







虚拟机上所需要的文件:Python-3.7.0.tgz
链接:https://pan.baidu.com/s/1jH76j-5Mhoq4jx-pI4elJw?pwd=msv8
提取码:msv8本机上所需要的文件:python-3.7.0-64位.exe
链接:https://pan.baidu.com/s/1SOq9v-X16rPMAOs0DkZHOQ?pwd=omzs
提取码:omzs
目录
一,在Windows(母机)上的安装与配置python3.7
1)从网盘下载Python-3.7.0.tgz到主机(Windows系统上)
python3.7软件可以让我们在命令行上使用pip3指令去下载相应的其他软件,所以它的安装也是很有必要的,在Windows主机上的安装很简单,只需要双击exe文件,之后安装步骤即可安装好,稍微复杂点的就是在虚拟机上进行安装及配置。现在我们先简略的看一下在Windows上的安装:
一,在Windows(母机)上的安装与配置python3.7
1,下载python3.7
从网盘上下载好软件之后我们只需要双击启动该exe文件即可:

2,安装python3.7


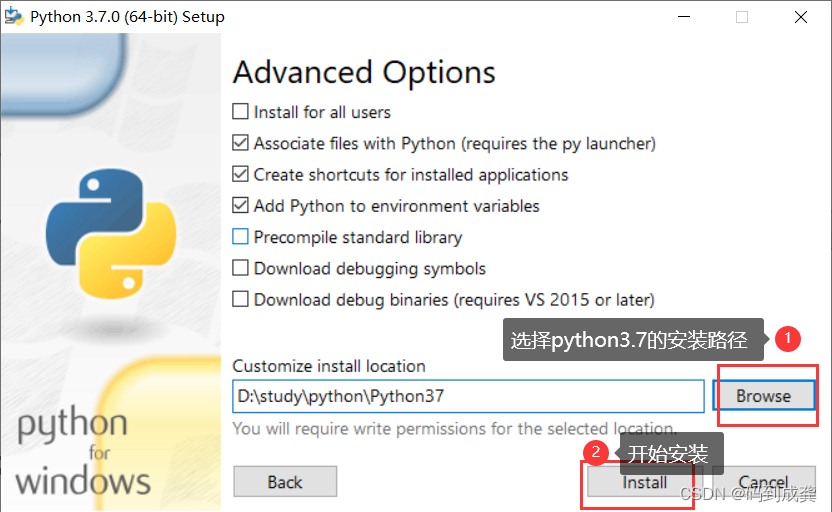
3,测试是否安装成功
