一、Prometheus介绍
1、Prometheus简介
Prometheus是由前 Google 工程师从 2012 年开始在Soundcloud以开源软件的形式进行研发的系统监控和告警工具包,自此以后,许多公司和组织都采用了 Prometheus 作为监控告警工具。Prometheus 的开发者和用户社区非常活跃,它现在是一个独立的开源项目,可以独立于任何公司进行维护。为了证明这一点,Prometheus 于 2016 年 5 月加入CNCF基金会,成为继Kubernetes之后的第二个 CNCF 托管项目。
2、Prometheus优势
Prometheus 的主要优势有:
由指标名称和和键/值对标签标识的时间序列数据组成的多维数据模型。
强大的查询语言 PromQL。
不依赖分布式存储;单个服务节点具有自治能力。
时间序列数据是服务端通过 HTTP 协议主动拉取获得的。
也可以通过中间网关来推送时间序列数据。
可以通过静态配置文件或服务发现来获取监控目标。
支持多种类型的图表和仪表盘。
3、Prometheus组件
Prometheus Server:
Prometheus的服务端,负责收集指标和存储时间序列数据,并提供查询接口。
和zabbix不同是,zabix server本身并不存储数据,依赖于外部数据库比如mysql,pgsql等。
Prometheus targets:
Prometheus将要监控的目标,可以类比于zabbix_agent。
Pushgateway:
短期存储指标数据,主要用于临时性的任务,比如备份数据库任务监控等。也可以用于自定义监控等度量值。
Server discovery
服务发现,例如配置动态的服务监控,无需重启Prometheus Server。
Altertmanager:
支持报警功能,比如支持邮件,微信,钉钉报警。
Prometheus Web UI:
Prometheus Server Web查询接口,需要写PromQL语句。后期可以使用Grafana替换。
4、Prometheus架构
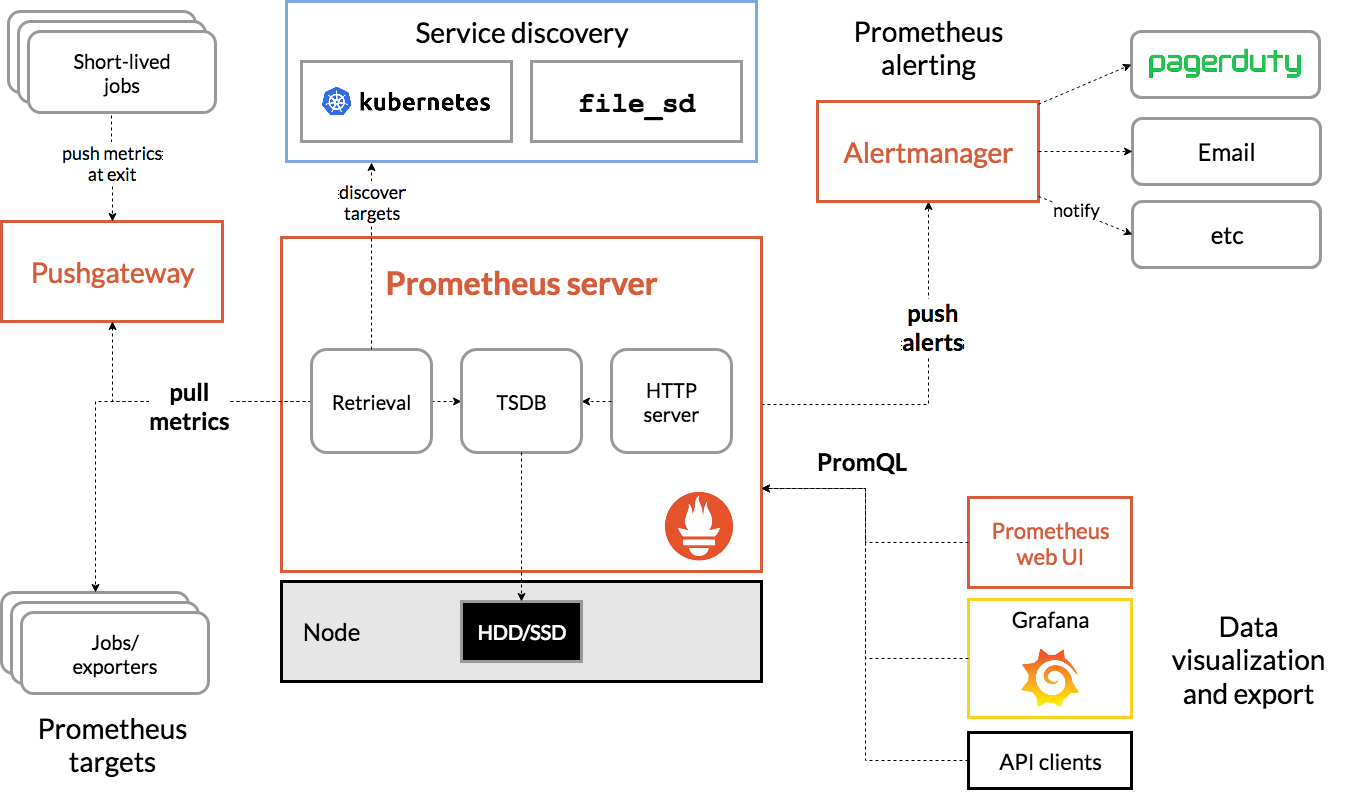
Prometheus 的整体架构以及生态系统组件如下图所示:
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化。
5、Prometheus应用场景
