







感知机
文章目录
一、感知机的基本原理
1.1 感知机学习的数学模型
感知机是根据输入实例的特征向量
x
x
x对其进行二类分类的线性分类模型,针对训练集数据:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
N
,
y
N
)
}
T = \{(x_1,y_1),(x_2,y_2),\dots,(x_N,y_N)\}
T={(x1,y1),(x2,y2),…,(xN,yN)}
其中,
x
i
∈
R
n
,
y
i
∈
{
−
1
,
1
}
,
i
=
1
,
2
,
…
,
N
x_i \in R^n,y_i \in \{-1,1\},i=1,2,\dots,N
xi∈Rn,yi∈{−1,1},i=1,2,…,N,则有感知机模型函数:
f ( x ) = sign ( w ⋅ x + b ) f(x)=\operatorname{sign}(w \cdot x+b) f(x)=sign(w⋅x+b)
感知机模型对应于输入空间(特征空间)中的分离超平面 w ⋅ x + b = 0 w \cdot x+b=0 w⋅x+b=0。其中,w是一个 n n n维向量,与 x x x维度相同, b b bd为一常数。
1.2 感知机的损失函数
感知机学习的策略是极小化损失函数:
min
w
,
b
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
\min _{w, b} L(w, b)=-\sum_{x_{i} \in M} y_{i}\left(w \cdot x_{i}+b\right)
w,bminL(w,b)=−xi∈M∑yi(w⋅xi+b)
M为误分类点的集合,损失函数对应于误分类点到分离超平面的总距离。
感知机学习算法是误分类驱动的,具体是采用随机梯度下降法。首先,任意选取一个超平面 w 0 , b 0 w_0,b_0 w0,b0,然后用梯度下降法不断极小化目标函数。极小化过程中不是一次使得集合 M M M中所有的误分类点的梯度下降,而是一次随机选取一个误分类点进行梯度下降。
对损失函数求梯度,有:
∇
w
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
x
i
∇
b
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
\nabla_wL(w,b) = -\sum_{x_i \in M}y_ix_i\\ \nabla_bL(w,b) = -\sum_{x_i \in M}y_i
∇wL(w,b)=−xi∈M∑yixi∇bL(w,b)=−xi∈M∑yi
随机选取一个误分类点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),对
w
,
b
w,b
w,b进行更新
w ← w + η y i x i b ← b + η y i w \leftarrow w + \eta y_ix_i\\ b \leftarrow b + \eta y_i w←w+ηyixib←b+ηyi
式中, η ( 0 ≤ η ≤ 1 ) \eta (0 \le \eta \le 1) η(0≤η≤1)是学习率。这样通过迭代可以使得损失函数 L ( w , b ) L(w,b) L(w,b)不断减少,直至为0
感知机学习算法是基于随机梯度下降法的对损失函数的最优化算法,有原始形式和对偶形式。
1.3 感知机学习算法的原始形式
原始形式中,首先任意选取一个超平面,然后用梯度下降法不断极小化目标函数。在这个过程中一次随机选取一个误分类点使其梯度下降。整个算法流程如下:
针对训练集数据:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
N
,
y
N
)
}
T = \{(x_1,y_1),(x_2,y_2),\dots,(x_N,y_N)\}
T={(x1,y1),(x2,y2),…,(xN,yN)}
其中,
x
i
∈
R
n
,
y
i
∈
{
−
1
,
1
}
,
i
=
1
,
2
,
…
,
N
x_i \in R^n,y_i \in \{-1,1\},i=1,2,\dots,N
xi∈Rn,yi∈{−1,1},i=1,2,…,N
有感知机模型函数: f ( x ) = sign ( w ⋅ x + b ) f(x)=\operatorname{sign}(w \cdot x+b) f(x)=sign(w⋅x+b)
- 选取初始值 w 0 , b 0 w_0,b_0 w0,b0(一般都取0作为初始值)
