






1 introduction
社会意义
问题提出
解决思路基础
利用一些有用的先验来帮助我们解决这个问题,我们已经确定了三个主要的先验。
首先,如果我们的目标是四足哺乳动物,那么人类和动物之间或动物之间的姿势相似性是重要的补充信息。
第二,我们已经有了大规模的动物数据集(例如[35]),带有其他类型的注释,这将有助于理解动物的外貌。
第三,考虑到动物之间的解剖相似性,如果某一类动物的姿态信息具有一定的相似性,则有助于估计其他类动物的姿态。
过渡
在此基础上,我们提出了一种新的方法来利用两个大规模数据集,即姿态标记的人类数据集和盒子标记的动物数据集,以及一个小的姿态标记的动物数据集来促进动物姿态估计。
研究方法的精炼的总结
在我们的方法中,我们从基于人类数据预处理的模型开始,然后设计一个“弱和半监督跨域自适应”(WS-CDA)方案来更好地提取跨域公共特征。
它由三部分组成:特征提取器、域鉴别器和关键点估计器。特征提取器从输入数据中提取特征,基于此,域鉴别器试图区分它们来自哪个域,并且关键点估计器预测关键点。关键点估计器和领域鉴别器被对立地优化,鉴别器鼓励网络适应来自不同领域的训练数据。这改善了跨域共享信息的姿态估计。在WS-CDA之后,模型已经具备了一些动物的姿态知识。但是它在特定的非动画类上仍然表现不佳,因为没有从这个类中获得高级知识。为了改进它,我们提出了一种模型优化机制,称为“基于伪标签的渐进优化”(PPLO)。使用基于当前模型的所选预测输出而生成的伪标签来优化对新物种动物的关键点预测。洞察到不同种类的动物通常有许多相似之处。在推断动物姿势之前提供的姿势,如肢体比例和频繁的手势。并且高置信度的预测有望非常接近地面真实情况,从而将增强的数据带进几乎没有噪声的训练中。采用自定步策略[30,27]来选择伪标签并减轻来自不可靠伪标签的噪声。交替训练方法旨在以渐进的方式鼓励模型优化。我们通过扩展[3]来构建动物姿态数据集,为模型训练和评估提供基础知识。这个数据集中包括五类四足哺乳动物:狗、猫、马、羊、牛。为了更好地融合来自人类数据集和动物数据集的姿态知识,使该数据集的姿态标注格式易于与流行的人类姿态数据集对齐[35]。
结果表明
该方法有效地解决了动物姿态估计问题。具体来说,我们在测试集上实现了65.7 mAP,并且在训练中使用了非常有限的姿势标记动物数据,接近人类姿势估计的最先进的精度水平。更重要的是,我们的方法在跨域动物姿态估计上给出了有希望的结果,它可以在没有任何姿态标记数据的情况下在看不见的动物类上实现50+ mAP,而无需任何姿态标记数据。
2 Related Work
姿态估计简介
姿势估计侧重于预测检测到的物体上的身体关节。传统的姿态估计是在人体样本上进行的[35,14,41,18,48]。有些作品还关注特定身体部位的姿势,比如手[10,29]和脸[38,12,32]。除了这些传统的应用之外,动物姿态估计在许多应用场景中带来了价值,例如形状建模[60]。
姿态估计数据集问题
然而,尽管一些作品研究了动物的面部标志[42,52,47],但对动物的骨骼检测研究很少,面临许多挑战。缺乏大规模的带注释的动物姿势数据集是第一个问题。手动标记数据是劳动密集型的,当考虑多样性时,为所有目标动物类别获得标记良好的数据甚至变得不现实。
数据需求
深度神经模型的兴起[23,31]带来了对数据的渴望,需要开发一个定制的多任务高性能模型。因此,当试图训练一个完全监督的模型时,数据饥渴变得很普遍。
解决办法以及又遇到的问题
