







🙋作者:爱编程的小贤
⛳知识点:python爬虫— cookie介绍
🥇:每天学一点,早日成大佬
文章目录
🍎前言
💎 💎 💎今天为大家介绍爬虫的cookie介绍啦!!! 这是爬虫的第四讲咯!!!🚀 🚀 🚀
如果你看完感觉对你有帮助,,,欢迎给个三连哦💗!!!您的支持是我创作的动力。🌹 🌹 🌹 🌹 🌹 🌹 感谢感谢!!!😘😘😘
🍎一、cookie的简单介绍
1.1状态保持
- 浏览器请求服务器是无状态的。
- 无状态:指一次用户请求时,浏览器、服务器无法知道之前这个用户做过什么,每次请求都是一次新的请求。
- 无状态原因:浏览器与服务器是使用Socket套接字进行通信的,服务器将请求结果返回给浏览器之后,会关闭当前的Socket连接,而且服务器也会在处理页面完毕之后销毁页面对象。
- 有时需要保持下来用户浏览的状态,比如用户是否登录过,浏览过哪些商品等
- 实现状态保持主要有两种方式:
- 在客户端存储信息使用 Cookie
- 在服务器端存储信息使用 Session
1.2什么是cookie?cookie的作用又是什么?
Cookie,有时也用其复数形式Cookies,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。
Cookie最早是网景公司的前雇员Lou Montulli在1993年3月的发明。
Cookie是由服务器端生成,发送给User-Agent(一般是浏览器),浏览器会将Cookie的key/value保存到某个目录下的文本文件内,下次请求同一网站时就发送该Cookie给服务器(前提是浏览器设置为启用cookie)。
Cookie名称和值可以由服务器端开发自己定义,这样服务器可以知道该用户是否是合法用户以及是否需要重新登录等。
服务器可以利用Cookies包含信息的任意性来筛选并经常性维护这些信息,以判断在HTTP传输中的状态。Cookies最典型记住用户名。
Cookie是存储在浏览器中的一段纯文本信息,建议不要存储敏感信息如密码,因为电脑上的浏览器可能被其它人使用。
1.3 cookie的特点
- cookie以键值对的格式进行信息的存储
- cookie基于域名安全,不同域名的cookie是不能互相访问的
- 当浏览器请求某网站时,会将浏览器存储的跟网站相关的所有cookie信息提交给网站服务器。
- cookie是有过期时间的,如果不指定,默认关闭浏览器后cookie就会过期
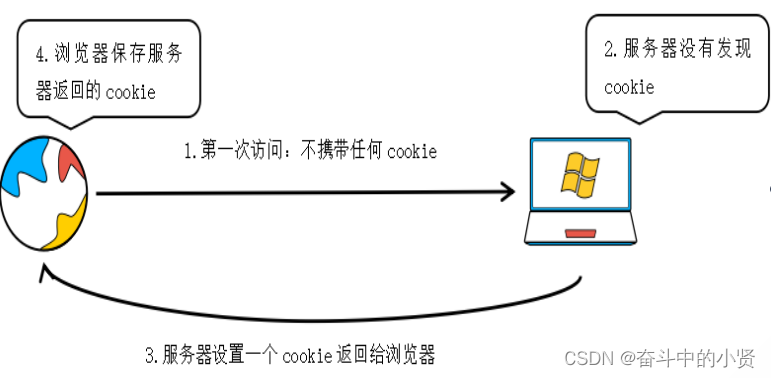
1.4 cookie的流程
- 浏览器在第一次请求服务器的时候,不会携带任何cookie信息
- 服务器接收到请求之后,发现请求中没有任何cookie信息
- 服务器设置一个cookie,这个cookie设置在响应中
- 浏览器在接收到这个响应之后,发现响应中有cookie信息,浏览器会将这个cookie信息保存起来
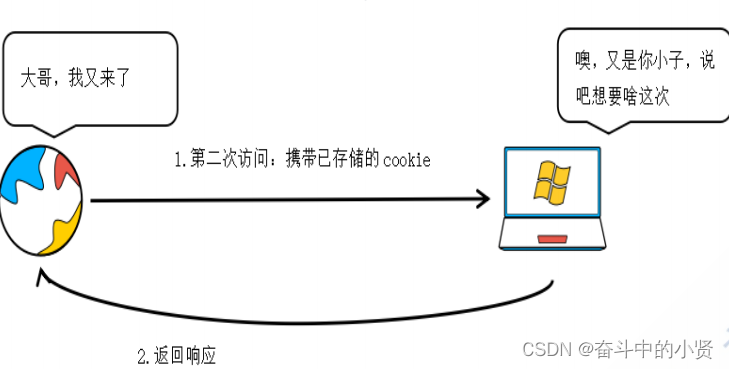
第二次及其之后的过程
- 当我们的浏览器第二次及其之后的请求都会携带cookie信息
- 服务器接收到请求之后,会发现请求中携带的cookie信息,这样的话就认识是谁的请求了
第一次访问:
第二次及其之后的访问:
🍎二、 爬虫中的cookie
为了能够通过爬虫获取到登录后的页面,或者是解决通过cookie的反爬手段,需要使用request来处理cookie相关的请求
2.1 爬虫中使用cookie的利弊
- 带上cookie的好处
- 能够访问登录之后的页面
- 能够解决部分反爬(例如用户认证)
- 带上cookie的坏处
- 一个cookie往往对应的是一个用户信息,如果请求出现异常的话可能会被对方识别为爬虫,那么为账号带来封禁的风险
那么要如何去解决上述问题呢?
