









贯穿始终的EDA
1.如何确保自己准备好竞赛使用的算法模型?
2.如何为数据集选择合适的算法?
3.如何定义可用于算法模型的特征变量?
数据探索:总结,可视化,熟悉数据集中重要特征的方法,有助于我们发现数据的一些特征,数据之间的关联性:
{
赛前数据初探:对数据集有整体的认识,发现数据中存在的问题(缺失值,异常值,数据冗余等)
赛中数据探索:分析数据发现变量的特点,帮助提取有价值的特征(从单变量,多变量和变量分布进行分析)
模型的分析:特征重要性分析和结果误差分析(从结果发现问题,进一步优化)
\begin{cases} 赛前数据初探:对数据集有整体的认识,发现数据中存在的问题(缺失值,异常值,数据冗余等)\\ 赛中数据探索:分析数据发现变量的特点,帮助提取有价值的特征(从单变量,多变量和变量分布进行分析)\\模型的分析:特征重要性分析和结果误差分析(从结果发现问题,进一步优化) \end{cases}
⎩
⎨
⎧赛前数据初探:对数据集有整体的认识,发现数据中存在的问题(缺失值,异常值,数据冗余等)赛中数据探索:分析数据发现变量的特点,帮助提取有价值的特征(从单变量,多变量和变量分布进行分析)模型的分析:特征重要性分析和结果误差分析(从结果发现问题,进一步优化)
数据初探
讨论去除噪声或异常值的具体处理办法
目的:加深对数据的理解
数据初探组成
=
{
分析思路
分析方法
明确目的
数据初探组成=\begin{cases} 分析思路\\分析方法\\明确目的 \end{cases}
数据初探组成=⎩
⎨
⎧分析思路分析方法明确目的
分析思路
多种探索思路和方法来探索每个变量并比较结果
分析方法
1.单变量可视化分析:提供原始数据集每个字段的摘要统计信息
2.多变量可视化分析:用来了解不同变量之间的交互关系
3.降维分析:有助于发现数据中特征变量之间方差最大的字段,从而可以在保留最大信息量的同时减少数据维度
可以验证我们在竞赛中的假设,并确定尝试方向,以便理解问题和选择模型,并验证数据是否是按照预期方式生成的,可以检查每个变量的分布,定义一些丢失值,最终找到替换它们的可能方法
明确目的
数据探索的作用:
1.回答问题,测试业务假设,生成进一步分析的假设
通过对数据进行可视化和统计分析,可以发现数据中的模式、趋势和异常情况,从而验证或修正业务假设。数据探索还可以提供初步见解,指导进一步的数据分析和决策制定;在数据探索阶段,可能会发现一些有趣的模式或关联。这些发现可以激发新的问题和假设,从而引导后续的深入分析。
2.使用数据探索来建模数据
数据探索还可以涉及到数据预处理和准备工作,以使数据适合建模。这包括处理缺失值、处理异常值、进行特征工程、标准化或归一化数据等操作。通过数据探索,您可以识别数据质量问题,并采取相应的措施来准备数据以进行建模
数据探索需要明确的事:
1.数据集的情况:数据集有多大,每个字段各是什么类型
2.重复值,缺失值和异常值:去除重复值,缺失值是否严重,缺失值是否有特殊含义,缺失的原因,如和发现异常值
3.特征之间是否冗余:通过特征间的相似性分析来找出冗余特征
4.是否存在时间信息:存在时间信息时,要进行相关性,趋势性,周期性和异常点的分析,以及可能涉及 数据穿越问题。
