*2),
nn.ReLU(),
nn.Conv2d(in_channels=DISCR_FILTERS * 2, out_channels=DISCR_FILTERS * 4,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(DISCR_FILTERS * 4),
nn.ReLU(),
nn.Conv2d(in_channels=DISCR_FILTERS * 4, out_channels=DISCR_FILTERS * 8,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(DISCR_FILTERS * 8),
nn.ReLU(),
nn.Conv2d(in_channels=DISCR_FILTERS * 8, out_channels=1,
kernel_size=4, stride=1, padding=0),
nn.Sigmoid()
)
def forward(self, x):
conv_out = self.conv_pipe(x)
return conv_out.view(-1, 1).squeeze(dim=1)
class Generator(nn.Module):
def __init__(self, output_shape):
super(Generator, self).__init__()
# pipe deconvolves input vector into (3, 64, 64) image
self.pipe = nn.Sequential(
nn.ConvTranspose2d(in_channels=LATENT_VECTOR_SIZE, out_channels=GENER_FILTERS * 8,
kernel_size=4, stride=1, padding=0),
nn.BatchNorm2d(GENER_FILTERS * 8),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=GENER_FILTERS * 8, out_channels=GENER_FILTERS * 4,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(GENER_FILTERS * 4),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=GENER_FILTERS * 4, out_channels=GENER_FILTERS * 2,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(GENER_FILTERS * 2),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=GENER_FILTERS * 2, out_channels=GENER_FILTERS,
kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(GENER_FILTERS),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=GENER_FILTERS, out_channels=output_shape[0],
kernel_size=4, stride=2, padding=1),
nn.Tanh()
)
def forward(self, x):
return self.pipe(x)
def iterate_batches(envs, batch_size=BATCH_SIZE):
batch = [e.reset() for e in envs]
env_gen = iter(lambda: random.choice(envs), None)
while True: #收集数据集
e = next(env_gen)
obs, reward, is_done, _ = e.step(e.action_space.sample())
if np.mean(obs) > 0.01:
batch.append(obs)
if len(batch) == batch_size:
# Normalising input between -1 to 1
batch_np = np.array(batch, dtype=np.float32) * 2.0 / 255.0 - 1.0
yield torch.tensor(batch_np)
batch.clear()
if is_done:
e.reset()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--cuda", default=False, action='store_true', help="Enable cuda computation")
args = parser.parse_args()
device = torch.device("cuda" if args.cuda else "cpu")
envs = [InputWrapper(gym.make(name)) for name in ('Breakout-v0', 'AirRaid-v0', 'Pong-v0')]
input_shape = envs[0].observation_space.shape
net_discr = Discriminator(input_shape=input_shape).to(device)
net_gener = Generator(output_shape=input_shape).to(device)
objective = nn.BCELoss()
gen_optimizer = optim.Adam(params=net_gener.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
dis_optimizer = optim.Adam(params=net_discr.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
true_labels_v = torch.ones(BATCH_SIZE, device=device)
fake_labels_v = torch.zeros(BATCH_SIZE, device=device)
def process_batch(trainer, batch): #该函数将获取批数据,并用该批数据对判别器和生成器模型进行更新,然后返回想要跟踪的任何数据
gen_input_v = torch.FloatTensor(
BATCH_SIZE, LATENT_VECTOR_SIZE, 1, 1)
gen_input_v.normal_(0, 1)
gen_input_v = gen_input_v.to(device)
batch_v = batch.to(device)
gen_output_v = net_gener(gen_input_v)
# train discriminator
dis_optimizer.zero_grad()
dis_output_true_v = net_discr(batch_v)
dis_output_fake_v = net_discr(gen_output_v.detach())
dis_loss = objective(dis_output_true_v, true_labels_v) + \
objective(dis_output_fake_v, fake_labels_v)
dis_loss.backward()
dis_optimizer.step()
# train generator
gen_optimizer.zero_grad()
dis_output_v = net_discr(gen_output_v)
gen_loss = objective(dis_output_v, true_labels_v)
gen_loss.backward()
gen_optimizer.step()
if trainer.state.iteration % SAVE_IMAGE_EVERY_ITER == 0:
fake_img = vutils.make_grid(
gen_output_v.data[:64], normalize=True)
trainer.tb.writer.add_image(
"fake", fake_img, trainer.state.iteration)
real_img = vutils.make_grid(
batch_v.data[:64], normalize=True)
trainer.tb.writer.add_image(
"real", real_img, trainer.state.iteration)
trainer.tb.writer.flush()
return dis_loss.item(), gen_loss.item()
engine = Engine(process_batch) #与之前的区别在于将需要for循环一定迭代次数的内容包装成了一个函数process_batch,
tb = tb_logger.TensorboardLogger(log_dir=None)
engine.tb = tb
RunningAverage(output_transform=lambda out: out[1]).\ #对应之前代码使用np.mean()完成求均值 这里用RunningAverage转换 是一种平滑时间序列值的办法,在数学上更加正确
attach(engine, "avg_loss_gen")
RunningAverage(output_transform=lambda out: out[0]).\
attach(engine, "avg_loss_dis")
handler = tb_logger.OutputHandler(tag="train",
metric_names=['avg_loss_gen', 'avg_loss_dis'])
tb.attach(engine, log_handler=handler,
event_name=Events.ITERATION_COMPLETED)
@engine.on(Events.ITERATION_COMPLETED) #附加了一个事件处理程序,在每次迭代完成时由Engine调用,该函数会写一行日志,索引是迭代数。
def log_losses(trainer):
if trainer.state.iteration % REPORT_EVERY_ITER == 0:
log.info("%d: gen_loss=%f, dis_loss=%f",
trainer.state.iteration,
trainer.state.metrics['avg_loss_gen'],
trainer.state.metrics['avg_loss_dis'])
engine.run(data=iterate_batches(envs))
源代码github:https://github.com/PacktPublishing/Deep-Reinforcement-Learning-Hands-On-Second-Edition

















 5770
5770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











