







目录
3、上传prometheus安装包到opt下,进行安装(192.168.159.68)
4、配置node_exporter(192.168.159.11、192.168.159.10)
5、配置prometheus节点的配置文件(192.168.159.68)
一、Prometheus的部署
1、实验环境
| 主机 | IP | 安装包 |
| prometheus | 192.168.159.68 | prometheus |
| server1 | 192.168.159.11 | node_exporter |
| server2 | 192.168.159.10 | node_exporter |
2、环境初始话
systemctl stop firewalld
systemctl disable firewalld
setenforce 0ntpdate ntp1.aliyun.com ####时间同步,必须要做的
3、上传prometheus安装包到opt下,进行安装(192.168.159.68)
[root@zwb_docker opt]# rz -E
rz waiting to receive.
[root@zwb_docker opt]# tar zxvf prometheus-2.27.1.linux-amd64.tar.gz -C /usr/local/
安装完成,启动prometheus
[root@zwb_docker prometheus-2.27.1.linux-amd64]# ./prometheus
prometheus启动后会占用前端界面,复制会话,重新打开另一个界面进行操作。
查看端口是否开启
[root@zwb_prometheus ~]# ss -antp | grep 9090
LISTEN 0 128 :::9090 :::* users:(("prometheus",pid=11006,fd=8))
ESTAB 0 0 ::ffff:192.168.159.68:9090 ::ffff:192.168.159.1:62136 users:(("prometheus",pid=11006,fd=21))
ESTAB 0 0 ::1:9090 ::1:51520 users:(("prometheus",pid=11006,fd=13))
ESTAB 0 0 ::ffff:192.168.159.68:9090 ::ffff:192.168.159.1:62135 users:(("prometheus",pid=11006,fd=18))
查看WEB页面

4、配置node_exporter(192.168.159.11、192.168.159.10)
两个节点的配置方法一样
[root@zwb opt]# rz -E ### 上传
rz waiting to receive.
[root@zwb opt]# tar zxvf node_exporter-1.1.2.linux-amd64.tar.gz ### 解压
-C /usr/local/
[root@zwb opt]# cd /usr/local/node_exporter-1.1.2.linux-amd64/[root@zwb node_exporter-1.1.2.linux-amd64]# mv node_exporter /ur/bin/
#############移动执行脚本到全局环境变量下
开启node_exporter
[root@zwb node_exporter-1.1.2.linux-amd64]# node_exporter
5、配置prometheus节点的配置文件(192.168.159.68)