之后我们使用cmd命令行窗口来检查python是否安装成功,如下显示表示安装与配置成功:

如果不需要使用到虚拟机的看到这里就够了,接下来的安装与配置都是在虚拟机上进行,有兴趣的可以进行阅读。
二,在虚拟机上的安装与配置python3.7
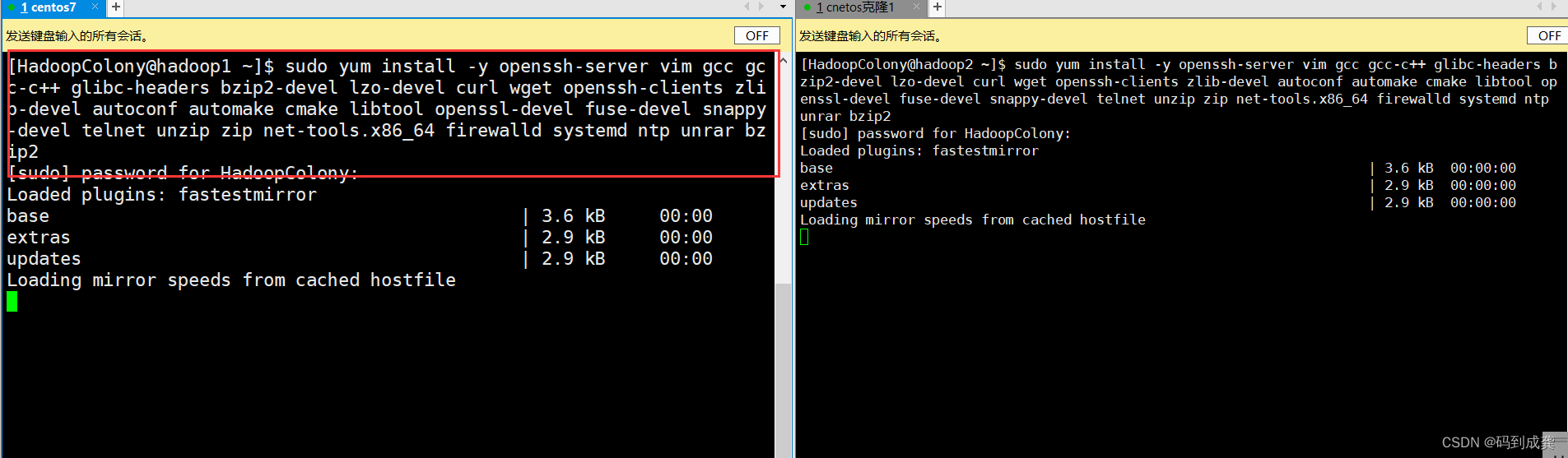
1,安装依赖
我们需要分别在两台虚拟机上执行下面的命令:
[HadoopColony@hadoop1 ~]$ sudo yum -y install libffi-devel
因为是自己创建的用户,所以我的HadoopColony用户权限不高,因此需要在使用yum命令时需要使用到root权限,上面我使用了sudo得到root权限。如果是直接使用的root用户来进行操作的话,那么可以不需要加上sudo。
执行成功后的界面如下:
2,xshell进行分屏并实现会话同步
如果觉得上面的方式很麻烦(不仅要切换虚拟机,还得再写一次命令),那么我们可以使用如下的方式,将我们的xshell软件进行相应的设置来让我们的命令可以同时在两个或者是三个会话及以上上进行:
1,将需要控制的会话(一个会话连接一个虚拟机),将虚拟机进行垂直排列,之后我们就可以直观的同时看到我们两边的输入:
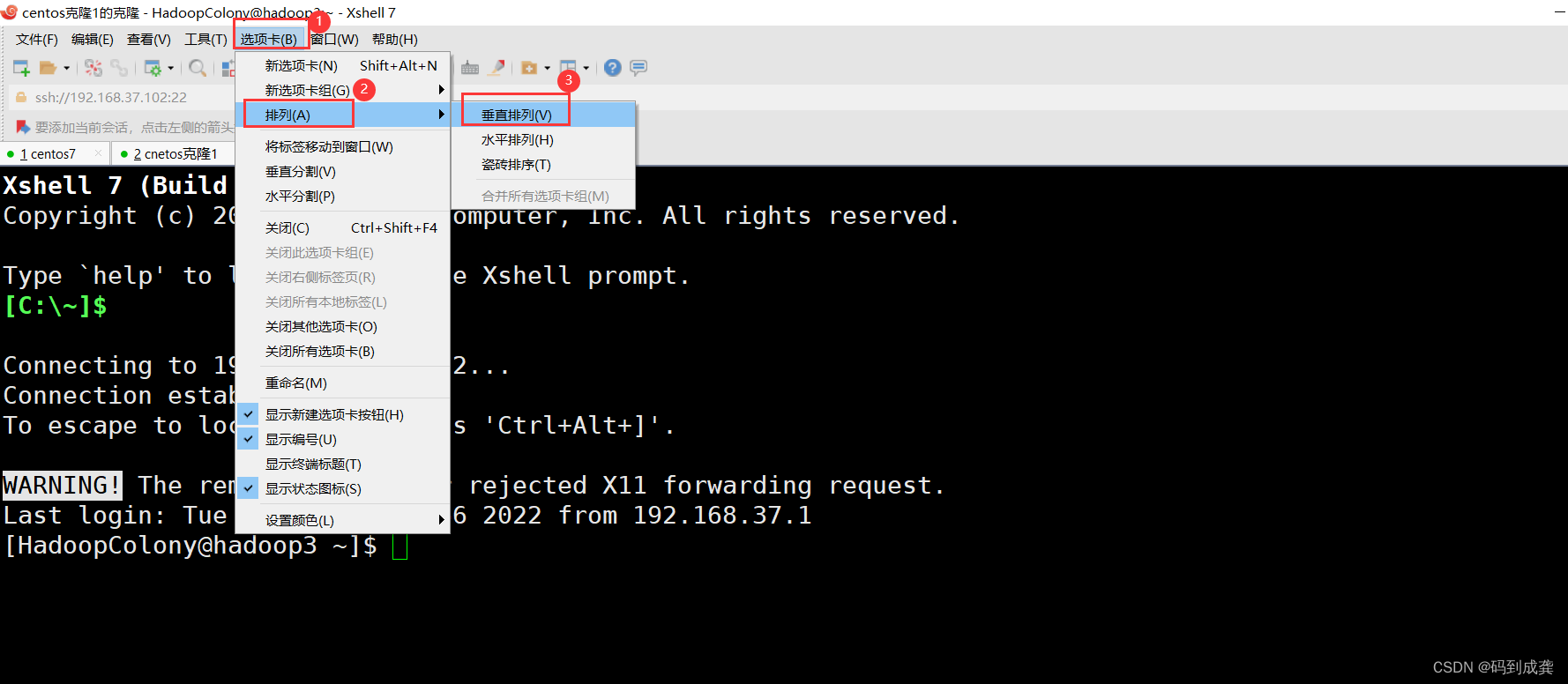
