






1.求解函数
f
(
x
)
=
0.4
+
s
i
n
c
(
4
x
)
+
1.1
s
i
n
c
(
4
x
+
2
)
+
0.8
s
i
n
c
(
x
−
2
)
+
0.7
s
i
n
c
(
6
x
−
4
)
f(x)=0.4+sinc(4x)+1.1sinc(4x+2)+0.8sinc(x-2)+0.7sinc(6x-4)
f(x)=0.4+sinc(4x)+1.1sinc(4x+2)+0.8sinc(x−2)+0.7sinc(6x−4)
s
i
n
c
(
x
)
=
{
1
,
x
=
0
s
i
n
(
π
x
)
π
x
,
x
≠
0
sinc(x)= \begin{cases} 1, & \text{ } x = 0 \\ \frac{sin(πx)}{πx}, & \text{ } x \neq 0 \end{cases}
sinc(x)={1,πxsin(πx), x=0 x=0
def sinc(x):
x = [1 if item == 0 else math.sin(math.pi * item) / (math.pi * item) for item in x]
x = np.array(x)
return x
def cal_objval(pop):
x = bintodec(pop)
objval = 0.4 + sinc(4*x) + 1.1*sinc(4*x + 2) + 0.8*sinc(x-2) + 0.7*sinc(6*x-4)
return objval
2.遗传算法介绍
遗传算法是一种模拟自然选择和遗传机制的优化算法,是基于达尔文的进化理论和孟德尔的遗传学原理。它通过模拟生物进化的过程,逐步优化出较好的解决方案。遗传算法通常用于解决搜索和优化问题,特别是那些复杂的、高维度的问题,如组合优化、函数优化、机器学习等领域。
遗传算法的基本思想是通过模拟“自然选择”、“遗传”和“突变”等过程,逐代演化出适应环境的个体,从而逐步寻找到问题的最优解或较好的解决方案。其核心步骤包括:
-
初始化种群:随机生成一组初始个体,称之为种群。
-
适应度评估:根据问题的特定评价标准,对每个个体进行适应度评估,确定每个个体的适应度。
-
选择:以某种策略从当前种群中选择适应度较高的个体,作为下一代种群的父代。
-
交叉:通过交叉操作,将选出的父代个体进行染色体交换,生成新的后代个体。
-
突变:对新生个体进行随机变异操作,引入新的遗传信息。
-
重复进化:重复进行选择、交叉和突变等操作,直到满足停止条件。
遗传算法的优点在于它能够处理复杂的搜索空间,并且不依赖于问题的具体形式,因此具有较高的适用性。然而,遗传算法也有一些缺点,比如对参数设置敏感、计算量大等问题。
3.代码的详细实现
import math
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
初始化种群函数initpop:两个参数,popsize值种群规模,binarylength值二进制编码长度。
def initpop(popsize,binarylength):
#生成popsize×binarylength的二维0、1序列
pop = np.random.randint(0,2,(popsize,binarylength))
return pop
# test module
test = initpop(30, 30)
test
array([[1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1,
1, 0, 1, 1, 1, 0, 0, 1],
[0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1,
1, 0, 1, 1, 1, 1, 0, 0],
......
[0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0,
1, 1, 0, 1, 1, 1, 0, 1]])
将二进制编码转换为十进制数(指定定义域内)的函数bintodec:参数ypop为种群参数,因为计算过程中要修改二级制种群中的数值,所以我们拷贝了种群函数进行处理。将16位二进制数转换成十进制数可以直接使用decimal_num = int(binary_num, 2)进行处理,然后将其映射到-2到2的区间,mapped_num = (decimal_num / (2 ** 16 - 1)) * 4 - 2,将转换的十进制除以 2^16-1,再乘以 4 得到值域为 -4 到 4,最后再减去 2 将其映射到 -2 到 2 的范围。
def bintodec(ypop):
pop=ypop.copy() #拷贝种群
[row,col] = pop.shape #得到pop种群的行数、列数
#将二进制数组中每一个位置的值转换位对应的十进制数
for i in range(col):
pop[:,i]=2**(col-1-i)*pop[:,i]
#每一行求和
pop = np.sum(pop,axis=1)
num=[]
#将16位的二进制数映射到-2到2之间的十进制数。
num=pop / 65535 * 4 - 2
#num=(pop / (2 ** 30 - 1)) * 4 - 2
return num
# test module
binary_number = np.array([
[1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0],
[1,0,1,0,1,0,1,0,1,0,1,0,1,0,0,0],
[1,0,1,0,1,0,1,0,1,0,1,1,1,0,1,0],
[1,0,1,0,1,0,1,0,0,1,1,1,1,0,1,0],
[1,0,1,0,1,0,1,0,0,0,1,0,1,0,1,0]
])
n = bintodec(binary_number)
n
array([0.66666667, 0.66654459, 0.66764324, 0.66373693, 0.65885405])
计算种群适应度函数cal_objval:适应度为其对应的函数值,函数值越大,适应度越高。
