







梯度下降法,常被用来求解算法的最佳参数(例如求解神经网络中的权重和偏置),举个多元线性回归问题的例子,来解释一下梯度下降法的原理
预测城市的平均房价y与该城市的GDP(x1),人口数(x2),交通便利程度(x3)等有关,X的权重矩阵用W来表示。
其中求解预测的最佳参数W的过程可以用梯度下降法进行参数的最优化。
如果用最小二乘法来计算误差J=(XW-Y)^2 ,令J对W偏导数=0,求解误差J最小时W的值,解如下,这种情况下有局限性的前提是X为可逆矩阵(也就是说X不含有多重共线性)。
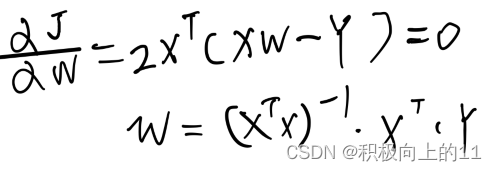
而梯度下降法则是一种更广泛的求解权重W的方法,很多资料中讲误差J比作是一个山谷,在山顶向山谷里丢一个人进去,其下降到无法下降的时候我们也就找到了山谷(也就是误差)的最低点,
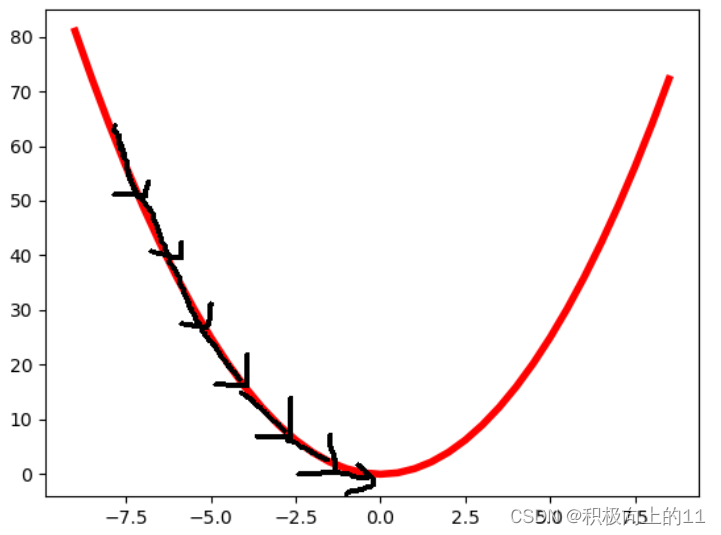
在最低点的梯度(导数值)也就为0。将人不断下降的过程看作是按照一定横向的步长a(也叫做学习率)迭代的过程,为了方便后续求解我们在误差J前面加一个1/2m的常数,由于最后梯度会变为0,就会停止迭代了。
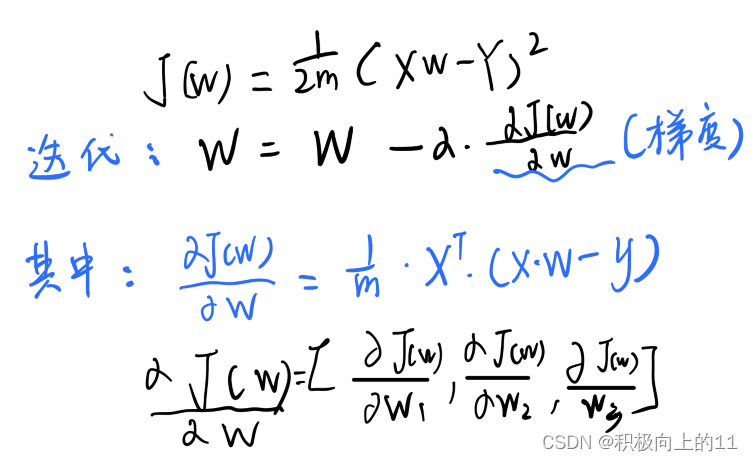
那么其中的梯度到底是什么?
梯度其实叫雅各比矩阵(Jacobian matrix) ,实际上就是多变量微分的一般化,在多变量函数中,梯度是一个向量,可以理解成多元函数在某一点的各个方向导数所构成的一个矩阵,它体现了一个可微方程与给出点的最优线性逼近。
如何应用梯度下降法求解多元线性回归问题呢?
把初始问题中的权重矩阵进行设置,其中gradient_descen这个函数是求解雅各比矩阵。
import numpy as np
# 数据的个数
m = 5
X0 = np.ones((m, 1))
X1 = np.array([
90,89,80, 100,100,140,100,100,120, 100,120, 150, 112,150,200
]).reshape(m, 3)
X = np.hstack((X0, X1))
#房价的三个特征
y = np.array([
171,236,217,256,328
]).reshape(m, 1)
#学习的步长 学习率
alpha = 0.000001
#误差函数
def error_function(theta, X, y):
diff = np.dot(X, theta) - y
return (1./2*m) * np.dot(np.transpose(diff), diff)
#偏导数函数 雅各比矩阵
def gradient_function(theta, X, y):
diff = np.dot(X, theta) - y
return (1./m) * np.dot(np.transpose(X), diff)
#梯度下降函数求解权重的函数
def gradient_descent(X, y, alpha):
new_inter=0
theta = np.array([1,1, 1,1]).reshape(4, 1)
gradient = gradient_function(theta, X, y)
while (np.all(np.absolute(gradient) >= 1e-5) ):
#print(theta)
theta = theta - alpha * gradient
new_inter=new_inter+1
gradient = gradient_function(theta, X, y)
return theta
optimal = gradient_descent(X, y, alpha)
print('optimal:', optimal)
print('error function:', error_function(optimal, X, y)[0,0])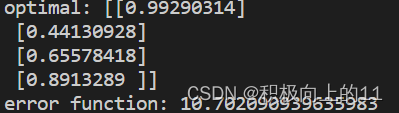
b和三个权重的权重分别为,0.99 0.44 0.65 0.89 误差项在10^1的数量级,在使用的时候应该注意调整学习率的参数,防止过拟合或无法完成迭代,会报出现缺失值的error
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











