






编者按
在物流运输、快递配送等场景中,如何规划车辆行驶路线,让成本最低、效率最高,这就是车辆路径规划问题(VRP)。它在计算机科学、运筹学等领域十分关键,可由于实际场景中存在各种复杂约束条件,求解难度极大。不过,最近一项发表于 ICLR 2025 的研究 “DRoC: Elevating large language models for complex vehicle routing via decomposed retrieval of constraints”为解决包括VRP在内的约束优化问题带来了新希望。
摘要:
本文提出了约束分解检索(DRoC)框架,旨在增强大语言模型(LLM)利用求解器处理复杂约束车辆路径问题(VRP)的能力。尽管 LLMs 在解决简单 VRPs 方面展现出一定潜力,但由于其内部嵌入知识有限,难以准确反映多样的 VRP 约束,在处理复杂 VRP 变体时能力受限。DRoC 框架通过一种新颖的检索增强生成(RAG)方法整合外部知识,对 VRP 约束进行分解,分别检索与各约束相关的信息,并将内部和外部知识协同结合,以优化解决 VRPs 的程序生成。该框架还允许 LLM 在 RAG 和自我调试机制之间动态选择,无需额外训练即可优化程序生成。在 48 个 VRP 变体上的实验表明,DRoC 具有优越性,生成程序的准确率和运行时错误率都有显著改善。DRoC 框架有望提升 LLM 在复杂优化任务中的性能,推动 LLM 在交通和物流等行业的应用。
关键词:大语言模型;车辆路径问题;约束分解检索框架
1. VRP 求解困境与大语言模型的挑战
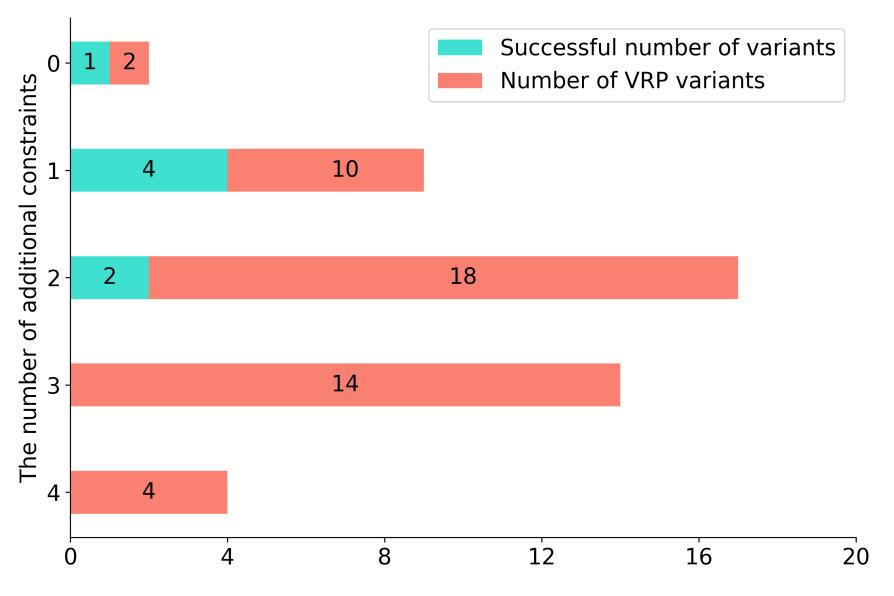
