







摘要:
本文提出了一种利用逆优化(Inverse Optimization-IO)方法来学习决策者在路由问题中的行为。逆优化框架属于监督学习类别,其基于的前提是:目标行为是一个未知成本函数的最优解。这个成本函数将针对历史数据进行学习,在路由问题的背景下,可以解释为决策者的路由偏好。本研究的主要贡献是提出了一种针对路由问题的IO方法论,其中包含假设函数、损失函数和适用于路由问题的随机一阶算法,并针对三种特定的路由问题实例进行建模,从而展示了IO方法论在路由问题中从决策者的决策中学习的灵活性和现实潜力。
关键词: 最后一公里配送问题、逆优化方法、监督学习
1. 引言
最后一公里配送是交付过程中的关键阶段,此时货物被送达最终客户。尽管优化配送路线是一个经过充分研究的主题,许多经典方法主要集中在最小化总旅行时间、距离和路线成本上,但专业司机所选择的路线往往与这些标准所推荐的路线存在显著差异。这种现象反映了人类驾驶员在选择路线时会考虑多种因素,例如良好的停车位、支持设施、加油站,以及避免狭窄或交通缓慢的街道等。这些专业司机所了解的环境知识难以被传统优化策略建模并纳入考虑,从而使他们在实际操作中选择了可能更为便利的路线,因此与优化的路线计划产生矛盾。综上所述,开发能够捕捉并有效利用这些知识的模型,可能会显著提升基于优化的路由工具在现实世界中的表现。
2. 方法描述
2.1 IO问题的形式化
考虑一个外生信号$\hat{s} \in \mathbb{S}
,其中
,其中
,其中\mathbb{S}$是信号空间。给定一个信号,假设专家解决以下参数优化问题以计算其响应动作:
(
1
)
min
x
∈
X
(
s
^
)
F
(
s
^
,
x
)
(1)\min_{x \in \mathbb{X}(\hat{s})} F(\hat{s}, x)
(1)x∈X(s^)minF(s^,x)
其中 X ( s ^ ) \mathbb{X}(\hat{s}) X(s^) 是专家已知的约束集, F : S × X → R F : \mathbb{S} \times \mathbb{X} \to \mathbb{R} F:S×X→R 是专家的未知成本函数,定义 X : = ⋃ s ^ ∈ S X ( s ^ ) X := \bigcup_{\hat{s} \in S} X(\hat{s}) X:=⋃s^∈SX(s^)。在IO形式中,信号空间 S \mathbb{S} S可以包含专家用来解决优化问题(1)的任何信息。例如,在路由问题的背景下,信号可能包含:
- 客户的需求
- 服务客户的时间窗口
- 需要服务的客户集合
- 一天中的时间
- 星期几
- 天气信息等等
由于正式(即数学上)定义一个包含所有可能类型信号的信号空间并不实用,作者将其保留为一般信号空间
S
\mathbb{S}
S。专家的决策$ \hat{x} $是从(1)的优化器集合中选择的,即
x
^
∈
arg
min
x
∈
X
(
s
^
)
F
(
s
^
,
x
)
\hat{x} \in \arg \min_{x \in X(\hat{s})} F(\hat{s}, x)
x^∈argminx∈X(s^)F(s^,x)。假设可以访问N对外生信号及其相应的专家最优决策的集合 {$ {(\hat{s}[i], \hat{x}[i])}KaTeX parse error: Expected 'EOF', got '}' at position 1: }̲_{i=1}^N $,即:
x
^
[
i
]
∈
arg
min
x
∈
X
(
s
^
[
i
]
)
F
(
s
^
[
i
]
,
x
)
∀
i
∈
[
N
]
,
\hat{x}^{[i]} \in \arg \min_{x \in X(\hat{s}^{[i]})} F(\hat{s}^{[i]}, x) \quad \forall i \in [N],
x^[i]∈argx∈X(s^[i])minF(s^[i],x)∀i∈[N],
其中帽子符号“
⋅
^
\hat{·}
⋅^”来表示信号-响应数据。在使用信号-响应数据集时,上标“
[
i
]
^{[i]}
[i]”来指代数据集的第i对。利用这些数据的目标是学习一个成本函数,该函数在针对相同外生信号进行优化时,能够近似地再现专家的动作。
2.2 仿射假设类
在本研究中,作者考虑具有非负成本向量的仿射假设空间中的成本函数:
(
2
)
H
θ
=
{
⟨
θ
,
x
⟩
+
h
(
s
^
,
x
)
:
θ
≥
0