Prometheus 适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。Prometheus 是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
二、体验Prometheus
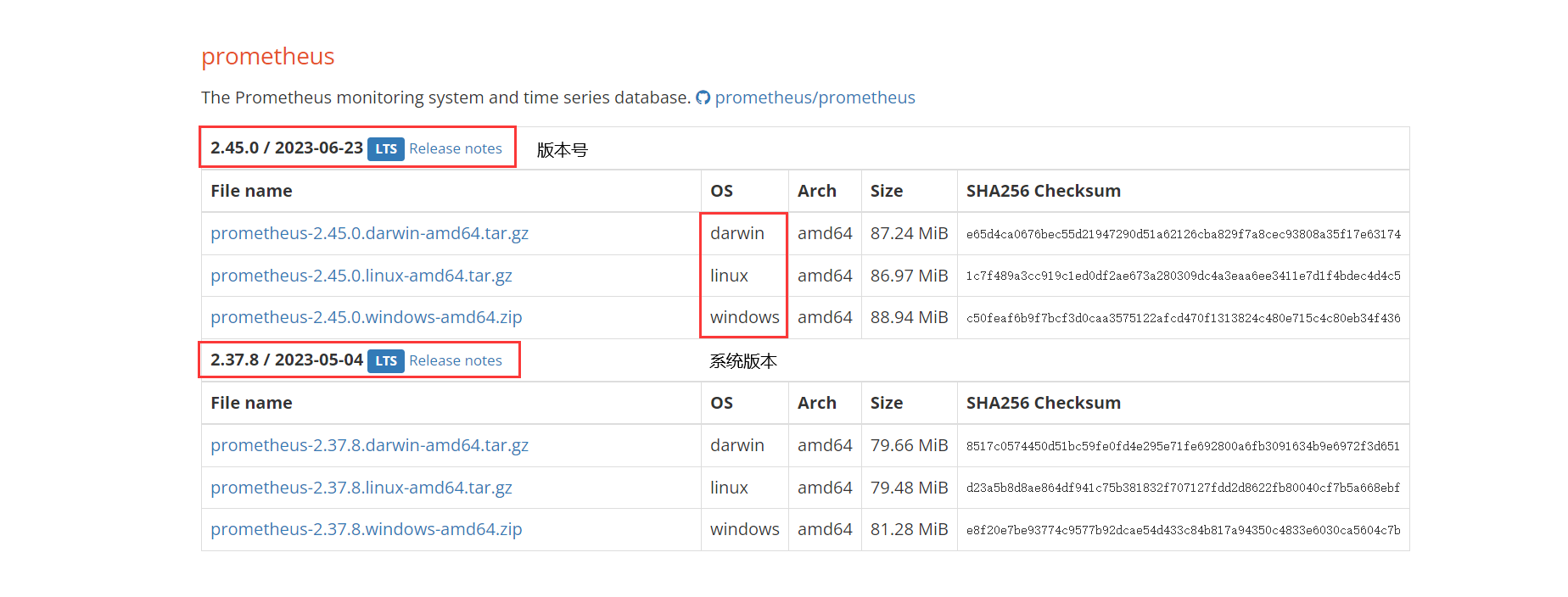
1、下载安装包
下载地址:Download | Prometheus

2、启动Prometheus
# 解压安装包
tar xvfz prometheus-*.tar.gz
# 进入目录
cd prometheus-*
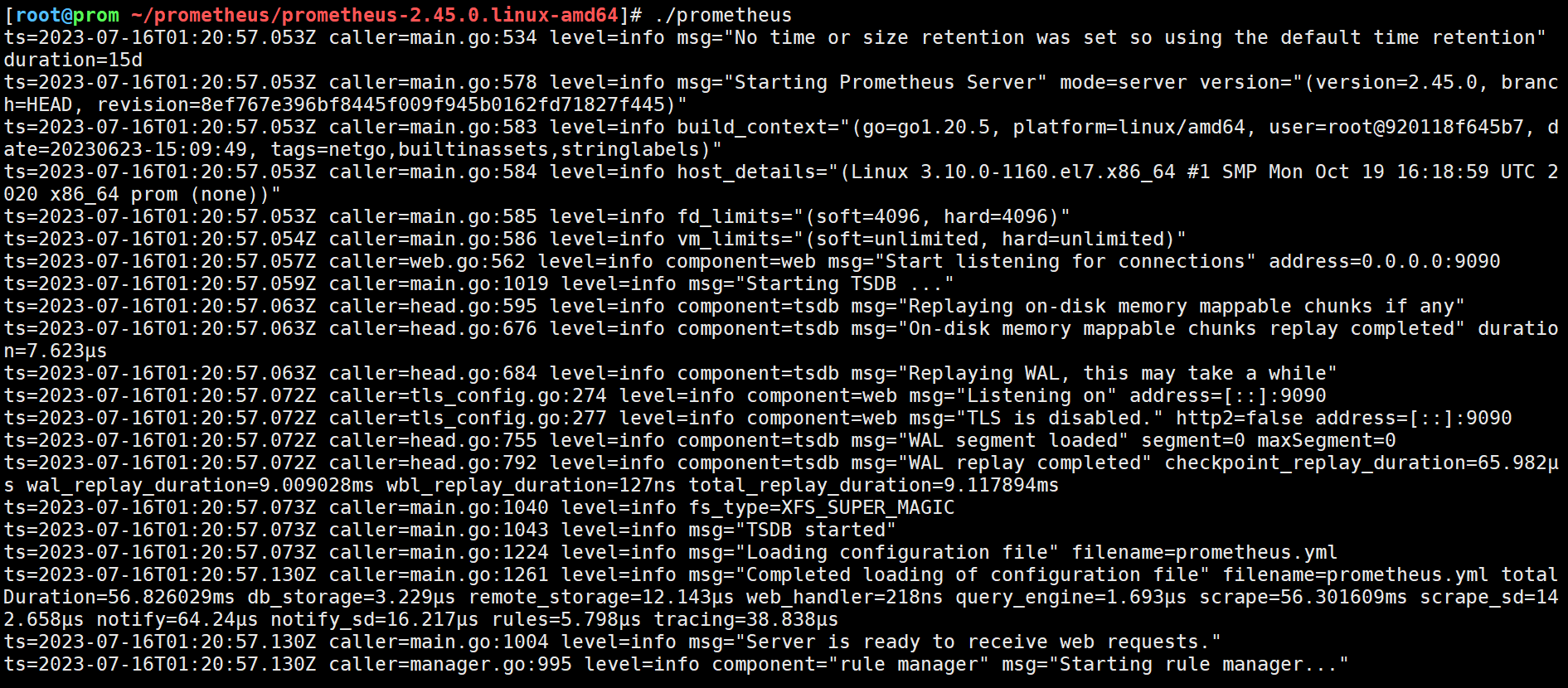
# 启动Prometheus
./prometheus
# 启动之后会监听本地的9090端口,浏览器访问ip:9090即可访问到Prometheus的webUI界面了
3、启动Prometheus时的参数
--config.file="prometheus.yml"
指定prometheus server配置文件。
--web.listen-address="0.0.0.0:9090"
指定服务器的监听端口。
--web.read-timeout=5m
请求连接最大的等待时间,防止太多空闲连接占用资源。
--web.max-connections=512
最大网络连接数量,可以适当该小,比如10。
--storage.tsdb.path="data/"
指定数据的存储路径,建议使用性能较好的磁盘。
--storage.tsdb.retention.time=STORAGE.TSDB.RETENTION.TIME
官方已废弃"--storage.tsdb.retention"参数,我们可以使用它来指定数据的保存周期。
默认保留15天的数据,通常情况下是不需要修改的,支持的单位有: y, w, d, h, m, s, ms。
如果工作中有需要看几个月前的数据,那需要适当调大该参数,这意味着会占用额外的存储空间。
--query.timeout=2m
可以防止用户查询语句出现慢查询超过2分钟后会自动终止PromQL的执行。
--query.max-concurrency=20
防止太多的用户并发查询。
--log.level=info
指定日志的级别,支持的值有debug, info, warn, error。
更多参数详情请参考:
./prometheus -h
