









模块的加载过程三
对“未解决的引用”符号(unresolved symbol)的处理
前文中已多次提到内核模块ELF文件中的“未解决的引用”符号,所谓的“未解决的引用”符号,就是模块的编译工具链在对模块进行链接生成最终的,ko文件时,对于模块中调用的一些函数,最简单的比如printk函数,链接工具无法在该模块的所有目标文件中找到这个函数的具体指令码(因为这个函数是在Linux的内核源代码中实现的,其指令码存在于编译内核生成的目标文件中,模块的链接工具显然不会也不应该去查找内核的目标文件),所以就会将这个符号标记为“未解决的引用”,对它的处理将一直延续到内核模块被加载时(处理的核心是在内核或者是其他内核模块导出的符号中找到这个“未解决的引用”符号,继而找到该符号所在的内存地址,从而最终形成正确的函数调用)。
Linux内核中,一个名为simplify_symbols的函数用来实现这一功能,
/*模块进行符号解析
*经过simplify_symbols函数的调用之后,内核模块符号表中的所有符号就都有了正确的st_value值,
*也即都有了正确的内存地址。
*/
/* Change all symbols so that st_value encodes the pointer directly. */
static int simplify_symbols(struct module *mod, const struct load_info *info)
{
Elf_Shdr *symsec = &info->sechdrs[info->index.sym];
Elf_Sym *sym = (void *)symsec->sh_addr;
unsigned long secbase;
unsigned int i;
int ret = 0;
const struct kernel_symbol *ksym;
/*
*通过一个循环遍历符号表中的所有符号,对于每一个符号都会根据
*该符号的st_shndx值分情况进行处理
*/
for (i = 1; i < symsec->sh_size / sizeof(Elf_Sym); i++) {
const char *name = info->strtab + sym[i].st_name;
switch (sym[i].st_shndx) {
case SHN_COMMON:
/* Ignore common symbols */
if (!strncmp(name, "__gnu_lto", 9))
break;
/* We compiled with -fno-common. These are not
supposed to happen. */
pr_debug("Common symbol: %s\n", name);
pr_warn("%s: please compile with -fno-common\n",
mod->name);
ret = -ENOEXEC;
break;
case SHN_ABS:
/* Don't need to do anything */
pr_debug("Absolute symbol: 0x%08lx\n",
(long)sym[i].st_value);
break;
case SHN_UNDEF:
ksym = resolve_symbol_wait(mod, info, name);
/* Ok if resolved. */
if (ksym && !IS_ERR(ksym)) {
sym[i].st_value = ksym->value;
break;
}
/* Ok if weak. */
if (!ksym && ELF_ST_BIND(sym[i].st_info) == STB_WEAK)
break;
pr_warn("%s: Unknown symbol %s (err %li)\n",
mod->name, name, PTR_ERR(ksym));
ret = PTR_ERR(ksym) ?: -ENOENT;
break;
default:
/* Divert to percpu allocation if a percpu var. */
/*先得到符号所在section的最终内存地址,然后加上它在section中的偏移量,
这样就得到了符号的最终内存地址。*/
if (sym[i].st_shndx == info->index.pcpu)
secbase = (unsigned long)mod_percpu(mod);
else
secbase = info->sechdrs[sym[i].st_shndx].sh_addr;
sym[i].st_value += secbase;
break;
}
}
return ret;
}
简言之,在加载模块的过程中,simplify_symbols函数用来为当前正在加载的模块中所有“未解决的引用”符号产生正确的目标地址。对这段代码的透彻理解需要读者熟悉ELF文件格式规范的相关概念,我们不可能在本书中全面介绍ELF文件格式,但是为了让读者能理解上面的代码,还是从代码的角度出发,将其中所涉及的一些有关ELF文件的概念予以简单介绍。
typedef struct elf64_sym {
Elf64_Word st_name; //st_name是符号名在符号名称字符串表中的索引值
/* Symbol name, index in string tbl */
unsigned char st_info; //st_value是符号所在的内存地址。
/* Type and binding attributes */
unsigned char st_other; /* No defined meaning, 0 */
Elf64_Half st_shndx; //st_shndx是该符号所在的section在Section header table中的索引值。
/* Associated section index */
Elf64_Addr st_value; /* Value of the symbol */
Elf64_Xword st_size; /* Associated symbol size */
