






1.依次选择数据类型

2.数据导入

3.问题分析: 找到指标恶化的位置

4.生成关联系数:权重越高代表影响越大,记录下是那些的关联度较高

5.生成相关矩阵: 矩阵中深蓝色的是相关性较高的特征,要选择性删除,不要都选上进行模型训练,否者可能会出现模型过拟合的问题。


6.机器学习:

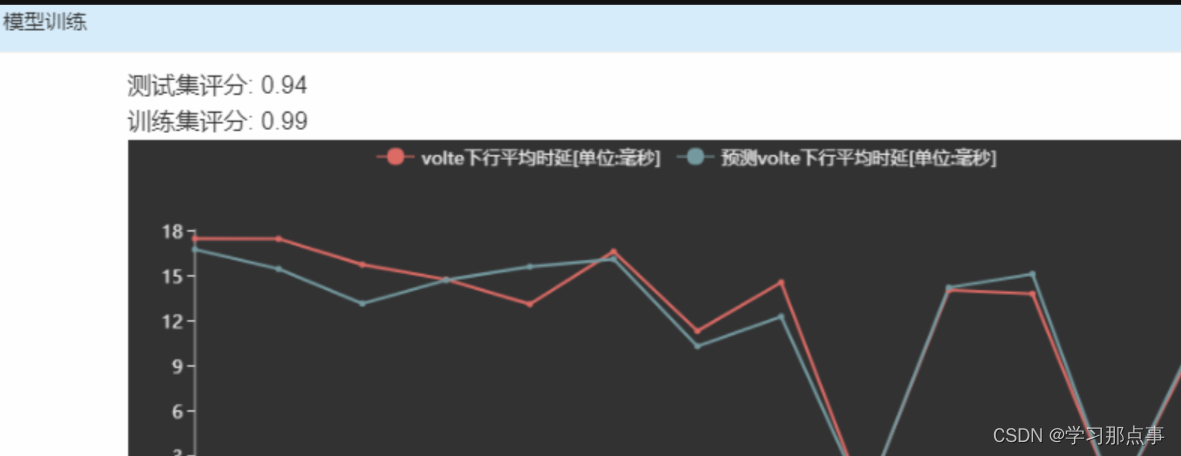
7.模型训练 :切换各自选项,得到测试集评分较高的情况再进行下一步
不可以下一步的情况:

可以下一步的情况:
8.参数调优:找到对应日期与关联性较高的参数,根据其他日期的参数进行对比调整
可以看见曲线得到了优化:
原曲线
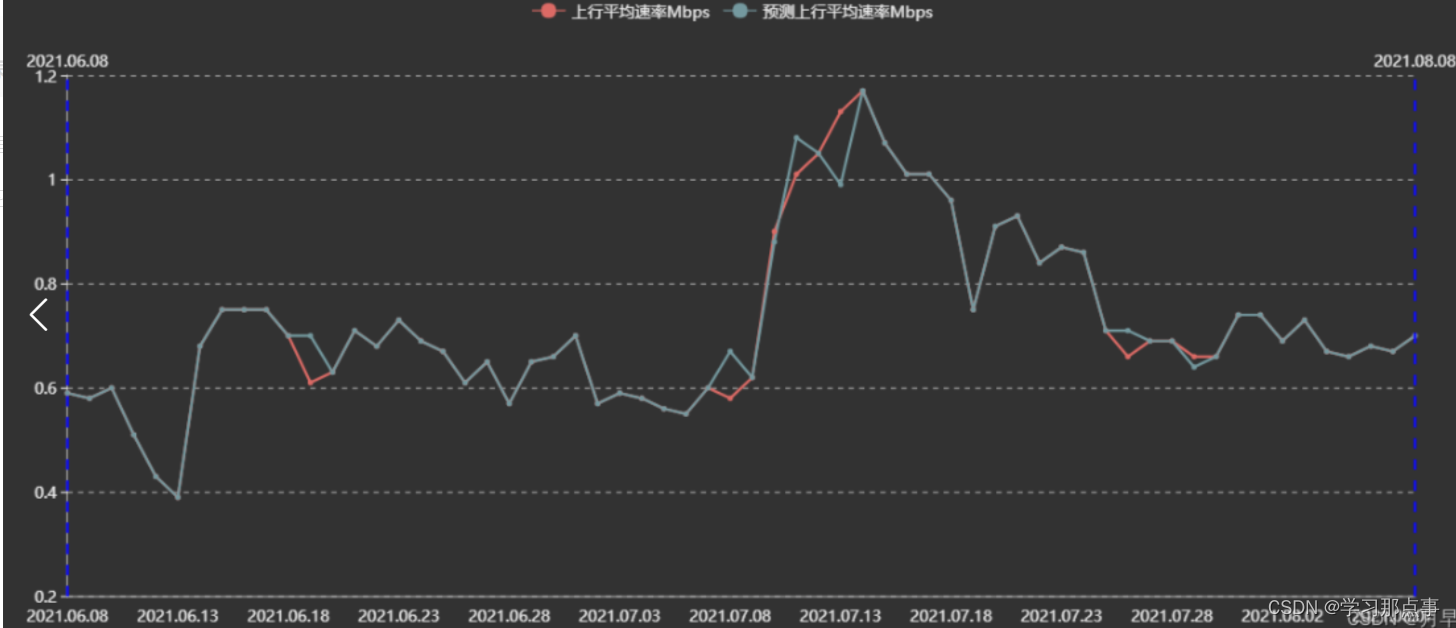
优化后曲线:

然后在分析报告里写清楚解决的途径:从6.13号的下行速率低于0.4为恶化指标,通过生成的关联系数发现相关的参数中xxxxx相关性较高,通过生成相关矩阵找到相关系数很高的关联系数,选择性删除其中xxxxx,以避免模型过拟合问题。
通过在参数调优时调整那几个xxxxxxx参数,将其调整到合适值并查看调整后的预测曲线,预测曲线显示下行速率得到了优化。
















 741
741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