2,选择需要键入的会话,即我们要怎么去控制我们的会话,如下,我们选择所有会话,表示只要是当前打开的会话,都一起同步输入:
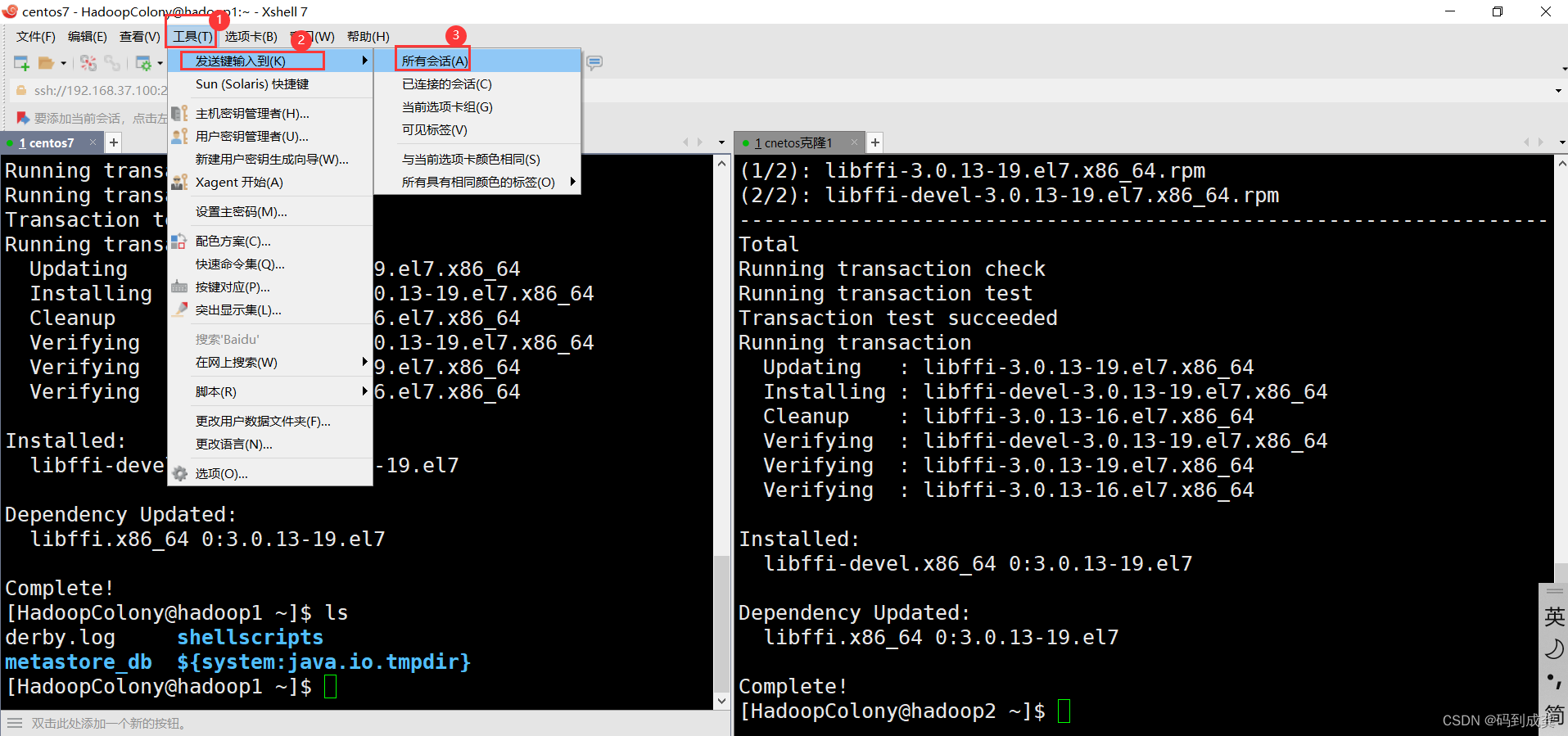
如下,我们只输入左边,右边就会自动的同步,这样子我们就不需要去重复的写一个命令:
安装好依赖并以键入所有会话的形式输入命令之后,接下来我们就可以同时在两台虚拟机进行下载安装python软件的操作了。
3,下载并上传Python-3.7.0.tgz
linux 系统自带Python2.7.5;但是我们现在用的基本上是3.7版本的python,所以我们需要将要用到的版本上传到linux,并解压,执行编译安装:
1)从网盘下载Python-3.7.0.tgz到主机(Windows系统上)
所需要的文件:Python-3.7.0.tgz
链接:https://pan.baidu.com/s/1jH76j-5Mhoq4jx-pI4elJw?pwd=msv8
提取码:msv8

2)上传Python-3.7.0.tgz到虚拟机
我习惯性的将一些压缩文件放到自己创建的/opt/softwares目录下,所以我首先会先将工作目录转到/opt/softwares目录,之后我就直接拖拽文件到该目录下即可。(如果不能够拖拽的需要去进行相关的下载:yum install -y lrzsz )