} Elf64_Sym;
其中,st_name是符号名在符号名称字符串表中的索引值,详见本章前面的“字符串表(string Table)”部分。st_value是符号所在的内存地址。simplify_symbols函数的唯一功能就是在加载模块时重新生成正确的st_value值。st_shndx是该符号所在的section在Section header table中的索引值。但是该值还有一些特殊的定义。对于符号表,它是ELF文件中的一个section,这个section就是由一系列struct Elf_Sym型元素所构成的一个数组,每个元素代码一个符号。
在对符号表的概念有了基本了解之后,回过头来看看simplify_symbols函数的代码实现。函数首先通过一个循环遍历符号表中的所有符号,对于每一个符号都会根据该符号的st_shndx值分情况进行处理。前面刚刚提到st_shndx,通常情况下,该值表示符号所在section的索引值,为方便叙述,我们称这种符号为一般符号。对于一般符号来说,它的st_value在ELF文件中的值是从其所在section起始处算起的一个偏移量,代码中在switch的default分支下进行处理:先得到符号所在section的最终内存地址,然后加上它在section中的偏移量,这样就得到了符号的最终内存地址。
除了一般符号,还有些符号的st_shndx具有特殊的含义,典型的如SHN_ABS和SHN_UNDEF,前者表明该符号具有绝对地址,因此simplify_symbols函数无须对这种情况予以任何处理,后者表明该符号是一“undefined symbol”,其实就是我们一直说的“未解决的引用”符号。这种情况下simplify_symbols函数会调用resolve_symbol函数来处理该未定义符号,后者会调用find_symbol函数去查找该符号(详细的查找过程见本章前面的"find_symbol函数”部分),如果找到了,就把它在内存中的实际地址赋值给st_valueo如此,经过simplify_symbols函数的调用之后,内核模块符号表中的所有符号就都有了正确的st_value值,也即都有了正确的内存地址。
回头看看图1巧“内核模块导出的符号”,每个“__ksymtab”,“
__ksymtab_gpl”和__ksymtab_gpl_future”section都是由struct kemel_symbol类型的元素所构成的数组。到目前为止,如果仔细考察每个元素的话,会发现其中的value成员依然是内核模块在静态编译时产生的地址。换句话说,根本不是这些符号在模块被加载进系统之后在内存中的实际地址。这显然不是我们想要的效果:想想本节前半部分提到的对模块中“未解决的引用”符号的处理,如果在别的模块中找到的符号其内存地址只是当初该模块在静态链接时填入的地址,那么对该符号的引用必然导致错误的内存访问。这是个很严重的问题。而Linux
内核对这一问题的处理便引出了下一部分的内容—重定位。
重定位
重定位主要用来解决静态链接时的符号引用与动态加载时实际符号地址不一致的问题,上节结束部分提到的模块导出的符号地址,就是一个典型的需要重定位的例子。仔细讨论重定位的内容不是件简单的事情,因为重定位的任务包含很多方面的内容,尤其是跟体系架构相关的一些微妙晦涩的技术细节。
如果模块有用EXPORT_SYMBOL导出的符号,那么模块的编译工具链会为这个模块的ELF文件生成一个独立的特殊section:“.rel_ksymtab",它专门用于对"_ksymtab"section的重定位,称为relocation section。这个section是由下面的数据结构元素形成的一个数组。
typedef struct elf32_rel {
Elf32_Addr r_offset;
Elf32_Word r_info;
} Elf32_Rel;
Linux源码中用于内核模块加载时重定位的代码:
static int apply_relocations(struct module *mod, const struct load_info *info)
{
unsigned int i;
int err = 0;
/* Now do relocations. */
//遍历HDR视图中Section header table中所有的entry。
//对于一个重定位的section,其entry中的sh_type的值为SHT_REL或者
//SHT_RELA,分别对应两种不同的重定位方式,我们拿第一种类型SHT_REL
//来说事。对于sh_type=SHT_REL的section而言,其Section header中的
//sh_info成员指明了被重定位的section在Section header table中的索
//引值,代码中用info变量来表示。
for (i = 1; i < info->hdr->e_shnum; i++) {
unsigned int infosec = info->sechdrs[i].sh_info;
/* Not a valid relocation section? */
if (infosec >= info->hdr->e_shnum)
continue;
/* Don't bother with non-allocated sections */
if (!(info->sechdrs[infosec].sh_flags & SHF_ALLOC))
continue;
if (info->sechdrs[i].sh_type == SHT_REL)
//如果发现了一个sh_type=SHT_REL的section,
//系统就调用apply_relocate函数来执行重定位
err = apply_relocate(info->sechdrs, info->strtab,
info->index.sym, i, mod);//系统就调用apply_relocate函数来执行重定位
else if (info->sechdrs[i].sh_type == SHT_RELA)
err = apply_relocate_add(info->sechdrs, info->strtab,
info->index.sym, i, mod);