答:搭建一个账号池,一般来说用户是可以搭建一个账号池的,例如某博客网站,用户可以根据虚拟信息注册多个账号搭建一个账号池供爬虫使用
2.2 requests处理cookie的方法
使用requests处理cookie有三种方法:
- 把cookie字典传给请求方法的cookies参数接收
- cookie字符串放在headers中,也就是构建请求头的时候同时添加cookie
- 使用requests提供的session模块
🍎三、cookie的在爬虫中的使用
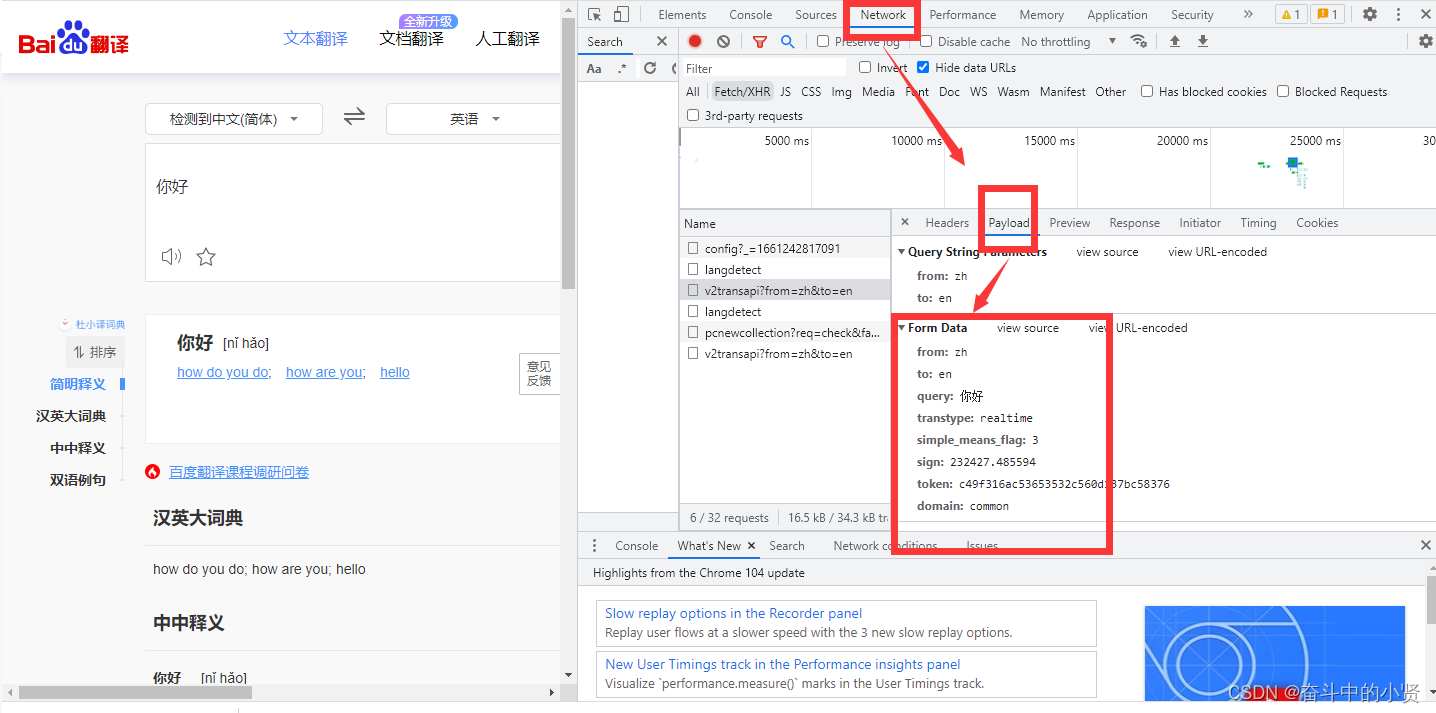
3.1 headers中cookie的位置
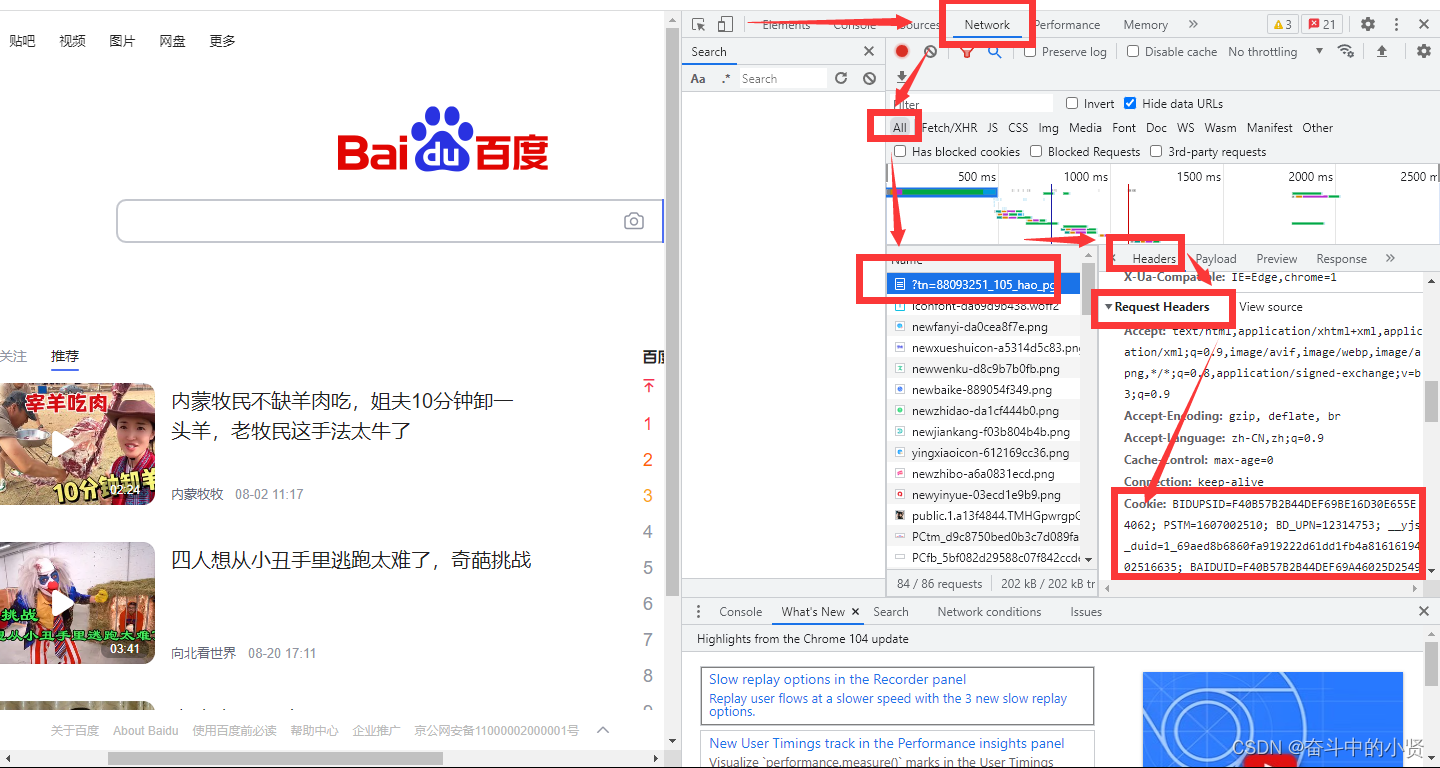
- headers中的cookie:
- 使用分号‘;’隔开
- 分号两边的类似a=b形式表示一条cookie
- a=b中,a表示键(key),b表示值(value)
- 在headers中仅仅使用了cookie的key和value
3.2 cookie的具体组成字段
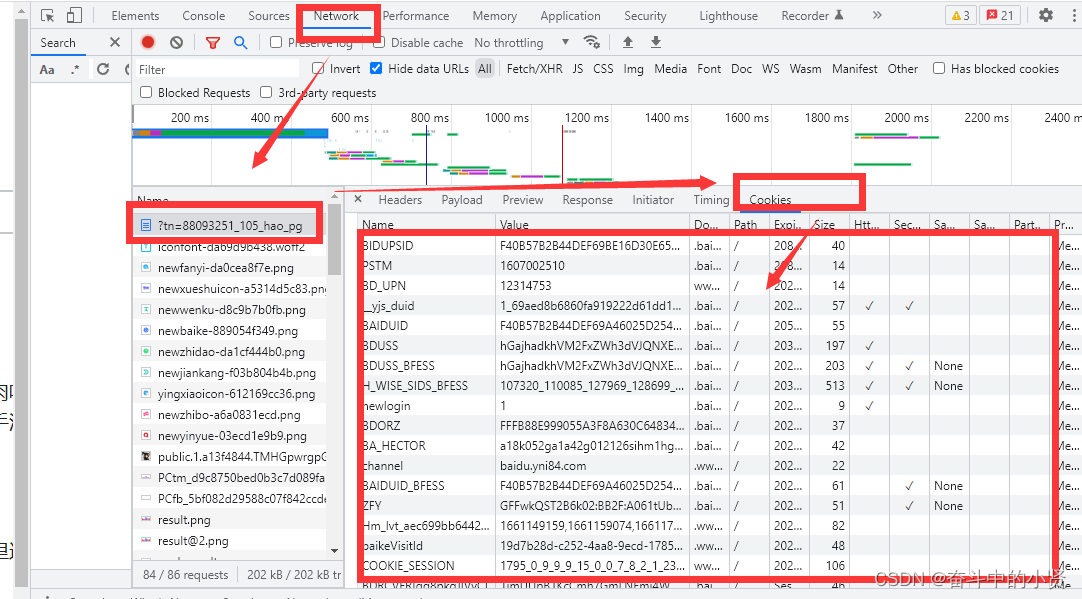
由于headers中对cookie仅仅使用它的key和value,所以在代码中我们仅仅需要cookie的key和value即 可
3.3 cookie在headers中的具体使用
3.3.1 使用cookies参数接收字典形式的cookie
- cookies的形式:字典
