






目录
K-means算法步骤
1、随机初始化K个聚类中心
2、计算每个样本与k个聚类中心的相似度,将样本划分到与之最相似的类中
3、计算划分到每个类别中所有样本特征的均值,并将该均值作为每个类别新的聚类中心;
4、重复2、3步操作,直至聚类中心不再改变,输出最终的聚类中心。
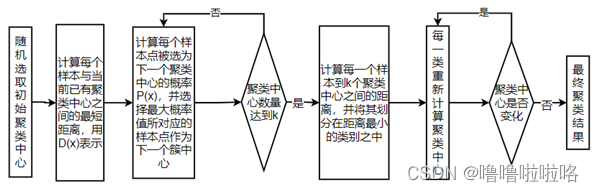
K-Means++算法步骤
K-Means++算法在初始化聚类中心时的基本原则是使聚类中心之间的相互距离尽可能的远,其初始过程如下:
1、在数据集中随机选择一个样本作为第一个初始化聚类中心;
2、计算样本中每一个样本点与已经初始化的聚类中心的距离,并选择其中最短的距离;
3、以概率选择距离最大的点作为新的聚类中心;
4、重复2、3步直至选出k个聚类中心;
5、对k个聚类中心使用K-Means算法计算最终的聚类结果。
K-Means++算法步骤如下图所示:
K-means与K-means++区别
通过以上可知,K-Means++算法和K-Means算法最本质的区别在与聚类中心的初始化















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