if (err < 0)
break;
}
return err;
}
代码用一个for循环来遍历HDR视图中Section header table中所有的entry。对于一个重定位的section,其entry中的sh_type的值为SHT_REL或者SHT_RELA,分别对应两种不同的重定位方式,我们拿第一种类型SHT_REL来说事。对于sh_type=SHT_REL的section而言,其Section header中的sh_info成员指明了被重定位的section在Section header table中的索引值,代码中用info变量来表示。
在遍历的过程中,如果发现了一个sh_type=SHT_REL的section,系统就调用apply_relocate函数来执行重定位,后者是个体系结构相关的函数。总体上,该函数对模块导出符号的重定位原理是,根据重定位元素中的r_offset以及relocation section header entry中的sh_info得到需要修改的导出符号struct kernel_symbol中value所在的内存地址:
int
apply_relocate(Elf32_Shdr *sechdrs, const char *strtab, unsigned int symindex,
unsigned int relindex, struct module *module)
{
Elf32_Shdr *symsec = sechdrs + symindex;
Elf32_Shdr *relsec = sechdrs + relindex;
Elf32_Shdr *dstsec = sechdrs + relsec->sh_info;
Elf32_Rel *rel = (void *)relsec->sh_addr;//entry[i]对应当前正在处理的relocation section
unsigned int i;
for (i = 0; i < relsec->sh_size / sizeof(Elf32_Rel); i++, rel++) {
unsigned long loc;
Elf32_Sym *sym;
const char *symname;
s32 offset;
u32 tmp;
#ifdef CONFIG_THUMB2_KERNEL
u32 upper, lower, sign, j1, j2;
#endif
offset = ELF32_R_SYM(rel->r_info);
if (offset < 0 || offset > (symsec->sh_size / sizeof(Elf32_Sym))) {
pr_err("%s: section %u reloc %u: bad relocation sym offset\n",
module->name, relindex, i);
return -ENOEXEC;
}
sym = ((Elf32_Sym *)symsec->sh_addr) + offset;
symname = strtab + sym->st_name;
if (rel->r_offset < 0 || rel->r_offset > dstsec->sh_size - sizeof(u32)) {
pr_err("%s: section %u reloc %u sym '%s': out of bounds relocation, offset %d size %u\n",
module->name, relindex, i, symname,
rel->r_offset, dstsec->sh_size);
return -ENOEXEC;
}
loc = dstsec->sh_addr + rel->r_offset;
switch (ELF32_R_TYPE(rel->r_info)) {
case R_ARM_NONE:
/* ignore */
break;
case R_ARM_ABS32:
case R_ARM_TARGET1:
*(u32 *)loc += sym->st_value;
break;
case R_ARM_PC24:
case R_ARM_CALL:
case R_ARM_JUMP24:
if (sym->st_value & 3) {
pr_err("%s: section %u reloc %u sym '%s': unsupported interworking call (ARM -> Thumb)\n",
module->name, relindex, i, symname);
return -ENOEXEC;
}
offset = __mem_to_opcode_arm(*(u32 *)loc);
offset = (offset & 0x00ffffff) << 2;
if (offset & 0x02000000)
offset -= 0x04000000;
offset += sym->st_value - loc;
if (offset <= (s32)0xfe000000 ||
offset >= (s32)0x02000000) {
pr_err("%s: section %u reloc %u sym '%s': relocation %u out of range (%#lx -> %#x)\n",
module->name, relindex, i, symname,
ELF32_R_TYPE(rel->r_info), loc,
sym->st_value);
return -ENOEXEC;
}
offset >>= 2;
offset &= 0x00ffffff;
*(u32 *)loc &= __opcode_to_mem_arm(0xff000000);
*(u32 *)loc |= __opcode_to_mem_arm(offset);
break;
case R_ARM_V4BX:
/* Preserve Rm and the condition code. Alter
* other bits to re-code instruction as
* MOV PC,Rm.