4、编写systemd启动文件(Prometheus server)
cat > /etc/sysconfig/prometheus <<'EOF'
PROMETHEUS_HOME=/root/prometheus-2.45.0.linux-amd64
EOF
cat > /usr/lib/systemd/system/prometheus.service <<'EOF'
[Unit]
After=network.target
[Service]
EnvironmentFile=/etc/sysconfig/prometheus
ExecStart=/root/prometheus-2.45.0.linux-amd64/prometheus \
--config.file=${PROMETHEUS_HOME}/prometheus.yml \
--web.listen-address=0.0.0.0:9090 \
--storage.tsdb.path=${PROMETHEUS_HOME}/data \
--web.max-connections=10 \
--storage.tsdb.retention.time=15d \
--log.level=info \
--web.read-timeout=5m
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
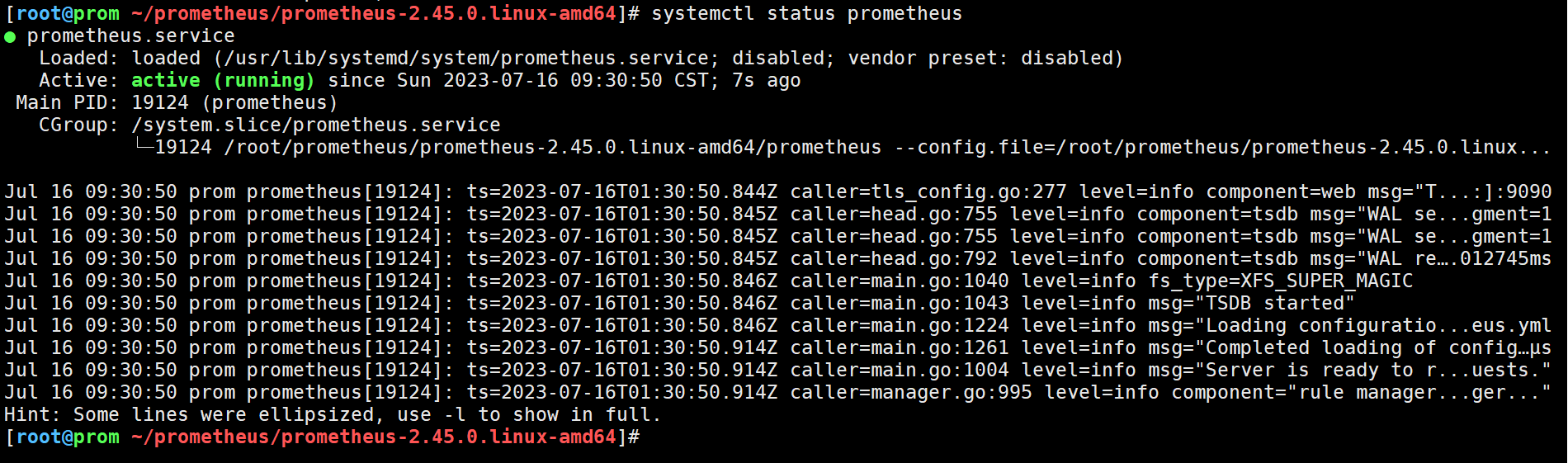
systemctl restart prometheus
systemctl status prometheus
5、部署node-exporter
下载地址:Download | Prometheus
# 解压
tar xf node_exporter-1.6.0.linux-amd64.tar.gz
# 运行node exporter
cd node_exporter-1.6.0.linux-amd64/
./node_exporter
# 访问node exporter的WebUI(如下图所示)
http://10.0.0.211:9100/metrics
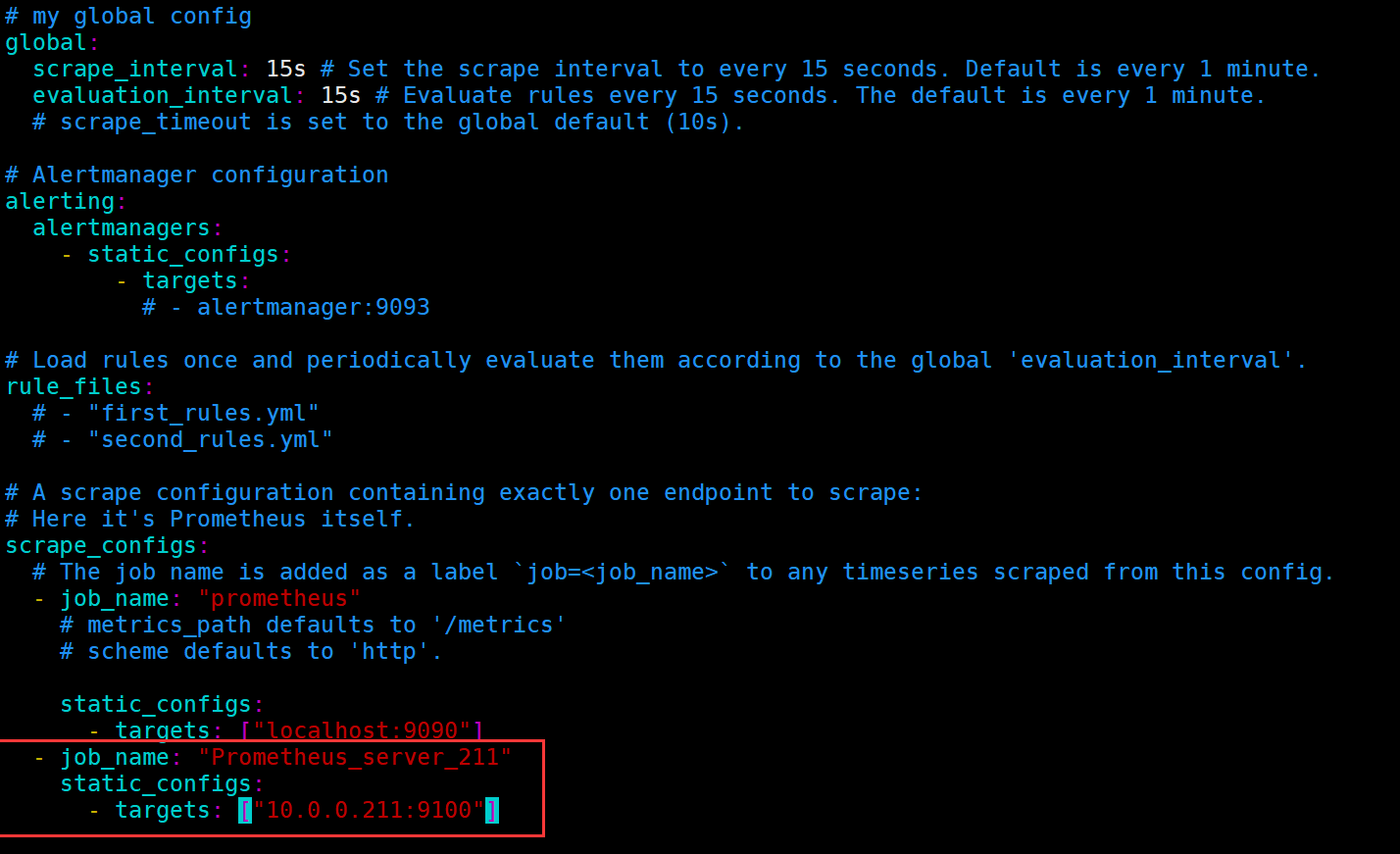
# 配置prometheus server监控node exporter
vim prometheus.yml
...
scrape_configs:
...
