






直接附上代码,兄弟们修改这两行路径就可以
test = pd.read_csv('D:\wangyong\Wang\kaggle\year/test.csv')
train = pd.read_csv('D:\wangyong\Wang\kaggle\year/train.csv')这是完整源码
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
test = pd.read_csv('D:\wangyong\Wang\kaggle\year/test.csv')
train = pd.read_csv('D:\wangyong\Wang\kaggle\year/train.csv')
print(train.head())
print(train.describe())
print(test.describe())
key_train = train.keys()
key_test = test.keys()
print(key_train)
print(key_test)
for i in range(len(key_test)-1):
train_data = []
test_data = []
for x in train[key_train[i+1]]:
train_data.append(x)
for x in test[key_test[i+1]]:
test_data.append(x)
plt.figure(figsize=(8,4),dpi = 150)
sns.kdeplot(train_data,color = "Red",shade = True)
ax = sns.kdeplot(test_data,color = "Blue",shade = True)
ax.set_xlabel(key_train[i])
ax.set_ylabel("values")
ax.legend(["train","test"])
plt.show()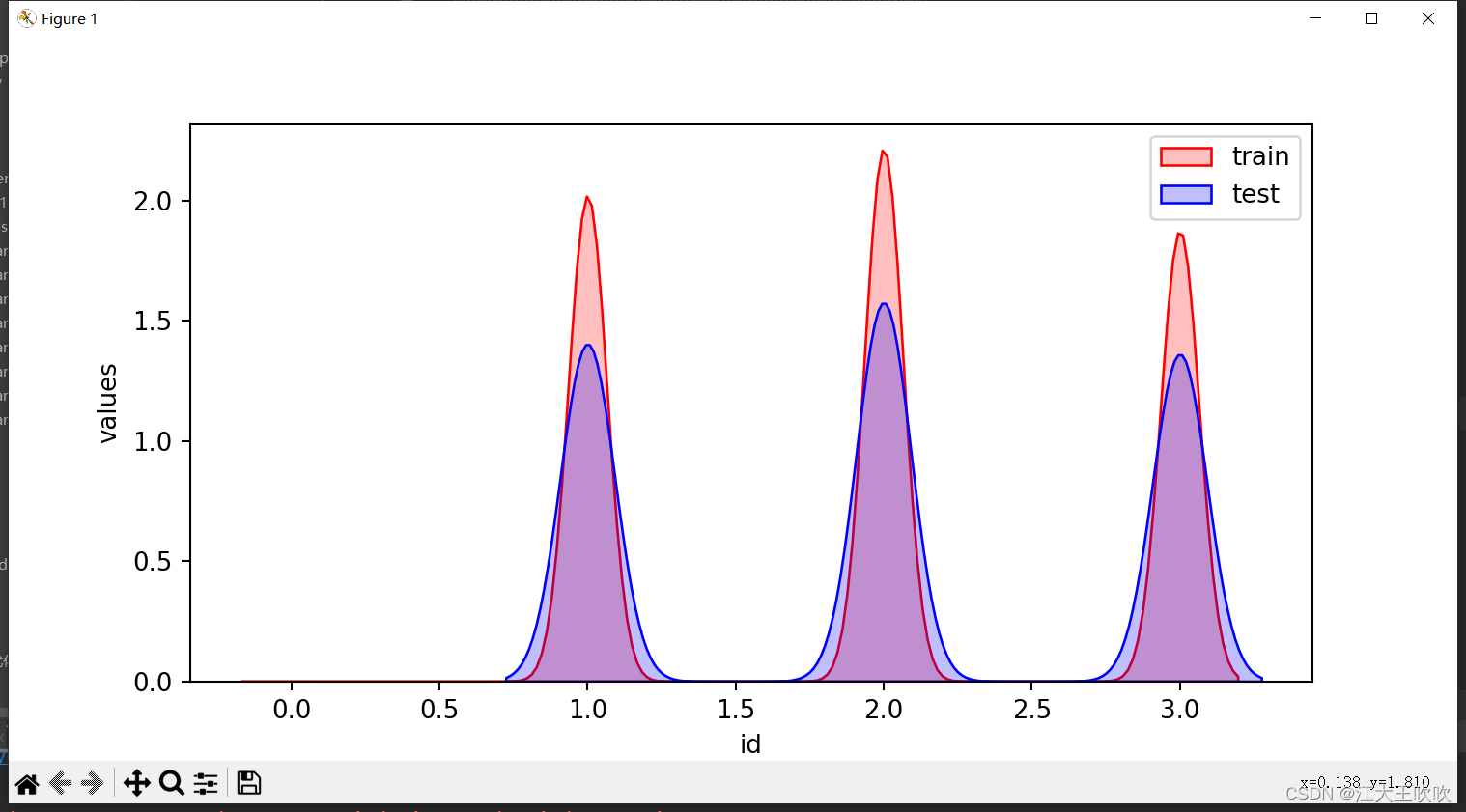
这个就是大致的一个效果,可以发现训练集与测试集的分布还是有一定差距的
这就通过可视化的方式观察训练集与测试集的分布















 3868
3868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









