






 本文介绍了Python中的re模块,包括正则表达式的基本语法,如匹配、替换和分组,以及贪婪匹配与非贪婪匹配的概念。重点展示了如何在爬取数据时,如寻找网址,使用re进行内容提取。
本文介绍了Python中的re模块,包括正则表达式的基本语法,如匹配、替换和分组,以及贪婪匹配与非贪婪匹配的概念。重点展示了如何在爬取数据时,如寻找网址,使用re进行内容提取。
前言
正则表达式(Regular Expression,简称regex)是一种强大的文本匹配工具,它在计算机科学和软件开发领域中被广泛应用。re模块是Python中用于操作正则表达式的标准库,提供了丰富的功能来进行字符串匹配、替换和解析等操作。
在计算机编程中,处理文本数据是一个常见的任务,而正则表达式可以帮助我们高效地处理各种复杂的文本匹配需求。通过使用re模块,我们可以轻松地实现对文本数据的搜索、替换、分割等操作,同时也能够有效地处理各种文本格式的解析。
正则表达式的语法虽然看起来有些晦涩,但一旦掌握,就能够成为处理文本数据的利器。re模块提供了丰富的函数和方法,可以让我们灵活地构建和应用各种复杂的正则表达式,从而实现对文本数据的精确操作。
在本文中,我们将探讨re模块的基本用法,包括如何创建正则表达式、如何进行文本匹配和替换、以及如何处理捕获组等高级功能。我们还将介绍一些常见的应用场景,并通过示例代码演示如何利用re模块解决实际的文本处理问题。
正则表达式作为一种强大的文本处理工具,在日常的软件开发工作中具有重要的意义,因此对其进行深入学习和掌握将有助于提升编程技能和解决实际问题的能力。下面就由我带领你们了解re。
一、re的基本语法
1.1基本语法
re.findall(pattern, string): 在字符串中查找所有符合正则表达式的内容,并以列表的形式返回。
re.search(pattern, string): 在字符串中搜索第一个符合正则表达式的内容,并返回包含该内容的匹配对象。
re.match(pattern, string): 从字符串的开头开始匹配正则表达式,并返回包含该内容的匹配对象。