}
(2)H_\theta = \{ \langle \theta, x \rangle + h(\hat{s}, x) : \theta \geq 0 \}
(2)Hθ={⟨θ,x⟩+h(s^,x):θ≥0}
其中,
θ
∈
R
p
\theta \in \mathbb{R}^p
θ∈Rp 是参数化成本函数的成本向量,仿射项
h
:
S
×
X
→
X
h : \mathbb{S} \times \mathbb{X} \to \mathbb{X}
h:S×X→X 是一个函数,可用于建模假设函数
⟨
θ
,
x
⟩
+
h
(
s
^
,
x
)
\langle \theta, x \rangle + h(\hat{s}, x)
⟨θ,x⟩+h(s^,x)中不依赖于
θ
\theta
θ的项。两个向量 $ x, y \in \mathbb{R}^m $ 之间的欧几里得内积用 $ \langle x, y \rangle $ 表示。此外,作者考虑非负成本向量是因为对于路由问题,它们表示图的边的权重。例如,给定一个包含n个节点的完全图,路由问题的常见成本函数是两索引或三索引的形式:
⟨
θ
,
x
⟩
=
∑
i
=
1
n
∑
j
=
1
n
θ
i
j
x
i
j
\langle \theta, x \rangle = \sum_{i=1}^{n} \sum_{j=1}^{n} \theta_{ij} x_{ij}
⟨θ,x⟩=i=1∑nj=1∑nθijxij
和
⟨
θ
,
x
⟩
=
∑
i
=
1
n
∑
j
=
1
n
∑
k
=
1
K
θ
i
j
x
i
j
k
\langle \theta, x \rangle = \sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{k=1}^{K} \theta_{ij} x_{ijk}
⟨θ,x⟩=i=1∑nj=1∑nk=1∑Kθijxijk
其中
x
i
j
x_{ij}
xij和
x
i
j
k
x_{ijk}
xijk是二元变量,如果连接节点i和节点j的边在路由中被使用,则等于1,否则为0。对于三索引的形式,有一个额外的索引
k
k
k,指定使用该边的K个可用车辆中的哪一个。此外,还可以在成本函数中包含一个仿射项,例如:
h
(
s
^
,
x
)
=
∑
i
=
1
n
∑
j
=
1
n
M
i
j
(
s
^
)
x
i
j
h(\hat{s}, x) = \sum_{i=1}^{n} \sum_{j=1}^{n} M_{ij}(\hat{s}) x_{ij}
h(s^,x)=i=1∑nj=1∑nMij(s^)xij
其中项
M
i
j
(
s
^
)
∈
R
M_{ij}(\hat{s}) \in \mathbb{R}
Mij(s^)∈R可用于构建作者希望在模型中强制执行的某些行为。
总之,最终的目标是通过IO学习一个成本向量
θ
\theta
θ,使得在解决前向优化问题(FOP)时:
(
3
)
FOP
(
θ
,
s
^
)
:
=
arg
min
x
∈
X
(
s
^
)
{
⟨
θ
,
x
⟩
+
h
(
s
^
,
x
)
}
(3)\text{FOP}(\theta, \hat{s}) := \arg \min_{x \in \mathbb{X}(\hat{s})} \{ \langle \theta, x \rangle + h(\hat{s}, x) \}
(3)FOP(θ,s^):=argx∈X(s^)min{⟨θ,x⟩+h(s^,x)}
作者可以重现(或近似)专家在解决未知优化问题(1)时在给定相同信号
s
^
\hat{s}
s^ 下所采取的响应。
2.3 定制损失函数
给定一个信号-响应数据集
{
(
s
^
[
i
]
,
x
^
[
i
]
)
}
i
=
1
N
\{(\hat{s}^{[i]}, \hat{x}^{[i]})\}_{i=1}^{N}
{(s^[i],x^[i])}i=1N,在本研究中,作者提出通过解决一个损失最小化问题来解决IO问题(即,找到参数向量
θ
\theta
θ):
(
4
)
min
θ
≥
0
1
N
∑
i
=
1
N
ℓ
θ
(
s
^
[
i
]
,
x
^
[
i
]
)
(4)\min_{\theta \geq 0} \frac{1}{N} \sum_{i=1}^{N} \ell_\theta(\hat{s}^{[i]}, \hat{x}^{[i]})
(4)θ≥0minN1i=1∑Nℓθ(s^[i],x^[i])