- job_name: "运维区虚拟机"
static_configs:
- targets: ["10.0.0.211:9100"]
# 重启prometheus server使得配置文件生效
systemctl restart prometheus
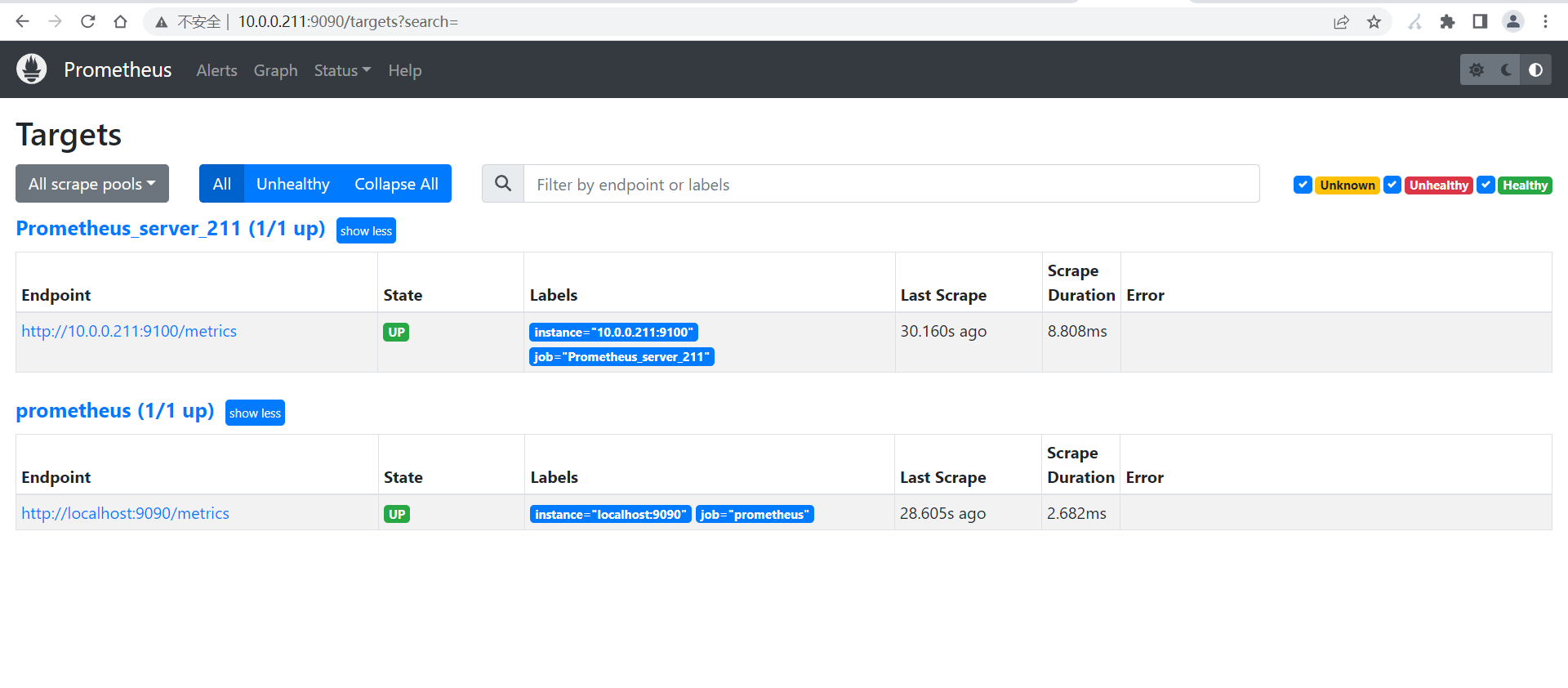
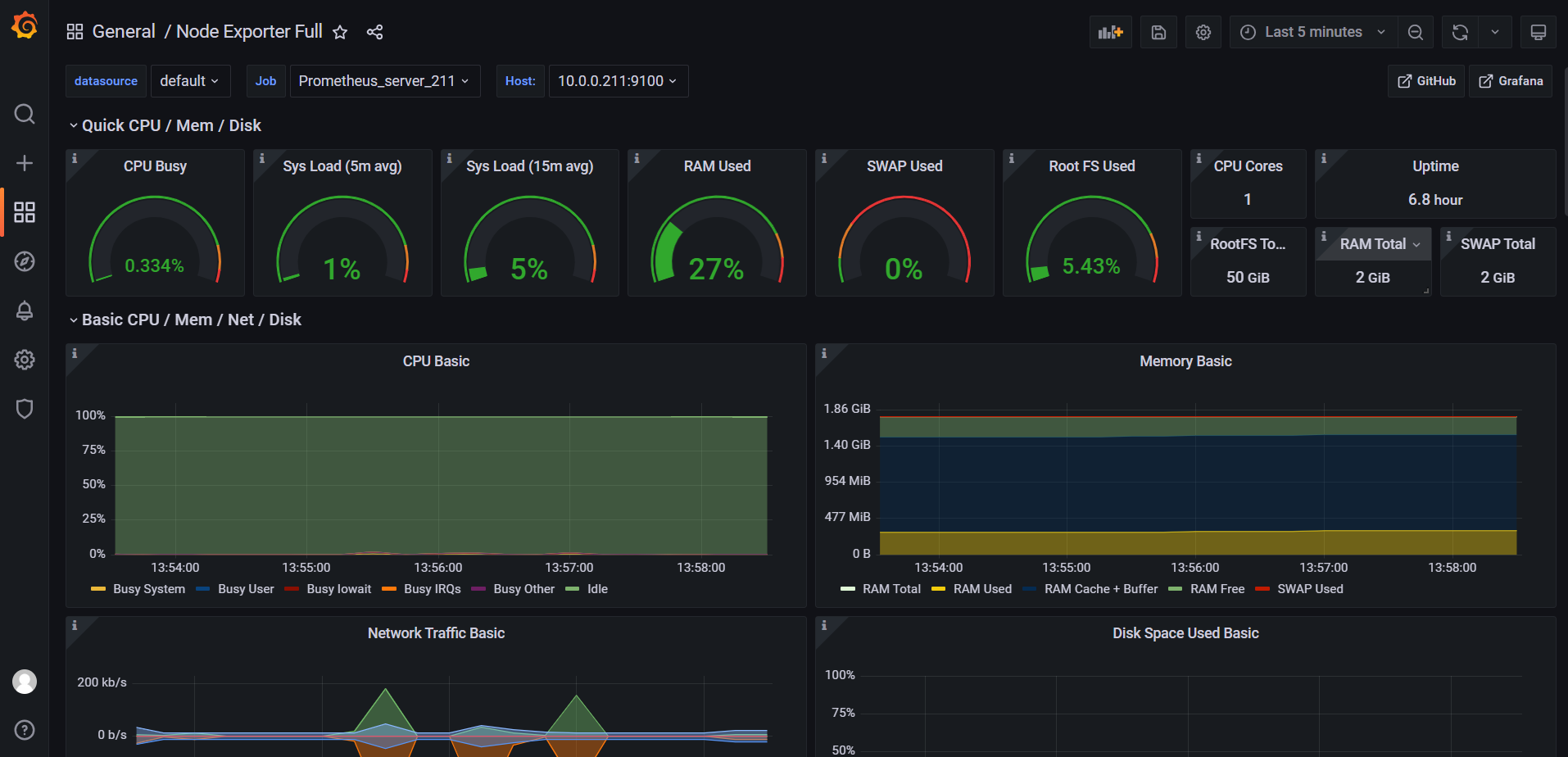
# 观察prometheus server的WebUI是否有数据
如下图所示。
6、node-exporter的systemd文件
cat > /usr/lib/systemd/system/node-exporter.service <<'EOF'
[Unit]
After=network.target
[Service]
ExecStart=/root/prometheus/node_exporter-1.6.0.linux-amd64/node_exporter \
--web.listen-address=:9100 \
--log.level=info
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl restart node-exporter
systemctl status node-exporter
三、PromQL语句
1、prometheus metrics type
prometheus监控中采集过来的数据统一称为Metrics数据,其并不是代表具体的数据格式,而是一种统计度量计算单位。
当我们需要为某个系统或者某个服务做监控是,就需要使用到metrics。
prometheus支持的metrics包括但不限于以下几种数据类型:
guage:
最简单的度量指标,只是一个简单的返回值,或者叫瞬时状态。
比如说统计硬盘,内存等使用情况。
couter:
就是一个计数器,从数据量0开始累积计算,在理想情况下,只能是永远的增长,不会降低(有特殊情况,比如粉丝量)。
比如统计1小时,1天,1周,1一个月的用户访问量,这就是一个累加的操作。
histograms:
是统计数据的分布情况,比如最小值,最大值,中间值,中位数等,代表的是一种近似百分比估算数值。
通过histograms可以分别统计处在一个时间段(1s,2s,5s,10s)内nginx访问用户的响应时间。
summary:
summary是histograms的扩展类型,主要弥补histograms不足。
2、promql语句
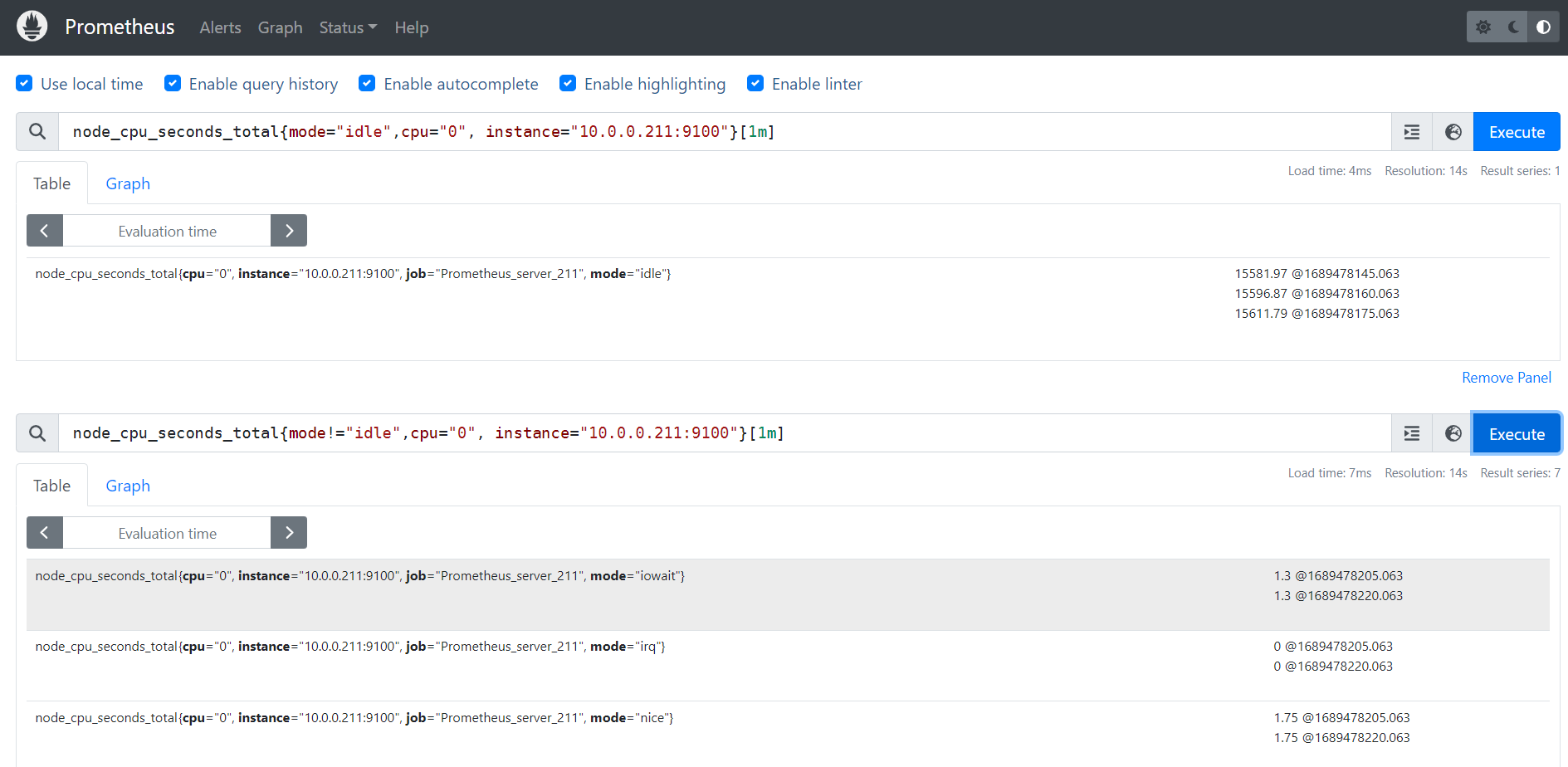
node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.211:9100"}
使用标签过滤器查看"10.0.0.211:9100"节点的第0颗CPU,空闲状态使用的总时间。
node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.211:9100"}[1m]
统计1分钟内,使用标签过滤器查看"10.0.0.211:9100"节点的第0颗CPU,空闲状态使用的总时间。
node_cpu_seconds_total{mode!="idle",cpu="0", instance="10.0.0.211:9100"}[1m]
统计1分钟内,使用标签过滤器查看"10.0.0.211:9100"节点的第0颗CPU,非空闲状态使用的总时间。
node_cpu_seconds_total{mode=~"i.*",cpu="0", instance="10.0.0.211:9100"}[1m]