为了解决这个问题,提出了许多技术[44,45,55]。因为通常不同的数据集共享相似的特征分布,尤其是当它们的数据是从相近的域中采样时。为了利用这种跨领域的共享知识,领域自适应[49,15]已经在不同的任务上被广泛研究,例如检测[7,26],分类[19,21,17,16],分割[59,54,16]和姿态估计[57,46]。但是在以前关于关键点检测或姿态估计的工作[9,57,53,56]中,源域和目标域面临的域转移比从人类数据集转移到动物或不同动物物种时要小得多。此外,一些额外的信息可能可用于更容易的知识转移,例如视图一致性[57],附加到样本的属性[17]或形态相似性[53,56]。
领域适应变得非常困难,当领域面临严重领域转变,且没有额外信息可用于调整不同领域上的特征表示时,正如在采用域自适应来估计动物姿势时所面临的那样。
在类似的情况下[13,36,49],一个关键的想法是提取和利用更多跨领域的共同特征来帮助完成最终任务。为了达到这个目标,一些著作[36,49]使用权重共享模块进行跨域特征提取。并且提取的特征被对齐[36]以用更相似的分布来表示。此外,对抗性网络[5,50,4]或简单的对抗性损失[49,17]也被用来混淆网络,以更加关注域名变体特征。除了模型设计的改进之外,目标域上的数据扩充也引起了域自适应的关注。从这个角度来看,GAN [20,58,37,33]提出了许多有趣的寺庙[26,25]。但是现有的工作仍然只处理更简单的任务,例如对象检测,并且当风格转换不能很好地模仿域转移时,GANs对数据扩充的帮助较小。另一方面,一些作品也使用“伪标签”进行数据扩充[26,59,28]。在这些工作中,对目标域数据足够自信的预测被视为“伪地面真实”并投入训练。对于这些作品,如何在训练中选择和使用伪标签是至关重要的,有时会为此设计一些特殊的学习策略[59,30,27]。
当涉及到动物姿态估计的域自适应问题时,所有上述方案都显示出一些缺点。与目标检测[26]或分类[17]相比,姿态估计要复杂得多,不同动物姿态估计的方差要大于纹理或风格差异。为此,我们为我们的任务提出了一种新颖的方法,其中一些流行的想法也在改进后投入使用。
- Preliminaries
3.1. Animal Pose Dataset
动物姿态数据集解析
由于可利用的姿态标记动物数据集很少,为了客观地评估动物姿态估计的性能并在弱监督下获得基础知识,我们构建了一个姿态标记动物数据集。幸运的是,来自VOC2011 [11]的姿势标记实例的数据集[2,3]是公开可用的。我们将其注释扩展到五种选定的哺乳动物:狗、猫、马、羊、牛。它有助于将注释格式与流行的人类关键点格式对齐,以便更好地利用人类数据中的知识。在这个数据集中,这5个类别的5,517个实例分布在3,000多幅图像中。注释扩展后,动物实例上最多有20个关键点,包括4个爪子、2个眼睛、2个耳朵、4个肘部、鼻子、喉咙、马肩隆和尾巴,以及我们标记的4个膝盖点。通过在17个关键点内进行选择,这种动物姿势注释可以与流行的COCO [35]数据集中定义的姿势相一致。一些数据集样本如图1所示。要建立这样一个新颖的数据集,只有非常涉及轻微的劳动。动物姿势和人类姿势之间的域转换主要来自于它们骨骼形态的差异,这种差异不能被风格转换模仿为纹理差异。我们定义了18个“骨骼”(两个相邻关节的链接)来帮助解释它,就像COCO数据集中的那些一样。我们计算不同类别平均“骨骼”的相对长度比例。结果如图2所示。一些不同种类的动物比动物和人类的骨骼差异要小得多,这反映了不同领域遭受的领域转移的严重性。
3.2. Problem Statement
对我们研究方法的叙述探讨
在这篇文章中,我们旨在估计动物的姿态配置,尤其是四足哺乳动物。利用大规模人体姿态数据集和少量已标记的动物样本,该问题被转化为一个领域适应问题,我们借助于来自姿态标记领域的知识来估计未见过动物的姿态。这个问题精确地表述如下。姿势标记的数据集被表示为由人类图像和哺乳动物图像组成的D:
其中包含m种动物,人类数据集DHis比动物数据集DA大得多。每个实例I ∈ D都拥有一个姿态真值Y ( I) ∈ Rd×2,它是一个包含有序关键点坐标的矩阵。我们的目标是预测未标记动物样本I ∈ D的潜在关键点。它们的潜在姿势地面真实被表示为Y (I),并且期望用Y ( I)以统一的格式描述。因此,我们将我们的任务表述为训练一个模型:
gθ将看不见的动物物种的图像作为输入,并预测图像上的关键点。因为先验知识是从人类数据或标记的动物物种中获得的,它们与那些未标记的动物物种有明显的域转移。因此,这个任务可以总结为动物姿势估计的跨域适应。
4 Proposed Architecture
对域适应存在问题的提出和解决,对以下分述做个小的总结开头
来自人类数据集和动物数据集的知识都有助于估计动物姿态,但存在数据不平衡问题:姿态标记的动物数据集较小,但与目标域的域偏移较小,而姿态标记的人类数据集较大,但域偏移较严重。在第4.1节中,我们设计了一个“弱和半监督跨域自适应”(WS-CDA)方案来缓解这种缺陷,并更好地学习跨域共享特征。在第4.2节中,我们介绍了设计的“基于伪标签的渐进优化”(PPLO)策略,以提高目标域上的模型性能,该策略引用“伪标签”进行数据扩充。最终的模型通过WS-CDA进行了预训练,并在PPLO的领导下得到提升。
4.1. Weakly- and Semi- supervised cross-domain
adaptation(WS-CDA)(弱监督和半监督跨域自适应)
如果一个模型能够学习到更多的跨域共享特征,那么当面临域转换时,期望它表现得更稳健是合理的。但是单领域数据通常会引导模型学习更多领域特定的和不可移植的特性。基于这样的观察,我们设计了WS-CDA来利用尽可能强的跨域共享特征来估计未知类的姿态。
网络设计如图3所示,输入数据有三个来源。第一个是大规模的姿势标记的人类数据集,第二个是较小的姿势标记的动物数据集,最后一个是未见过类的姿势标记的动物样本。这种设计使用半监督,因为很少动物样本被注释,而weaksupervision,因为很大一部分动物数据只在较低的级别被标记(只有边界框被标记)。WS-CDA中使用的模块有四个:1)所有数据首先馈入一个基于CNN的模块,称为特征提取器,生成特征图;2)所有特征图将进入域鉴别器,该鉴别器区分从哪个域生成的输入特征图;3)来自姿态标记样本的特征图也被转发到关键点估计器,用于姿态估计的监督学习;4)插入域自适应网络以对齐特征表示,用于随后的动物关键点估计。域鉴别器和关键点估计器的损失被设置为对抗性的。由于姿态估计是主要任务,因此域鉴别器用于特征提取过程中的域混淆。通过这种设计,通过利用在域上共享的更好的特征,该模型有望在姿势未标记的样本上表现得更好。
损失函数基于交叉熵损失将域鉴别损失定义为:
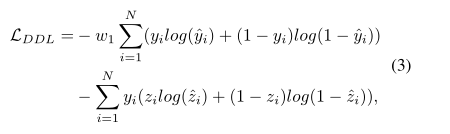
姿势标记的动物和人类样本在监督下一起增强关键点估计器,产生“动物姿势估计损失”(APEL)和“人类姿势估计损失”(HPEL)。姿态估计的总体损失如下:

其中LH和lain分别表示HPEL和APEL的损失函数,通常都是均方误差。w2是减轻数据集体积差距影响的权重因子。考虑到比动物样本投入训练的姿势标记的人类样本多得多,在w2> 1的情况下,模型往往表现得几乎等同于仅在人类样本上训练。
因此,框架的综合优化目标表述为:
当αβ < 0时,域鉴别器和关键点估计器被对立地优化,鼓励域混淆并同时提高姿态估计性能。
4.2. Progressive Pseudo-label-based Optimization
(PPLO)(基于伪标签的渐进优化)
在本节中,我们将讨论旨在利用姿势未标记的动物样本来进一步提高模型性能的策略。直觉是从“基本可靠”模型的粗略估计开始逼近底层标签,并以高置信度选择目标域上的预测进行训练。这些预测是称为[28,26]中介绍的“伪标签”。考虑到模型在不同阶段的可靠度,我们引入了一种自适应交替训练的优化方法。为了方便起见,这些创新被总结为“基于渐进伪标签的优化”(PPLO)。
