






yolov7:安装配置以及训练自己的数据集
1.安装并测试yolov7
1.下载yolov7源码及yolov7权重
源码和权重在github上下载,权重下载完放在yolov7源码根目录
https://github.com/WongKinYiu/yolov7
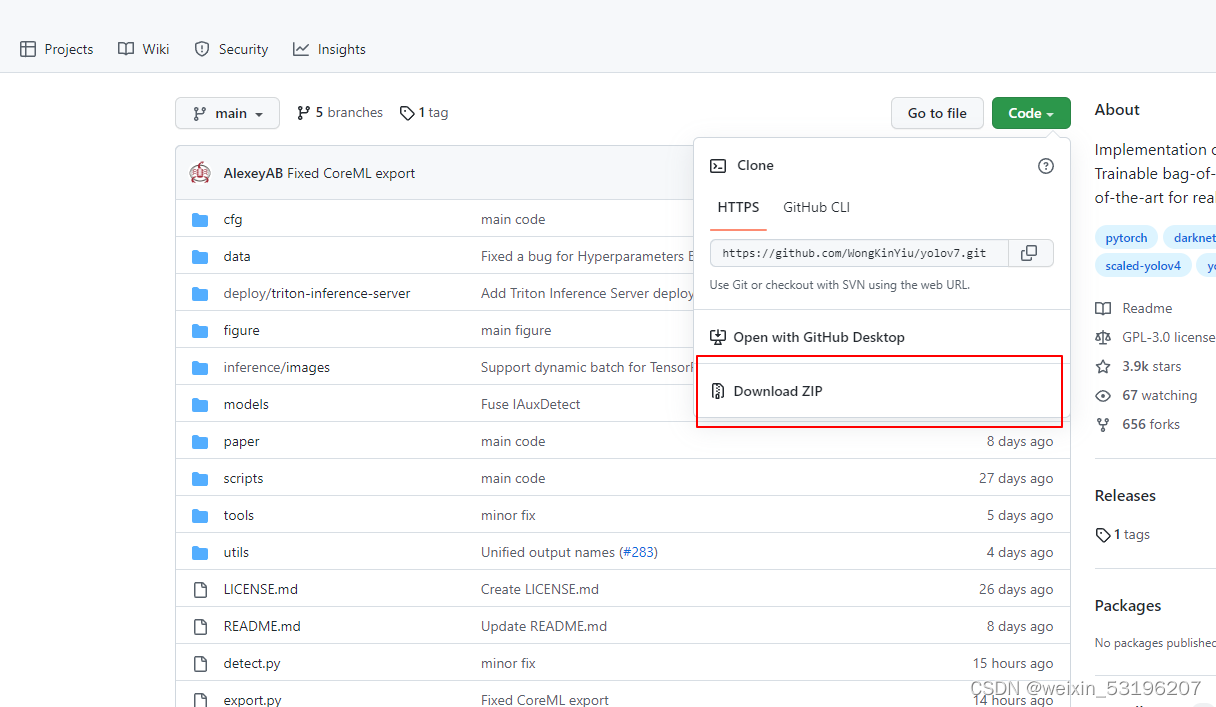
不方便的下载百度云连接:
链接:https://pan.baidu.com/s/1eT2dkvYJBxwIER1bGNtGZQ
提取码:ytkm
下载完源码和权重后在pycharm中打开。
2.环境配置
在Anconda中创造Yolov7环境:
激活Yolov7环境 并安装Yolov7所需各种包,采用清华镜像源安装所需包,在终端中执行命令
activate yolov7
pip install -r F:\objectdet\yolov7-main/requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
将requirements.txt路径改为源码中requirements.txt所在路径。
如果完全按照requirements.txt来安装的话,你会发现安装的torch版本并不是gpu版本,所以得重新安装gpu版本的才能用你的gpu来训练Yolov7
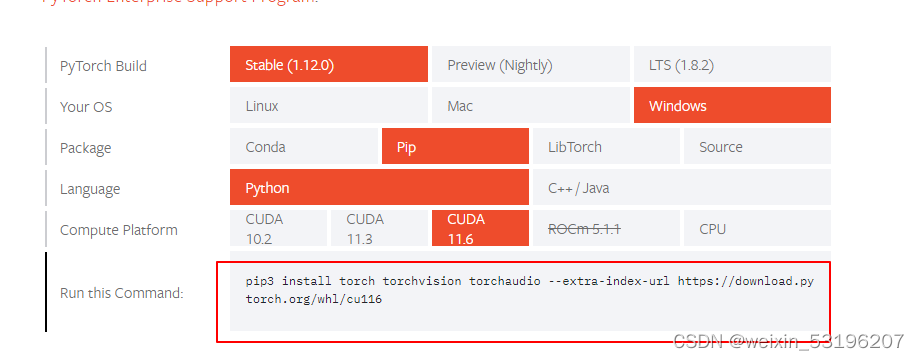
安装pytorch
进入pytorch官网:Start Locally | PyTorch
根据版本选择,然后在终端中输入红框所示指令
在终端中输入pip list查看安装的包
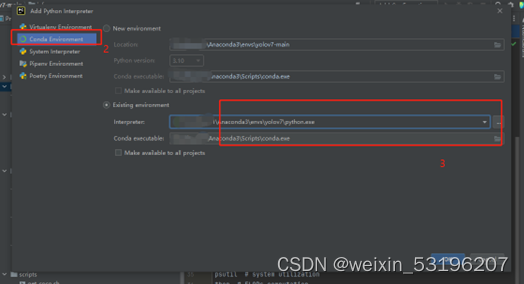
在pycharm中安装环境
3.测试
运行detect.py,可进行测试。
测试文件在inference文件夹下,可修改测试内容
2.样本标注软件labelimg的安装和使用