*/
*(u32 *)loc &= __opcode_to_mem_arm(0xf000000f);
*(u32 *)loc |= __opcode_to_mem_arm(0x01a0f000);
break;
case R_ARM_PREL31:
offset = *(u32 *)loc + sym->st_value - loc;
*(u32 *)loc = offset & 0x7fffffff;
break;
case R_ARM_MOVW_ABS_NC:
case R_ARM_MOVT_ABS:
offset = tmp = __mem_to_opcode_arm(*(u32 *)loc);
offset = ((offset & 0xf0000) >> 4) | (offset & 0xfff);
offset = (offset ^ 0x8000) - 0x8000;
offset += sym->st_value;
if (ELF32_R_TYPE(rel->r_info) == R_ARM_MOVT_ABS)
offset >>= 16;
tmp &= 0xfff0f000;
tmp |= ((offset & 0xf000) << 4) |
(offset & 0x0fff);
*(u32 *)loc = __opcode_to_mem_arm(tmp);
break;
#ifdef CONFIG_THUMB2_KERNEL
case R_ARM_THM_CALL:
case R_ARM_THM_JUMP24:
/*
* For function symbols, only Thumb addresses are
* allowed (no interworking).
*
* For non-function symbols, the destination
* has no specific ARM/Thumb disposition, so
* the branch is resolved under the assumption
* that interworking is not required.
*/
if (ELF32_ST_TYPE(sym->st_info) == STT_FUNC &&
!(sym->st_value & 1)) {
pr_err("%s: section %u reloc %u sym '%s': unsupported interworking call (Thumb -> ARM)\n",
module->name, relindex, i, symname);
return -ENOEXEC;
}
upper = __mem_to_opcode_thumb16(*(u16 *)loc);
lower = __mem_to_opcode_thumb16(*(u16 *)(loc + 2));
/*
* 25 bit signed address range (Thumb-2 BL and B.W
* instructions):
* S:I1:I2:imm10:imm11:0
* where:
* S = upper[10] = offset[24]
* I1 = ~(J1 ^ S) = offset[23]
* I2 = ~(J2 ^ S) = offset[22]
* imm10 = upper[9:0] = offset[21:12]
* imm11 = lower[10:0] = offset[11:1]
* J1 = lower[13]
* J2 = lower[11]
*/
sign = (upper >> 10) & 1;
j1 = (lower >> 13) & 1;
j2 = (lower >> 11) & 1;
offset = (sign << 24) | ((~(j1 ^ sign) & 1) << 23) |
((~(j2 ^ sign) & 1) << 22) |
((upper & 0x03ff) << 12) |
((lower & 0x07ff) << 1);
if (offset & 0x01000000)
offset -= 0x02000000;
offset += sym->st_value - loc;
if (offset <= (s32)0xff000000 ||
offset >= (s32)0x01000000) {
pr_err("%s: section %u reloc %u sym '%s': relocation %u out of range (%#lx -> %#x)\n",
module->name, relindex, i, symname,
ELF32_R_TYPE(rel->r_info), loc,
sym->st_value);
return -ENOEXEC;
}
sign = (offset >> 24) & 1;
