









基于PyTorch搭建LeNet卷积神经网络识别FasionMNIST数据集
LeNet网络介绍
LeNet-5由LeCun等人于1998年提出,是一种用于手写体字符识别的卷积神经网络。出自论文《Gradient-Based Learning Applied to Document Recognition》
网络结构

LeNet5网络结构主要分为两部分,第一部分为卷积层与池化层,第二部分为全连接层。
Pytorch代码实现
在论文中,作者采用的是平均池化层,并使用Sigmoid作为激活函数。但目前在图像处理领域,最大池化层与Rule激活函数更为常用。
# LeNet5
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = x.view(-1, 400)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1)
FasionMNIST数据集介绍
Fashion MNIST/服饰数据集包含70000张灰度图像,其中包含60,000个示例的训练集和10,000个示例的测试集,每个示例都是一个28x28灰度图像,分为以下几类:t-shirt(T恤),trouser(牛仔裤),pullover(套衫),dress(裙子),coat(外套),sandal(凉鞋),shirt(衬衫),sneaker(运动鞋),bag(包),ankle boot(短靴)

代码实现
import torch
from torch import nn
import torchvision
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
n_epochs = 10
batch_size_train = 128
batch_size_test = 1000
learning_rate = 0.001
log_interval = 10
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.FashionMNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])), batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.FashionMNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])), batch_size=batch_size_test, shuffle=True)
# LeNet5
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = x.view(-1, 400)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1)
network = Net().cuda() # gpu加速
optimizer = optim.Adam(network.parameters(), lr=learning_rate)
train_losses = []
def train(epoch):
network.train() # 训练模式
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad() # 梯度清零
output = network(data.cuda())
loss = F.nll_loss(output, target.cuda())
loss.backward() # 反向传播
optimizer.step() # 参数更新
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data),
len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item()))
train_losses.append(loss.item())
torch.save(network.state_dict(), './model/model_FashionMnist.pth')
torch.save(optimizer.state_dict(), './model/optimizer_FashionMnist.pth')
def test():
network.eval() # 测试模式
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data_cuda = data.cuda()
target_cuda = target.cuda()
output = network(data_cuda)
test_loss += F.nll_loss(output, target_cuda, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target_cuda.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
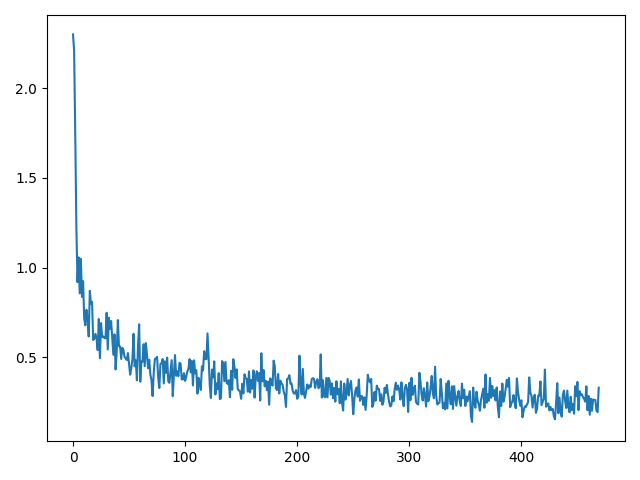
plt.plot(train_losses)
plt.show()
测试结果:
Test set: Avg. loss: 0.3134, Accuracy: 8842/10000 (88%)
损失函数图像:















 3374
3374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