- 在训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
- 如果
y
i
(
w
⋅
x
i
+
b
)
≤
0
y_i(w \cdot x_i + b) \le 0
yi(w⋅xi+b)≤0
w ← w + η y i x i b ← b + η y i w \leftarrow w + \eta y_ix_i\\ b \leftarrow b + \eta y_i w←w+ηyixib←b+ηyi - 转至步骤2,直至训练集中没有误分类点
1.4 感知机学习算法的对偶形式
对偶性的基本思想是希望将
w
,
b
w,b
w,b表示为实例
x
i
,
y
i
x_i,y_i
xi,yi线性组合的形式。已知在感知机原始形式中,对误分类点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)参数迭代形式:
w
←
w
+
η
y
i
x
i
b
←
b
+
η
y
i
w \leftarrow w + \eta y_ix_i\\ b \leftarrow b + \eta y_i
w←w+ηyixib←b+ηyi
现在假设初始值
w
0
,
b
0
w_0,b_0
w0,b0均为0,则可修改迭代公式为:
w
←
η
y
i
x
i
b
←
η
y
i
w \leftarrow \eta y_ix_i\\ b \leftarrow \eta y_i
w←ηyixib←ηyi
则可知,第n次迭代时,
w
,
b
w,b
w,b关于
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的增量分别是
n
⋅
η
y
i
x
i
n \cdot \eta y_ix_i
n⋅ηyixi和
n
⋅
η
y
i
n \cdot \eta y_i
n⋅ηyi
假设 α i = n ⋅ η \alpha_i=n \cdot \eta αi=n⋅η,得增量表达式: α i y i x i \alpha_i y_ix_i αiyixi和 α i y i \alpha_i y_i αiyi因此最后学习到得 w , b w,b w,b可以用下式表达:
w
=
∑
i
=
1
N
α
i
y
i
x
i
b
=
∑
i
=
1
N
α
i
y
i
w = \sum_{i=1}^N \alpha_iy_ix_i\\ b = \sum_{i=1}^N \alpha_iy_i
w=i=1∑Nαiyixib=i=1∑Nαiyi
其中,N时迭代次数。对于每个实例点,如果其使得参数更新的次数越多,意味着其离超平面越近,即其越难被分类。
整个算法流程如下:
针对训练集数据:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
N
,
y
N
)
}
T = \{(x_1,y_1),(x_2,y_2),\dots,(x_N,y_N)\}
T={(x1,y1),(x2,y2),…,(xN,yN)}
其中,
x
i
∈
R
n
,
y
i
∈
{
−
1
,
1
}
,
i
=
1
,
2
,
…
,
N
x_i \in R^n,y_i \in \{-1,1\},i=1,2,\dots,N
xi∈Rn,yi∈{−1,1},i=1,2,…,N
有感知机模型函数: f ( x ) = sign ( ∑ i = 1 N α i y i x i ⋅ x + b ) f(x)=\operatorname{sign}( \sum_{i=1}^N \alpha_iy_ix_i \cdot x+b) f(x)=sign(∑i=1Nαiyixi⋅x+b)
- 选取初始值 α 0 , b 0 \alpha_0,b_0 α0,b0(一般都取0作为初始值)
- 在训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
- 如果
y
i
(
∑
j
=
1
N
α
j
y
j
x
j
⋅
x
i
+
b
)
≤
0
y_i(\sum_{j=1}^N \alpha_jy_jx_j \cdot x_i+b) \le 0
yi(∑j=1Nαjyjxj⋅xi+b)≤0
α j ← α j + η b ← b + η y i \alpha_j \leftarrow \alpha_j + \eta\\ b \leftarrow b + \eta y_i αj←αj+ηb←b+ηyi - 转至步骤2,直至训练集中没有误分类点
在本算法中,训练集实例仅以内积的形式出现。为了方便,可以预先将训练集中实例间的内积计算出来并以矩阵的形式存储,这就是所谓的Gram矩阵
G = ∥ x i ⋅ x j ∥ N × N G = \|x_i \cdot x_j \|_{N \times N} G=∥xi⋅xj∥N×N