re.sub(pattern, replacement, string): 使用replacement替换字符串中符合正则表达式的内容。
1.2常用模式:
\d: 匹配任意数字。
\w: 匹配任意字母、数字或下划线。
\s: 匹配任意空白字符。
.: 匹配除换行符外的任意字符。
[]: 匹配中括号内的任意一个字符。
^: 匹配字符串的开头。
$: 匹配字符串的结尾。
*: 匹配前面的模式0次或多次。
+: 匹配前面的模式1次或多次。
?: 匹配前面的模式0次或1次。
1.3贪婪匹配与非贪婪匹配:
*、+、?默认为贪婪匹配,即尽可能匹配更多的字符。
在*、+、?后加上?可以将其转变为非贪婪匹配,即尽可能少地匹配字符。
1.4分组:
使用()进行分组,可以方便提取匹配结果中的不同部分。
1.5标题预定义字符集合:
\d:匹配数字,相当于[0-9]。
\D:匹配非数字,相当于[^0-9]。
\w:匹配单词字符,相当于[a-zA-Z0-9_]。
\W:匹配非单词字符,相当于[^a-zA-Z0-9_]。
\s:匹配空白字符,包括空格、制表符、换行符等。
\S:匹配非空白字符。
二、re的在爬取数据上的应用
2.1寻找网址
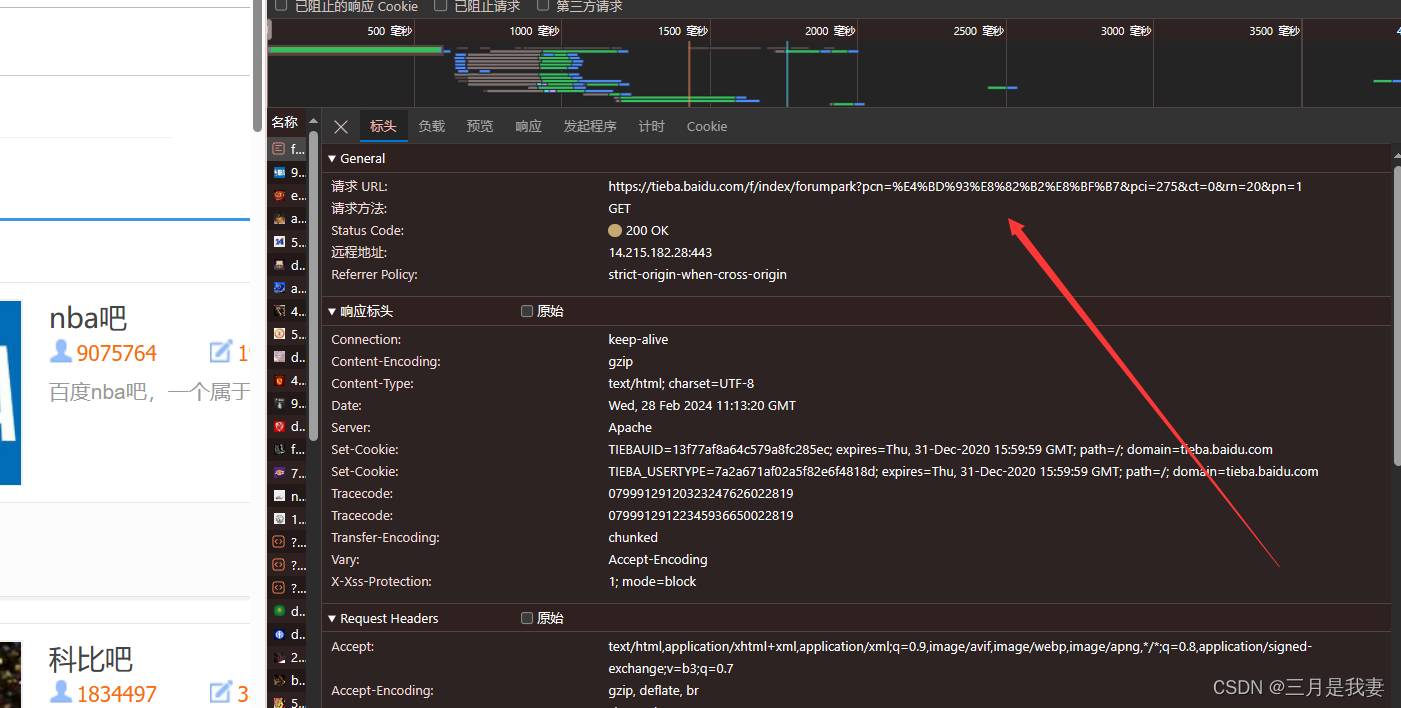
上图红色箭头指向的就是该贴吧的网址。
res = request.urlopen(
'https://tieba.baidu.com/f/index/forumpark?cn=&ci=0&pcn=%E4%BD%93%E8%82%B2%E8%BF%B7&pci=275&ct=&st=new&pn=3')
res = res.read().decode()
print(res)
我们运行这一行代码,就会发现res是一长串字符串,而这一串字符就是,下图所示的内容。
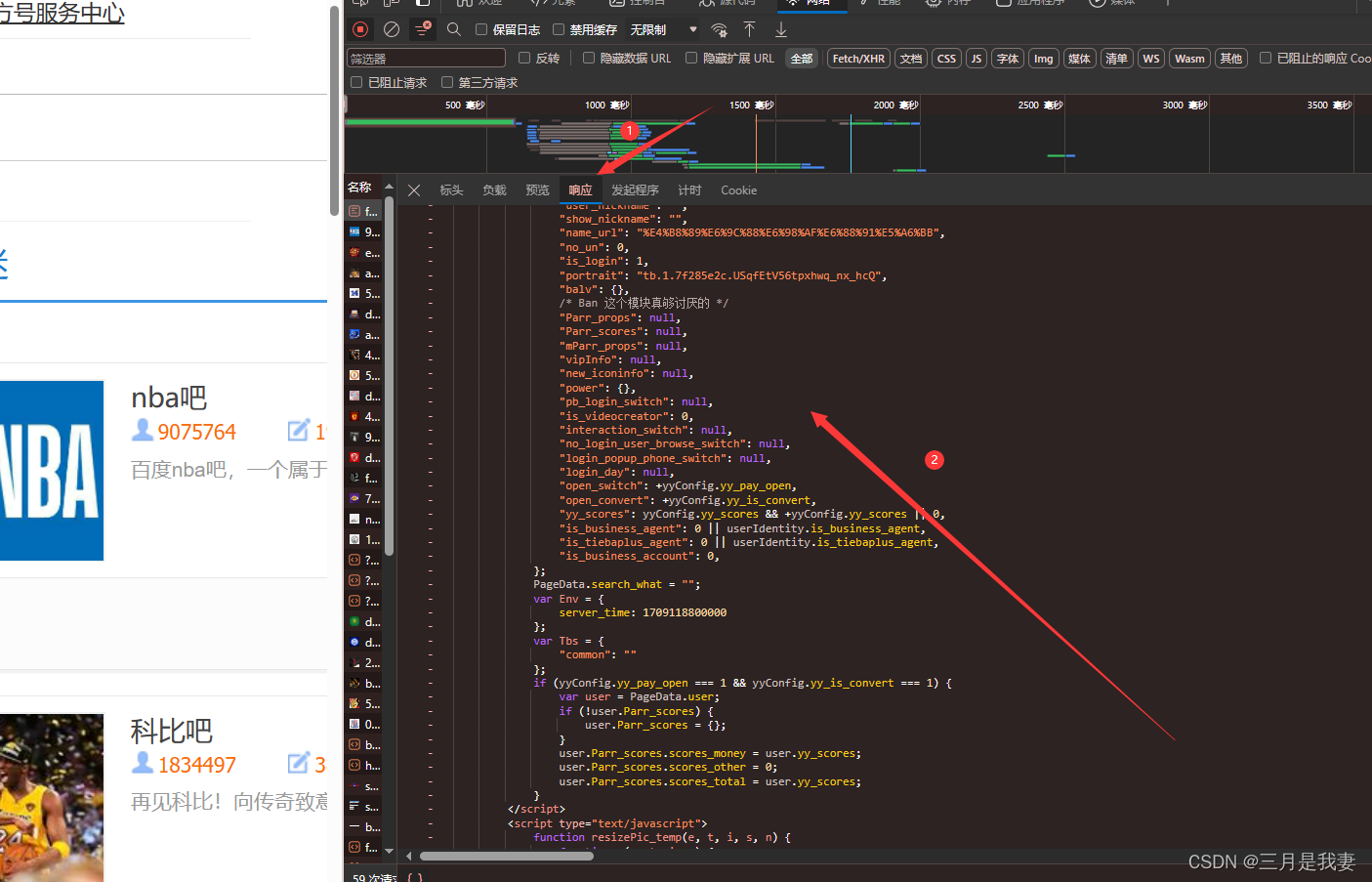 先点击响应,出现的内容就是我们刚才在控制台输出的字符串!