其中
ℓ
θ
:
S
×
X
→
R
\ell_\theta : \mathbb{S} \times \mathbb{X} \to \mathbb{R}
ℓθ:S×X→R 是损失函数。利用仿射假设类(2),作者提出以下损失函数:
(
5
)
ℓ
θ
(
s
^
,
x
^
)
:
=
⟨
θ
,
x
^
⟩
+
h
(
s
^
,
x
^
)
−
min
x
∈
X
(
s
^
)
{
⟨
θ
+
2
x
^
−
1
,
x
⟩
+
h
(
s
^
,
x
)
−
⟨
1
,
x
^
⟩
}
(5)\ell_\theta(\hat{s}, \hat{x}) := \langle \theta, \hat{x} \rangle + h(\hat{s}, \hat{x}) - \min_{x \in \mathbb{X}(\hat{s})} \left\{ \langle \theta + 2\hat{x} - 1, x \rangle + h(\hat{s}, x) - \langle 1, \hat{x} \rangle \right\}
(5)ℓθ(s^,x^):=⟨θ,x^⟩+h(s^,x^)−x∈X(s^)min{⟨θ+2x^−1,x⟩+h(s^,x)−⟨1,x^⟩}
损失函数(5)是 Zattoni Scroccaro、Atasoy 和 Mohajerin Esfahani(2024)提出的损失函数的扩展。
2.4 一阶算法
在本研究中,作者提出使用随机一阶算法来解决问题(4),如下图所示

在算法中,作者选择了一个预定义的
T
T
T,并在每个周期后监控模型的性能。在每个周期开始时对
[
N
]
[N]
[N] 进行一次排列抽样(第 3 行),这仅意味着数据集中示例的顺序被打乱。这被称为随机重新洗牌,研究表明与标准均匀随机抽样相比,这种方法在实践中表现更好。接下来,对于每个周期,作者对数据集中的每个示例执行一次更新步骤。特别是在第 5 行计算 A-FOP 的一个元素,作者定义:
(
6
)
A-FOP
(
θ
,
s
^
,
x
^
)
=
arg
min
x
∈
X
(
s
^
)
{
⟨
θ
+
2
x
^
−
1
,
x
⟩
+
h
(
s
^
,
x
)
}
(6)\text{A-FOP}(\theta, \hat{s}, \hat{x}) = \arg \min_{x \in \mathbb{X}(\hat{s})} \left\{ \langle \theta + 2\hat{x} - 1, x \rangle + h(\hat{s}, x) \right\}
(6)A-FOP(θ,s^,x^)=argx∈X(s^)min{⟨θ+2x^−1,x⟩+h(s^,x)}
在第 6 行计算损失函数 (5) 的次梯度。对于更新步骤(第 7 行),作者提供两种可能性:
- 指数更新:专门用于具有非负变量的优化问题。
- 标准更新:可以解释为使用标准投影次梯度方法,投影到非负锥体上。
最后,为了将算法的输出 { θ t [ N + 1 ] } t = 1 T \{\theta^{[N+1]}_t\}_{t=1}^T {θt[N+1]}t=1T 转换为单一成本向量,可以使用标准方法,例如:
- θ = θ T [ N + 1 ] \theta = \theta^{[N+1]}_T θ=θT[N+1](最后一次迭代)
- θ = 1 T ∑ t = 1 T θ t [ N + 1 ] \theta = \frac{1}{T} \sum_{t=1}^T \theta^{[N+1]}_t θ=T1∑t=1Tθt[N+1](平均)
- θ = 2 T ( T + 1 ) ∑ t = 1 T t θ t [ N + 1 ] \theta = \frac{2}{T(T+1)} \sum_{t=1}^T t \theta^{[N+1]}_t θ=T(T+1)2∑t=1Ttθt[N+1](加权平均)
3. 建模示例
这部分作者阐述了如何使用IO方法对SCVRP问题,VRPTW问题和R-TSP问题进行建模的示例。
3.1 SCVRP问题
K辆车的对称有容量车辆路径问题(SCVRP)定义为
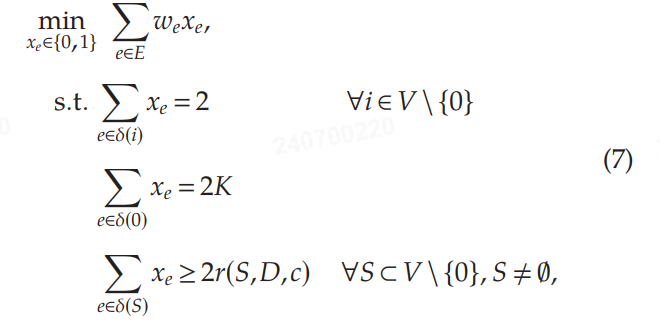