cookie = {"Cookie": "cookie的值}
- 使用方法
requests.get(url,headers=headers,cookies=cookie)
注意:要复制 对应的数据包的Cookie,因为不同的网站Cookie数据不同,我们分析cookie可以发现它是键值对呈现的
3.3.2 在headers中使用cookie
复制浏览器中的cookie到代码中使用
headers = {
"User-Agent": "UA字符串",
"Cookie": "Cookie字符串"
}
使用方法:
request.get(url, headers=headers)
注意:
cookie有过期时间 ,所以直接复制浏览器中的cookie可能意味着下一程序继续运行的时候需要替换代码中的cookie,对应的我们也可以通过一个程序专门来获取cookie供其他程序使用;当然也有很多网站的cookie过期时间很长,这种情况下,直接复制cookie来使用更加简单
总不能过期了我们再复制吧,那么有没有更好的模拟登录的方式呢?
接下来我们就来学习一下post请求
3.3.3 post请求的介绍
post请求跟get请求的传参:
post请求: 需要先向服务器提供数据,才能够获取对应的响应 – 登录的时候的发送的请求.post请求. 提供账号,密码. – 说说,微博, 里面的内容文字 post请求发送,
get请求可以在url后面传参携带数据:为什么还会有post请求的存在 携带数据的方式不同: get: url后面传参携带数据
post: 请求体:携带数据 单据的空间,请求头之外的 – 请求体携带数据更加的安全: 账号密码 – 携带的数据比较大: 说说
requests.post(url, headers=headers_, data=form_data)
import requests
url_ = 'https://fanyi.baidu.com/sug'
headers_ = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Mobile Safari/537.36'
}
data_ = {
'kw': '我爱你'
}
respons_ = requests.post(url_, headers=headers_, data=data_)
print(respons_.json())
🍎总结
本文到这里就结束啦👍👍👍,如果有帮到你欢迎给个三连支持一下哦❤️ ❤️ ❤️
文章中有哪些不足需要修改的地方欢迎指正啦!!!让我们一起加油👏👏👏
⭕⭕⭕最最最后还是要提示一下啦!!!!!🔺🔺🔺
提示:做爬虫一定要**注意**如果涉及到私人信息或者公司单位的机密信息就不要去碰,爬虫开发过程中意外拿到了用户私人信息或者公司机密,千万不要交易!!!!掌握好爬虫的度就没有任何问题!!!!!!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