5.标签分布:分类:是否存在类别不均衡;回归:是否存在异常值,整体分布如何,是否需要进行【目标变换】
6.训练集和测试集的分布:是否有很多在测试集中存在得特征字段而训练集中没有的
7.单变量/多变量分布:熟悉特征的分布情况,以及特征和标签之间的关系
//展示nunique和缺失值的代码
stats=[]
for col in train.columns:
stats.append((col,train[col].nunique,
train[col].isnull().sum()*100/train.shape[0],
train[col].val_counts(normalize=True,
dropna=False).values[0]*100,
train[col].dtype))
stats_df=pd.DataFrame(stats,columns=["Feature","Unique_values",
"Percentage of missing value",
"Percentage of values in the biggest category",
"type"])
stats_df.sort_values("Percentage of missing values",ascending=False)[:10]
// `变量缺失值可视化`。
missing=train.isnull().sum()
missing=missing[missing>0]
missing.sort_values(incline=True)
missing.plot.bar()
变量分析
不单针对每个变量,更多是分析特征之间的联系以及特征和标签的相关性,并进行假设检验,帮助我们提取有用特征
单变量分析
标签
基本信息生成:
train["标签名"].describe()#标签名根据自己题目条件换成相应字符串
变量分布情况可视化:了解数据的分布性质,集中趋势和离散性
直方图展示了数据在不同数值范围内的分布情况,bins【箱子数量】决定了直方图的细粒度
plt.figure(figsize=(9,8))
sns.distplot(train["SalePrice"],color="g",bins=500,hist_kws={"alpha":0.4})
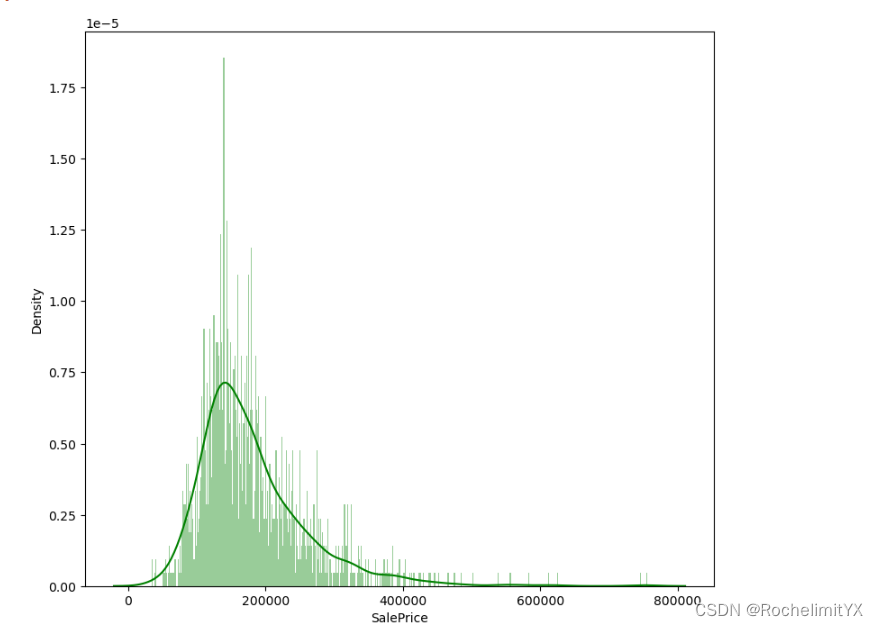
plt.figure(figsize=(9,8))
sns.distplot(np.log(train["SalePrice]),color="b",bins=100,hist_kws={"alpha":0.4})
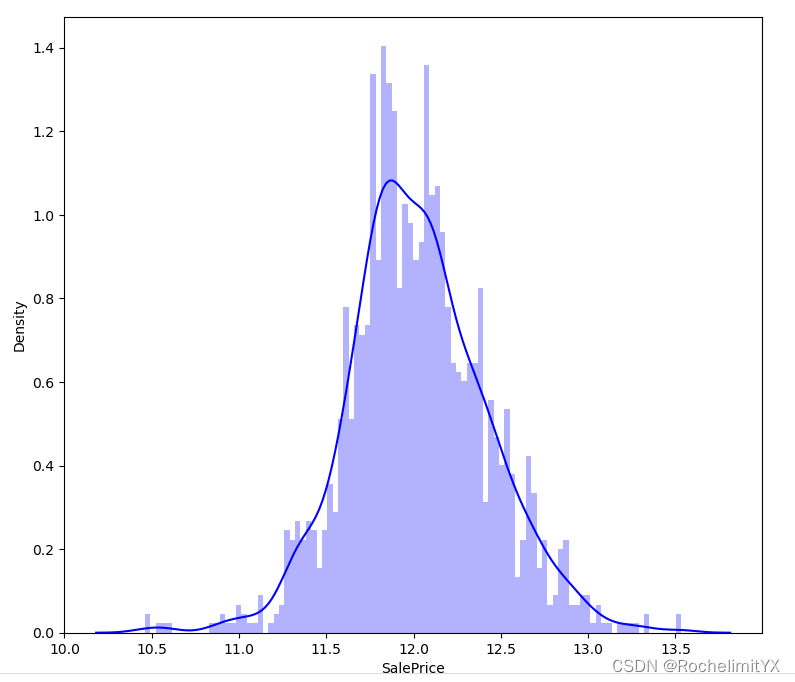
连续型
1.先观察连续型变量的分布:主要使用直方图这种可视化方式观察值的分布,每个值的频率,【一个区间的值视为相同进行统计】
df_num=train.select_dtype(include=["float64,int64])
df_num=df_num[df_num.columns.tolist()[1:5]]
df_num.hist(figsize=(16,200),bins=100,xlabelsize=8,ylabelsize=8)