在这里,$ G = (V, E, W) $ 是一个边权重图,其中节点集为 $ V $(节点 0 为仓库),无向边集为 $ E $,边权重为 $ W $。对于这个问题,每个节点 $i \in V $ 代表一个需求为 d i ∈ D d_i \in D di∈D 的客户。共有 K K K辆车,每辆车的容量为 $ c $。给定一个集合 $ S \subset V $,用 $ \delta(S) $ 表示仅在 S S S 中有一个端点的边的集合。此外,给定一个集合 S ⊂ V S \subset V S⊂V \ {0},用 r ( S , D , c ) r(S,D,c) r(S,D,c) 表示服务集合 S S S 中所有客户需求所需的最小车辆数,车辆容量为 $ c $。变量 $ x_e $ 是二元变量,如果边 $ e \in E $ 在解中被使用,则其值为 1,否则为 0,而$ w_e \in W $ 是边$ e \in E $ 的权重。
接下来,作者展示在给定一组示例路径的数据集的前提下,如何使用IO来学习边权重,以复制专家的行为。考虑信号 s ^ : = D \hat{s}:=D s^:=D,其中 D D D是客户的需求集合,响应为 x ^ ∈ { 0 , 1 } ∣ E ∣ \hat{x} \in \{0, 1\}^{|E|} x^∈{0,1}∣E∣。定义线性假设函数(即, h ( s ^ , x ) = 0 h(\hat{s}, x) = 0 h(s^,x)=0)如下:
(
8
)
⟨
θ
,
x
⟩
:
=
∑
e
∈
E
θ
e
x
e
(8)\langle \theta, x \rangle := \sum_{e \in E} \theta_e x_e
(8)⟨θ,x⟩:=e∈E∑θexe
并定义约束集如下:
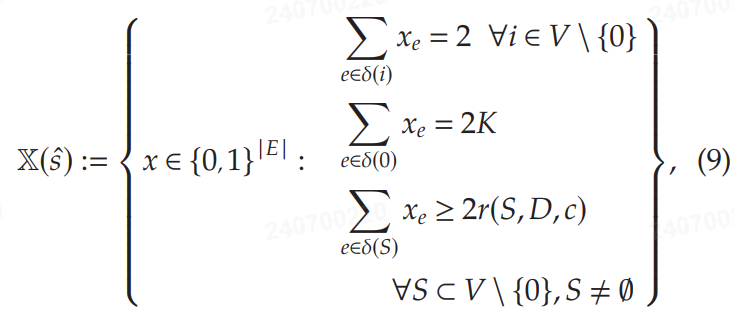
作者将信号-响应对 $ (\hat{s}, \hat{x}) $ 解释为来自一个专家代理,该代理在给定需求信号 $ \hat{s} $ 的情况下,解决 SCVRP 以计算其响应 $ \hat{x} $。因此,为了学习一个成本函数(即,学习一个边权重向量)以复制 SCVRP 路径 $ \hat{x} $,可以使用算法 1 来解决问题 (4),该问题使用假设 (8) 和约束集 (9)。
为了说明算法 1 如何在图的路由问题中学习边权重,考虑一个简单的 SCVRP,其中 $ K = 2 $ 辆车,每辆车的容量 $ c = 3 $,以及 5 个客户,每个客户 $ i $ 的需求 $ d_i = 1 $。在这个例子中,为了简单起见,作者使用边权重 $ w_e $ 等于客户之间的欧几里得距离,然后使用这些权重创建一个训练示例。图 1(a) 显示了客户的位置(点)、仓库(方形)和使用权重 $ w_e $ 的最优 SCVRP 路径。图 1(b) 显示了图中每条边的权重表示,其中权重越小,边越粗和越暗。作者使用算法 1,并采用指数更新,设置 $ \eta_t = 0.0002 $,并将初始权重 $ \theta_1 $ 设置为所有边相同的权重。
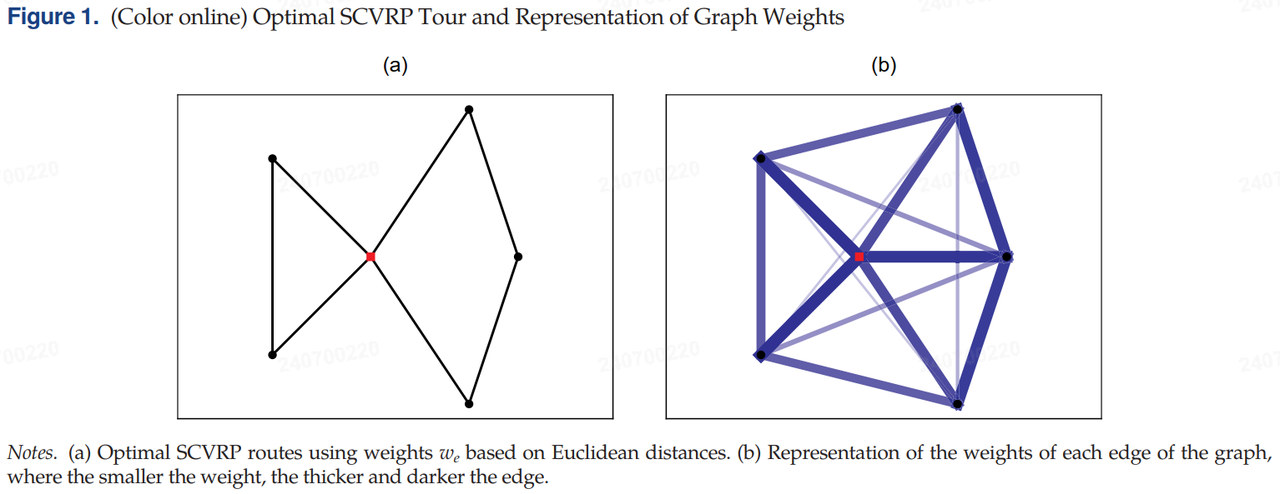
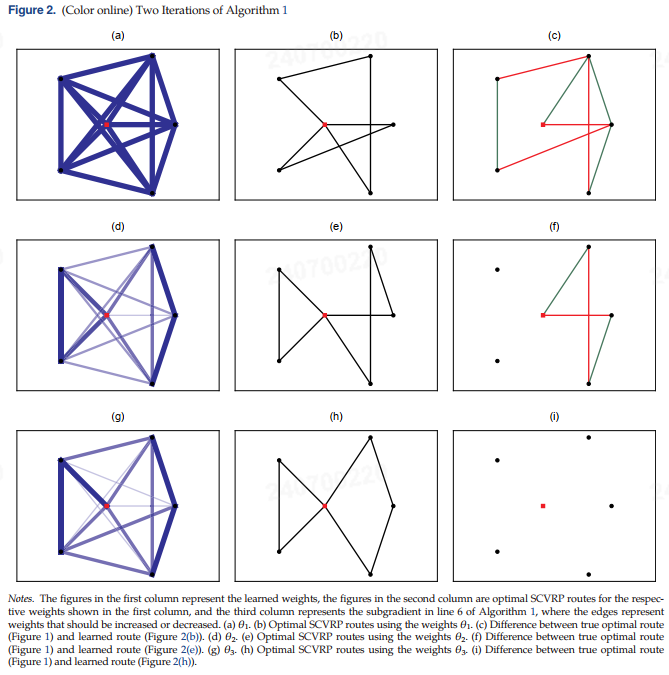
图 2 展示了该问题的两个迭代过程。第一列展示了学习到的权重 $ \theta_t $ 的演变。第二列展示了使用第一列中的权重计算的最优 SCVRP 路径(即,通过解决算法 1 第 5 行中的 A-FOP 计算的路径),第三列展示了使用真实权重(图 1(a))的最优路径与使用当前学习到的权重(第二列中的路径)之间的差异。这两条路径之间的差异是算法 1 第 6 行中计算的次梯度,用于更新学习到的权重 $ \theta_t $。在第三列中,次梯度的表示中,边表示负或正的次梯度,即应增加或减少的边权重。这是算法 1 的主要直觉:在每次迭代中,作者将要复制的路径与当前边权重下得到的路径进行比较。然后,通过比较这两条路径中使用的边,相应地增加或减少它们的权重,从而推动使用学习到的权重的最优路径更接近理想要复制的路径。在图 2 中的示例中可以看到,在算法 1 的两次迭代后,使用学习到的权重的最优路径与示例路径重合。
3.2 VRPTW问题
考虑带时间窗的车辆路径问题(VRPTW):
(
10
)
min
x
i
j
k
∈
{
0
,
1
}
∑
i
=
1
n
∑
j
=
1
n
∑
k
=
1
K
w
i
j
x
i
j
k
(10)\min_{x_{ijk} \in \{0, 1\}} \sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{k=1}^{K} w_{ij} x_{ijk}
