







支撑向量机建模
问题描述
给定训练数据集训练数据集:训练数据集:
D
=
{
x
i
,
y
i
}
i=1...n
;
y
i
∈
{
−
1
,
1
}
(
{
0
,
1
}
)
D=\overset{\text{}}{% \left\{x_i,y_i \right\}% }% \underset{\text{i=1...n}}{};y_i\in \{-1,1\}(\{0,1\})%
D={xi,yi}i=1...n;yi∈{−1,1}({0,1})
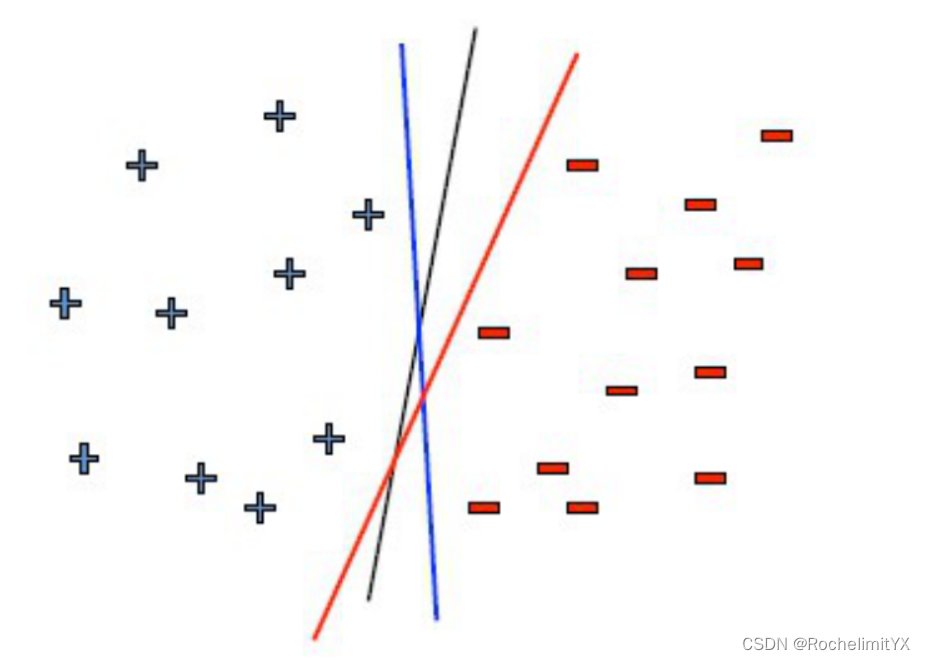 分类器学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面将不同类别的样本分开,但是,如上图所示,能够将训练样本分开的划分超平面可能有很多,哪个分类器更好呢?
分类器学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面将不同类别的样本分开,但是,如上图所示,能够将训练样本分开的划分超平面可能有很多,哪个分类器更好呢?
朴素自然的,直观上我们会选择位于两类训练样本正中间的划分你超平面,也就是具有最大分隔区间的,这样可以保证分类精度相同时,推广能力更佳,潜在认为当我有一个新的数据时分类器也能把它分好,即使数据有一定的噪声,这根线分的也是最稳定的;总的来说,就是我们要找能完美把数据分开,且往两边拉开间隔最大的超平面,以保证对未来数据泛化能力最强
Large Margin
学习机:
f
w
(
x
)
=
w
T
x
+
b
f_w(x)=w^Tx+b
fw(x)=wTx+b
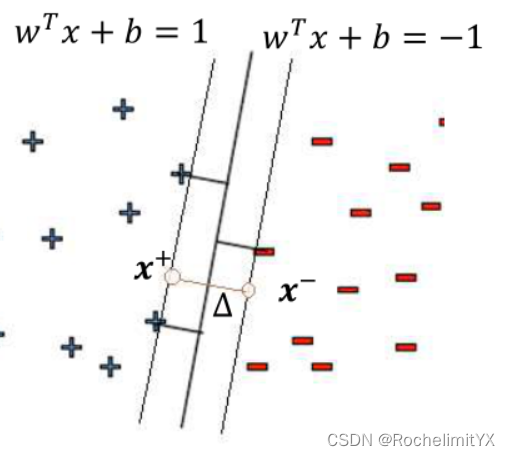
假设间隔最大的那个分类面往两边拉开得到的直线是
w
T
x
+
b
=
1
w^Tx+b=1
wTx+b=1和
w
T
+
b
=
−
1
w^T+b=-1
wT+b=−1;也可以设为
w
T
x
+
b
=
c
w^Tx+b=c
wTx+b=c和
w
T
+
b
=
−
c
w^T+b=-c
wT+b=−c,两边同时除以c,把制度变换放在w和b中,反正这两是变量;接下来,我们就开始找寻符合两个要求的超平面
首先,如何刻画每个样本都分对了?