4.2.1 Joint learning for domain adaptation(用于领域适应的联合学习)
在迁移学习实践中,给定两个领域的基本事实,可以在联合监督方案中执行自适应,该方案被表述为:
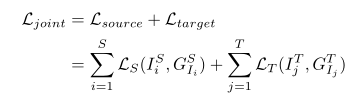
然而,对于无监督的域自适应,这个过程被卡住了,因为在目标域上没有可用的基本事实标签。作为次优选择,引入“伪标签”来填补其空缺。等式6中目标域的损失转化为:

4.2.2 Self-paced selection of pseudo labels(伪标签的自定进度选择)
在训练中涉及伪标签的一个主要挑战是伪标签的正确性无法保证。不可靠的伪标签不会提供更多有用的目标领域知识,反而会误导模型在目标领域表现更差。为了克服这个缺陷,我们提出了一个自定步调的[30,27]策略,选择伪标签进行训练,从简单的案例到困难的案例。这避免了由于冒用伪标签而导致的模型降级。总的来说,当前的模型预测只有在置信度足够高的情况下才会作为伪标签用于训练。这将公式7更新为:
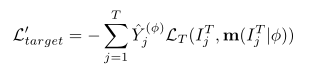
4.2.3 Alternating cross-domain training(交替跨领域训练)
WS-CDA和伪标签的谨慎自定步调的选择使得训练中涉及的伪标签已经可靠得多。然而,伪标签仍然包含比真实地面真实更多的噪声,带来模型降级的风险。为了减轻这种影响,以谨慎的方式联合训练该模型,其中来自源域和目标域的样本被交替输入训练。
如果源域和目标域的数据量接近,这种交替训练近似于对来自两个域的混合数据的训练。然而,在我们的任务中,域遭受巨大的数据量差距,其中姿势标记的动物样本比带有伪标记的目标域样本多得多。在这种情况下,混合数据集上的训练将导致模型从具有更多样本的领域中学习更多,而交替训练缓解了这个问题
算法1解释了一个时期内PPLO的过程。我们提出的基于多域数据的域自适应方案的总体设计如图4所示。
5 Evaluation
我们在本节中评估建议设计的有效性。由于在没有标记太多样本的情况下,很少有现有的方法可用于动物姿态估计,我们试图通过移植一些专注于类似任务的先前工作来建立比较。

5.1. Experiment Settings
多方面综合比较、总结
我们移植了一些流行的多姿态估计框架[14,8,22]来做动物姿态估计进行比较。此外,我们还比较了不同的流行领域适应方法[49,36,26]。
为了公平起见,数据来源仅限于实验。用于训练的姿势标记的人类数据集是完整的COCO2017训练数据集[35],它包含100k+个实例,比构建的姿势标记的动物数据集大得多。我们构建的数据集是姿态标记动物样本的唯一来源,姿态未标记动物样本来自检测任务的COCO2017训练数据集[35]。
除非另有说明,否则默认情况下,所有模型都按照官方发布的代码中的定义来实现。但我们详细解释了所采用的“AlphaPose”模型的配置:I)特征提取器和域自适应网络(DAN)都基于ResNet-101 [23]。ii)将阿瑟模块[24]插入相邻的剩余块之间;iii)关键点估计器由两个DUC [51]层组成。模型出来用置信度(等式9中的C()为每个关键点放置热图,以过滤不可靠的检测到的关键点候选。
训练程序也实现了标准化:AlphaPosebased模型全部通过3个步骤进行培训:I)学习率= 1e-4的培训;ii)增加学习率= 1e-4和干扰(斑块修剪的噪声和抖动)的训练;iii)学习率= 1e-5且干扰增加的训练。模型由RMSprop [43]优化,默认参数在Pytorch [40]中。训练进行到下一阶段或在损失稳定收敛时结束。