传统求解 VRP 的工具,例如 OR - tools 和 Gurobi,虽功能强大,但对普通用户并不友好。当 VRP 涉及复杂约束时,由于缺乏具体的示例代码和文档指导,用户运用这些工具建模求解时常遇到困难,需要依赖较强的专业领域知识。 大语言模型(LLM)的出现,为自动化解决 VRP 带来可能。它在一些领域展现出专家级能力,也能处理简单的 OR 问题。可一旦面对有复合约束的 VRP,LLM 就 “力不从心” 了。比如,GPT-3.5-turbo 在解决 48 个 VRP 变体时,随着约束增多,准确率大幅下降。这是因为 LLM 内部知识有限,训练数据中的领域特定语料不足,导致在生成解决 VRP 的程序时,难以准确表述特定约束,也无法有效整合不同约束。下图展示了gpt-3.5-turbo对具有不同数量复合约束的 48 个 VRP 变体的求解效果。
2. DRoC 框架
为了让 LLM 更好地解决复杂 VRP,文章提出了约束分解检索(Decomposed Retrieval of Constraints, DRoC)框架。该框架融合外部知识与分解技术,能让 LLM 在无需额外训练的情况下,更高效地应对复杂 VRP。DRoC 框架的实现主要分为以下几步:
-
直接代码生成:LLM依据输入的 VRP 直接生成程序。此时,生成过程仅依赖 LLM 内部知识,凭借其固有编程能力尝试解决问题。
-
代码检查:生成的程序由代码执行器运行,调用求解器处理目标问题。若代码存在错误,执行器会将错误信息反馈给 LLM,这相当于为 LLM 提供外部反馈进行反思。
-
路由决策:LLM 充当路由智能体,根据代码执行报错信息决定下一步操作,选择自我调试或 RAG(检索增强生成)。
-
自我调试或分解检索:若选择自我调试,LLM 会分析错误并优化代码;若选择进行检索增强生成,会将检索过程分解,针对 VRP 的各个约束从外部文档或示例代码中查找相关信息,提升代码生成的准确性。
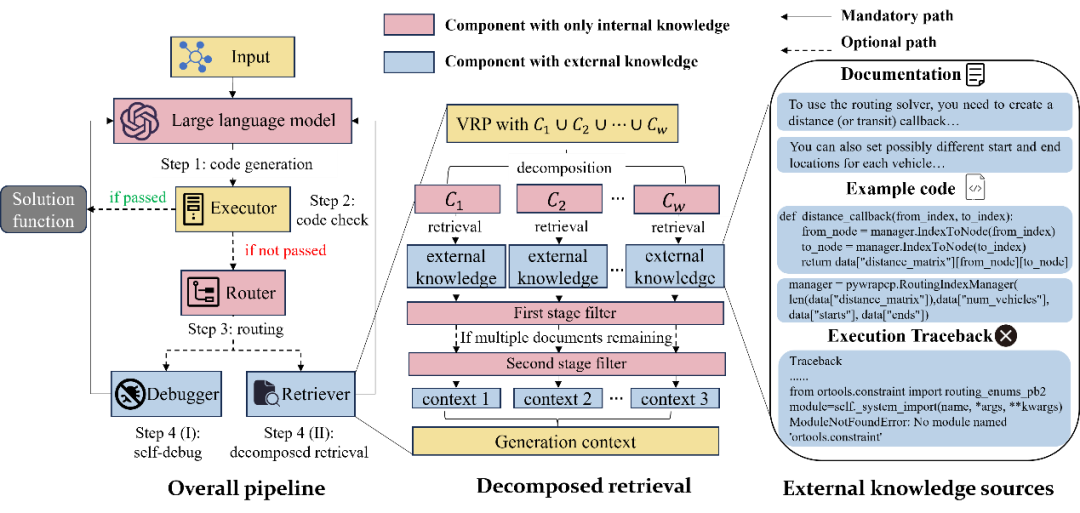
下图直观呈现了 DRoC 框架的工作流程和关键环节,包括直接代码生成、代码检查、路由决策、自我调试或分解检索。右侧子图以 OR-Tools 为例,展示外部知识来源,如求解器文档、示例代码和代码执行反馈。中间子图展示问题分解过程,将 VRP 约束分解为单个关键词,便于后续检索。