j1 = sign ^ (~(offset >> 23) & 1);
j2 = sign ^ (~(offset >> 22) & 1);
upper = (u16)((upper & 0xf800) | (sign << 10) |
((offset >> 12) & 0x03ff));
lower = (u16)((lower & 0xd000) |
(j1 << 13) | (j2 << 11) |
((offset >> 1) & 0x07ff));
*(u16 *)loc = __opcode_to_mem_thumb16(upper);
*(u16 *)(loc + 2) = __opcode_to_mem_thumb16(lower);
break;
case R_ARM_THM_MOVW_ABS_NC:
case R_ARM_THM_MOVT_ABS:
upper = __mem_to_opcode_thumb16(*(u16 *)loc);
lower = __mem_to_opcode_thumb16(*(u16 *)(loc + 2));
/*
* MOVT/MOVW instructions encoding in Thumb-2:
*
* i = upper[10]
* imm4 = upper[3:0]
* imm3 = lower[14:12]
* imm8 = lower[7:0]
*
* imm16 = imm4:i:imm3:imm8
*/
offset = ((upper & 0x000f) << 12) |
((upper & 0x0400) << 1) |
((lower & 0x7000) >> 4) | (lower & 0x00ff);
offset = (offset ^ 0x8000) - 0x8000;
offset += sym->st_value;
if (ELF32_R_TYPE(rel->r_info) == R_ARM_THM_MOVT_ABS)
offset >>= 16;
upper = (u16)((upper & 0xfbf0) |
((offset & 0xf000) >> 12) |
((offset & 0x0800) >> 1));
lower = (u16)((lower & 0x8f00) |
((offset & 0x0700) << 4) |
(offset & 0x00ff));
*(u16 *)loc = __opcode_to_mem_thumb16(upper);
*(u16 *)(loc + 2) = __opcode_to_mem_thumb16(lower);
break;
#endif
default:
pr_err("%s: unknown relocation: %u\n",
module->name, ELF32_R_TYPE(rel->r_info));
return -ENOEXEC;
}
}
return 0;
}
然后根据重定位元素中的r_info获得需要定位的符号在符号表中的偏移量:
loc = dstsec->sh_addr + rel->r_offset;
因为符号表section的基地址很容易获得,于是就可以获得需要重定位的符号在符号表中对应的Elf32_Sym型元素:
sym = ((Elf32_Sym *)symsec->sh_addr) + offset;
所以,最终导出符号的地址被修改。
这一过程简单地说,就是根据导出符号所在section的relocation section,结合导出符号表section,修改导出符号的地址为在内存中最终的地址值。如此,内核模块导出符号的地址在系统执行完重定位之后被更新为正确的值。
模块传参
#define module_param(name, type, perm) \
module_param_named(name, name, type, perm)
#define module_param_named(name, value, type, perm) \
param_check_##type(name, &(value)); \
module_param_cb(name, ¶m_ops_##type, &value, perm); \
__MODULE_PARM_TYPE(name, #type)
#define module_param_cb(name, ops, arg, perm) \
__module_param_call(MODULE_PARAM_PREFIX, name, ops, arg, perm, -1, 0)
#define __module_param_call(prefix, name, ops, arg, perm, level, flags) \
/* Default value instead of permissions? */ \