统计1分钟内,使用标签过滤器查看"10.0.0.211:9100"节点的第0颗CPU,mode名称以字母"i"开头的所有CPU核心。
node_cpu_seconds_total{mode!~"i.*",cpu="0", instance="10.0.0.211:9100"}[1m]
统计1分钟内,使用标签过滤器查看"10.0.0.211:9100"节点的第0颗CPU,mode名称不是以字母"i"开头的所有CPU核心。
3、prometheus常用的函数
increase 截取一段时间总量
increase函数:
用来针对counter数据类型,截取其中一段时间总的增量。
举例:
increase(node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.211:9100"}[1m])
统计1分钟内,使用标签过滤器查看"10.0.0.211:9100"节点的第0颗CPU,空闲状态使用的总时间增量。
sum 求和
sum函数:
加和的作用。
举例:
sum(increase(node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.211:9100"}[1m]))
统计1分钟内,使用标签过滤器查看"10.0.0.211:9100"节点的第0颗CPU,空闲状态使用的总时间增量,并将返回结果累加。
by 分组
by函数:
将数据进行分组,类似于MySQL的"GROUP BY"。
举例:
sum(increase(node_cpu_seconds_total{mode="idle",cpu="0"}[1m])) by (instance)
统计1分钟内,使用标签过滤器查看第0颗CPU空闲状态,并将结果进行累加,基于instance进行分组。
rate 过滤每秒
rate函数:
它的功能是按照设置的时间段,取counter在这个时间段中平均每秒的增量。
举例:
rate(node_cpu_seconds_total{mode="idle",cpu="0", instance="10.0.0.211:9100"}[1m])
统计1分钟内,使用标签过滤器查看"10.0.0.211:9100"节点的第0颗CPU,空闲状态使用的每秒的增量。
increase和rate如何选择:
(1)对于采集数据频率较低的场景建议使用increase函数,因为使用rate函数可能会出现断点,比如针对硬盘容量监控。
(2)对于采集数据频率较高的场景建议使用rate函数,比如针对CPU,内存,网络流量等都是可以基于rate函数来采集等。
topk 取最高值
topk函数:
取前几位的最高值,实际使用的时候一般会用该函数进行瞬时报警,而不是为了观察曲线图。
举例:
topk(3, rate(node_cpu_seconds_total{mode="idle",cpu="0"}[1m]))
统计1分钟内,使用标签过滤器查看第0颗CPU,空闲状态使用的每秒的增量,只查看前3个节点。
count
count函数:
把数值符合条件的,输出数目进行累加加和,一般用它进行一些某户的监控判断。
比如说企业中有100台服务器,如果只有10台服务器CPU使用率高于80%时候是不需要报警的,但是数量操作70台时就需要报警了。
举例:
count(http_tcp_wait_conn > 500):
假设http_tcp_wait_conn是咱们自定义的KEY。
整改成果一大部分去啊吧TCP等待数量大于500的机器数量。
其他函数
推荐阅读:
https://prometheus.io/docs/prometheus/latest/querying/functions/
四、监控CPU的使用情况案例
1、统计各个节点CPU的使用率