最后,除非另有说明,否则超参数必然是一致的。对于WS-CDA参数,我们设置α= 1,β = 500,w1= 1和w2= 10。我们在算法1中将初始值设置为0.9,如果在最近的10个时期内更新了某个伪标签,则在每10个时期后初始值会减少0.01。训练批次大小始终设置为64。
5.2. Evaluation for WS-CDA
评估从实验的角度进行
为了准确评估WS-CDA的有效性,我们设置了启用不同模块或使用不同训练数据的实验组,所有组都使用前面描述的“AlphaPose”框架。详情见表1。我们从构建的动物姿势数据集中选择1,117个实例进行测试。实验结果表明,当仅在人类数据集上训练时,即使该数据集较大且标记良好,该模型在动物测试集上也会遭遇完全失败。在训练中加入一些贴有姿势标签的动物样本后,模型的表现有了飞跃。这种差异显然来自于一个巨大的领域转移,针对动物和人类。此外,即使仅基于人类数据的训练显著失败,但将同一组人类样本与动物样本一起添加到训练中,可以显著提高模型性能。它证明了仍然有许多共同的特征有助于人类和动物的姿态估计,而仅在人类数据上训练会误导模型使用更多人类特有的特征来代替它们。然后,实验表明,领域自适应网络和权重因子减轻了动物数据集和人类数据集之间的体积差距的负面影响。当权重因子启用时,未标记姿势的动物样本会有所帮助,否则,它可能会降低模型的质量。
5.3. Evaluation on unseen species
通过一个具有代表性、且未涉及训练的动物类,运用我们的实验方案来进行评估,得出结果、优势所在
我们设计实验来评估一个看不见的动物类的姿态估计性能。“不可见”是指用于测试的动物样本来自不涉及训练的类别/领域。在五个贴了姿势标签的动物类中,我们简单地设置一个类作为测试集,另外四个类用于训练。在表2中,基线模型仅在动物数据集上训练。对于其他组,模型是使用姿势标记的人体数据集进行训练的。对于“w/o自适应”组,模型在人类数据集上进行预分类,然后在动物样本上进行简单的微调。我们将一些其他的域自适应方法[26,49,36]引入评估中进行比较。对于[58]中的方法,Cyclegan用于使用额外的动物样本进行数据扩增[39]。采用[49]中的方法,不涉及“软标签损失”。对于[36]中的方法,我们使用基于全连接网络的剩余转移网络来代替对立域鉴别器。
实验证明了人类先验知识、WS-CDA和PPLO在对未知动物类进行姿态估计的跨域自适应时的有效性。此外,我们提出的方法优于其他领域适应技术。一个有趣的事实是,基于GAN的方法很难显示出良好的有效性,尽管它们在其他一些任务中取得了令人印象深刻的性能[26]。当用GANs增加训练数据时,我们将其归结为原始姿势标签的失败[58,37,33]。准确地说,GANs仅在变换后保持分割遮罩不变,但关节位置通常会改变,这将使原始姿势标签无效。这种数据扩充在训练中引入了大量标签噪声,并可能导致模型退化。
6 Conclusion
这个结论一般是在上述的叙述中存在的
我们提出了一个新的任务,用域自适应的方法对看不见的动物进行姿态估计。为此,开发了一种新的跨域自适应机制。我们设计了一个“弱监督和半监督跨域自适应”(WS-CDA)方案,将人类和动物数据中的知识传递给看不见的动物。此外,我们设计了一种“基于伪标签的渐进式优化”(PPLO),通过使用“伪标签”对目标域数据进行训练来提高模型性能,为此引入了自定步的“伪标签”选择方法和交替训练方法。为了方便类似的未来任务,我们建立了一个动物姿态数据集,提供了新的先验知识。实验证明了该方案的有效性,在动物姿态估计上达到了人水平的姿态估计精度。















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