 2.相关性分析:只能比较数值特征,对于非数值特征【字母或者字符串特征】,先进行编码,并将其转化为数值,然后再看看特征之间有什么关联
2.相关性分析:只能比较数值特征,对于非数值特征【字母或者字符串特征】,先进行编码,并将其转化为数值,然后再看看特征之间有什么关联
实际竞赛中得作用:相关性分析可以很好地过滤掉与标签没有直接关系得特征
#生成有关标签的相似性矩阵图
corrmat=train.corr()
f,ax=plt.subplots(figsize=(20,9))
sns.heatmap(corrmat,vmax=0.8,squre=Ture)
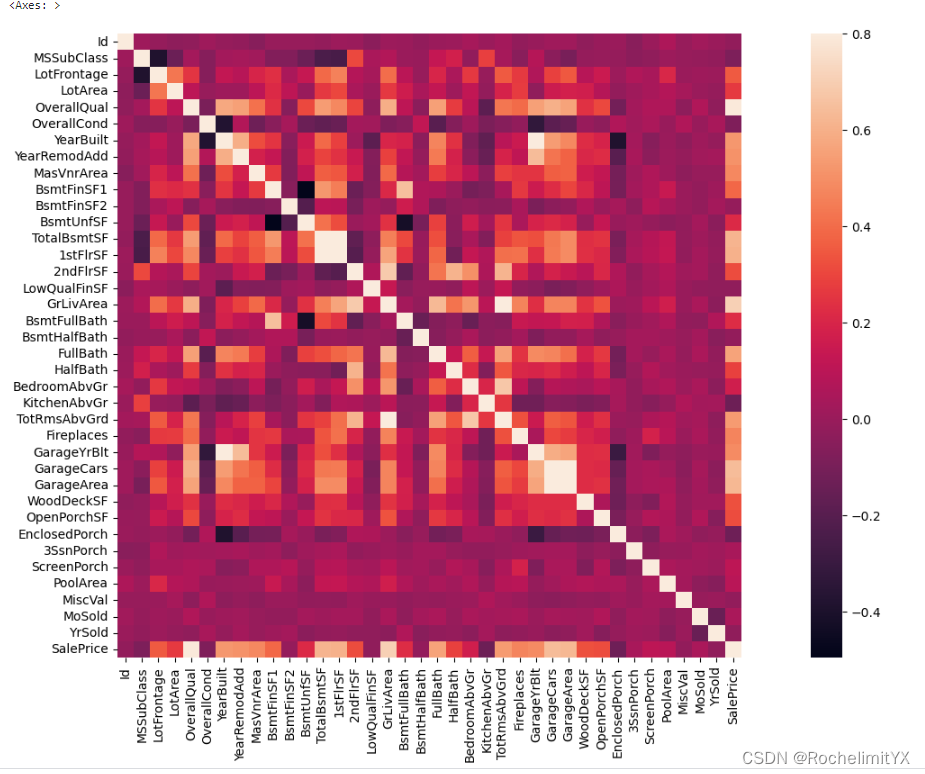 从相似性矩阵中发现标签与特征之间的关系,以及变量之间得关系,那么如何利用相似性矩阵进行分析就成为了关键
从相似性矩阵中发现标签与特征之间的关系,以及变量之间得关系,那么如何利用相似性矩阵进行分析就成为了关键
1.可视化相似性矩阵:首先,您可以绘制相似性矩阵的热力图,以直观地查看特征之间和标签与特征之间的相似性。不同的颜色和模式可以帮助您识别相似性和差异性。您可以使用工具如Seaborn中的heatmap来创建热力图。
2.聚类分析:利用相似性矩阵进行聚类分析,例如层次聚类或K均值聚类,可以帮助您发现数据中的群组结构。这有助于识别具有相似特性的样本或特征。聚类可以用于数据挖掘、市场细分等应用。
3.降维分析:使用降维技术如主成分分析(PCA)或多维尺度分析(MDS),可以将高维数据映射到低维空间,同时保留尽可能多的信息。这有助于可视化数据,减少维度,并发现潜在的数据结构。
4.关联规则挖掘:在处理标签与特征之间的关系时,可以使用关联规则挖掘来发现不同特征之间的关联性。这对于市场分析、交叉销售和协同过滤等任务非常有用。
5.特征选择和特征工程:通过分析相似性矩阵,您可以识别出高度相关的特征或标签。这有助于进行特征选择,删除冗余特征,以及进行特征工程,提取更有信息价值的特征。
6.预测和分类:将相似性矩阵用作输入数据,可以用于预测或分类任务。例如,您可以使用相似性矩阵中的信息来推断未标记数据的标签或进行异常检测。
7.网络分析:如果相似性矩阵表示节点之间的相似性,那么您可以将其用于网络分析。这对于社交网络分析、推荐系统和生物网络分析非常有用。
8.深度学习:深度学习模型(如Siamese网络)可以使用相似性矩阵来进行训练和推理。这在人脸识别、图像匹配和语义搜索等应用中非常有用。
类别型
EDA的目的:了解数据并且构建有效特征
找到与标签有强相关的特征,围绕这个强相关特征进行一系列拓展,进行交叉组合:
强相关+弱相关;强相关+强相关;挖掘出更高维度的潜在信息
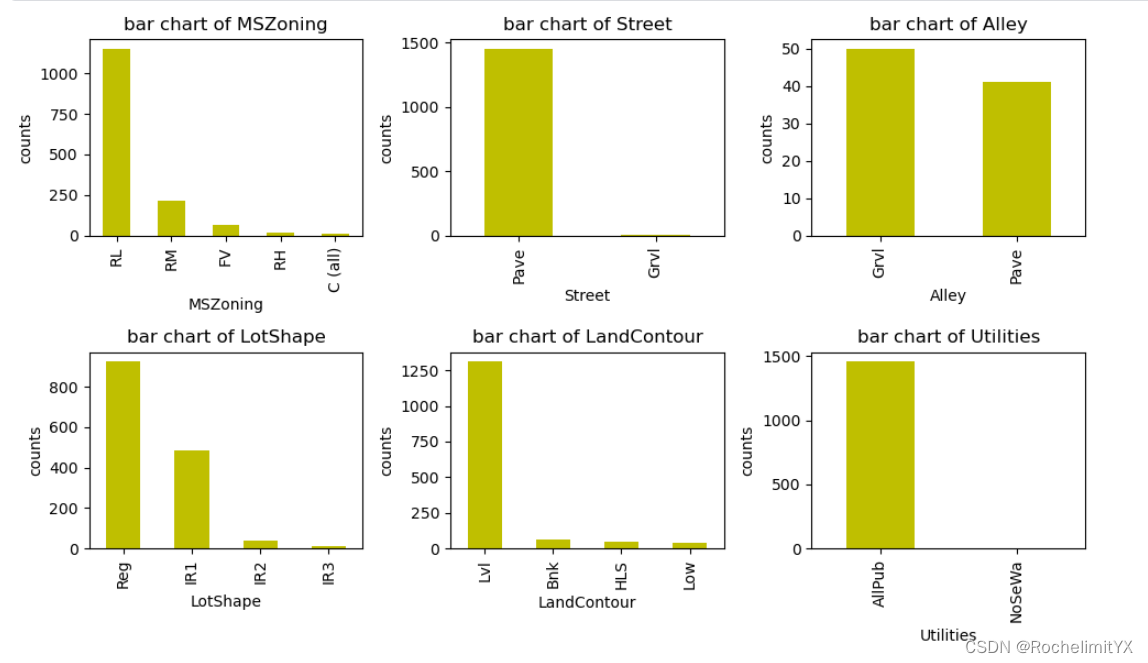
观察类别型变量的基本分布情况:观察每个属性的频次
根据频次:发现热点特征以及极少出现的特征,以及进一步分析出现这种情况的原因【从业务角度/数据采样等角度分析原因】
fig,axes=plt.subplots(nrows=len(df_class.columns)//3,ncols=3,figsize=(10,len(df_class.columns)))#(宽:横向,高:竖着)