(1)我们需要先找到CPU相关的KEY
node_cpu_seconds_total
(2)过滤出CPU的空闲时间({mode='idle'})和全部CPU的时间('{}')
node_cpu_seconds_total{mode='idle'}
过滤CPU的空闲时间。
node_cpu_seconds_total{}
此处的'{}'可以不写,因为里面没有任何参数,代表获取CPU的所有状态时间。
(3)统计1分钟内CPU的增量时间
increase(node_cpu_seconds_total{mode='idle'}[1m])
统计1分钟内CPU空闲状态的增量。
increase(node_cpu_seconds_total[1m])
统计1分钟内CPU所有状态的增量。
(4)将结果进行加和统计
sum(increase(node_cpu_seconds_total{mode='idle'}[1m]))
将1分钟内所有CPU空闲时间的增量进行加和计算。
sum(increase(node_cpu_seconds_total[1m]))
将1分钟内所有CPU空闲时间的增量进行加和计算。
(5)按照不同节点进行分组
sum(increase(node_cpu_seconds_total{mode='idle'}[1m])) by (instance)
将1分钟内所有CPU空闲时间的增量进行加和计算,并按照机器实例进行分组。
sum(increase(node_cpu_seconds_total[1m])) by (instance)
将1分钟内所有CPU空闲时间的增量进行加和计算,并按照机器实例进行分组。
(6)计算1分钟内CPU空闲时间的百分比
sum(increase(node_cpu_seconds_total{mode='idle'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)
(7)统计1分钟内CPU的使用率,计算公式: (1 - CPU空闲时间的百分比) * 100%。
(1 - sum(increase(node_cpu_seconds_total{mode='idle'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100
(8)统计1小时内CPU的使用率,计算公式: (1 - CPU空闲时间的百分比) * 100%。
(1 - sum(increase(node_cpu_seconds_total{mode='idle'}[1h])) by (instance) / sum(increase(node_cpu_seconds_total[1h])) by (instance)) * 100
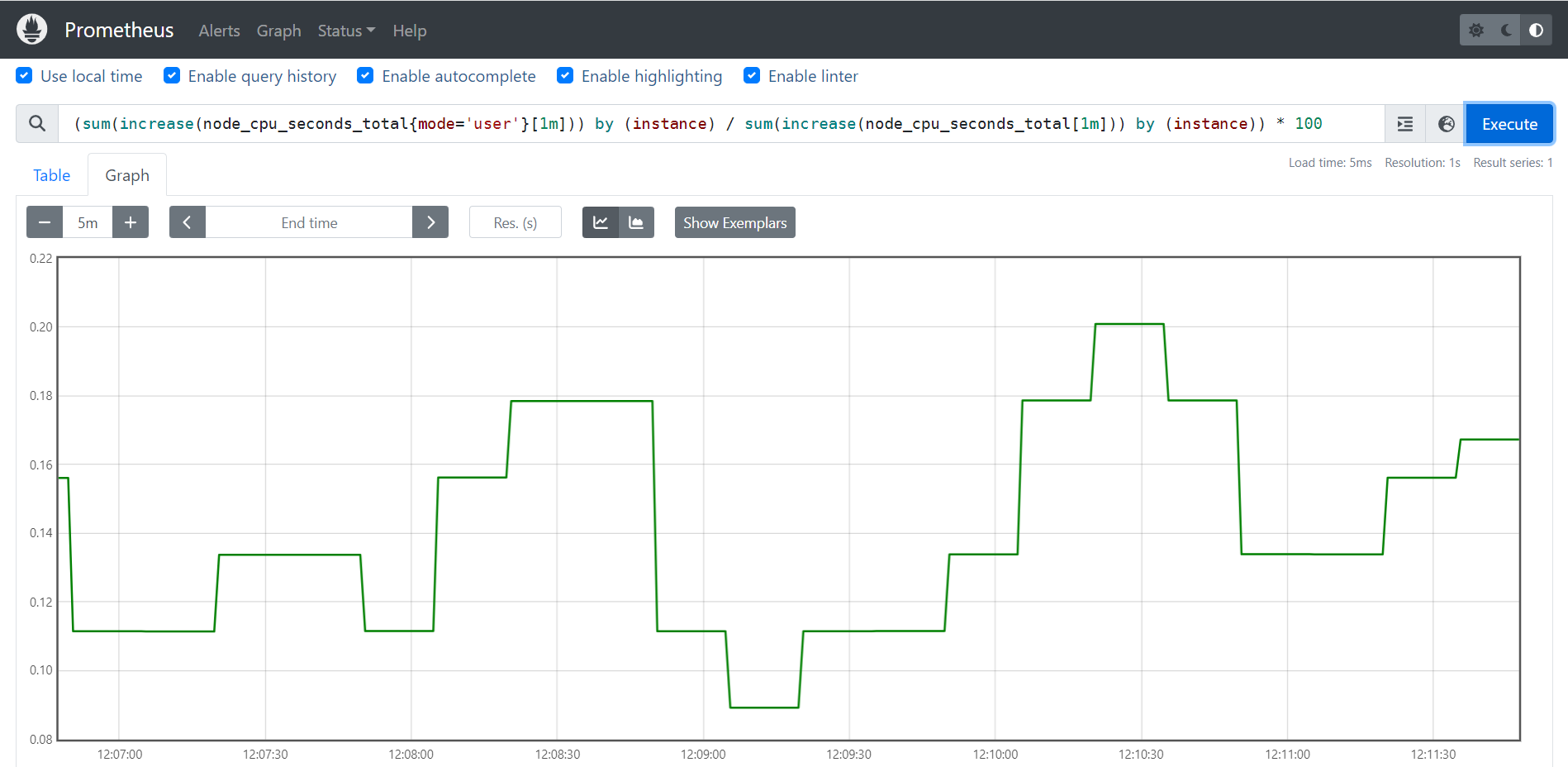
2、计算CPU用户态的1分钟内百分比
(sum(increase(node_cpu_seconds_total{mode='user'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100
温馨提示:
可以使用stress命令来进行压测CPU,即执行"stress -c 2 -v"命令即可。
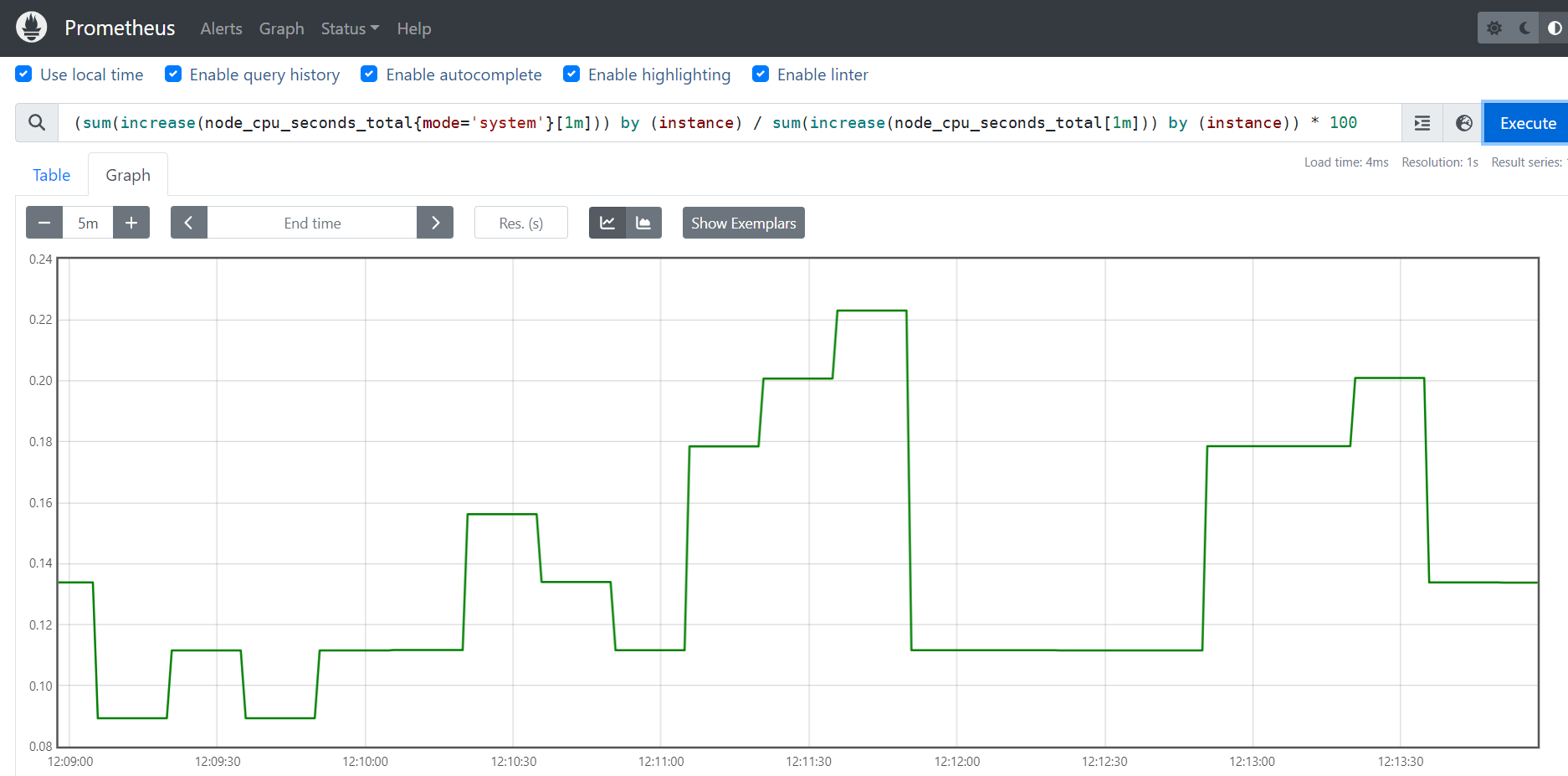
3、计算CPU内核态的1分钟内百分比
(sum(increase(node_cpu_seconds_total{mode='system'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100
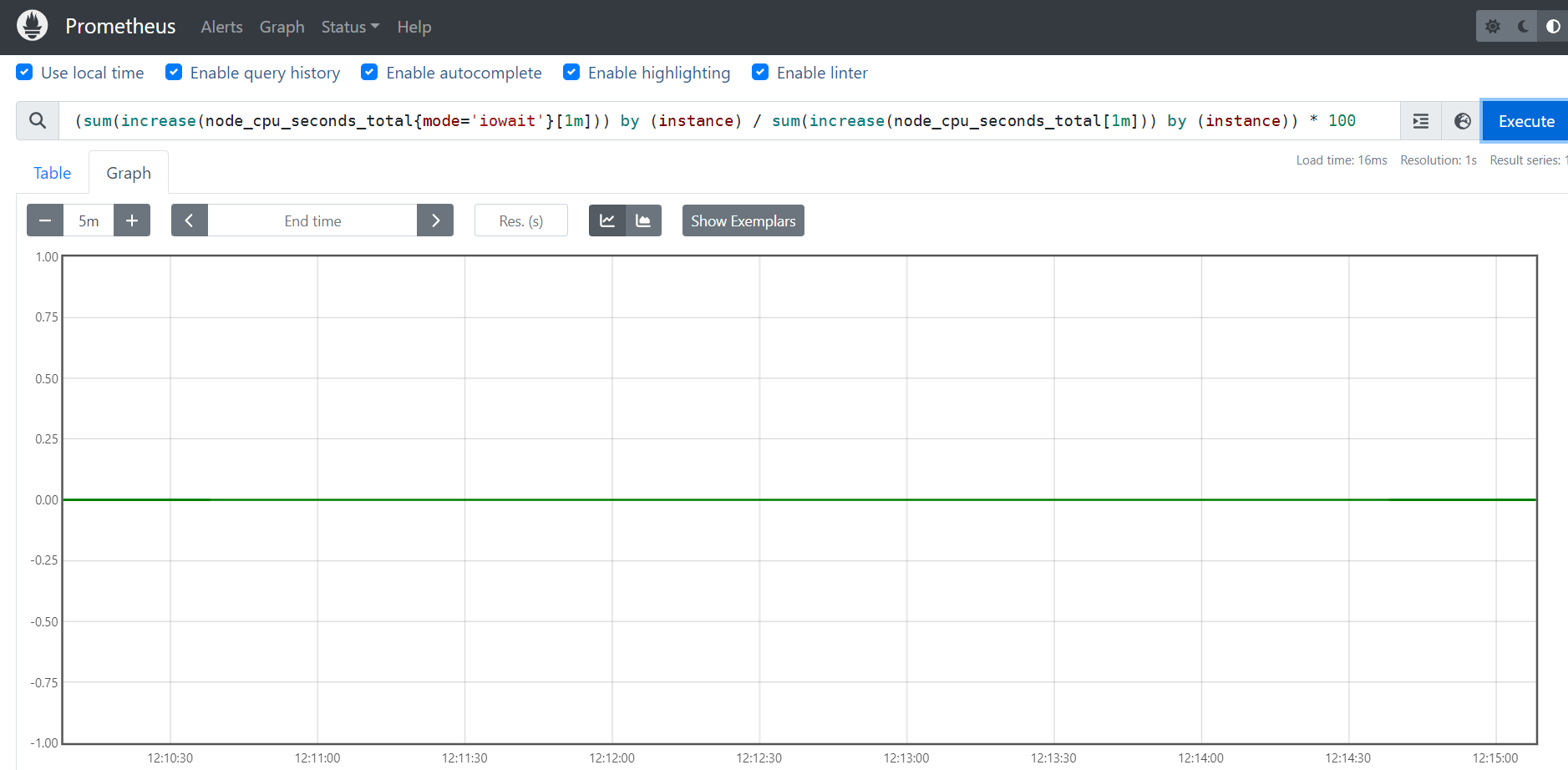
