






paper:https://arxiv.org/abs/2210.01391
一、概述
3D目标检测是计算机视觉中的一个关键研究领域,通常使用3D点云作为传统设置中的输入。最近,有一种趋势是利用多源输入数据,例如将3D点云与通常具有更丰富颜色和较少噪音的2D图像相结合。然而,由于2D和3D表示的异构几何性质,这阻止了我们使用现成的神经网络来实现多模态融合。因此,我们提出了一种名为Bridged Transformer(BrT)的端到端架构,用于3D目标检测。BrT简单而有效,能够从点和图像块中学习识别3D和2D物体边界框。BrT的关键元素在于利用对象查询来桥接3D和2D空间,从而统一Transformer中不同数据表示源。我们采用一种通过点到图像块的投影实现的特征聚合形式,进一步增强了图像和点之间的相关性。此外,BrT可以无缝地融合点云和多视角图像。我们通过实验证明,BrT在SUN RGB-D和ScanNetV2数据集上超越了最先进的方法。
二、创新点
-
提出了BrT,一种新颖的用于3D目标检测的框架,它在Transformer内部桥接了图像和点云的学习过程。
-
提出了从两个桥接角度加强图像和点的相关性,包括条件对象查询和点到图像块的投影。
-
BrT在两个基准测试上实现了最先进的性能,这证明了作者的设计的卓越性以及在多视角场景中的潜力。
三、方法
作者提出了Bridged Transformer(BrT)用于3D目标检测,同时使用视觉和点云作为输入。我们首先在第1节描述了BrT的总体结构,然后在第2节中介绍了构建模块的设计。在第3节和第4节中,我们考虑了两个方面来桥接视觉和点云的学习过程。
1.整体架构
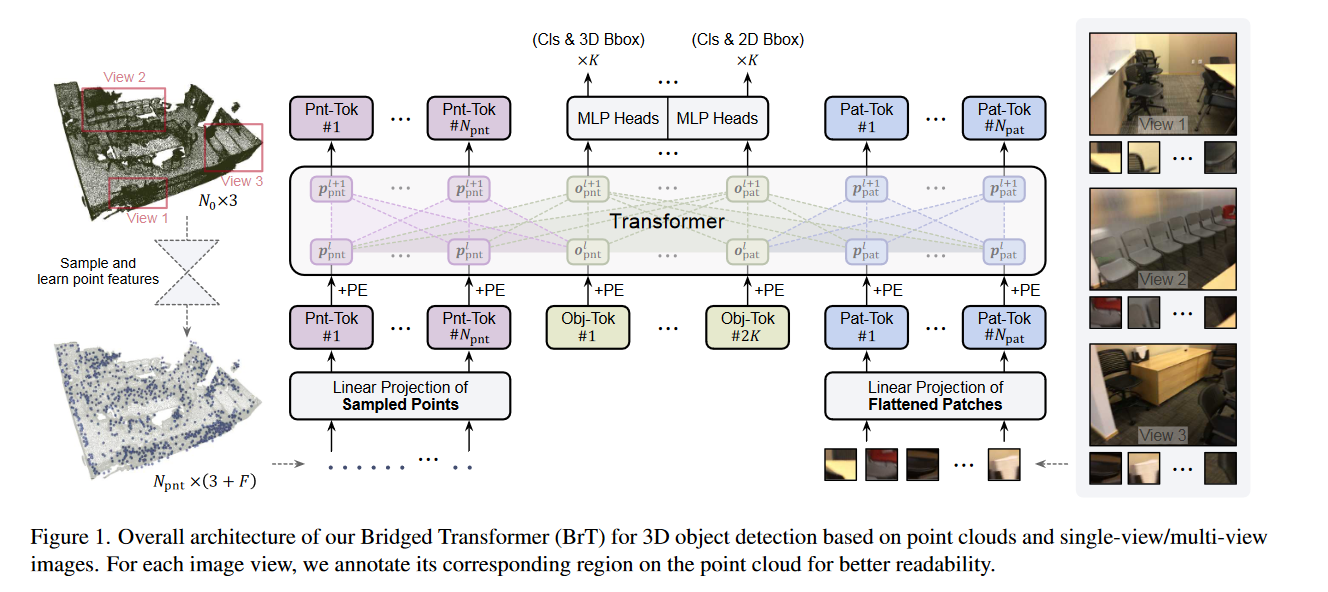
首先输入数据是N×3的点表示3D坐标点,和一个H×W×3的图像。简单起见,作者首先分析一个场景中的一个图像(后面第五节会提到多视角的问题)。
对于点云数据的预处理,作者使用PointNet++从N×3个初始数据中采样的seed points,是点的个数,3是欧几里得坐标,F是特征维度3
对于图像数据的预处理,作者将每一张图片分割成个patch,然后再送入到一个MLP中进行embedding。同时,可查询的查询对象将和分割成的patch一起送入到MLP中进行embedding,生成用于预测边界框坐标和类别标签的output embedding。
另外,作者采用了2K个可学习的查询对象(learnable object queries,也就是图像预处理时用到的),K个点云处理的,K个图像处理的。总之,这里有个基本token,2K个查询对象token。假设隐藏维度为D的话,则输入到第l个Transformer的Point tokens ,patch tokens ,point的查询对象 ,patch的查询对象。
然后介绍如何从3D点投影到相机平面,建立3D坐标和2D图像像素之间的关系,作者定义了一个操作proj:,表示从一个3D坐标投影到2D像素坐标的相应图片上,公式如下:
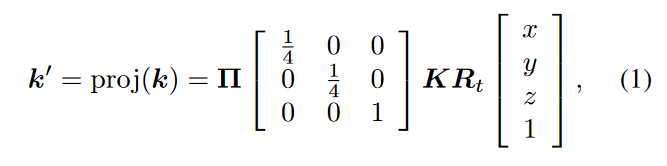