static const char __param_str_##name[] = prefix #name; \
static struct kernel_param __moduleparam_const __param_##name \
__used \
__attribute__ ((unused,__section__ ("__param"),aligned(sizeof(void *)))) \
= { __param_str_##name, ops, VERIFY_OCTAL_PERMISSIONS(perm), \
level, flags, { arg } }
可见module_param(a,b,c)在“__param”section中定义了一个类型为struct kernel_param的静态常量。struct kernel_param的定义如下:
struct kernel_param {
const char *name;//name为参数名
const struct kernel_param_ops *ops;
//·perm为对sysfs文件系统中模块参数的访问许可,定义在结构体struct
//kernel_param_ops对象ops中的成员函数(set和get)用来在模块mod的
//args成员和模块的参数section间拷贝数据
u16 perm;
s8 level;
u8 flags;
union {
void *arg;
const struct kparam_string *str;
const struct kparam_array *arr;
};//指向参数的指针
};
__used和unused主要用来避免编译器产生警告信息,因为此处声明的param_a变量在模块源码的其他部分并不会被使用。
param_check_int宏用来检测变量a在module_param宏之前是否定义,因为struct kernel_param中的union联合体只是用来放置模块使用的参数所在地址,如果之前该参数没有定义,就不可能生成&a的值。所以我们的内核模块源代码hello.c在用module_param声明模块参数之前,要首先定义出这些参数。
在上面的宏展开的实例中,可以看到指向参数的指针值被设定为“{&a}”,在模块静态链接期间,&a指令不可能生成其最终的运行期地址,因此模块参数所在的"__param”section需要有一个对应的relocation section“.rel__param”,用来完成对参数指针的重定位,这样才能把命令行中的参数值正确复制到模块的“__param"section中。
下面讨论“insmod demodev.ko dolphin=10 bobcat=5”中携带的参数值如何为模块所用,不看代码也应该可以猜想出命令行中的参数值应该会被复制到模块的参数中,这样模块在开始使用参数dolphin之前,其值己经被insmod命令行中的实际值所改写。图1一7展示了命令行参数传递到模块的“__param”section的全过程:
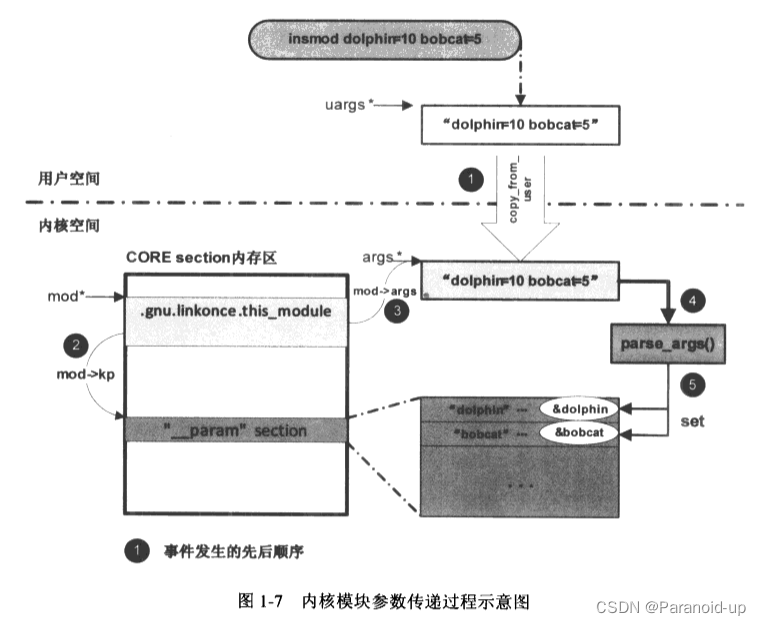
在实际的内核源代码中,sys_init_module函数的最后一个参数const char __user *uargs清楚地表明这是由用户空间传递过来的放置模块参数的内存地址,在insmod一个模块时所携带的参数将以字符串的形式向内核空间传递。然后在load_module函数中,通过strndup_user的调用将用户空间的模块参数复制到内核空间。
args=sfrndup_user(uargs,~0UL>>1);
strndup_user函数内部会调用kmalloc为在内核空间保存模块参数字符串分配一段内存区域,然后通过copy_from_user将模块参数从用户空间复制到内核空间。
接着,在HDR视图的section被搬移到CORE和INIT section之后,load_module通过下面的section。函数调用取得“__param",section在内存空间的最终地址,并记录在struct module的struct kernel_param *kp成员变量中。


模块依赖
实际运行的系统中并不是只加载一个模块,模块可以随时添加进系统,也可以随时被卸载。这些内核模块之间并不是完全相对独立的,比如当一个模块引用到另一个模块中导出的符号时,这两个模块间就建立了依赖关系。因此依赖关系只存在于模块与模块之间,模块与内核之间不构成依赖关系,因为在模块生存期间我们不可能去卸载内核,当然内核也不可能引用到模块导出的符号。内核必须能跟踪模块间的这种依赖关系,只有这样,如果由于存在依赖关系卸载一个模块有可能影响到系统的稳定性,内核才可能采取必要的措施防止这种情况发生。