1.5 感知机学习算法的收敛性
当训练数据集线性可分时,感知机学习算法是收敛的。感知机算法在训练数据集上的误分类次数 k k k满足不等式:
k ⩽ ( R γ ) 2 k \leqslant\left(\frac{R}{\gamma}\right)^{2} k⩽(γR)2
当训练数据集线性可分时,感知机学习算法存在无穷多个解,其解由于不同的初值或不同的迭代顺序而可能有所不同。
二、应用实例
计划需要完成四种分类问题:
- 使用感知机原始形式解决二维分类问题(可视化)
- 使用感知机对偶形式解决二维分类问题(可视化)
- 使用感知机原始形式算法解决四维分类问题
- 使用感知机对偶形式解决四维分类问题
2.1 使用感知机原始形式解决二维分类问题
# 导入所需库
import csv
import numpy as np
from matplotlib import pyplot as plt
2.1.1 Iris数据提取、抽取、分割和可视化
# 样本数据的抽取
with open('iris.data') as csv_file:
data = list(csv.reader(csv_file, delimiter=','))
label_map = {
'Iris-setosa': -1,
'Iris-versicolor': 1,
}
# 感知机解决二分类问题的标签一定为1或-1(因为sign函数),别为正实例点和负实例点,
# 抽取样本
X = np.array([[float(x) for x in s[:-1]] for s in data[:100]], np.float32) # X是一个四维数据,此处我们只去其两维
Y = np.array([[label_map[s[-1]]] for s in data[:100]], np.float32) #
# 样本可视化
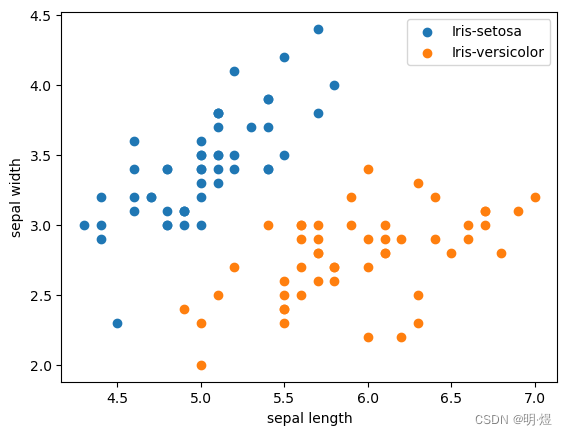
plt.scatter(X[:50, 0], X[:50, 1], label='Iris-setosa') # 前50个数据点为1类
plt.scatter(X[50:, 0], X[50:, 1], label='Iris-versicolor') # 后50个数据点为1类
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
# 分割数据集
# 将数据集按照8:2划分为训练集和测试集
train_idx = np.random.choice(100, 80, replace=False)
test_idx = np.array(list(set(range(100)) - set(train_idx)))
# train-训练集 test-测试集
X_train, Y_train = X[train_idx], Y[train_idx]
X_test, Y_test = X[test_idx], Y[test_idx]
2.1.2 训练
# 感知机学习类(原始形式)
class PerceptionMethod(object): # 定义 感知机学习类
def __init__(self, X, Y, eta): # 类中参数是 X,Y(X,Y)均为numpy数组,eta,eta是学习率
if X.shape[0] != Y.shape[0]: # 要求X,Y中的数目一样,即一个x对应一个y,否则返回错误
raise ValueError('Error,X and Y must be same when axis=0 ')
else: # 在类中储存参数
self.X = X
self.Y = Y
self.eta = eta
def ini_Per(self): # 感知机的原始形式
weight = np.zeros(self.X.shape[1]) # 初始化weight,b,np.zeros(size)表示生成0矩阵,weight的数据类型是array
b = 0
number = 0 # 记录训练次数
mistake = True # mistake是变量用来说明分类是否有错误
while mistake is True: # 当有错时
mistake = False # 开始下一轮纠错前需要将mistake变为true,一来判断这一轮是否有错误
for index in range(self.X.shape[0]): # 循环开始
if self.Y[index] * (weight @ self.X[index] + b) <= 0: # 错误判断条件 这里@表示的是矩阵运算的乘法