1.安装labelimg:ctrl+R输入cmd打开终端输入命令行快速安装。
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
2.打开labelimg:在命令行中输入快速打开。
labelimg
3.基本使用方法:
主要操作:打开软件后选择标注图片目录和存放标注XML格式文件目录,按W画框框住目标后进行标注,将目标逐一标注完后按D切换至下一张,保存文件为XML格式,可用文本编辑器打开。
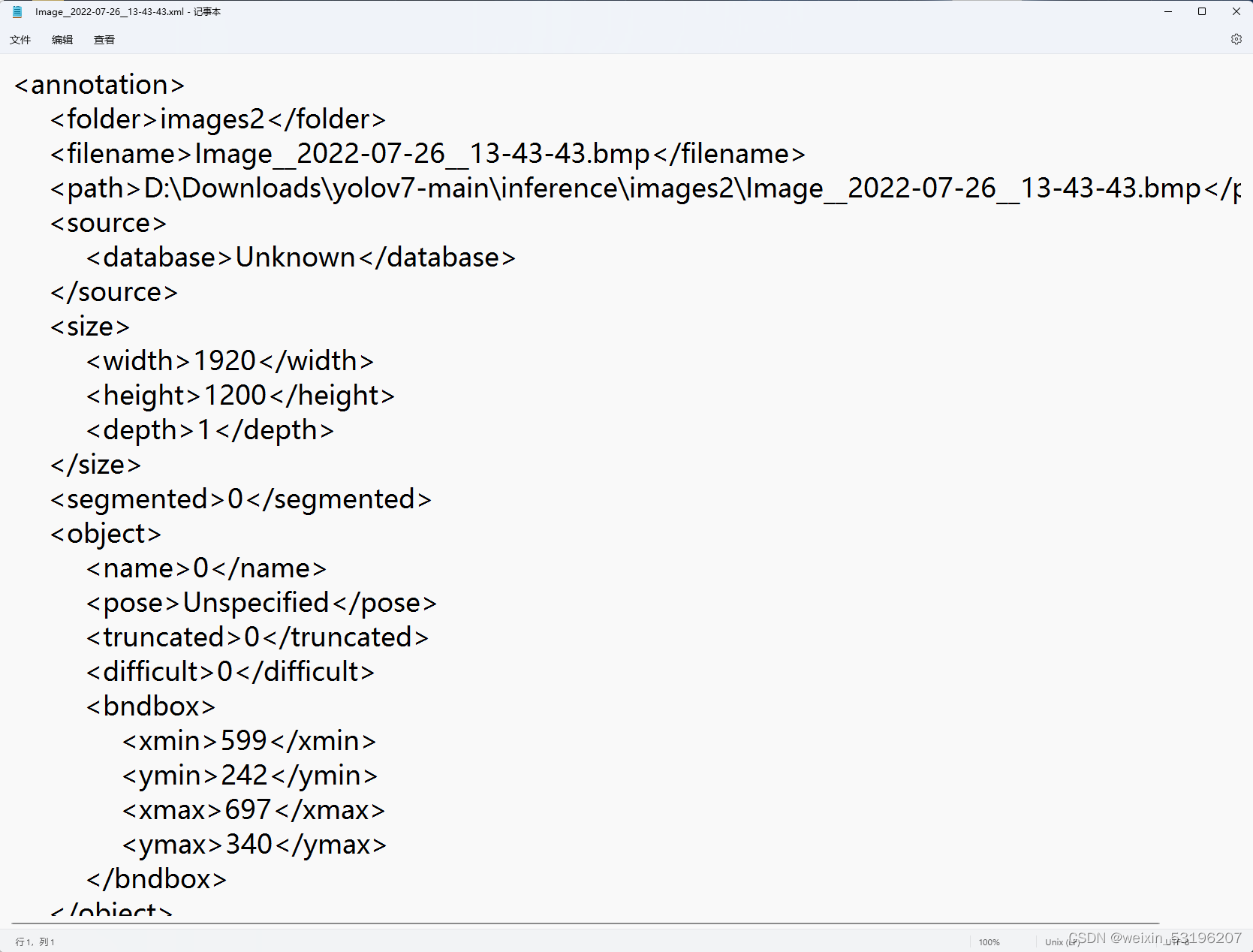
基本快捷键:按W快捷键画框,按A和D切换下一张,ctrl+滚轮调整图片大小,左键拖动,ctrl+S保存。

建议设置:建议打开自动保存方便保存和显示标注框和标签防止标错。
注意:如果在labelimg中打不开XML文件可能是新旧版本问题,可尝试将路径改为英文路径。
3.训练自己的数据
1.转换数据
我们需要将用标注软件生成的XML格式文件转为TXT文件。
我们先根据以下格式创建文件夹。
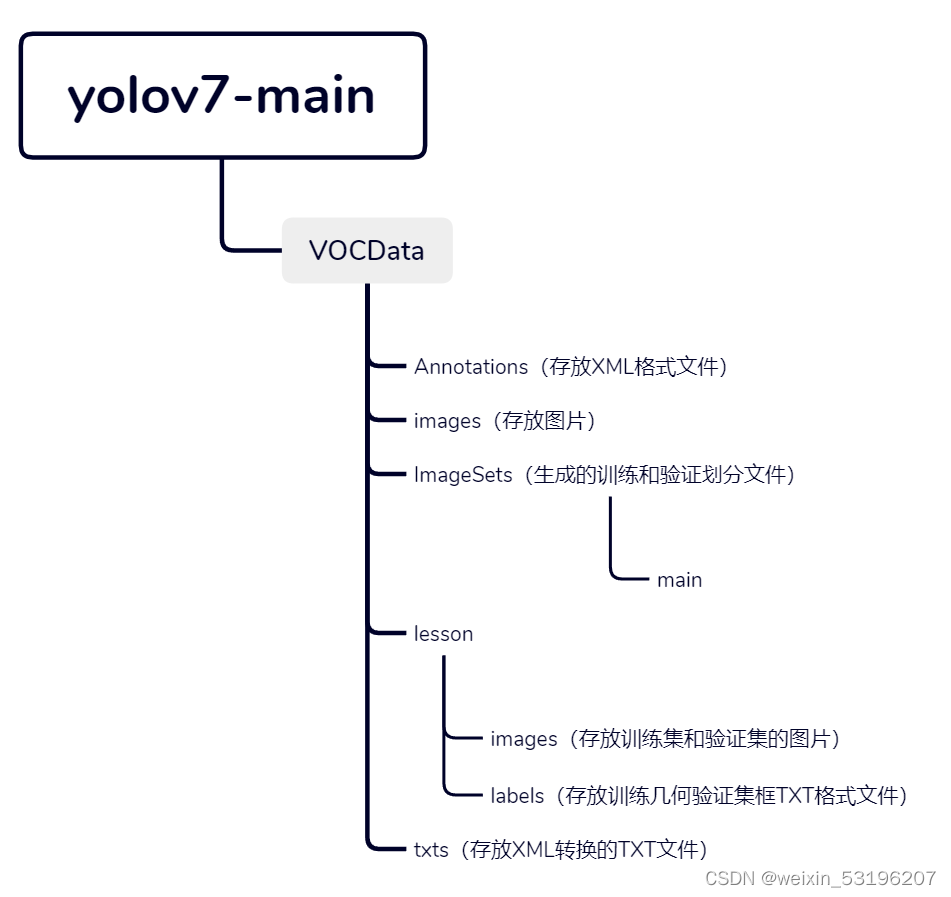
将图片和标注文件分别放到images和Annotations文件夹中。
运行代码text_yolo.py,代码如下,注意修改class_names,xmlpath,txtpath。
import os.path
import xml.etree.ElementTree as ET
class_names = ['0','1','2','3','4','5','6','7','8','A','B','C','D','E','F','G','H','I','J','K','L',
'M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z','&']
xmlpath = "D:\\Downloads\\yolov7-main\\VOCData\\Annotations\\" # 原xml路径