模块的依赖关系的建立最早发生在当前模块对象mod被加载时,模块加载函数调用resolve_symbol函数来解决其中一些“未解决的引用”符号。如果成功地在其他模块导出的符号中找到了指定的符号,那么resolve_symbol函数会将导出这一“未解决的引用"符号的模块记录在一个变量struct module *owner中,然后调用ref_module(mod,0艹er)在模块mod和owner之间建立依赖关系。ref_module函数在做一些必要的安全性检查之后调用
add_module_usage(mod,owner)在mod和owner模块间建立依赖关系,add_module_usage函数的定义如下:
static int add_module_usage(struct module *a, struct module *b)
{
struct module_use *use;
pr_debug("Allocating new usage for %s.\n", a->name);
use = kmalloc(sizeof(*use), GFP_ATOMIC);//kmalloc分配一struct module_use型内存空间us
if (!use) {
pr_warn("%s: out of memory loading\n", a->name);
return -ENOMEM;
}
/*将use中的source指向mod模块,target指向owner模块,
*同时将use的target-list加入mod中的target_list指向的双向链表,
*将use的sourcelist加入owner中的source_list指向的双向链表。
*/
use->source = a;
use->target = b;
list_add(&use->source_list, &b->source_list);
list_add(&use->target_list, &a->target_list);
return 0;
}
函数首先调用kmalloc分配一struct module_use型内存空间use,然后将use中的source指向mod模块,target指向owner模块,同时将use的target-list加入mod中的target_list指向的双向链表,将use的sourcelist加入owner中的source_list指向的双向链表。图1·8展示了通过struct module_use对象在三个模块间建立依赖关系的技术细节:

图1·8中,模块mod_A和mod_B均依赖于模块owner,mod_A和mod_B之间则没有依赖关系。owner模块先加入系统,它导出一个函数为模块mod_A和mod_B所使用。图中显示modA先于modB加入系统,在mod_A加入系统时,模块加载器创建了use_A对象在mod_A和owner间建立依赖关系。随后mod_B加入了系统,因为它和owner模块间存在
依赖关系,加载器同样创建了useB对象在modB和owner间建立关联。从图中可以看到,use_A对象中的source_list成员己不再指向owner->source_list,而是指向了useB->source_list,后者则和owner->source_list建立了直接的链接关系
如此,mod_A和mod_B模块可以通过遍历其target_list成员知道所依赖的所有模块,而owner模块则可以通过遍历其source_list成员知道所有依赖于自己的模块。
当从系统中卸载一个模块时,系统必须确保没有其他模块依赖于该模块,根据上面的讨论,只要模块结构中的sourceJist是一空链表,就表明没有其他模块依赖于它。
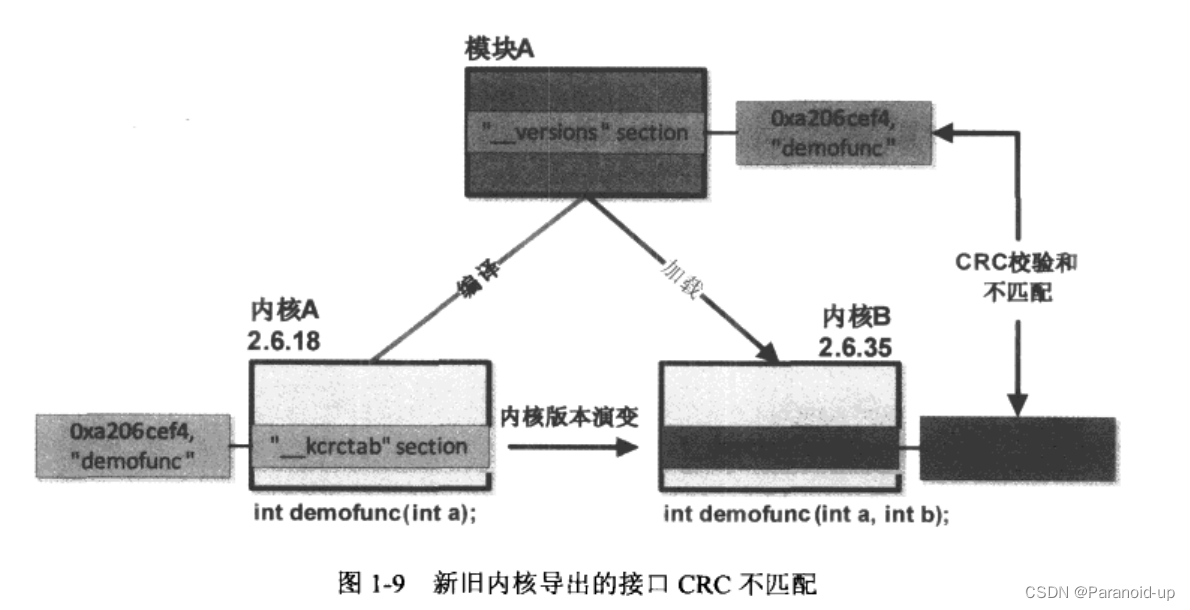
版本控制
版本控制主要用来解决内核模块和内核之间的接口一致性问题。所谓内核模块和内核之间的接口,简单地说是指由内核导出并被内核模块调用的那些符号。产生这种问题的根源在于内核模块和内核作为独立实体各自分开编译,实现重要函数如下:
/*
*在resolve_symbol函数的内部会调用find_symbol来查找该符号。如果成功查找到,
*则函数接下来会调用check_version对这种接口进行校验码的验证
*/
/* Resolve a symbol for this module. I.e. if we find one, record usage. */
static const struct kernel_symbol *resolve_symbol(struct module *mod,
const struct load_info *info,
const char *name,
char ownername[])
{
struct module *owner;
const struct kernel_symbol *sym;
const unsigned long *crc;
int err;
/*
* The module_mutex should not be a heavily contended lock;