weight += self.eta * self.Y[index] * self.X[index] # 进行更新weight,b
b += self.eta * self.Y[index]
number += 1
mistake = True # 此轮检查出错误,表明mistake为true,进行下列一轮
break # 找出第一个错误后调出循环
return weight, b # 返回值
# 测试验证函数
def test(weight,b,X,Y):
num = 0 # 错误分类个数
for index in range(X.shape[0]): # 循环开始
if Y[index] * (weight @ X[index] + b) <= 0: # 错误判断条件 这里@表示的是矩阵运算的乘法
num += 1
return 1- num/(X.shape[0])
# 只使用训练集的两个维度
X_train_2 = X_train[:,0:2]
X_test_2 = X_test[:,0:2]
# 训练
PER = PerceptionMethod(X_train_2, Y_train, 1) # 类初始化
weight,b = PER.ini_Per()
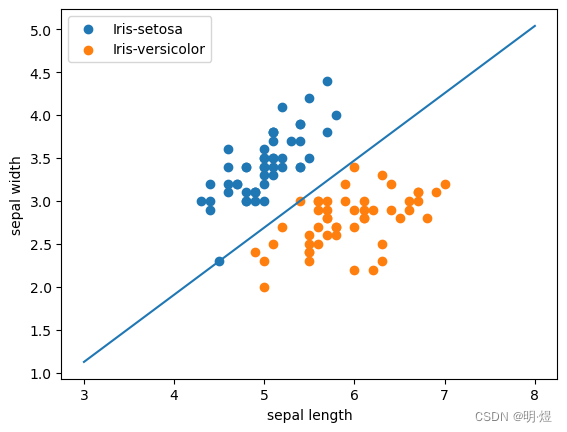
# 训练集可视化
plt.scatter(X[:50, 0], X [:50, 1], label='Iris-setosa') # 前50个数据点为1类
plt.scatter(X[50:, 0], X [50:, 1], label='Iris-versicolor') # 后50个数据点为1类
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
# 可视化分类平面
x = np.linspace(3, 8, 100)
y = -(weight[0]*x + b)/weight[1]
plt.plot(x, y)
2.1.3 测试
# 测试集验证
acc = test(weight,b,X_test_2,Y_test)
print('Test accuracy is', acc)
Test accuracy is 1.0
2.2 使用感知机对偶形式解决二维分类问题
2.2.1 Iris数据提取、抽取、分割和可视化
在上文已经完成
2.2.2 训练
# 感知机学习类(对偶形式)
import numpy as np
from matplotlib import pyplot as plt
class PerceptionMethod(object): # 定义 感知机学习类
def __init__(self, X, Y, eta): # 类中参数是 X,Y(X,Y)均为numpy数组,eta,eta是学习率
if X.shape[0] != Y.shape[0]: # 要求X,Y中的数目一样,即一个x对应一个y,否则返回错误
raise ValueError('Error,X and Y must be same when axis=0 ')
else: # 在类中储存参数
self.X = X
self.Y = Y
self.eta = eta
G = np.zeros((X.shape[0],X.shape[0]))
for i in range(X.shape[0]):
for j in range(X.shape[0]):
G[i,j] = X[i] @ X[j]
self.G = G
def ini_Per(self): # 感知机的原始形式
a = np.zeros(self.X.shape[0]) # 初始化weight,b,np.zeros(size)表示生成0矩阵,weight的数据类型是array
b = 0
number = 0 # 记录训练次数
mistake = True # mistake是变量用来说明分类是否有错误
while mistake is True: # 当有错时
mistake = False # 开始下一轮纠错前需要将mistake变为true,一来判断这一轮是否有错误
for index in range(self.X.shape[0]): # 循环开始
tmp = 0
for j in range(self.X.shape[0]):
tmp += a[j]*self.Y[j]*self.G[index,j]
if self.Y[index] * (tmp + b) <= 0: # 错误判断条件 这里@表示的是矩阵运算的乘法
a[index] += self.eta # 进行更新weight,b
b += self.eta * self.Y[index]