txtpath = "D:\\Downloads\\yolov7-main\\VOCData\\txts\\" # 转换后txt文件存放路径
files = []
if not os.path.exists(txtpath):
os.makedirs(txtpath)
for root, dirs, files in os.walk(xmlpath):
None
number = len(files)
#number = 409 # 若无法识别可手动输入数据集数量
print(number)
i = 0
while i < number:
name = files[i][0:-4]
xml_name = name + ".xml"
txt_name = name + ".txt"
print(name)
xml_file_name = xmlpath + xml_name
txt_file_name = txtpath + txt_name
xml_file = open(xml_file_name,"rb")
tree = ET.parse(xml_file)
root = tree.getroot()
# filename = root.find('name').text
# image_name = root.find('filename').text
w = int(root.find('size').find('width').text)
h = int(root.find('size').find('height').text)
f_txt = open(txt_file_name, 'w+')
content = ""
first = True
for obj in root.iter('object'):
name = obj.find('name').text
class_num = class_names.index(name)
xmlbox = obj.find('bndbox')
x1 = int(xmlbox.find('xmin').text)
x2 = int(xmlbox.find('xmax').text)
y1 = int(xmlbox.find('ymin').text)
y2 = int(xmlbox.find('ymax').text)
if first:
content += str(class_num) + " " + \
str((x1 + x2) / 2 / w) + " " + str((y1 + y2) / 2 / h) + " " + \
str((x2 - x1) / w) + " " + str((y2 - y1) / h)
first = False
else:
content += "\n" + \
str(class_num) + " " + \
str((x1 + x2) / 2 / w) + " " + str((y1 + y2) / 2 / h) + " " + \
str((x2 - x1) / w) + " " + str((y2 - y1) / h)
# print(str(i / (number - 1) * 100) + "%\n")
print(content)
f_txt.write(content)
f_txt.close()
xml_file.close()
i += 1
TXT文件夹结果:
左边数字表示类的序号
2.划分训练集和验证集
在ImagesSets/Main下生成train.txt,val.txt。
运行代码split_train_val.py,代码如下,注意修改xmlfilepath,saveBasePath。
import os
import random
random.seed(0)
xmlfilepath = 'D:\\Downloads\\yolov7-main\\VOCData\\Annotations'