4、计算CPU IO等待时间的1分钟内百分比
(sum(increase(node_cpu_seconds_total{mode='iowait'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100
五、Grafana展示数据
(1)基于rpm方式安装
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-8.5.4-1.x86_64.rpm
yum install -y grafana-enterprise-8.5.4-1.x86_64.rpm
systemctl enable --now grafana-server.service
浏览器访问http://10.0.0.211:3000
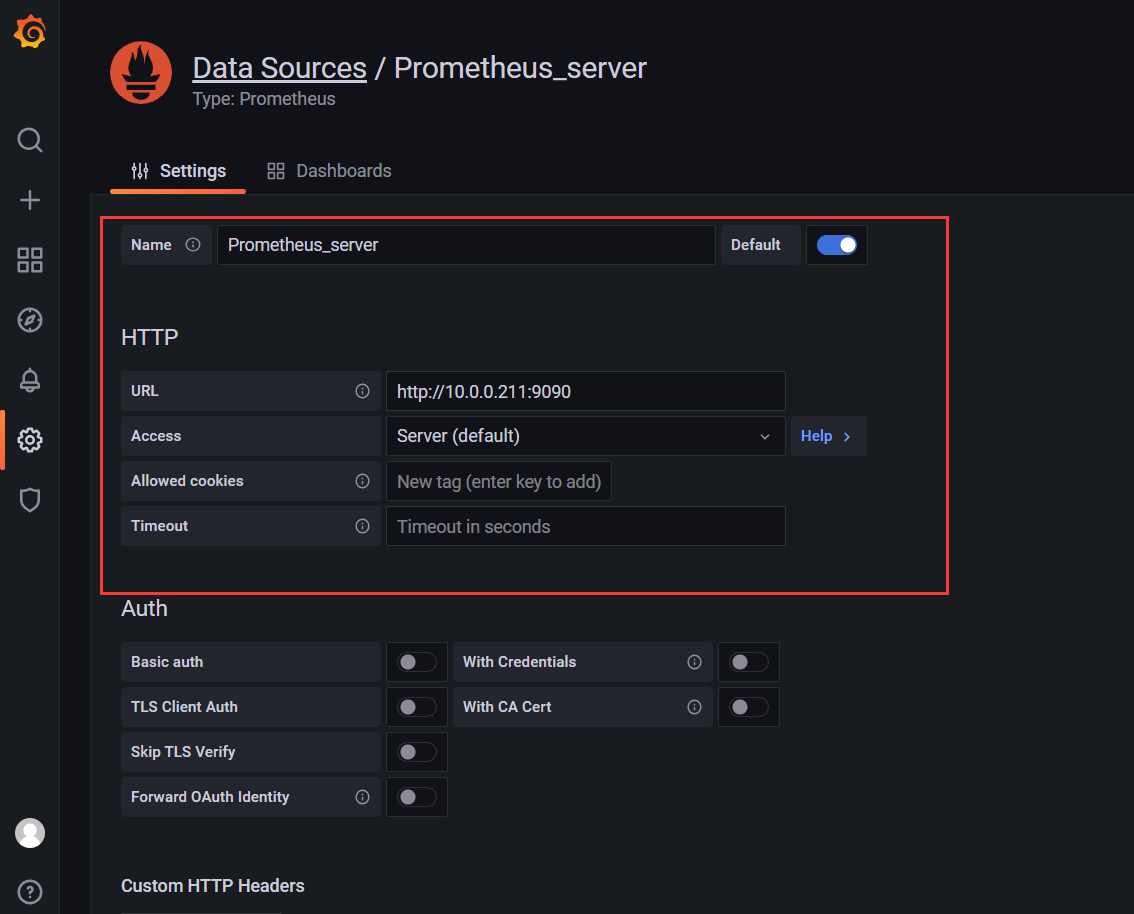
添加数据源为Prometheus
之后再import选择合适的仪表盘,导入数据
(2)基于docker方式部署
docker run -d --name=grafana -p 3000:3000 grafana/grafana-enterprise
参考链接:
https://grafana.com/grafana/download
六、pushgateway概述
什么是pushgateway:
它是一种采用被动推送(push)的方式获取监控数据的prometheus插件。
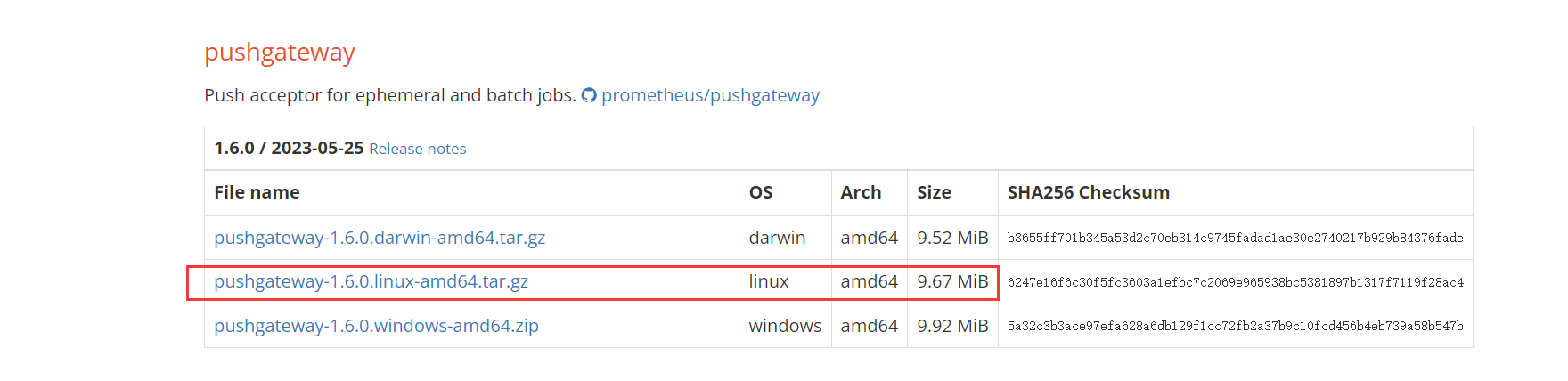
下载地址:
https://prometheus.io/download/
1、部署pushgateway组件
(1)解压软件包
tar xf pushgateway-1.4.3.linux-amd64.tar.gz -C /oldboyedu/softwares/
(2)编写启动脚本
cat > /usr/lib/systemd/system/pushgateway.service <<'EOF'
[Unit]
Description=Oldboyedu Linux80 pushgateway daemon
After=network.target`
[Service]
ExecStart=/oldboyedu/softwares/pushgateway-1.4.3.linux-amd64/pushgateway \
--web.listen-address=:9091 \
--log.level=info
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl restart pushgateway
systemctl status pushgateway
(3)访问WebUI
如上图所示。
七、altermanager告警
什么是alertmanager:
它是一种实现报警功能的prometheus插件。
下载地址:
https://prometheus.io/download/#alertmanager
1、部署alertmanager
(1)解压安装包
tar xf alertmanager-0.25.0.linux-amd64.tar.gz
cd alertmanager-0.25.0.linux-amd64/
(2)修改alertmanager的配置文件
vim alertmanager.yml
global:
resolve_timeout: 5m
smtp_from: '3587152523@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '3587152523@qq.com'