number += 1
mistake = True # 此轮检查出错误,表明mistake为true,进行下列一轮
break # 找出第一个错误后调出循环
return a, b # 返回值
# 测试验证函数
def test(weight,b,X,Y):
num = 0 # 错误分类个数
for index in range(X.shape[0]): # 循环开始
if Y[index] * (weight @ X[index] + b) <= 0: # 错误判断条件 这里@表示的是矩阵运算的乘法
num += 1
return 1- num/(X.shape[0])
# 只使用训练集的两个维度
X_train_2 = X_train[:,0:2]
X_test_2 = X_test[:,0:2]
# 训练
PER = PerceptionMethod(X_train_2, Y_train, 1) # 类初始化
a,b = PER.ini_Per()
weight = 0
for i in range(X_train_2.shape[0]): # 循环开始
weight += a[i]*X_train_2[i]*Y_train[i]
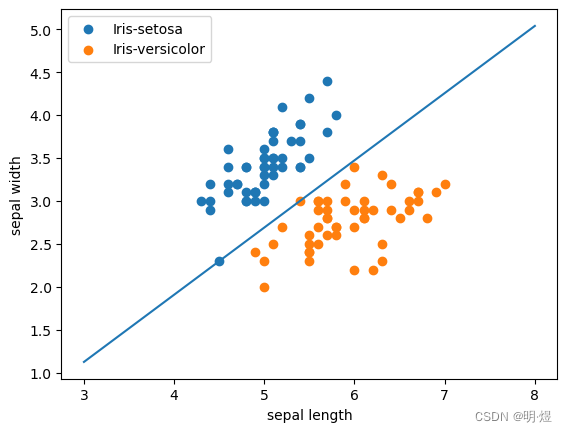
# 训练集可视化
plt.scatter(X[:50, 0], X [:50, 1], label='Iris-setosa') # 前50个数据点为1类
plt.scatter(X[50:, 0], X [50:, 1], label='Iris-versicolor') # 后50个数据点为1类
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
# 可视化分类平面
x = np.linspace(3, 8, 100)
y = -(weight[0]*x + b)/weight[1]
plt.plot(x, y)
2.2.3 测试集验证
acc = test(weight,b,X_test_2,Y_test)
print('Test accuracy is', acc)
Test accuracy is 1.0
2.3 使用感知机原始形式解决四维分类问题
2.3.1 Iris数据提取、抽取、分割和可视化
在上文已经完成
2.3.2 训练
# 感知机学习类(原始形式)
class PerceptionMethod(object): # 定义 感知机学习类
def __init__(self, X, Y, eta): # 类中参数是 X,Y(X,Y)均为numpy数组,eta,eta是学习率
if X.shape[0] != Y.shape[0]: # 要求X,Y中的数目一样,即一个x对应一个y,否则返回错误
raise ValueError('Error,X and Y must be same when axis=0 ')
else: # 在类中储存参数
self.X = X
self.Y = Y
self.eta = eta
def ini_Per(self): # 感知机的原始形式
weight = np.zeros(self.X.shape[1]) # 初始化weight,b,np.zeros(size)表示生成0矩阵,weight的数据类型是array
b = 0
number = 0 # 记录训练次数
mistake = True # mistake是变量用来说明分类是否有错误
while mistake is True: # 当有错时
mistake = False # 开始下一轮纠错前需要将mistake变为true,一来判断这一轮是否有错误
for index in range(self.X.shape[0]): # 循环开始
if self.Y[index] * (weight @ self.X[index] + b) <= 0: # 错误判断条件 这里@表示的是矩阵运算的乘法
weight += self.eta * self.Y[index] * self.X[index] # 进行更新weight,b
b += self.eta * self.Y[index]
number += 1
mistake = True # 此轮检查出错误,表明mistake为true,进行下列一轮
break # 找出第一个错误后调出循环
return weight, b # 返回值
# 测试验证函数
def test(weight,b,X,Y):
num = 0 # 错误分类个数
for index in range(X.shape[0]): # 循环开始