(10)xijk∈{0,1}mini=1∑nj=1∑nk=1∑Kwijxijk
s.t.
x
∈
X
(
s
^
)
\text{s.t.} \quad x \in \mathbb{X}(\hat{s})
s.t.x∈X(s^),
其中
n
n
n是客户的数量,$ K $ 是可用车辆的最大数量,$ x_{ijk} $ 是一个二元变量,如果车辆
k
k
k在解中从节点
i
i
i到节点
j
j
j的边经过,则其值为 1,否则为 0,$ w_{ij} $ 是连接节点
i
i
i和节点
j
j
j的边的权重。在(10) 的约束集中,$ x $ 是包含变量$ x_{ijk} $ 的向量,信号$ \hat{s} $ 被定义为需要遵守的时间窗列表(每个客户一个),而$ \mathbb{X}(\hat{s}) $ 是 VRPTW 中时间窗的可行解集。集合$ \mathbb{X}(\hat{s}) $ 可能依赖于问题的其他参数,例如每个客户的服务时间、每个客户的需求、客户之间的旅行时间等。在此示例中作者明确使约束集仅依赖于时间窗,因为这是在本例中唯一会变化的外部参数。
接下来将阐述如何将 VRPTW 建模到 IO 框架中。考虑数据集
{
(
s
^
[
i
]
,
x
^
[
i
]
)
}
i
=
1
N
\{(\hat{s}^{[i]}, \hat{x}^{[i]})\}_{i=1}^{N}
{(s^[i],x^[i])}i=1N,其中信号
s
^
[
i
]
\hat{s}^{[i]}
s^[i] 是需要遵守的时间窗列表,响应
x
^
[
i
]
∈
{
0
,
1
}
n
2
K
\hat{x}^{[i] }\in \{0, 1\}^{n^2K}
x^[i]∈{0,1}n2K 是相应的最优 VRPTW 路径(即,包含组件$ x_{ijk} $ 的向量)。定义线性假设函数:
(
11
)
⟨
θ
,
x
⟩
:
=
∑
i
=
1
n
∑
j
=
1
n
∑
k
=
1
K
θ
i
j
x
i
j
k
(11)\langle \theta, x \rangle := \sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{k=1}^{K} \theta_{ij} x_{ijk}
(11)⟨θ,x⟩:=i=1∑nj=1∑nk=1∑Kθijxijk
将该数据集解释为来自一个专家代理,该代理在给定信号
s
^
[
i
]
\hat{s}^{[i]}
s^[i] 的情况下,解决 VRPTW 以计算其响应
x
^
[
i
]
\hat{x}^{[i]}
x^[i]。因此,为了学习一个成本函数(即,学习一个边权重向量)以复制 VRPTW 路径
x
^
\hat{x}
x^,本文使用算法 1 来解决问题 (4),使用假设 (11) 和约束集 (10)。
作者选择了一个VRPTW场景实例来生成测试 IO 公式的训练数据:具有$ n = 200 $ 个客户和$ K = 15 $ 辆可用车辆,数据集 { ( s ^ [ i ] , x ^ [ i ] ) } i = 1 N \{(\hat{s}^{[i]}, \hat{x}^{[i]})\}_{i=1}^{N} {(s^[i],x^[i])}i=1N,其中信号 s ^ [ i ] \hat{s}^{[i]} s^[i] 是客户的时间窗随机分配,响应 x ^ [ i ] \hat{x}^{[i]} x^[i] 是相应的最优 VRPTW 解。作者生成了 n = 50 n=50 n=50个训练和测试实例,所有这些实例都有相同的真实边权重 $ w_{ij} ,对应于从客户 ,对应于从客户 ,对应于从客户i$到客户 j j j的真实行驶时间。因此,本文的 IO 目标是学习一组权重 $ \theta_{ij} ,使得在给定的信号 − 响应训练示例数据集中尽可能复制使用 ,使得在给定的信号-响应训练示例数据集中尽可能复制使用 ,使得在给定的信号−响应训练示例数据集中尽可能复制使用w_{ij}$ 的路径。作者测试了三种解决 IO 问题的方法,并将初始权重$ \theta_1 $ 设置为客户 i i i和 j j j之间的欧几里得距离。
- 切割平面法:
使用 Wang (2009) 的切割平面算法来解决
min
θ
≥
0
∣
∣
θ
−
θ
1
∣
∣
1
\min_{\theta \geq 0} ||\theta - \theta_1||_1
θ≥0min∣∣θ−θ1∣∣1
s.t.
