









论文地址![]() https://paperswithcode.com/paper/multi-cue-correlation-filters-for-robust
https://paperswithcode.com/paper/multi-cue-correlation-filters-for-robust
代码地址![]() https://github.com/594422814/MCCT
https://github.com/594422814/MCCT
许多基于相关滤波的跟踪算法通过融合多种类型的特征取得了令人印象深刻的性能,然而,它们中的大多数未能充分探索所采用的多种特征之间的上下文以及它们的之间的联系,所以本文提出了一种多线索联合策略,它是通过组合各种不同类型的特征,然后通过传统DCF的方式构造多expert,每个expert独立的跟踪目标,然后根据一种评价策略,选择出跟踪性能最优的expert。(我认为每个expert相当于一个滤波器)
主要贡献如下:
1,提出了一种保持多线索跟踪的算法。通过仔细检查多个专家的鲁棒性得分,在每一帧中选择可靠的专家进行跟踪来改进跟踪结果。
2,通过考虑多个专家的分歧,提出了一种自适应更新策略,该策略能够有效区分不可靠样本(如遮挡或严重变形)并减轻训练样本的污染。
3,实现了两个版本的方法来验证框架的通用性MCCT(CNN,HOG,CN),MCCT-H(HOG1,HOG2,CN)。
作者首先分析了融合多个滤波器所具有的缺点:
1,整体速度受到集合中最低跟踪器的限制
2,跟踪器仅被视为独立的黑盒,其每帧的融合结果并不反馈给跟踪器
3,随着滤波器数量的增加,计算量增大
针对以上问题作者的解决办法如下:
1,通过ROI和训练样本共享策略,构造基于DCF的所有专家。
2,将改进后的跟踪结果反馈给专家,以进一步提高跟踪效果。
3,通过一种简单而有效的鲁棒性评估策略,在T帧和N个专家中复杂度仅为O(T N)。
具体实现如下:
1,首先介绍了传统DCF的跟踪流程,这里不再赘述。
2,特征池核专家池
MCCT:
采用HOG特征、VGG-19中的conv4-4、conv5-4卷积层作为特征池的{Low, Middle, High}。
并通过随机组合采用DCF方法构成7个专家池。
MCCT-H:
采用31维的HOG特征和一维灰度特征,构成32维总特征,再将其分解成两个16维的HOG1和HOG2特征,并与cn特征三者一起构成特征池。专家池与MCCT一样。如下图所示

3,多线索跟踪
其具体流程如下:

首先,根据DCF框架提取并组合ROI的不同特征来训练多个专家 ,然后,每个专家给出一个单独的预测提示,并选择最可靠的专家进行当前跟踪,最后,自适应更新有助于防止专家出错。

多个专家并行跟踪目标,节点表示专家生成的线索(边界框)。在每一帧中,不同节点之间的得分表示了专家之间的一致程度,这被表示为成对评价。由于每个专家都有自己的轨迹连续性和平滑度。因此,给定一个假设节点,其鲁棒性程度可以通过成对评估和自我评估来评估。在评估了每个节点的整体可靠性之后,选择具有最高鲁棒性分数的专家,并将其跟踪结果用于当前帧。为了清楚起见,只显示了四个专家。
Expert Pair-Evaluation:
首先计算重叠率:
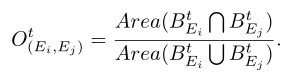
这里的![]() 表示的是第t帧的第i的专家所对应的边界框,为了减小低重叠率和高重叠率之间的差距,采用非线性高斯函数:
表示的是第t帧的第i的专家所对应的边界框,为了减小低重叠率和高重叠率之间的差距,采用非线性高斯函数:

再求专家i与其他专家之间的均值:(K=7,是专家的总数)

作者将短期内(例如5帧之内)重叠率的波动程度表示表示专家的稳定性:

![]() 表示的是短期内(例如5帧)的平均重叠率
表示的是短期内(例如5帧)的平均重叠率 ![]()
我认为这个式子相当于求短期帧内的标准差。
作者也考虑了时间稳定性,引入了一个权重矩阵![]()
最后得到:
![]()
![]()
这里的N表示的是权重W的总和![]()
最后专家i在帧t的Expert Pair-Evaluation分数定义如下:
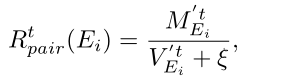
这里的是一个小常数,可以避免分母为零。
Expert Self-Evaluation:
![]()
![]()
表示前后两帧的欧几里得距离,![]() 表示的边界框中心位置。
表示的边界框中心位置。

这个公式表示在帧t中,专家i的轨迹波动程度,![]() 表示边界框长和高的平均长度,在这里作者也考虑了时间稳定性:
表示边界框长和高的平均长度,在这里作者也考虑了时间稳定性:
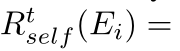
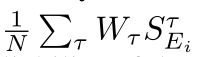
最后作者将![]() 与
与![]() 两者线性组合,表示在t帧,专家i的最终得分:
两者线性组合,表示在t帧,专家i的最终得分:

共享策略:
在跟踪过程中,所有专家使用相同的样本进行更新,并共享相同的搜索区域(ROI)。这种共享策略有两个优点:(1)通过共享目标位置预测和模型更新的优化结果,有效地缓解了漂移和跟踪失败;(2)极大地保证了框架的效率。DCF的主要计算负担在于特征提取过程,尤其是深度特征。虽然在本文方法中保持了多个专家(K = 7),但共享策略使得特征提取过程在每帧中只进行两次(而不是7 × 2 = 14次),一次用于搜索块(ROI),另一次用于训练块(用于模型更新),这与标准DCF相同,并且独立于专家数量。
自适应专家更新:
利用峰值旁瓣比(PSR)来检验跟踪的可靠性,
![]()
Rmax是最大置信度,m和σ是响应的均值和标准差,本文利用不同特征的平均PSR表示第t个跟踪结果
![]()
括号里的三项分别表示高、中和低级特征别响应图的PSR值。
实验中,观察到当发生遮挡或严重变形时,专家的平均鲁棒性得分![]() 显著下降,这可以看作是多个专家在面对一个不可靠样本时的发散。通过综合考虑平均PSR评分和平均专家鲁棒性评分,提出了一种组合可靠性评分
显著下降,这可以看作是多个专家在面对一个不可靠样本时的发散。通过综合考虑平均PSR评分和平均专家鲁棒性评分,提出了一种组合可靠性评分![]() ,该评分能更有效地发现不可靠样本,更好地评估当前跟踪的质量。
,该评分能更有效地发现不可靠样本,更好地评估当前跟踪的质量。
当前信度得分St显著低于过去平均信度得分时(![]() ):
):

这里的表示的标准DCF中的模型学习率

c是标准DCF的学习速率,α是可靠性阈值,β是幂函数的幂指数。通过这样就会严厉惩罚低可靠性得分的样本,以保护专家免受破坏。
实验结果不再赘述,可以自行看论文。
















 3271
3271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