3. 关键技术点解析
-
外部知识来源:VRP 求解器通常有丰富的社区文档和示例代码,DRoC 将其纳入外部知识源。以 Google 的 OR - Tools 为例,其在线文档有详细教程,开源仓库也有大量示例代码。此外,代码执行器的反馈,如 Python 解释器提供的错误信息和回溯,也能帮助 LLM 精准定位代码错误。
-
分解检索:为了克服传统 RAG 在解决复杂 VRP 时难以获取合适上下文的问题,DRoC 采用分解检索策略。先将目标 VRP 按约束分解,用分解器(也是 LLM)把约束转化为关键词;再利用 OpenAI 的嵌入模型检索相关外部知识,通过计算平方欧氏距离衡量相似度,选取最相关文档;最后将检索到的单约束上下文合并,为 LLM 生成新程序提供指导。同时,还设计了两级过滤器,筛选掉无关信息,确保检索内容的相关性和准确性。
-
实现细节:DRoC 允许 LLM 生成代码的过程最多进行 I 次迭代。若首次生成失败,路由器会在自我调试和分解检索两种策略中动态选择。研究团队设计了两种提示模板,检索增强生成器用于基于检索上下文生成全新程序,检索增强调试器则在后续迭代中优化已有代码。
4. XAI监管
为了验证 DRoC 的有效性,文章在 48 个 VRP 变体上对 DRoC 和多种基线方法进行评估。主要使用 ChatGPT(gpt-4o 和 gpt-3.5-turbo)作为 LLM,OR - tools 作为优化求解器,并在其他 LLM(如 claude3.5 和 llama3.1)和求解器(如 Gurobi)上进行实验,同时提供了在其他优化问题(如工人指派问题和设施选址问题)上的实验结果,以验证其通用性。
-
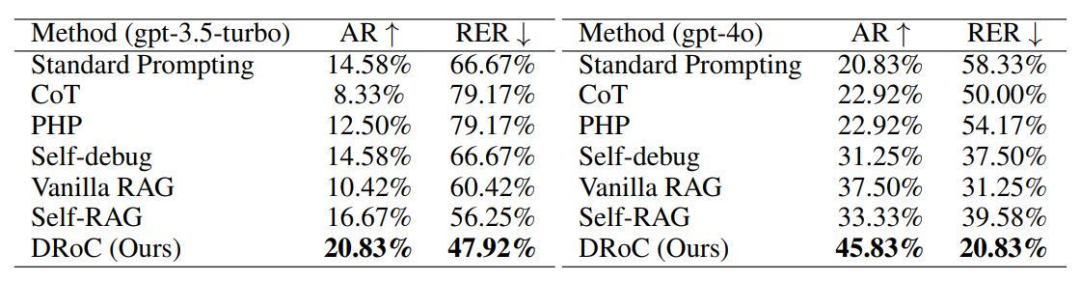