if Y[index] * (weight @ X[index] + b) <= 0: # 错误判断条件 这里@表示的是矩阵运算的乘法
num += 1
return 1- num/(X.shape[0])
# 使用训练集的四个维度
# 训练
PER = PerceptionMethod(X_train, Y_train, 1) # 类初始化
weight,b = PER.ini_Per()
2.3.3 测试
acc = test(weight,b,X_test,Y_test)
print('Test accuracy is', acc)
Test accuracy is 1.0
2.4 使用感知机对偶形式解决四维分类问题
2.4.1 Iris数据提取、抽取、分割和可视化
在上文已经完成
2.4.2 训练
# 感知机学习类(对偶形式)
import numpy as np
from matplotlib import pyplot as plt
class PerceptionMethod(object): # 定义 感知机学习类
def __init__(self, X, Y, eta): # 类中参数是 X,Y(X,Y)均为numpy数组,eta,eta是学习率
if X.shape[0] != Y.shape[0]: # 要求X,Y中的数目一样,即一个x对应一个y,否则返回错误
raise ValueError('Error,X and Y must be same when axis=0 ')
else: # 在类中储存参数
self.X = X
self.Y = Y
self.eta = eta
G = np.zeros((X.shape[0],X.shape[0]))
for i in range(X.shape[0]):
for j in range(X.shape[0]):
G[i,j] = X[i] @ X[j]
self.G = G
def ini_Per(self): # 感知机的原始形式
a = np.zeros(self.X.shape[0]) # 初始化weight,b,np.zeros(size)表示生成0矩阵,weight的数据类型是array
b = 0
number = 0 # 记录训练次数
mistake = True # mistake是变量用来说明分类是否有错误
while mistake is True: # 当有错时
mistake = False # 开始下一轮纠错前需要将mistake变为true,一来判断这一轮是否有错误
for index in range(self.X.shape[0]): # 循环开始
tmp = 0
for j in range(self.X.shape[0]):
tmp += a[j]*self.Y[j]*self.G[index,j]
if self.Y[index] * (tmp + b) <= 0: # 错误判断条件 这里@表示的是矩阵运算的乘法
a[index] += self.eta # 进行更新weight,b
b += self.eta * self.Y[index]
number += 1
mistake = True # 此轮检查出错误,表明mistake为true,进行下列一轮
break # 找出第一个错误后调出循环
return a, b # 返回值
# 测试验证函数
def test(weight,b,X,Y):
num = 0 # 错误分类个数
for index in range(X.shape[0]): # 循环开始
if Y[index] * (weight @ X[index] + b) <= 0: # 错误判断条件 这里@表示的是矩阵运算的乘法
num += 1
return 1- num/(X.shape[0])
# 使用训练集的四个维度
# 训练
PER = PerceptionMethod(X_train, Y_train, 1) # 类初始化
a,b = PER.ini_Per()
weight = 0
for i in range(X_train.shape[0]): # 循环开始
weight += a[i]*X_train[i]*Y_train[i]
print(weight)
[-1.3999987 -5.1000004 8. 4.1000004]
2.4.3 测试
acc = test(weight,b,X_test,Y_test)
print('Test accuracy is', acc)
Test accuracy is 1.0














 1865
1865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