6、重启prometheus,查看页面
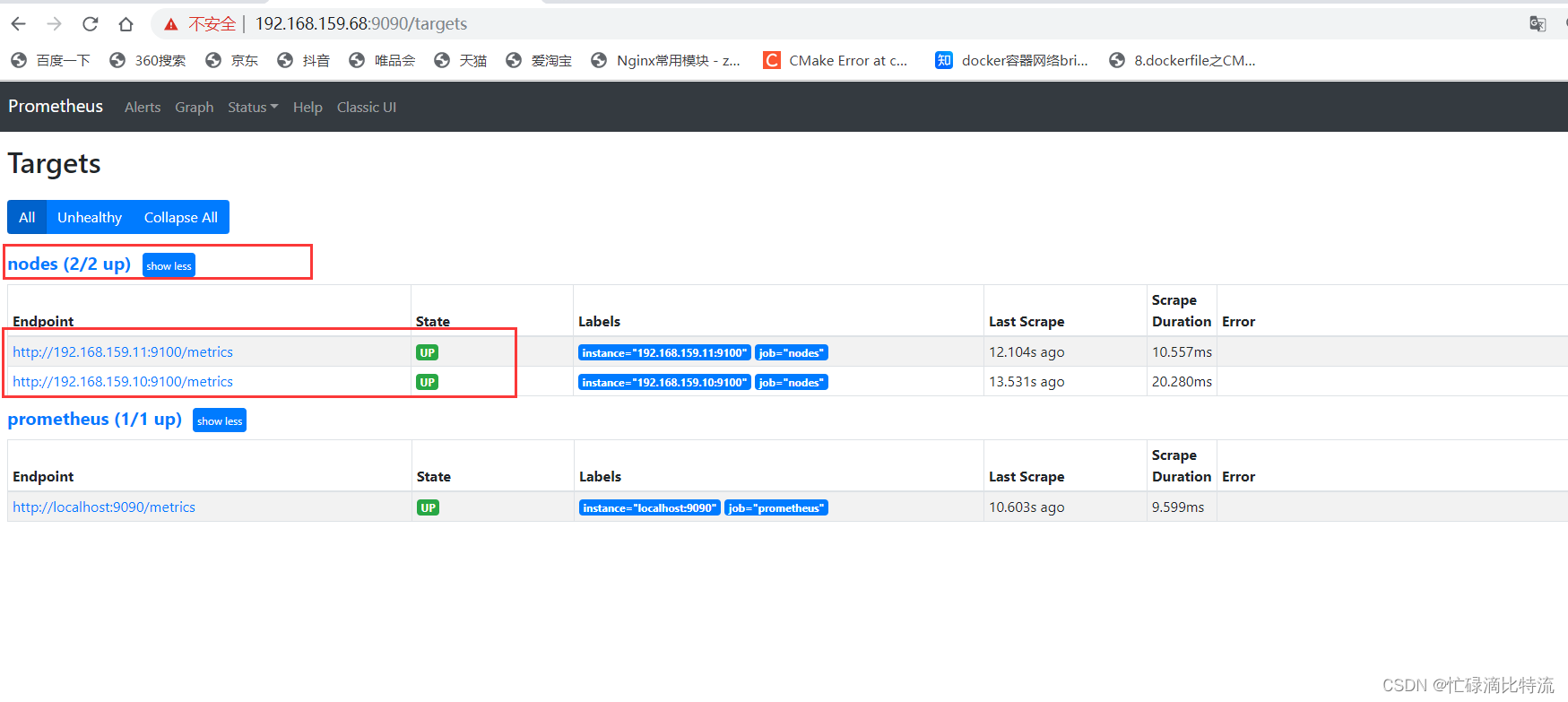
如果整体关机后,开机需要重新启动prometheus和exporter
7、采集数据流向
prometheus节点通过收集。被监测点的node_exporter周期性抓取数据并转化为prometheus兼容格式。node_exporter被监测点的信息需要在prometheus节点配置。
二、配置文件解析
prometeus配置文件prometeus.yml的组成
## 用于定义全局配置,主要定义的是周期。一个是scrape周期,一个自动识别、更新配置文件的周期
# my global config
global:
scrape_interval: 15s# Set the scrape interval to every 15 seconds. Default is every 1 minute.
# 用来指定Prometheus从监控端抓取数据的时间间隔
evaluation_interval: 15s# Evaluate rules every 15 seconds. The default is every 1 minute.
# 用于指定检测告警规则的时间间隔,每15s重新检测告警规则,并对变更进行更新
# scrape_timeout is set to the global default (10s).# 定义拉取实例指标的超时时间
## 用于设置Prometheus与Alertmanager的通信,在Prometheus的整体架构中,Prometheus会根据配置的告警规则触发警报并发送到独立的Alertmanager组件,Alertmanager将对告警进行管理并发送给相关的用户
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs: ### 配置alertmanager的地址信息
- targets:
# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: ### 用于指定告警规则的文件路径,告警逻辑(写了布尔值表达式文件的文件名)
# - "first_rules.yml"
# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs: ### 指定Prometheus抓取的目标信息(采集数据的配置)
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.static_configs:
- targets: ['localhost:9090']- job_name: 'nodes' ### 自定义指定Prometheus抓取的目标信息
static_configs:
- targets:
- 192.168.159.11:9100
- 192.168.159.10:9100
三、表达式浏览器(prometheusUI控制台)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7368
7368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