整体性能:实验结果显示,即便使用更强大的 LLM(如 gpt-4o),6 种基线方法在解决复杂 VRP 时,成功率也不到 40%。而 DRoC 在生成正确程序和减少运行时错误方面表现最佳。相比标准提示方法,gpt - 4o 使用 DROC 能多解决 25% 的 VRP 变体,且生成的无错程序更多,整体性能对比情况如下表(AR:准确率,RER:运行错误率)。
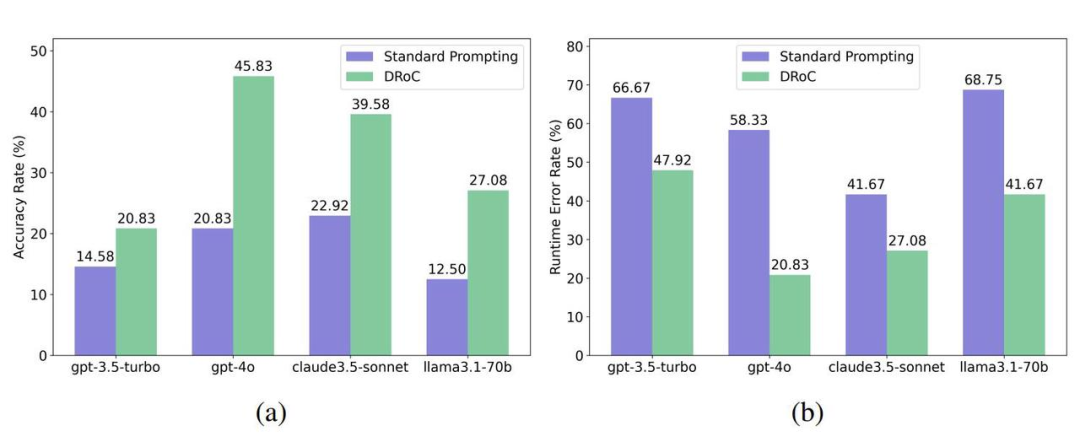
2. 不同 LLM 的评估:在 claude-3.5-sonnet 和 llama3.1-70b等 LLM 上,DRoC 同样能提升其解决 VRP 的能力,表明 DRoC 具有通用性,不受 LLM 架构差异的影响。具体表现如下图所示,其中(a)图展示准确率(AR)指标,(b)图展示运行错误率(RER)指标。
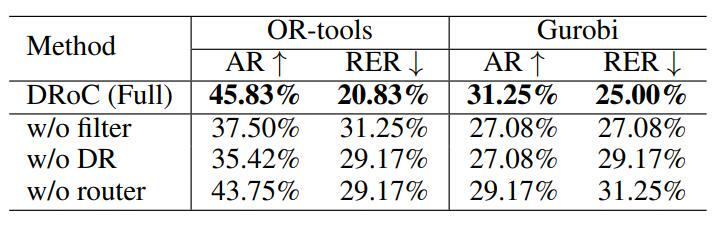
3. 与 Gurobi 求解器的结合:DRoC 与 Gurobi 求解器结合时依然有效。即便外部知识源仅包含简单 VRP 解决方案,LLM 借助 DRoC 仍能准确解决更多复杂 VRP 变体,具体表现如下表。

4. 消融研究:通过对 DRoC 关键组件的消融研究发现,两级过滤器、分解检索和路由器对模型性能都很重要。去掉这些组件,模型性能会下降,具体表现如下表。
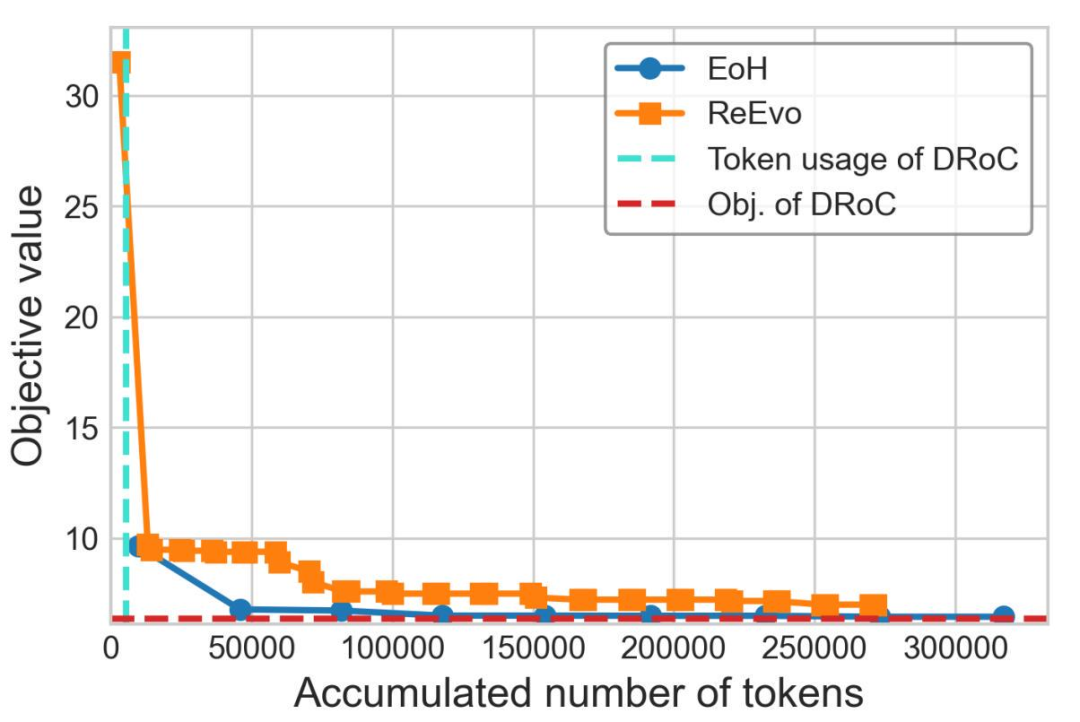
5. 与 LLM + EC 方法的比较:对比基于进化计算的 LLM + EC 方法,DRoC 在解决特定 VRP(如 PCTSP)时,不仅计算成本更低(消耗更少的 token),而且能获得更优的目标值。具体表现如下图所示,横坐标为累积的 token 使用量,纵坐标为目标值。以奖品收集旅行商问题(PCTSP)为例,LLM+EC 方法(EoH 和 ReEvo)在迭代进化过程中需要消耗大量 token(超过 0.1M),且得到的最佳目标值分别为 6.436 和 6.984;而 DRoC 结合 OR-Tools 得到的目标值为 6.352。