先点击响应,出现的内容就是我们刚才在控制台输出的字符串!
此时,就可以使用re模块来选取我们需要的内容。
import json
import pprint
import re
from urllib import request
datas = [
]
res = request.urlopen(
'https://tieba.baidu.com/f/index/forumpark?cn=&ci=0&pcn=%E4%BD%93%E8%82%B2%E8%BF%B7&pci=275&ct=&st=new&pn=3')
res = res.read().decode()
ba_cintents = re.findall(r'ass="ba_name">(.*?)</p><p class', res)
ba_m_nums = re.findall(r'"ba_m_num">(.*?)</span', res)
ba_p_nums = re.findall(r'"ba_p_num">(.*?)</span', res)
desces = re.findall(r'="ba_desc">(.*?)</p>', res)
for i in range(len(ba_cintents)):
dic = {
"ba_cintent": ba_cintents[i],
"ba_m_num": ba_m_nums[i],
"ba_p_num": ba_p_nums[i],
"desc": desces[i]
}
datas.append(dic)
pprint.pprint(datas, width=30, indent=4, depth=3, compact=True)
运行以上代码就会得到一些想要的特定值!
总结
Re模块是非常重要的一个模块,在今后的爬虫工作或者其他相关工作中都会出现!希望咱们都可以重视re模块的学习!















 850
850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