x
^
i
∈
F
O
P
(
θ
,
s
^
i
)
∀
i
∈
[
N
]
\text{s.t. } \quad \hat{x}_i \in FOP(\theta, \hat{s}_i) \, \quad \forall i \in [N]
s.t. x^i∈FOP(θ,s^i)∀i∈[N]
这是 Bodur、Chan 和 Zhu (2022) 提出的多点 IO 公式。
- SAMD法
使用 Zattoni Scroccaro、Atasoy 和 Mohajerin Esfahani (2024) 的 SAMD 算法来解决 (4),采用指数更新和 $ \eta_t = 0.3/t $。
- 算法 1
使用算法 1 来解决 (4),采用指数更新和 $ \eta_t = 0.3/t $。在这个例子中,Zattoni Scroccaro、Atasoy 和 Mohajerin Esfahani (2024) 的 SAMD 算法与算法 1 的区别在于,前者使用均匀随机采样,而后者使用重新洗牌的采样策略。
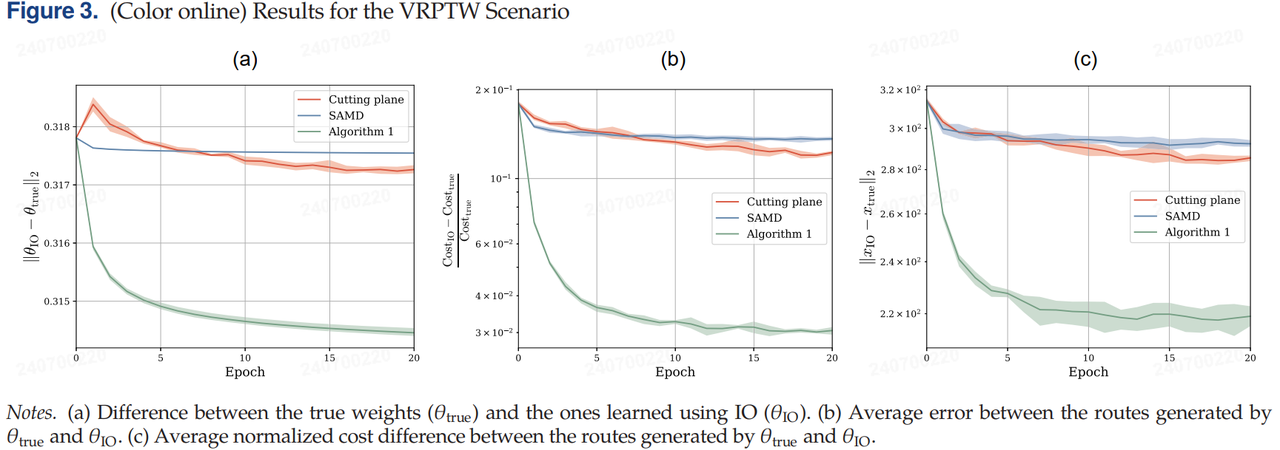
图 3 显示了该实验的结果。在所有图中,x 轴表示周期 $ t \in [1, T] $,它由用于解决问题的方法的
N
N
N次迭代组成。图 3(a) 显示了 IO 方法返回的权重向量(即 $ \theta_{IO} $)与用于生成数据的权重向量(即 $ \theta_{true}
)之间的归一化差异。图
3
(
b
)
显示了使用
)之间的归一化差异。图 3(b) 显示了使用
)之间的归一化差异。图3(b)显示了使用 \theta_{IO}
的最优路径(即
的最优路径(即
的最优路径(即 x_{IO} $)与测试数据集中的路径(即 $ x_{true}
)之间的平均差异。图
3
(
c
)
显示了专家决策的成本与使用
)之间的平均差异。图 3(c) 显示了专家决策的成本与使用
)之间的平均差异。图3(c)显示了专家决策的成本与使用 \theta_{IO} $的决策成本之间的归一化差异。定义
Cost
I
O
:
=
∑
i
=
1
N
⟨
θ
t
r
u
e
,
x
I
O
[
i
]
⟩
\text{Cost}_{IO} := \sum_{i=1}^{N} \langle \theta_{true}, x^{[i]}_{IO} \rangle
CostIO:=i=1∑N⟨θtrue,xIO[i]⟩
Cost
t
r
u
e
:
=
∑
i
=
1
N
⟨
θ
t
r
u
e
,
x
t
r
u
e
[
i
]
⟩
\text{Cost}_{true} := \sum_{i=1}^{N} \langle \theta_{true}, x^{[i]}_{true} \rangle
Costtrue:=i=1∑N⟨θtrue,xtrue[i]⟩
并比较它们之间的相对差异。由于$ x^{[i]}_{true} $ 的最优性,这个差异将始终是非负的。从该实验的结果中可以看到,算法 1 的表现明显优于其他方法(即切割平面和 SAMD),这表明重新洗牌采样策略,即算法 1在这个例子中的有效性。
3.3 R-TSP问题
设$ G = (V, E, W) $ 是一个完整的边权重有向图,其中节点集为 $ V $,有向边为 $ E $,边权重为 $ W $。接下来,给定 $ \hat{s} \subset V $(即,图 G G G 的节点子集),作者将限制旅行销售员问题(R-TSP)定义为:
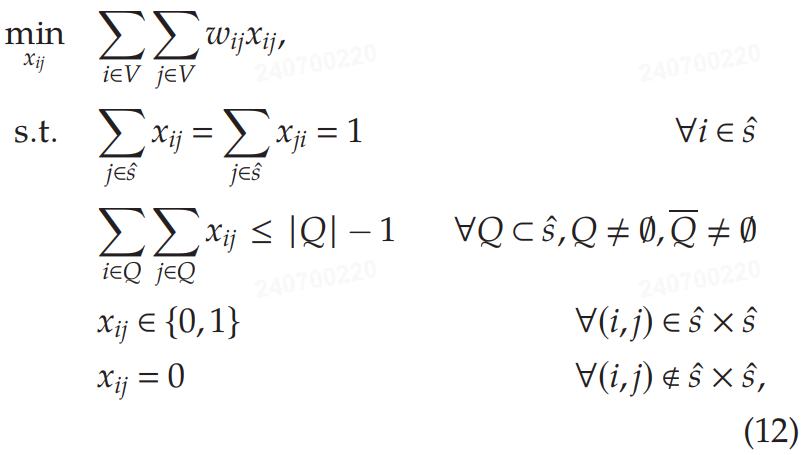
其中$ x_{ij} $ 是一个二元变量,如果从节点 i i i到节点 j j j的边在解中被使用,则其值为 1,否则为 0,$ w_{ij} $ 是连接节点 i i i和节点 j j j的边的权重。问题 (12) 基于标准的旅行销售员问题(TSP)的二元优化问题公式(Dantzig, Fulkerson, 和 Johnson 1954)。与标准 TSP 的唯一区别在于,对于 R-TSP,所需要计算的是节点集合$ \hat{s} $ 的最优巡回路径,而不是要求访问图中的所有节点。
接下来的内容讲阐述如何使用 IO 学习边权重,以复制专家的行为。给定一组示例路径,考虑数据集
{
(
s
^
[
i
]
,
x
^
[
i
]
)
}
i
=
1
N
\{(\hat{s}^{[i]}, \hat{x}^{[i]})\}_{i=1}^{N}
{(s^[i],x^[i])}i=1N,其中信号
s
^
[
i
]
∈
V
\hat{s}^{[i]} \in V
s^[i]∈V 是需要访问的节点集合,响应
x
^
[
i
]
∈
{
0
,
1
}
∣
V
∣
2
\hat{x}^{[i]} \in \{0, 1\}^{|V|^2}
x^[i]∈{0,1}∣V∣2 是相应的最优 R-TSP 路径(即,包含组件$ x_{ij} $ 的向量,适用于 $ (i, j) \in V \times V $)。定义仿射假设函数:
(
13
)
⟨
θ
,
x
⟩
+
h
(
s
^
,
x
)
:
=
∑
i
∈
V
∑
j
∈
V
(
θ
i
j
+
M
i
j
)
x
i
j
,
(13)\langle \theta, x \rangle + h(\hat{s}, x) := \sum_{i \in V} \sum_{j \in V} (\theta_{ij} + M_{ij}) x_{ij}, \quad
(13)⟨θ,x⟩+h(s^,x):=i∈V∑j∈V∑(θij+Mij)xij,
以及约束集:
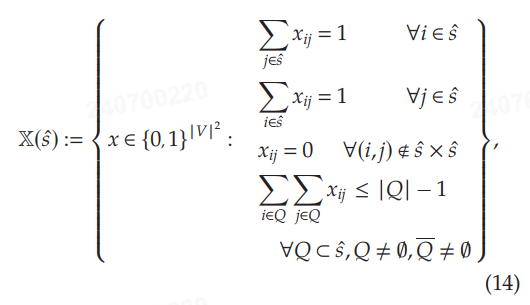
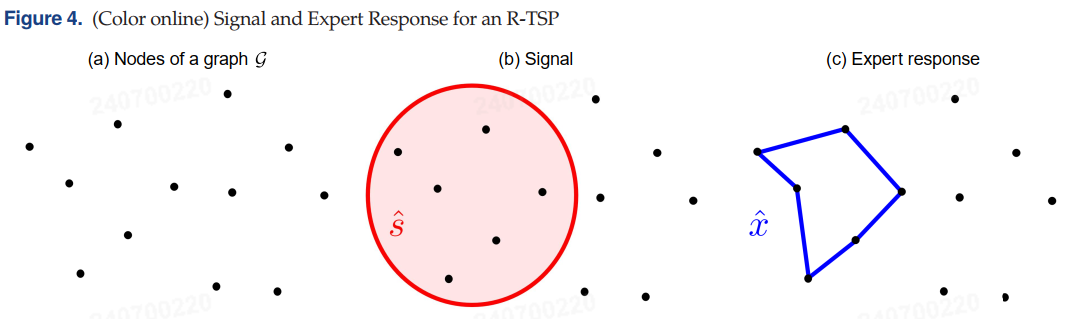
作者将这个数据集解释为来自一个专家代理的输出,该代理在给定信号 s ^ [ i ] \hat{s}^{[i]} s^[i]的情况下,解决一个 R-TSP 问题以计算其响应 x ^ [ i ] \hat{x}^{[i]} x^[i]。对于假设函数,项 M i j M_{ij} Mij 可以用作惩罚项,以强制模型执行某种预期行为,例如,通过对图中的某些边添加惩罚。图 4 说明了一个信号及其对应的专家响应。因此,为了学习一个成本函数,即学习一个边权重向量,以复制或尽可能接近数据集中示例路径,可以使用算法 1 来解决问题 (4),结合假设 (13) 和约束集 (14)。
从以上建模示例中,作者总结了IO方法的以下特点:
- IO 方法并不要求数据集 { ( s ^ [ i ] , x ^ [ i ] ) } i = 1 N \{(\hat{s}^{[i]}, \hat{x}^{[i]})\}_{i=1}^{N} {(s^[i],x^[i])}i=1N 与单一成本函数(即单一边权重集)一致,这在任何现实环境中都是可以预期的,原因包括模型不确定性、测量噪声或有限理性等等。