* if we get the occasional sleep here, we'll go an extra iteration
* in the wait_event_interruptible(), which is harmless.
*/
sched_annotate_sleep();
mutex_lock(&module_mutex);
sym = find_symbol(name, &owner, &crc,
!(mod->taints & (1 << TAINT_PROPRIETARY_MODULE)), true);
//查找该符号
if (!sym)
goto unlock;
if (!check_version(info->sechdrs, info->index.vers, name, mod, crc,
owner)) {//对这种接口进行校验码的验证
sym = ERR_PTR(-EINVAL);
goto getname;
}
err = ref_module(mod, owner);
if (err) {
sym = ERR_PTR(err);
goto getname;
}
getname:
/* We must make copy under the lock if we failed to get ref. */
strncpy(ownername, module_name(owner), MODULE_NAME_LEN);
unlock:
mutex_unlock(&module_mutex);
return sym;
}
当模块加载时处理“未解决的引用”符号时是如何对接口一致性进行验证的。这种验证是通过在resolve_symbol函数里调用check_version函数完成的,check_version函数的完整定义如下:
static int check_version(Elf_Shdr *sechdrs,
unsigned int versindex,
const char *symname,
struct module *mod,
const unsigned long *crc,
const struct module *crc_owner)
{
unsigned int i, num_versions;
struct modversion_info *versions;
/* Exporting module didn't supply crcs? OK, we're already tainted. */
if (!crc)
return 1;
/* No versions at all? modprobe --force does this. */
if (versindex == 0)
return try_to_force_load(mod, symname) == 0;
versions = (void *) sechdrs[versindex].sh_addr;
num_versions = sechdrs[versindex].sh_size
/ sizeof(struct modversion_info);
/*
*在定义了CONFIG_MODVERSIONS的前提下,check_version用一个for循环在
*“__versions”section中进行遍历,对每一struct modversion_info元素和找
*到的符号名symname进行匹配,如果匹配成功,再进行接口的校验码比较,
*如果校验码相等,说明模块所使用的接口和内核导出的接口是一致的,否则
*产生版本不匹配的错误。
*/
for (i = 0; i < num_versions; i++) {
if (strcmp(versions[i].name, symname) != 0)
continue;
if (versions[i].crc == maybe_relocated(*crc, crc_owner))
return 1;
pr_debug("Found checksum %lX vs module %lX\n",
maybe_relocated(*crc, crc_owner), versions[i].crc);
goto bad_version;
}
pr_warn("%s: no symbol version for %s\n", mod->name, symname);
return 0;
bad_version:
pr_warn("%s: disagrees about version of symbol %s\n",
mod->name, symname);
return 0;
}

















 1675
1675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