for i,column in enumerate(df_class.columns):
r,c=divmod(i,3)#可以根据循环的索引来动态确定每个子图的位置,以实现多行多列的子图排列
ax=axes[r][c]
counts=df_class[column].value_count()
counts.plot(kind="bar",ax=ax,color="y")
ax.set_title(f"bar chart of {column}")
ax.set_xlabel(f"{column}")
ax.set_ylabel("counts")
plt.tight_layout()#它可以自动调整子图、坐标轴和标题之间的间距,使得图像更紧凑,更美观。 它会忽略那些被标记为不可见或已经被删除的子图。 在绘制多个子图时,可以使用该函数来调整布局,以免各子图之间的重叠或空隙过大。
plt.show()
多变量分析
单变量分析太过单一,不足以挖掘变量之间的内在联系,获取更加细粒度的信息;分析特征变量与特征变量之间的关系有助于构建更好的特征,同时降低冗余特征的概率
可视化的方式来展现二者之间的联系:
堆叠条形图的绘制:
其中 x 轴表示 “OverallQual” 值,不同的 “Neighborhood” 组合以不同颜色堆叠在每个 “OverallQual” 值上。这样的可视化有助于比较不同 “Neighborhood” 组合在不同 “OverallQual” 值上的分布情况,给出了不同位置下房屋评价的分布图
plt.style.use("seaborn-v0_9-bright")
type_cluster=train.groupby(["Neighbornhood","OverallQual"]).size()
type_cluster.unstack().plot(kind="bar",stacked=True,colormap="RdBu",grid=True)#stacked=True 表示要堆叠不同的 "Neighborhood" 组合
plt.xlabel("Neighborhood",fontsize=26)
plt.show()
通过 groupby 方法对 “Neighborhood” 和 “OverallQual” 列进行分组,并计算每个组合的频数。这里的代码使用了 groupby 方法,将数据按照 “Neighborhood” 和 “OverallQual” 列的值进行分组,然后使用 .size() 方法计算每个分组的大小,即每个组合的出现次数。结果被存储在 type_cluster 变量中:
 箱线图的绘制:
箱线图的绘制:
plt.figure(figsize=(22,9))
sns.boxplot(x="Neighborhood",y="SalePrice",data=train)
plt.xlabel("Neighborhood",fontsize=16)
plt.ylabel("SalePrice",fontsize=16)
plt.show()
 通过箱形图,可以很容易地比较不同地区的房屋销售价格分布情况,可以看到每个地区的箱体、触须、中位数线以及是否存在异常值(异常值通常以单独的数据点呈现),这有助于分析不同地区的房屋销售价格的中心趋势、离散程度和潜在离群值情况,箱形图是一种有效的可视化工具,用于探索和比较数据的分布。