saveBasePath ='D:\\Downloads\\yolov7-main\\VOCData\\ImageSets\\main'
# ----------------------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# train_percent不需要修改
# ----------------------------------------------------------------------#
trainval_percent = 1
train_percent = 0.8
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("traub suze", tr)
ftrainval = open(os.path.join(saveBasePath, 'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, 'train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
3.生成最终结果
根据train.txt和val.txt将图片和txt分别复制到labels和images。
运行代码clauculate_anchors.py,代码如下,注意修改各种路径,以及图片的后缀名。
import os
import shutil
from tqdm import tqdm
SPLIT_PATH = "D:\\Downloads\\yolov7-main\\VOCData\\ImageSets\\main\\"
IMGS_PATH = "D:\\Downloads\\yolov7-main\\VOCData\\images\\"
TXTS_PATH = "D:\\Downloads\\yolov7-main\\VOCData\\txts\\"
TO_IMGS_PATH = "D:\\Downloads\\yolov7-main\\VOCData\\lesson\\images\\"
TO_TXTS_PATH = "D:\\Downloads\\yolov7-main\\VOCData\\lesson\\labels\\"
data_split = ['train.txt', 'val.txt']
to_split = ['train2017', 'val2017']
for index, split in enumerate(data_split):
split_path = os.path.join(SPLIT_PATH, split)
to_imgs_path = os.path.join(TO_IMGS_PATH, to_split[index])
if not os.path.exists(to_imgs_path):
os.makedirs(to_imgs_path)
to_txts_path = os.path.join(TO_TXTS_PATH, to_split[index])
if not os.path.exists(to_txts_path):
os.makedirs(to_txts_path)
f = open(split_path, 'r')
count = 1
for line in tqdm(f.readlines(), desc="{} is copying".format(to_split[index])):
# 复制图片
src_img_path = os.path.join(IMGS_PATH, line.strip() + '.bmp')
dst_img_path = os.path.join(to_imgs_path, line.strip() + '.bmp')
if os.path.exists(src_img_path):
shutil.copyfile(src_img_path, dst_img_path)
else:
print("error file: {}".format(src_img_path))
# 复制txt标注文件
src_txt_path = os.path.join(TXTS_PATH, line.strip() + '.txt')
dst_txt_path = os.path.join(to_txts_path, line.strip() + '.txt')
if os.path.exists(src_txt_path):
shutil.copyfile(src_txt_path, dst_txt_path)
else:
print("error file: {}".format(src_txt_path))
最终结果:
Lesion/images/train2017 中存放的是所有训练图片
Lesion/images/val2017 中存放的是所有验证图片
Lesion/labels/train2017 中存放的是所有训练图片的目标框txt
Lesion/labels/val2017 中存放的是所有验证图片的目标框txt
4.创建myData.yaml
在data文件夹中复制一份coco.yaml重命名为myData.yaml,以此为蓝本修改训练集,验证集,类数,类名。
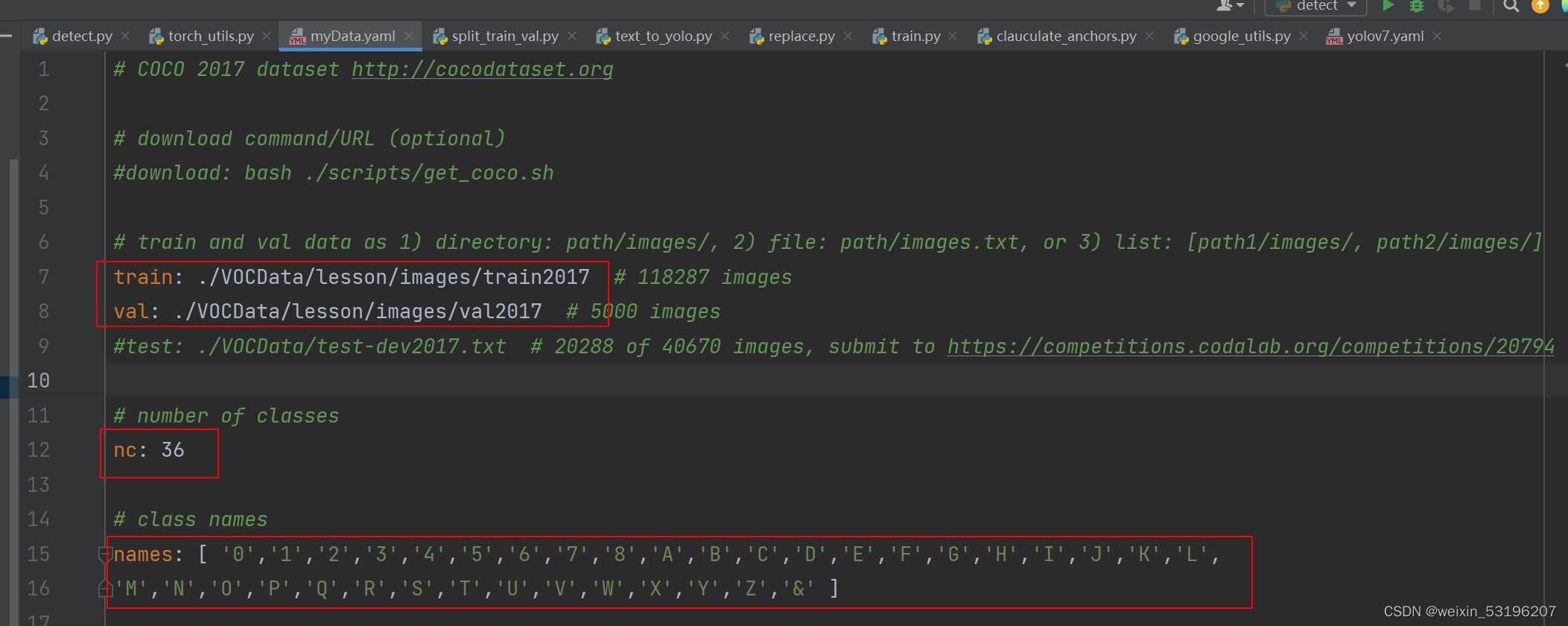
注意train.py中使用的权重
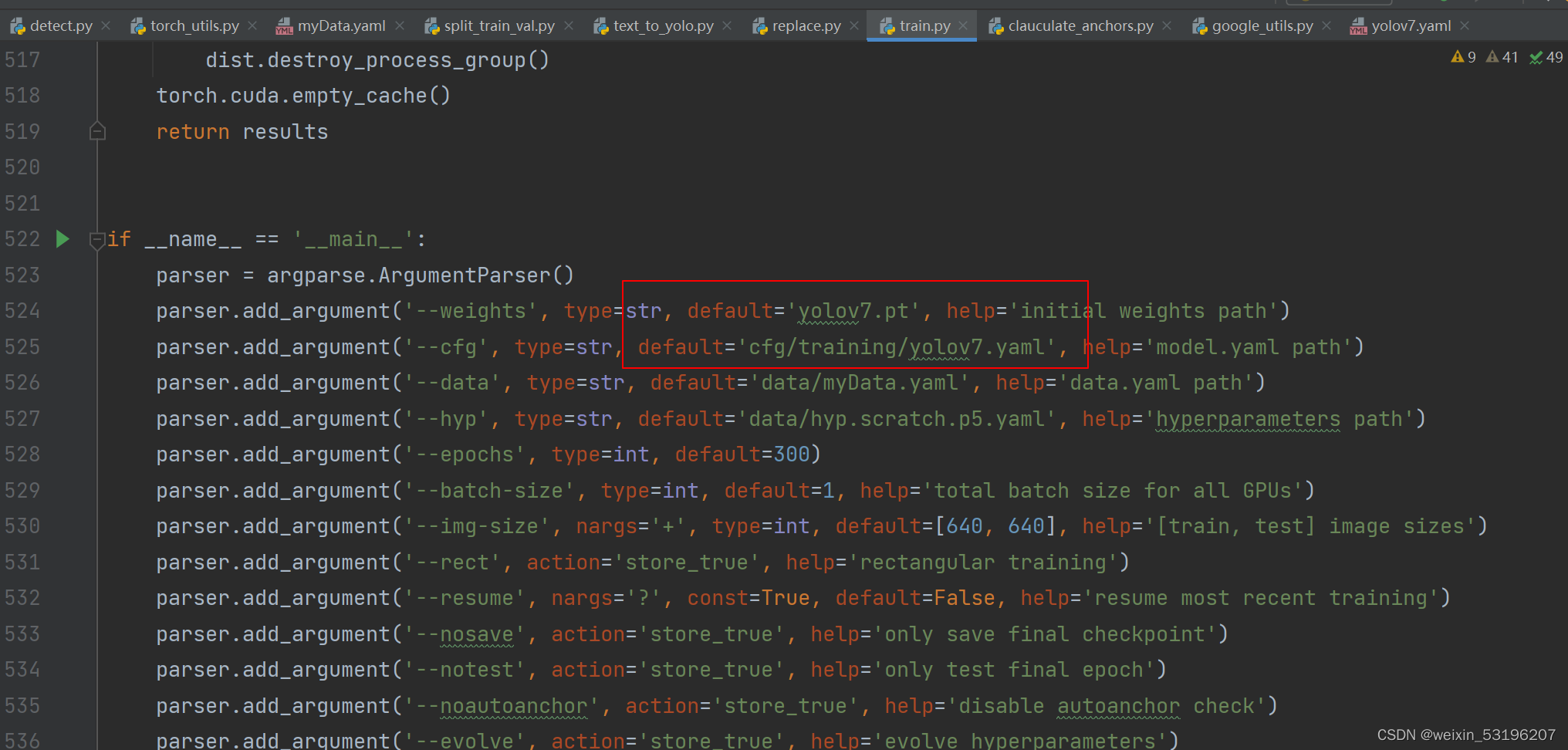
修改使用权重中类数
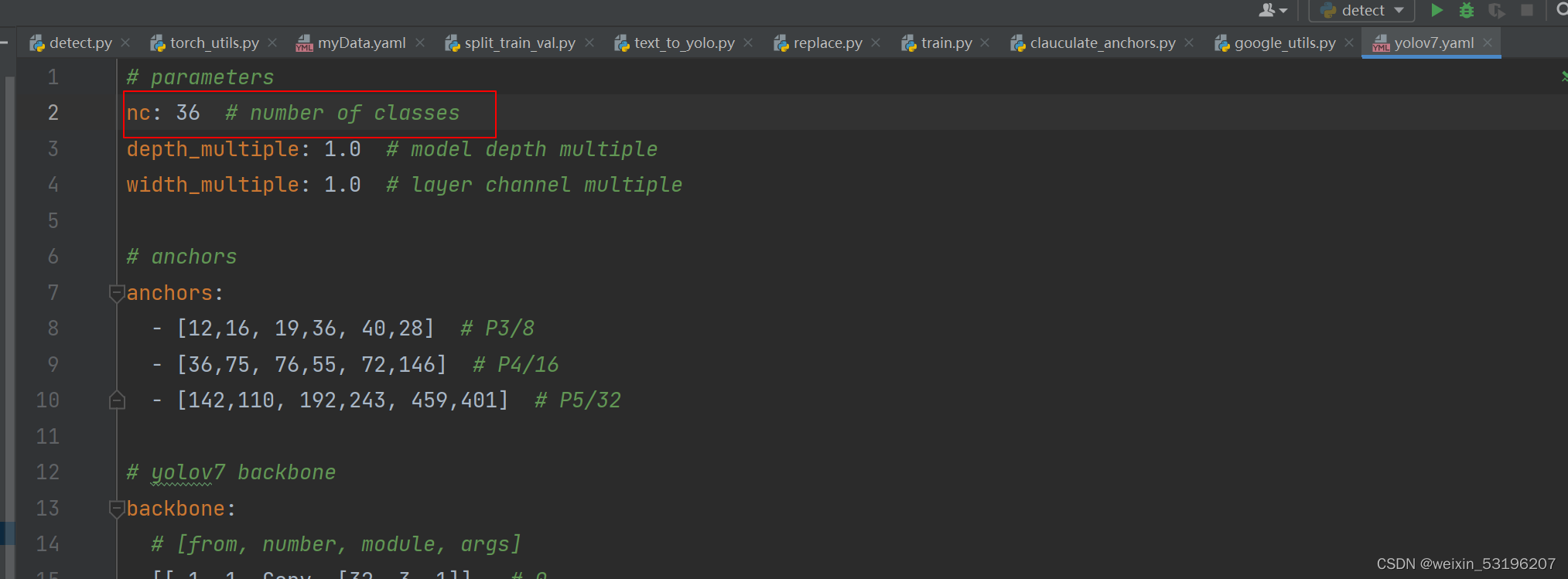
根据计算机的性能选择黄框内参数,如果报错out of memory 错误,可能是电脑显存不足,也可能是cuda自身限制函数。可以将调低batch-size,至少为1或者将图片大小调小。其他参数可以参照我的数据修改,主要修改红框数据。
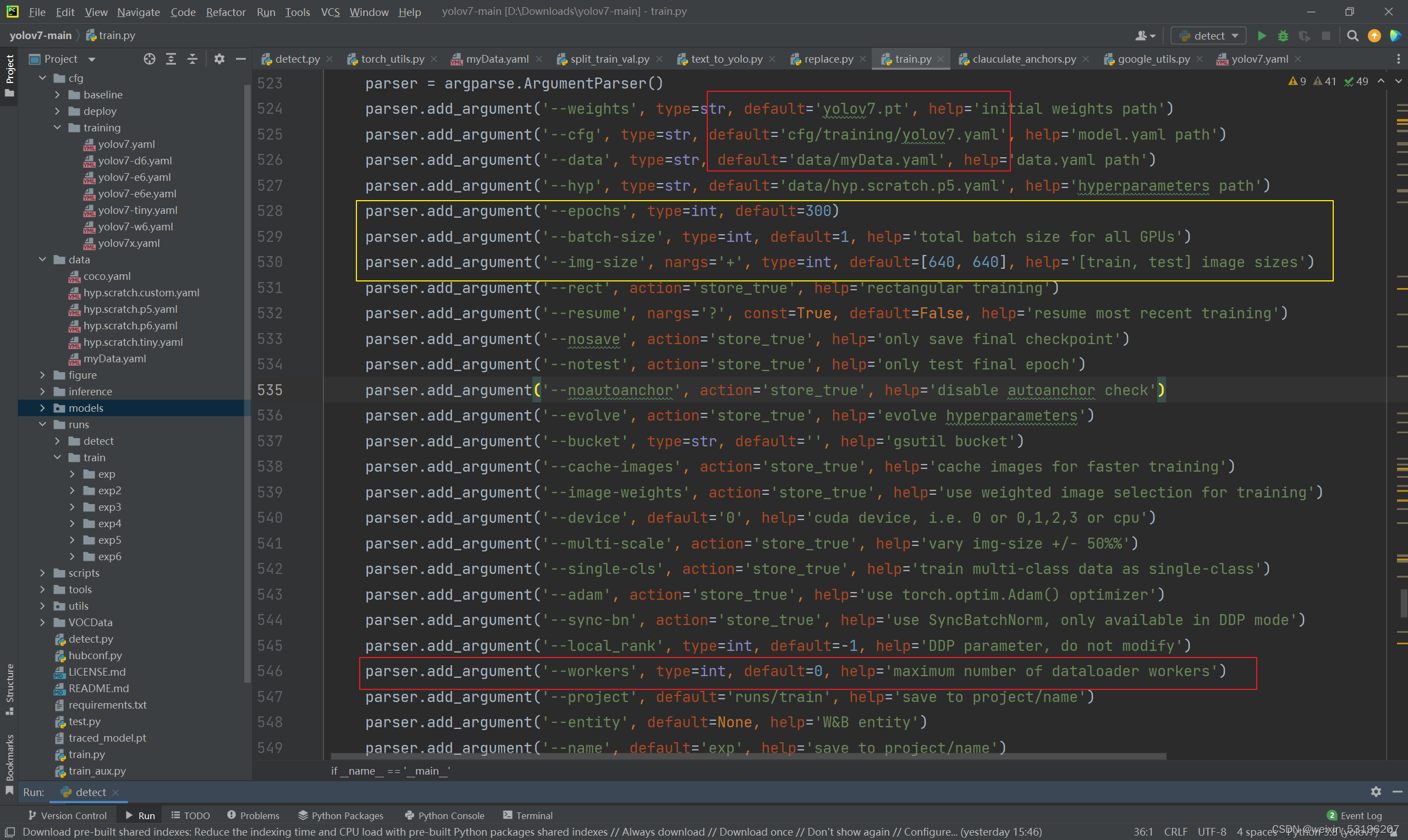
设置完成无误后运行train.py,开始训练,结果保存在runs/train/exp下。
