







前言
今天做一套蓝桥杯python元年的国赛题目,我数了一下5道选择,可以说是福利之年了,以后都不会出现这种情况了,当时python组别刚出现,估计很多大学和专业连python这门课都没开设,或部分开设,咱们废话少嗦直接开敲,这次不看源码哈。
发现有的同学还不清楚比赛环境,贴一个我们学校机子的供参考哈。

A:美丽的2

数数题,上来3分钟签个道
ans=0
for i in range(1,2021):
if str(i).count('2')>0:
ans+=1
print(ans)
要比赛了就给大家搜一手官方解释趴
B:合数个数

这道题就写个简单check函数判断是不是质数,循环输一下就行。
ans=0
def check(i):
for j in range(2,i):
if i%j==0:
return True
else:
return False
for i in range(4,2021):
if check(i):
ans+=1
print(ans)
C:阶乘约数

这题我写了一个跑的时间有点长,上网学习了一个大家看下。
总之没第一反应想的那么简单,它要求的是正约数的个数,那它的因子进行排列组合的乘积当然也是它的正约数,质数也可以是约数,而且质数也可以是它的因子组成的,如果用每个因子一个个去除累加次数时间太久,还是通过分解的方式好用,而且约数进行相互间的组合数,就是它们的乘积和
import os
import sys
# 计算100的阶乘有多少因数
n = 100 # 阶乘的参数
p = [2] # 质数列表,初始化为[2]
# 找出100以内的所有质数,存入p
for i in range(3, n + 1):
j = 2
while j < i:
if i % j == 0: # 如果i能被j整除,说明i不是质数
break
j += 1
else: # 如果i不能被任何小于i的数整除,说明i是质数
p.append(i)
# print(p) # 输出p,查看质数列表
m = {} # 质因数字典,用来记录每个质因数的个数
for i in p:
m[i] = 1 # 初始化为1,代表不选这个质因数的可能
# 遍历从2到100的每个数,对每个数进行质因数分解,并更新m中对应的质因数的个数
for i in range(2, n + 1):
x = i # x为当前要分解的数
for j in p: # 遍历质数列表
if j > x: # 如果j大于x,说明x已经分解完毕,跳出循环
break
while x % j == 0: # 如果x能被j整除,说明j是x的一个质因数
x //= j # 将x除以j,并更新x的值
m[j] += 1 # 将m中j对应的值加一
s = 1 # 约数个数,初始化为1
# 将m中所有的值相乘,得到约数个数
for i in m.values():
s *= i
print(s) # 输出约数个数
# 请在此输入您的代码
D:本质上升序列

这题我搜了半天,一开始我以为是数每个字母出现的次数,后来发现递增序列是每个字母只出现一次,所以我们只要记住每个第一次出现产生的个数,它后面重复出现也没作用。我们从前往后数,初始化为1。
x = "tocyjkdzcieoiodfpbgcncsrjbhmugdnojjddhllnofawllbhfiadgdcdjstemphmnjihecoapdjjrprrqnhgccevdarufmliqijgihhfgdcmxvicfauachlifhafpdccfseflcdgjncadfclvfmadvrnaaahahndsikzssoywakgnfjjaihtniptwoulxbaeqkqhfwl"
dp = [1] * 200 #初始化
for i in range(200):
for j in range(i): #当前字母与它前面的字母进行比较
if x[i] > x[j]: #现在出现的字典序大于之前,可以产生新的子序列
dp[i] += dp[j]
elif x[j] == x[i]: #之前已经出现了,把前者产生的子序列数量减掉
dp[i] -= dp[j]
print(sum(dp)) #sum
总的来说这题还是挺复杂的,没那么好想,因为这个字母之前出现过,新增一个对前面没有任何影响,所以把它减掉一个差值,后面求和就抵消掉了
E:玩具蛇

这题考查深度递归dfs,通过循环将表中每个位置都初始化一次,然后四个方向判断是否超界以及是否有站位。
m=[[0]*4 for i in range(4)]
res=0
def dfs(x,y,cnt):
global res #result
if cnt==16: #16个位置都走了就结束
res+=1
return
for i,j in [(1,0),(0,-1),(0,1),(-1,0)]:#四个方向
a,b=x+i,y+j
if 0<=a<4 and 0<=b<4 and m[a][b]==0:#判断是否可以走
m[a][b]=1 #站位走下一步
dfs(a,b,cnt+1)
m[a][b]=0 #回退到之前
m[x][y]=0 #回退
return res
for i in range(4):
for j in range(4):
m[i][j]=1
dfs(x,y,1)
print(res)
F:天干地支

老取余法了,先判断初试那年的天干地支,60年一个周期,2020%10=0,2020%12=4
N=int(input())
a=['jia','yi','bing','ding','wu','ji','geng','xin','ren','gui']
b=['zi','chou','yin','mao','chen','si','wu','wei','shen','you','xu','hai']
C=N-4
print(a[C%10]+b[C%12])
注意!因为要求两者之间无空格,所以不要用逗号链接,用加号连接字符串。
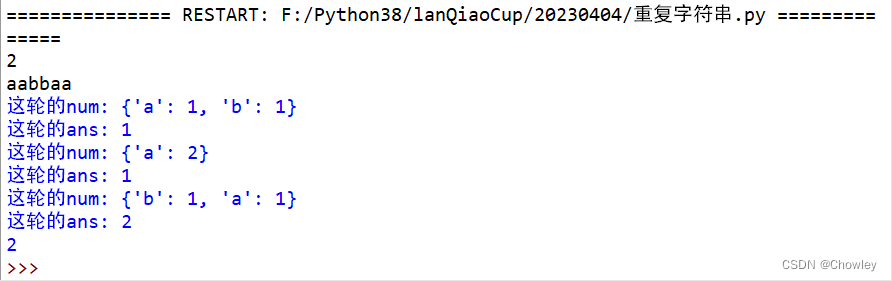
G:重复字符串

遇到这种分类的,用dict还是很香的
k = int(input())
s = list(input())
step = len(s)//k # 判断子字符串长度
ans = 0
for i in range(step):
num = dict()
for j in s[i::step]: # 分别遍历每个子字符串的第i位,统计其出现次数,num存储出现次数
if j in num:
num[j] += 1 # 这个字母之前出现过num+1
else:
num[j] = 1
ans += k-max(num.values()) # k减去字符串该位出现次数最多的num(最多就是不用换的)
num.clear() # 清除这个位置的记录
print(ans)
看代码有点抽象,我debug了一下,大家看看,对应子串如果都相同,就和k一样大,有一个不同就要改变一个,结果累加。
H:答疑

这题我建议大家先拿笔推推,最后结果就是越小的排前面越好
n=int(input())
li=[]
for i in range(n):
x,y,z=map(int,input().split())
A=x+y #解答时间
B=x+y+z #总时间
li.append([A,B])
li=sorted(li,key=lambda x:x[1],reverse=False) #用总时间排序
t=0
for i in range(n):
for j in range(i): #这层循环添加当前学生之前的学生总时间
t+=li[j][1]
t+=li[i][0] #当前学生的答疑时间
print(t) #妙!
I:补给

J:蓝跳跳

结语
最后两个妹写出来,但是把前八个做通做懂也足够了,记得考前三天把模板整理一下,每天敲敲,找点真题带进去试试,最后祝大家心想事成















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