通过箱形图,可以很容易地比较不同地区的房屋销售价格分布情况,可以看到每个地区的箱体、触须、中位数线以及是否存在异常值(异常值通常以单独的数据点呈现),这有助于分析不同地区的房屋销售价格的中心趋势、离散程度和潜在离群值情况,箱形图是一种有效的可视化工具,用于探索和比较数据的分布。
模型分析
学习曲线
通过学习曲线来观察模型是否过拟合,通过判断拟合程度来确定如何改进模型
欠拟合学习曲线
欠拟合是指模型无法学习到训练数据集中所展现的信息:通过观察训练损失的曲线来确定是否发生欠拟合;若是有着较高损失的平坦曲线,表明模型根本无法学习训练集
过拟合学习曲线
过拟合是指模型对训练集学习得很好,包括统计噪声和训练集中得随机波动都学习到了;泛化误差得增加可以通过模型在验证集上得表现来衡量
可能原因:
模型的容量超出了问题所需的容量,而灵活性又过多
模型训练时间长
正常情况:模型在训练集和验证集上的损失都降到最低点,并且两个损失值之间的差距很小,则拟合程度很好
特征重要性分析
通过模型可以得到特征的重要性:
1.对于树模型:通过计算特征的信息增益或分裂次数得到特征的重要性得分
2.对于LR和SVM:使用特征系数w作为特征重要性得分
误差分析
误差分析是我们通过模型预测结果来发现问题的关键
回归问题:看预测结果的分布
分类问题:看混淆矩阵
面向结果的建模:帮助我们找到模型对于哪些样本或者哪类样本预测能力不够从而导致结果不准确·,然后分析造成结果误差的可能因素,最终修正训练数据和模型
考虑:
1.挖掘更多能够描述误判样本的特征信息帮助增强模型的预测能力
2.样本加权:在模型训练中赋予这些误判样本更高的权重
样本加权的两种方式:(1)对损失大的样本加更大的权重?(2)对损失大的样本加更小的权重?
思考
1.如何绘制混淆矩阵的图像?怎么发现错误高的类别?
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import saeborn as sns
cm=confusion_metrics(y_true,y_pred)
plt.figure(figsize=(10,8))
sns.heatmap(cm,annot=Ture,fmt="d",cmap="Blues",xticklabels=np.unique(y_true),yticklabels=np.unique(y_true))#annot=True 表示在每个单元格中显示数值,fmt="d" 表示数值以整数形式显示,cmap="Blues" 指定颜色图。
plt.xlabel("Predicted")
plt.ylabel("True")
plt.title("Condusion Metrics")
plt.show()
通过观察图像来发现哪些类别的错误较多;通常,对角线上的数字表示模型正确预测的样本数量,非对角线上的数字表示模型错误预测的样本数量。通过分析这些数字,可以识别模型在哪些类别上表现较差,从而有针对性地改进模型或数据处理。















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