smtp_auth_password: 'bqzujehjueaqdbej'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '3587152523@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
(3)启动alertmanager
./alertmanager
相关参数说明:
global:
resolve_timeout:
解析超时时间。
smtp_from:
发件人邮箱地址。
smtp_smarthost:
邮箱的服务器的地址及端口,例如: 'smtp.qq.com:465'。
smtp_auth_username:
发送人的邮箱用户名。
smtp_auth_password:
发送人的邮箱密码。
smtp_require_tls:
是否基于tls加密。
smtp_hello:
邮箱服务器,例如: 'qq.com'。
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval:
重复报警的间隔时间,如果没有解即报警问题,则会间隔指定时间一直触发报警,比如:5m。
receiver:
采用什么方式接收报警,例如'email'。
receivers:
- name:
定义接收者的名称,注意这里的name要和上面的route对应,例如: 'email'
email_configs:
- to:
邮箱发给谁。
send_resolved: true
inhibit_rules:
- source_match:
severity:
匹配报警级别,例如: 'critical'。
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
温馨提示:
163邮箱修改授权码步骤很简单,依次点击"设置" ---> "POP3/SMTP/IMAP" ---> "新增授权密码"
3.配置prometheus server监控alertmanager
(1)配置alertmanager服务器及规则文件名称
vi /etc/prometheus/prometheus.yml
...
alerting:
alertmanagers:
- static_configs:
- targets:
- 10.0.0.211:9093
rule_files:
- "cpu_rules.yml"
...
(2)添加规则
cat > /root/prometheus/prometheus-2.45.0.linux-amd64/cpu_rules.yml <<'EOF'
groups:
- name: cpu_seconds_total
rules:
- alert: cpu_seconds_total-CPU使用率已超80%
expr: (1 - sum(increase(node_cpu_seconds_total{mode='idle'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100 > 80
for: 15s
labels:
city: bejing
annotations:
summary: "使用率已超80%"
EOF
(3)重启prometheus服务器
(4)查看webUI
如上图所示,访问"http://10.0.0.101:9090/rules"即可。
(5)测试验证告警功能是否生效
停止容器测试即可。

























 1778
1778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