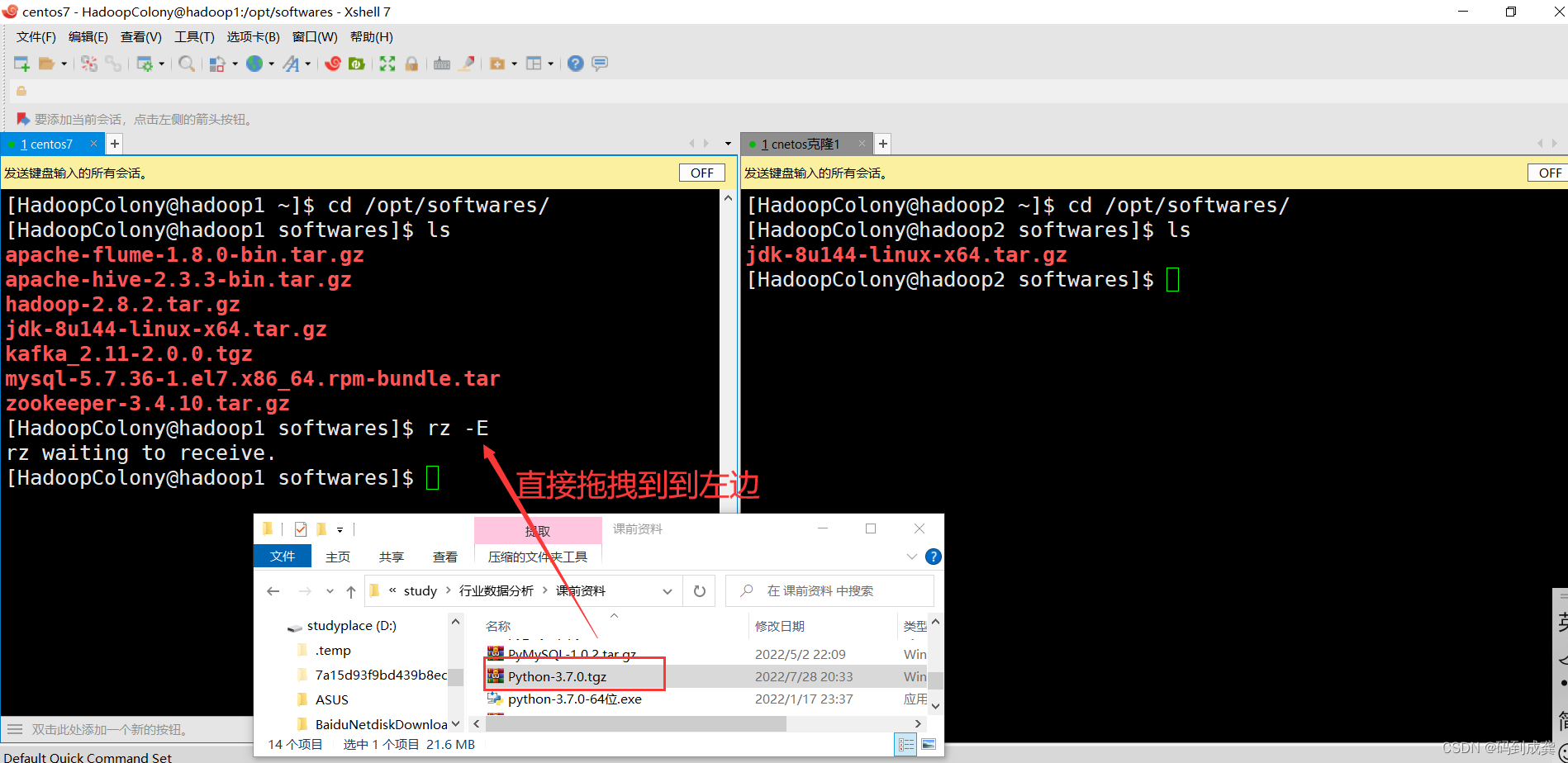
现在我们去查看两台虚拟机是否都有这个压缩包:
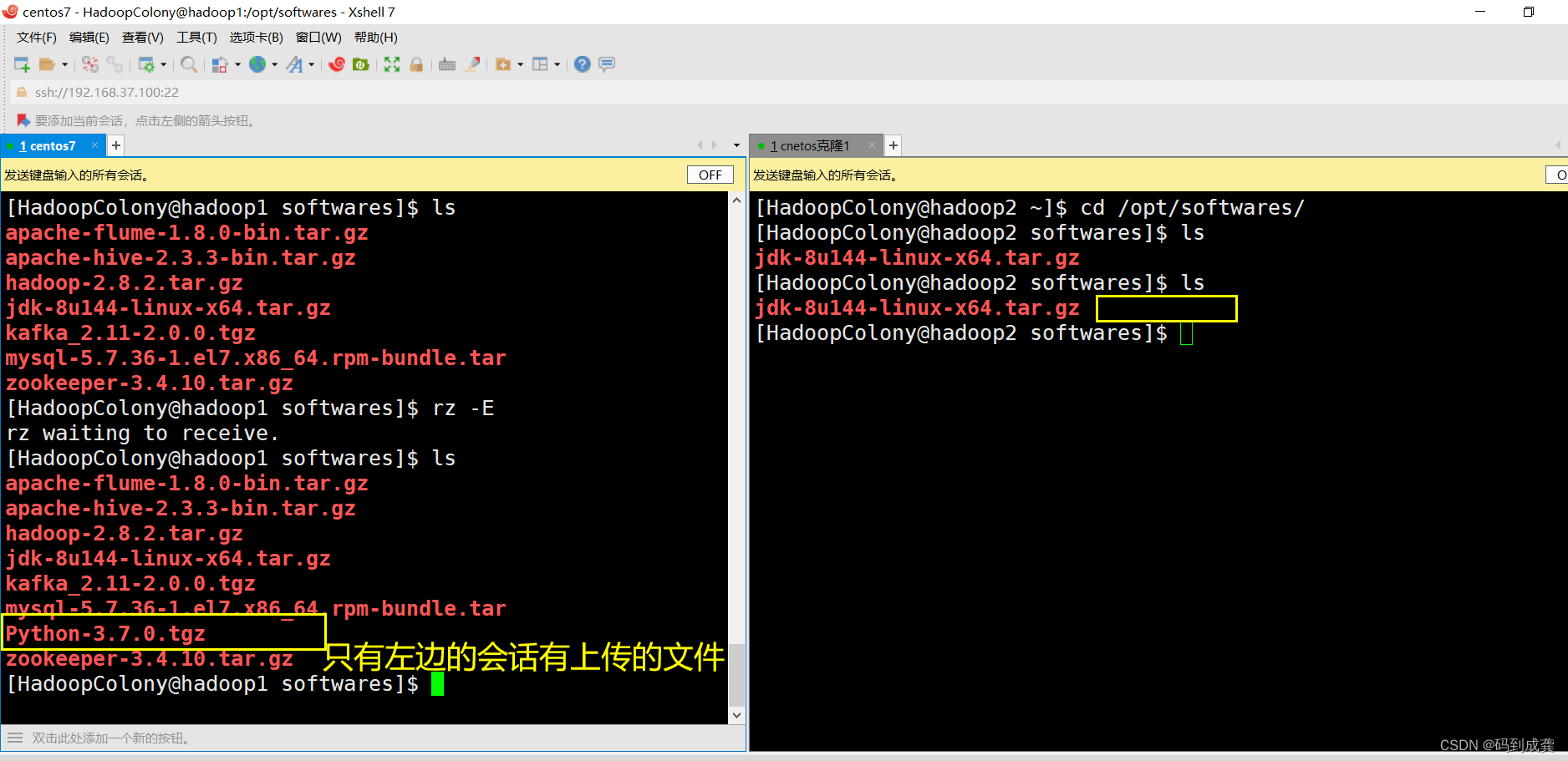
如上,可见,使用键入所有会话的形式只能保证命令是相同的,但并不能够做到同步文件。因此我们还得需要再在另外一台虚拟机里面上传python文件,如下:

3)解压Python-3.7.0.tgz
我们两台虚拟机上 现在都有python文件了,因此可以使用键入所有会话的形式输入解压命令:
[HadoopColony@hadoop1 softwares]$ tar -zxf Python-3.7.0.tgz -C /opt/softwares/
[HadoopColony@hadoop1 softwares]$ cd ../softwares/
[HadoopColony@hadoop1 softwares]$ ls

4,下载gcc
因为后面我们需要运行configure脚本文件,所以需要保证自己的虚拟机上是已经是安装了gcc程序的,因为在虚拟机中的shell文件都是使用c来进行编写的,所以在编译的时候也是使用c来编译,如果没有安装gcc的话就会报如下错误:
checking build system type... x86_64-pc-linux-gnu