def sinc(x):
x = [1 if item == 0 else math.sin(math.pi * item) / (math.pi * item) for item in x]
x = np.array(x)
return x
# if x == 0:
# return 1
# else:
# return math.sin(math.pi * x) / (math.pi * x)
def cal_objval(pop):
x = bintodec(pop)
objval = 0.4 + sinc(4*x) + 1.1*sinc(4*x + 2) + 0.8*sinc(x-2) + 0.7*sinc(6*x-4)
return objval
# test module
test2 = sinc(n)
print(test2)
test2 = np.array(test2)
type(test2)
[0.41349667 0.41366394 0.41215854 0.41751122 0.4242022 ]
numpy.ndarray
选择函数selection,参数pop为种群,参数fitval为种群适应度,参数popsize为种群规模。根据其适应度选择个体,适应度高的个体我们多选择一些,来替换掉适应度低的个体(总个体数仍为popsize)。返回新生成的种群。这里在计算 p=fitval/fitval.sum() 时,由于p 数组中可能会出现非常小的负数或零,从而导致无法进行随机选择,所以使用softmax()函数进行了归一化处理。
def selection(pop,fitval,popsize):
prob = np.exp(fitval) / np.sum(np.exp(fitval))
idx = np.random.choice(np.arange(popsize),size=popsize,replace=True,p=prob)
return pop[idx]
# test module
n1 = cal_objval(test)
print(n1)
#n2 = selection(test, n1, 30)
p=n1/n1.sum()
print(p)
[0.18282542 1.15299924 1.09527027 0.64187223 0.45001125 0.79488221
1.08971277 0.67153479 0.91030701 1.32413059 0.59663778 0.34408481
0.4038168 1.40426359 0.60878624 0.73235482 1.35846828 0.65202379
0.09470733 0.29468945 0.17103921 0.52498788 0.58388445 0.50981044
0.35373815 0.57707908 1.36747492 1.25392895 1.28195859 0.8602489 ]
[0.00820304 0.05173293 0.04914274 0.02879961 0.02019117 0.03566489
0.04889339 0.03013052 0.04084378 0.05941128 0.02677003 0.01543845
0.01811851 0.0630067 0.02731511 0.0328594 0.06095195 0.0292551
0.00424934 0.01322217 0.00767421 0.02355523 0.02619781 0.02287425
0.01587157 0.02589247 0.06135606 0.05626146 0.0575191 0.03859777]
# n2 = selection(test, n1, 30)
# n2
交叉函数crossover:参数pop为种群,参数pc为交叉概率。生成同样规格的newpop数组来存储新种群。
交叉规则:我们将其分成15对染色体,相邻的两个染色体为新染色体的父本和母本。每次随机生成一个数,如果生成数落在交叉概率pc外(大于pc)说明不需要进行交叉操作,那么将父本和母本原封不动的拷贝到两个子代个体中。如果生成数落在交叉概率pc内(小于pc)说明需要进行交叉操作,那么我们再随机生成一个0-15的数cpoint,我们将父本中[0:cpoint]和母本中[cpoint+1:py]组合形成第一个子代个体,将母本[0:cpoint]和父本[cpoint+1:py]组合形成子代第二个个体。对于15对染色体重复该操作,生成新的30个个体。
def crossover(pop,pc):
[px,py] = pop.shape
newpop = np.ones((px,py))
for i in range(0,px,2):
if np.random.rand()<pc:
cpoint = int(np.random.rand()*py*10//10)
newpop[i,0:cpoint]=pop[i,0:cpoint]
newpop[i,cpoint:py]=pop[i+1,cpoint:py]
newpop[i+1,0:cpoint]=pop[i+1,0:cpoint]
newpop[i+1,cpoint:py]=pop[i,cpoint:py]
else:
newpop[i,:]=pop[i,:]
newpop[i+1,:]=pop[i+1,:]
return newpop
# test module
n3 = crossover(n2,0.6)
n3
变异函数mutation:参数pop为种群,参数pm为变异概率。
变异规则:对于每一个个体,我们首先生成一个随机数,如果随机数落在变异概率pm外(大于pm),那么就不发生变异。如果随机数落在变异概率pm内(小于pm)说明需要进行变异,我们再随机生成一个0-15的数mpoint,将该个体中mpoint位置的0、1互换,发生变异。
def mutation(pop,pm):
[px,py] = pop.shape
newpop = np.ones((px,py))
for i in range(px):
if(np.random.rand()<pm):