- IO方法可以轻松适应不同类型的路径规划问题。例如,如果问题是带有回程的 VRP,或者是取货和送货位置,可以通过修改假设专家代理正在解决的问题以生成其响应,这突显了 IO 方法的普遍性和灵活性。
- IO方法可以轻松适应新信号-响应示例以在线方式到达的场景。也就是说,不是从离线数据集中学习示例,而是使用在线示例逐渐更新边权重 θ t \theta_t θt,这可以通过调整算法 1 来直接完成,以使用在线到达的示例,方式与使用信号-响应对 ( s ^ [ π i ] , x ^ [ π i ] ) (\hat{s}^{[\pi_i]}, \hat{x}^{[\pi_i]}) (s^[πi],x^[πi]) 相同。
4. 结论
在本研究中,作者提出了一种 IO 方法论,用于学习决策者在路由问题中的偏好。为了展示IO方法的潜力和灵活性,作者首先将其应用于一个简单的 CVRP 问题,通过比较示例路线与使用当前学习的权重获得的最优路线,展示 IO 算法的工作原理。然后将其应用于一个更大的 VRPTW 示例,比较文中提出的算法与文献中不同方法的性能。最后,作者通过仅需访问部分节点的 TSP问题,给定信号数据集(要访问的节点)和专家响应(R-TSP 路线),阐述了如何使用 IO 学习解释观察到的数据的边权重。作者还在原文中描述了一个具体案例,即在亚马逊挑战赛的背景下,学习这些边权重转化为学习专家人类驾驶员偏好的城市区域顺序,有兴趣的小伙伴可以去阅读原文。
作为未来的研究方向,IO方法论可以应用于不同且更复杂的路由问题,例如动态 VRP、带回程的路由问题,以及具有连续决策变量的路由问题。此外,尽管在本研究专注于路由问题,但本文提出的方法论也可以适应并定制不同类别的具有二元决策空间的问题,例如 0-1 背包等更广泛的现实世界决策问题。
参考文献:
[1] Pedro Zattoni Scroccaro, Piet van Beek, Peyman Mohajerin Esfahani, Bilge Atasoy (2024) Inverse Optimization for Routing Problems. Transportation Science 0(0). https://doi.org/10.1287/trsc.2023.0241
[2] Zattoni Scroccaro P, Atasoy B, Mohajerin Esfahani P (2024) Learning in inverse optimization: Incenter cost, augmented suboptimality loss, and algorithms. Oper. Res. Forthcoming.
[3] Wang L (2009) Cutting plane algorithms for the inverse mixed integer linear programming problem. Oper. Res. Lett. 37(2):114–116
[4] Bodur M, Chan TCY, Zhu IY (2022) Inverse mixed integer optimization: Polyhedral insights and trust region methods. INFORMS J. Comput. 34(3):1471–1488.

















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