checking host system type... x86_64-pc-linux-gnu
checking for python3.7... no
checking for python3... no
checking for python... python
checking for --enable-universalsdk... no
checking for --with-universal-archs... no
checking MACHDEP... checking for --without-gcc... no
checking for --with-icc... no
checking for gcc... no
checking for cc... no
checking for cl.exe... no
configure: error: in `/opt/softwares/Python-3.7.0':
configure: error: no acceptable C compiler found in $PATH
See `config.log' for more details
这个时候就需要使用命令去下载gcc程序:yum install -y gcc。进行解决。
5,运行configure脚本并编译安装python3.7
1)运行configure脚本
安装好后我们转到Pyhton的安装目录里面:
[HadoopColony@hadoop1 Python-3.7.0]$ ./configure --prefix=/opt/softwares/python3
/opt/softwares/python3:表示我们python3的安装路径。
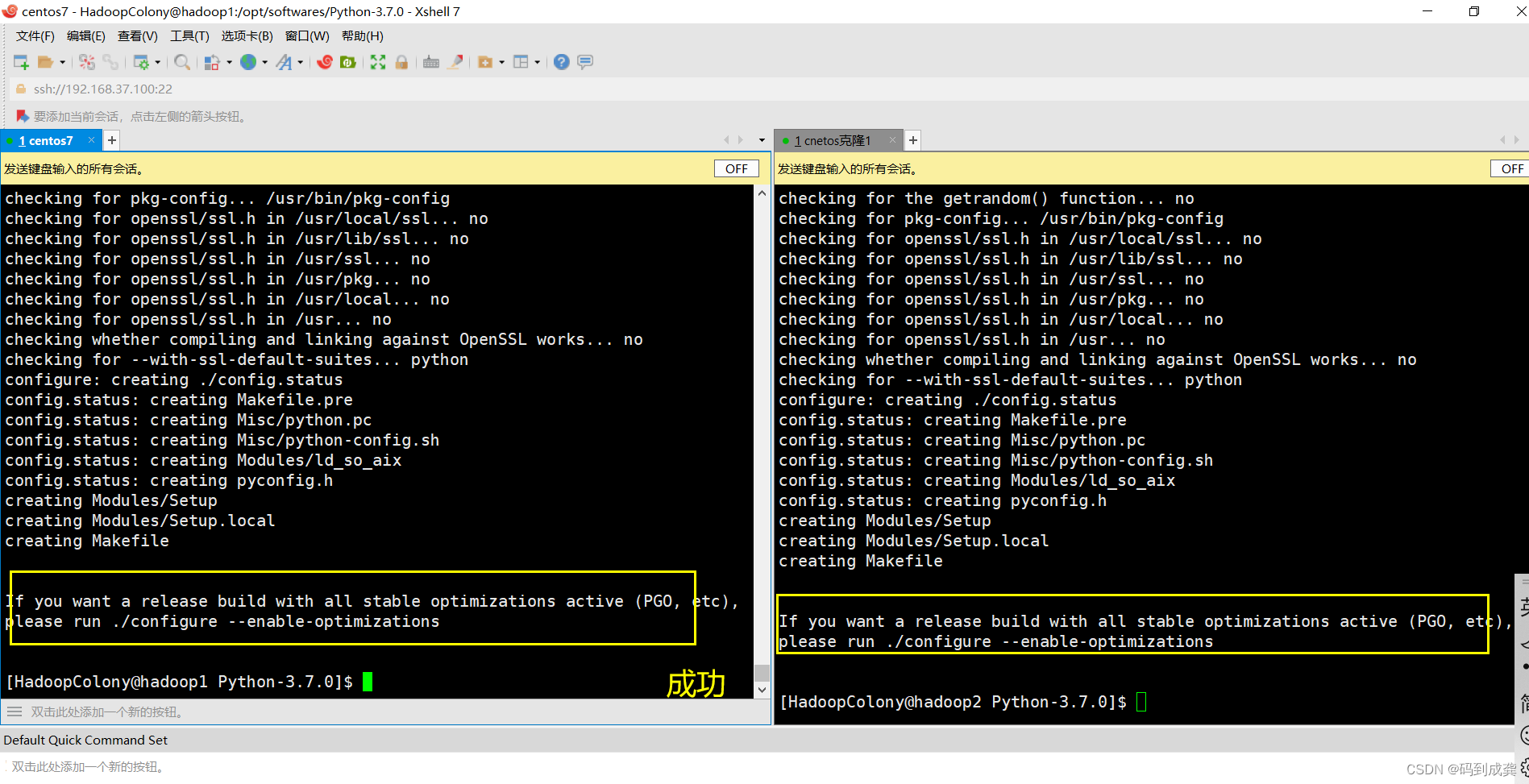
2)使用make命令执行编译
我们再使用make来进行编译,因为我们的python不像其他的软件那样,下载好后就可以,而是像我们的centos那样,需要进行编译:

等待.............
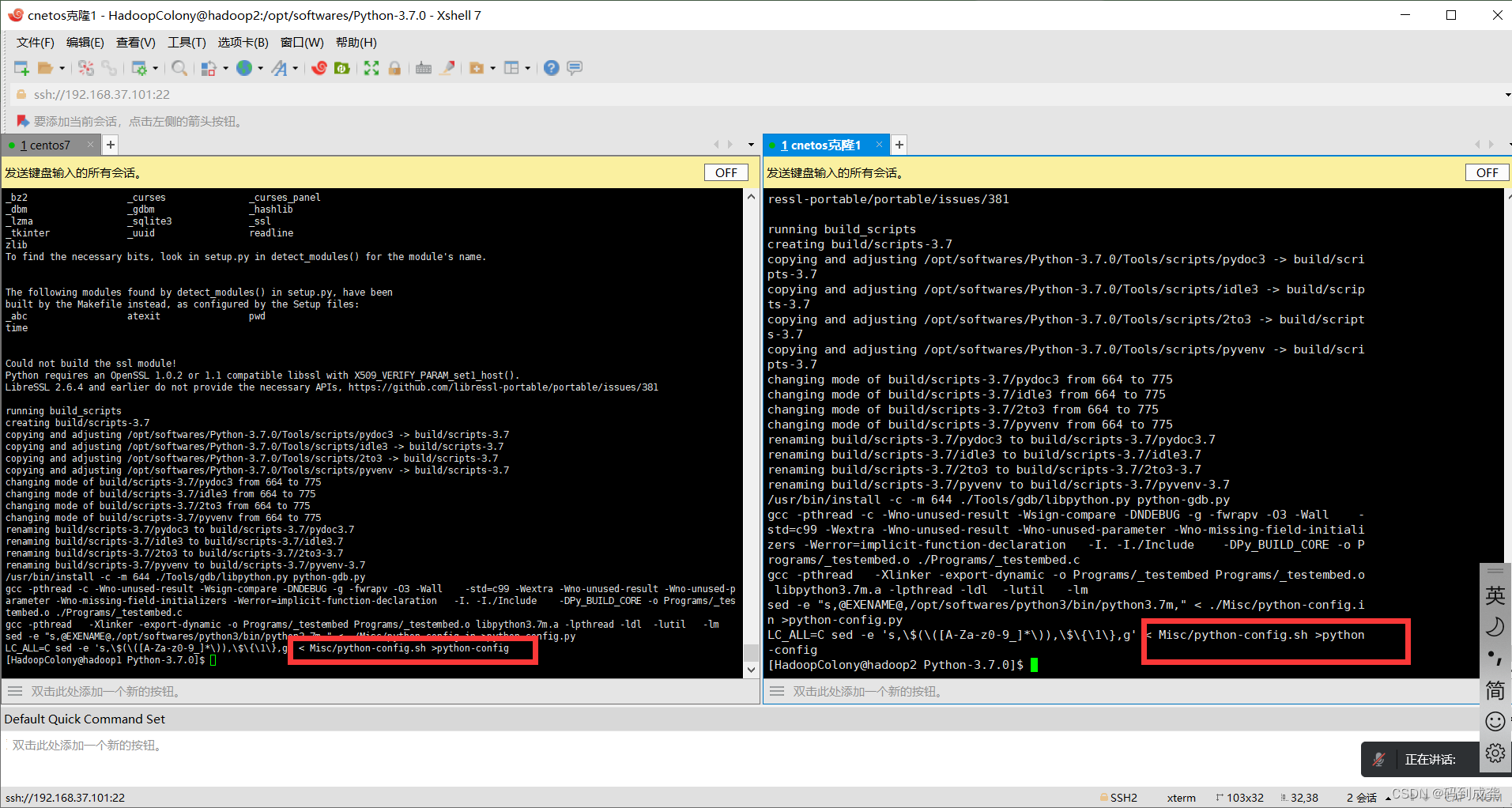
3)使用make install 命令安装软件
编译好后,我们就可以使用“make install”命令来安装我们的软件:

如上,我们可以看到,提示我们的下载错误,出现如上的错误主要还是因为我们的环境少了依赖,我们可以去下载来解决这个问题:
yum install -y openssh-server vim gcc gcc-c++ glibc-headers bzip2-devel lzo-devel curl wget openssh-clients zlib-devel autoconf automake cmake libtool openssl-devel fuse-devel snappy-devel telnet unzip zip net-tools.x86_64 firewalld systemd ntp unrar bzip2
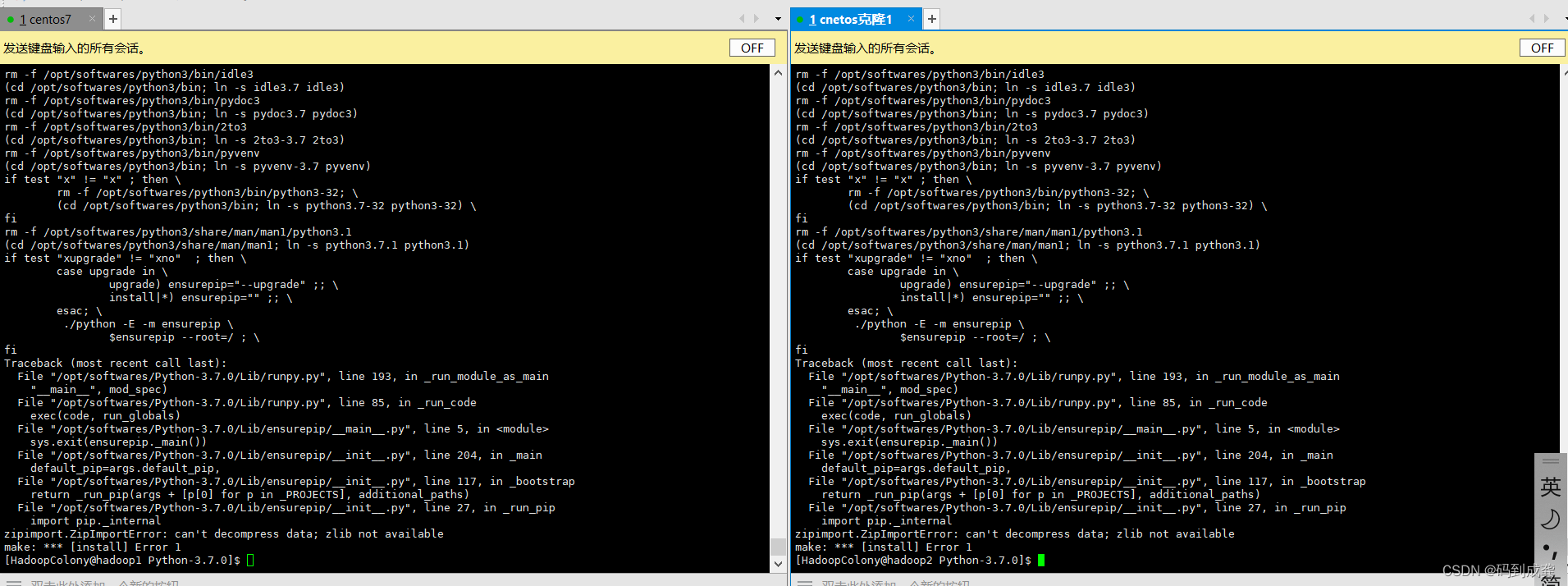
 下载好后相关的依赖后,如下界面显示:
下载好后相关的依赖后,如下界面显示:
如果之前在该目录下有python3及pip3的蓝色目录的话建议使用rm -rf删除。
[HadoopColony@hadoop1 softwares]$ rm -rf pip3
之后再重新运行make命令和make install命令,如果最后的显示如下,代表安装成功:
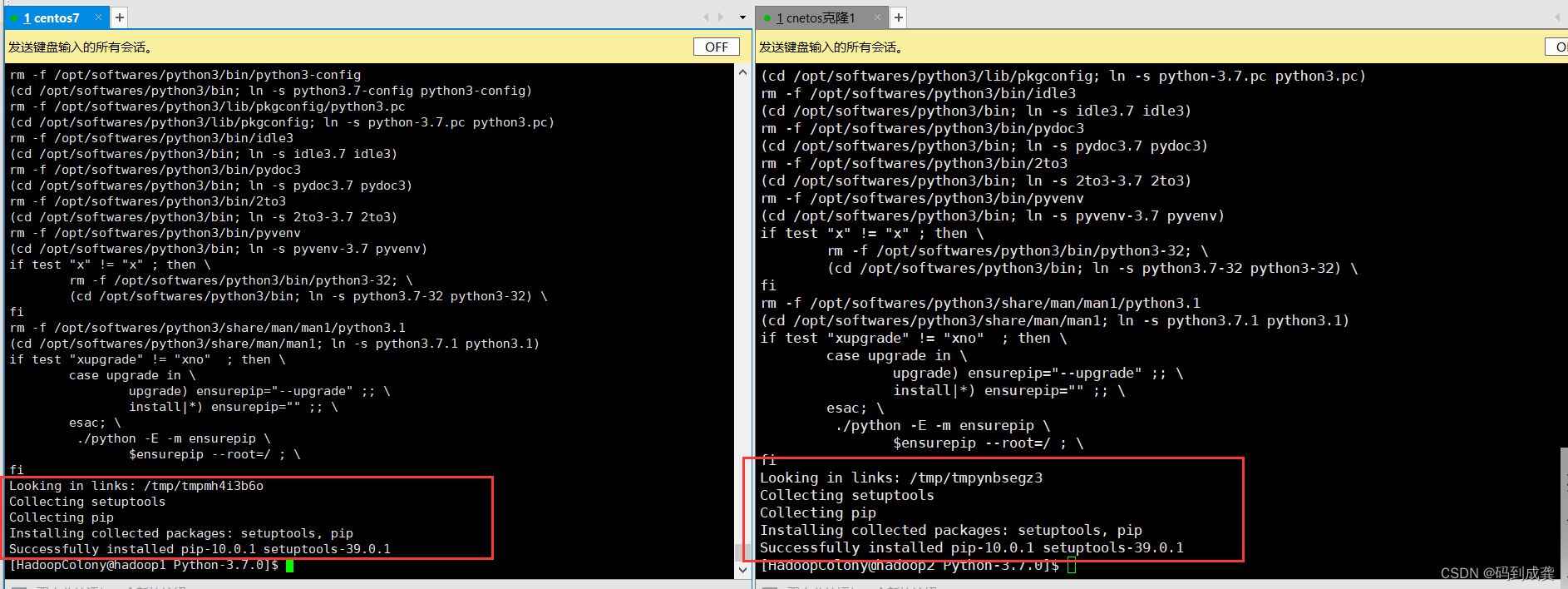
现在python3、setuptools 和 pip 都已经安装完成。
6,配置python3.7及pip3的环境
但是在我们的path路径下并不能找不到该软件

所以我们需要去创建python3和pip3的软连接:
[HadoopColony@hadoop1 bin]$ pwd
/usr/bin
[HadoopColony@hadoop1 bin]$ cd /opt/softwares/Python-3.7.0
[HadoopColony@hadoop1 Python-3.7.0]$ sudo ln -s /opt/softwares/python3/bin/python3 /usr/bin/python3
[HadoopColony@hadoop1 Python-3.7.0]$ sudo ln -s /opt/softwares/python3/bin/pip3 /usr/bin/pip3
[HadoopColony@hadoop1 Python-3.7.0]$ python3 -V
Python 3.7.0
[HadoopColony@hadoop1 Python-3.7.0]$

7,测试是否安装成功
如上,我们的python环境就可以显示出来。 并且我们还可以通过pip3 list命令来查看我们的pip3的版本,如下我们当前的版本为10。

如上就是python3.7在Windows系统及linux系统中的安装与配置。
有问题的请在评论区留言。















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