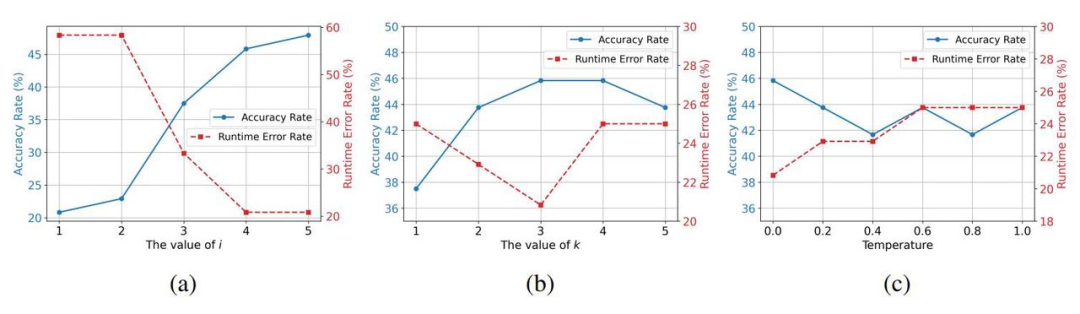
6. 敏感性分析:研究还分析了 DRoC 中关键参数对性能的影响,如下图所示。发现增加最大生成次数 I,性能会提升,但 4 次之后提升幅度变小;检索文档数量 k 在 1 - 3 范围内变化时,性能会略有提升,之后趋于稳定;温度参数对性能影响较小。
7. 基于 Bootstrap 的优化:将 LLM 生成的正确结果纳入外部知识,通过 Bootstrap 机制能进一步提升 DRoC 性能,引入该机制后,超过 50% 的 VRP 变体可被解决。
5. 总结与拓展
DRoC 不仅在 VRP 领域表现出色,在其他运筹学问题上也有应用潜力。在分配问题中,DRoC 能正确建模约束,生成有效程序,而传统方法则难以做到;在设施选址问题上,DRoC 能帮助 LLM 解决更多变体问题,包括外部知识未涵盖的部分。
这项研究提出的 DRoC 框架为解决复杂 VRP 提供了有效方案,显著提升了 LLM 在该领域的性能。未来,研究团队计划将 DRoC 与求解器选择、元启发式生成过程相结合,增强其在更多优化任务中的通用性和可靠性;还会引入更多外部知识源,优化 RAG 性能,并将建模功能集成到框架中,进一步提升其效果。相信随着研究的深入,基于LLM的运筹求解方法将在交通、物流等行业发挥更大作用,为解决实际优化问题带来更多便利。
参考文献:
[1] 论文原文链接:DROC: ELEVATING LARGE LANGUAGE MODELS FOR COMPLEX VEHICLE ROUTING VIA DECOMPOSED RETRIEVAL OF CONSTRAINTS

















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