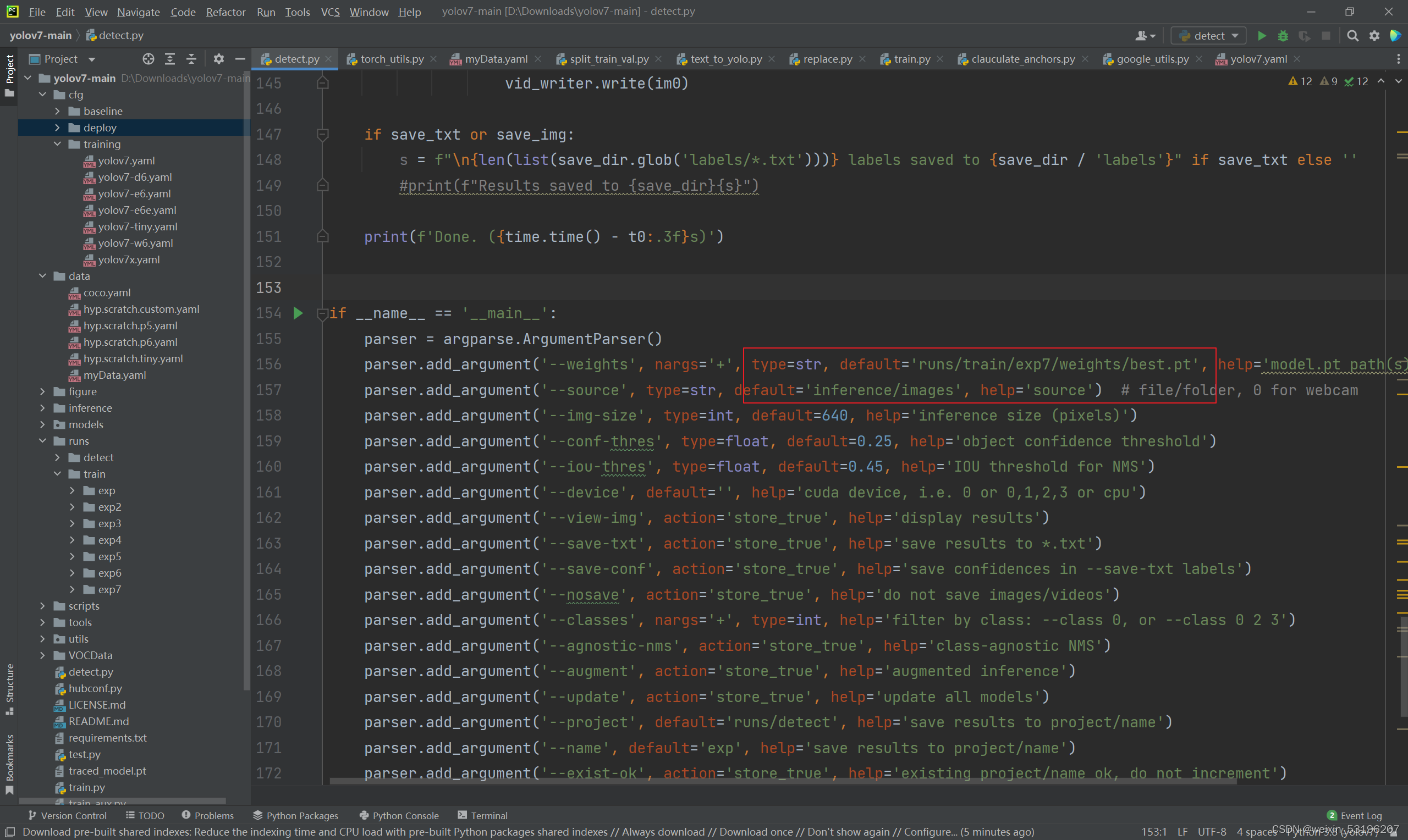
5.测试
训练完后用detect.py进行测试,修改权重和路径,将权重改为训练所得pt文件(结果在runs/train/exp/weights/下)
 #### 6.生成onnx格式文件
#### 6.生成onnx格式文件
1.安装依赖库:
在打开终端命令行中快速安装:
pip install onnx coremltools onnx-simplifier
2.生成onnx格式文件:
打开终端在命令行中输入:
python models/export.py --weights runs\train\exp7\weights\best.pt --img 640 --batch 1
python models/export.py --weights ..\runs\train\exp7\weights\best.pt --include onnx
img-q45V08nG-1681695911482)]
6.生成onnx格式文件
1.安装依赖库:
在打开终端命令行中快速安装:
pip install onnx coremltools onnx-simplifier
2.生成onnx格式文件:
打开终端在命令行中输入:
python models/export.py --weights runs\train\exp7\weights\best.pt --img 640 --batch 1
python models/export.py --weights ..\runs\train\exp7\weights\best.pt --include onnx
注意修改训练得到的pt文件路径,生成onnx文件是pt文件大小的两倍左右,如果不是可能是哪里有问题。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