BrT有2K个输出,正好对应2K个输入对象查询。前K个输出,用一个MLP来预测3D的监测边框和类别标签。另外K个也是一个MLP来预测2D边框坐标和类别。作者这里提到,2D的边框坐标,不需要额外的信息,因为它们是通过首先将3D边界框坐标的标签投影到2D相机平面,然后获取投影形状的轴对齐2D边界框(背景知识不懂)。
然后对于BrT的优化器,是为了最小化两部分的损失函数,一个用于定位边框的回归损失,一个是预测类别的分类损失。回归损失包括两个部分3D的和2D的。分类损失也有两个部分3D的和2D的,
因此,整体损失函数计算如下:
是三个参数,用于加权这些损失之间的权重,、或进一步由两个子项组成,论文中4.1节讲了。
2. Transformer building block of BrT
作者这里首先简单介绍了一下多头注意力机制,它有三个输入集合Q,K,V,假设Q集合是,然后类似的K,V集合是(这里我理解为作者举了一个cross Attention的例子),公式如下:
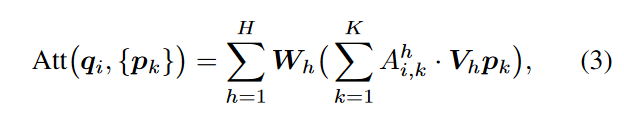
h是第几个头,H是一共多少个头,就是一个标准的多头自注意力机制,最后将所有头的特征聚合起来,就是求第h个头的Attention值:

这里exp就是softmax函数,先求点积注意力,然后softmax。
由前面的模型架构图可以看到,和之间是不计算Attention的。因此这两部分的Attention计算如下:
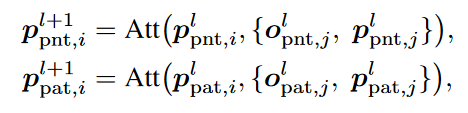
其中下标i和j表示标记索引。在这里,基于给定范围内的标记计算注意力得分,而不考虑其他标记,可以通过对注意力应用零掩码来实现。
这里没有考虑和之间的Attention,但是作者在3.4节中建立了一个point-to-patch的Bridge来连接它们。
此外,和还有其他功能, 可以进一步缩小3D坐标和2D坐标之间的差距,这将在下一节中详细说明。因此,和之间的Attention计算和所以token相关:
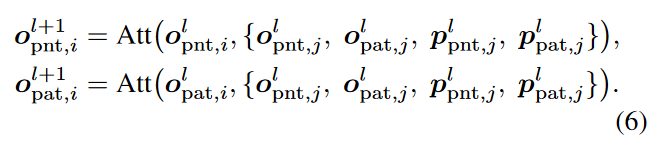
3. Bridge by conditional object queries
这部分的目标是基于同时感知3D和2D坐标的条件对象查询,旨在通过两种不同的组件来实现三维点云和二维图像的关联:一种是通过关注连接,另一种是通过使用共享的位置嵌入(PE)来对齐三维和二维对象查询。
作者发现,基于Transformer的目标检测模型,对象查询可能会专注于特定区域和定位框的大小。受到这个启发,作者假设对象查询关于点和图像的隐藏特征可能在Transformer内部被对齐,因此,作者采用了条件对象查询,以基于点和图像的对象查询对齐来提高预测学习过程。(这里没怎么理解。。。)
为了对齐点和图像的对象查询,作者首先使用KNN从中采样K个点,这K个点的3D坐标和特征分别表示为和,

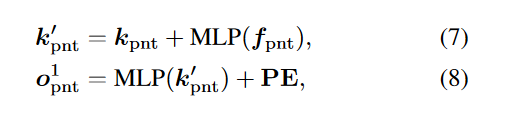
其中, 是随机初始化的位置嵌入。
然后对于图像的对象查询,作者通过之前提到的proj方法,将投影对应的平面上,获得投影像素的2D坐标,表示为。
则,图像快的对象查询公式如下:
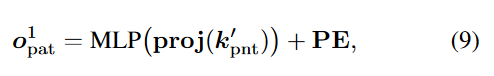
PE和(8)里的相同。相同的PE告诉了Transformer对象查询和是对齐的。
4. Bridge by point-to-patch projection
除了通过对象查询来连接和之间的关系外,作者在这部分还使用了point-to-patch projection的方式建立起了point token和image token之间的联系。
先将采样点的3D坐标表示为,然后将投影到相应的2D相机平面,并表示为,让和分别表示第n个元素的x轴和y轴,n = 1,2,…. 。如果和分别满足image大小限制和,然后这个2D坐标可以存在于大小为H×W×3的输入图像中。通过下面这种方式,可以很容易获得图像像素索引:


然后point-to-patch projection可通过以下方式聚合point和image的特征:

下标n和是和的索引。
5. Extend to multiple-view scenarios
(这里贴个翻译)
将当前仅针对点云或点图像的方法直接扩展到点云和多视图图像的检测任务具有挑战性,而这在实际数据组织中是常见的情况。例如,[20]避免使用包含丰富多视图图像的ScanNetV2数据集,可能是因为难以将点云与每个视图的交互结合起来。
幸运的是,我们提出的BrT在不增加太多复杂性的情况下,具有天然的优势,可以将点云与多视图图像结合起来,从而可以利用点图像的交互和多视图图像的交互来进一步提高性能。如图1所示,当一个场景有不同的输入图像视图时,我们首先沿宽度方向连接这些图像,获得一个宽图像。接下来的处理过程与单视图条件相同。由于多视图图像通常每个视图包含较少的对象,我们期望对象查询的数量K仍然可以处理所有对象。我们当前的设计主要旨在在每个视图和点云之间建立联系,但没有利用不同视图之间的关系进行明确的投影,这将留作我们未来的工作。















 7540
7540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