mpoint = int(np.random.rand()*py*10//10)
if mpoint<=0:
mpoint=1
newpop[i,:]=pop[i,:]
if newpop[i,mpoint]==0:
newpop[i,mpoint]=1
else:
newpop[i,mpoint]=0
else:
newpop[i,:]=pop[i,:]
return newpop
mpoint = int(np.random.rand()py10//10)这一行可以用mpoint = np.random.randint(0, 16)来代替。
# test module
# q = int(np.random.rand()*16*10//10)
q = np.random.randint(0, 16)
q
15
# test module
n4 = mutation(n3,0.001)
n4
求最优解函数best:参数pop为种群,参数fitvalue为适应度。选择种群中适应度最高的个体返回其二进制序列bestindividual以及适应度bestfit。
def best(pop,fitvalue):
[px,py]=pop.shape
bestindividual = pop[0,:]
bestfit = fitvalue[0]
for i in range(1,px):
if fitvalue[i]>bestfit:
bestindividual = pop[i,:]
bestfit = fitvalue[i]
return bestindividual,bestfit
GA(遗传算法)参数设定
popsize = 30 #种群规模
binarylength = 16 #二进制编码长度(DNA)
pc = 0.3 #交叉概率
pm = 0.3 #变异概率
iterations = 500 #迭代次数
pop = initpop(popsize,binarylength) #初始化种群
函数图像
# 绘制函数图像
def sinc1(x):
x = [1 if item == 0 else math.sin(math.pi * item) / (math.pi * item) for item in x]
x = np.array(x)
return x
def cal_objval1(x):
objval = 0.4 + sinc1(4*x) + 1.1*sinc1(4*x + 2) + 0.8*sinc1(x-2) + 0.7*sinc1(6*x-4)
return objval
x = np.arange(-2, 2, 0.001)
y = cal_objval1(x)
# 创建图形并绘制折线图
plt.plot(x, y)
# 设置图形标题和坐标轴标签
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文乱码问题
plt.rcParams["axes.unicode_minus"] = False #使一些符号正常显示
plt.title('函数图像')
plt.xlabel("X 轴")
plt.ylabel("Y 轴")
# 显示图形
plt.grid(True)
plt.show()
tt = np.array([np.float64(-0.507179)])
print(cal_objval1(tt))
4.实验结果

[1.60991778]
#进行计算
for i in range(iterations):
#计算当前种群适应度
objval = cal_objval(pop)
fitval = objval
#选择操作
newpop = selection(pop,fitval,popsize)
#交叉操作
newpop = crossover(newpop,pc)
#变异操作
newpop = mutation(newpop,pm)
#更新种群
pop = newpop
#寻找最优解并绘图
[bestindividual,bestfit]=best(pop,fitval)
x1 = bintodec(newpop)
#print(x1)
y1 = cal_objval(newpop)
#print(y1)
x = np.arange(-2, 2, 0.001)
y = cal_objval1(x)
if i==0 or i == 200 or i == 50 or i == 100 or i == 300 or i == 400:
plt.figure()
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文乱码问题
plt.rcParams["axes.unicode_minus"] = False #使一些符号正常显示
plt.plot(x,y)
plt.plot(x1,y1,'*')
plt.title('迭代次数为:%d'%i)
plt.grid(True)






[n]=bestindividual.shape
x2=0
for i in range(n):
x2+=2**(n-1-i)*bestindividual[i]
print("The best X is ",x2 / 65535 * 4 - 2)
print("The best Y is ",bestfit)
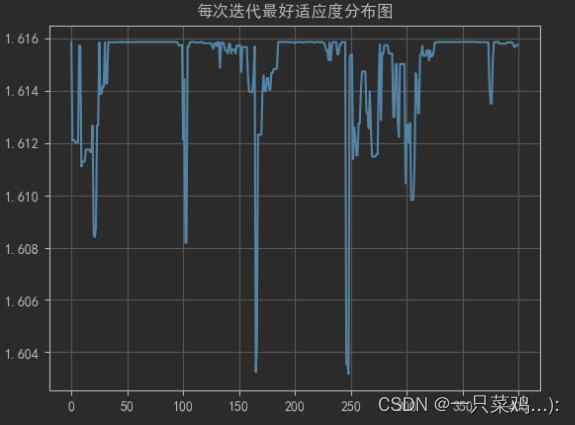
# 每次迭代最好适应度的分布图
x = np.arange(0,400)
y = bestfit_list
# 创建图形并绘制折线图
plt.plot(x, y)
# 设置图形标题和坐标轴标签
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文乱码问题
plt.rcParams["axes.unicode_minus"] = False #使一些符号正常显示
plt.title('每次迭代最好适应度分布图')
# 显示图形
plt.grid(True)
plt.show()















 5192
5192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