对于每一个
x
i
x_i
xi,
y
i
y_i
yi都分对了,则有
f
w
(
x
i
)
y
i
≥
0
f_w(x_i)y_i\geq0
fw(xi)yi≥0,这是我们在感知机模型里提到的线性可分假设;那么在上述的假设下,对于每个样本,分对了,有:
(
w
T
x
i
+
b
)
y
i
≥
1
(w^Tx_i+b)y_i \geq 1
(wTxi+b)yi≥1
因为
{
当该样本是正类时
y
i
=
1
w
T
x
+
b
≥
1
当该样本是负类时
y
i
=
−
1
w
T
x
+
b
≥
−
1
\begin{cases} \text{当该样本是正类时}\thinspace y_i=1 & w^Tx+b\geq1\\ \text{当该样本是负类时}\thinspace y_i=-1 & w^Tx+b\geq-1 \end{cases}
{当该样本是正类时yi=1当该样本是负类时yi=−1wTx+b≥1wTx+b≥−1,将二者相乘,无论正负样本都有
(
w
T
x
i
+
b
)
y
i
≥
1
(w^Tx_i+b)y_i \geq 1
(wTxi+b)yi≥1;
第二,如何表示Margin?
如图所示,我们假设
x
+
x^+
x+位于直线
w
T
x
+
b
=
1
w^Tx+b=1
wTx+b=1上,
x
−
x^-
x−位于直线
w
T
x
+
b
=
−
1
w^Tx+b=-1
wTx+b=−1上,这是肯定的,如果正样本还在这条线的左边或者负样本还在这条线的右边,我们将
w
T
x
+
b
=
1
w^Tx+b=1
wTx+b=1往左边拉,或者将
w
T
x
+
b
=
−
1
w^Tx+b=-1
wTx+b=−1往右边拉,直到碰到相应的边界点为止,其实这两个点就是我们所说的支撑向量的一种,支撑向量机有了这些支撑向量的样本,其它的样本有没有都无所谓了
△
=
∣
∣
x
+
−
x
−
∣
∣
=
?
\triangle=||x^+-x^-||=?
△=∣∣x+−x−∣∣=?
等式右边
w
T
x
+
b
−
(
w
T
x
−
+
b
)
=
w
T
(
x
+
−
x
−
)
=
1
−
(
−
1
)
=
2
w^Tx+b-(w^Tx^-+b)=w^T(x^+-x^-)=1-(-1)=2
wTx+b−(wTx−+b)=wT(x+−x−)=1−(−1)=2
x
+
x^+
x+位于直线
w
T
x
+
b
=
1
w^Tx+b=1
wTx+b=1上,
x
−
x^-
x−位于直线
w
T
x
+
b
=
−
1
w^Tx+b=-1
wTx+b=−1上
又有
w
T
w^T
wT代表了
w
x
+
b
=
c
w^x+b=c
wx+b=c的垂线,显然是和直线
x
+
−
x
−
x^+-x^-
x+−x−平行的,所以有
∣
∣
w
T
(
x
+
−
x
−
)
∣
∣
=
∣
∣
w
T
∣
∣
.
∣
∣
(
x
+
−
x
−
)
∣
∣
c
o
s
0
=
∣
∣
w
T
∣
∣
.
∣
∣
(
x
+
−
x
−
)
∣
∣
=
2
||w^T(x^+-x^-)||=||w^T||.||(x^+-x^-)||cos0=||w^T||.||(x^+-x^-)||=2
∣∣wT(x+−x−)∣∣=∣∣wT∣∣.∣∣(x+−x−)∣∣cos0=∣∣wT∣∣.∣∣(x+−x−)∣∣=2
△
=
∣
∣
x
+
−
x
−
∣
∣
=
2
∣
∣
w
T
∣
∣
2
=
2
∣
∣
w
∣
∣
2
\triangle=||x^+-x^-||=\frac{2}{||w^T||_2}=\frac{2}{||w||_2}
△=∣∣x+−x−∣∣=∣∣wT∣∣22=∣∣w∣∣22
接下来我们就是要在样本分类准确的前提下最大化Margin
我们试图把样本在严格分类准确的前提下最大化Margin;Margin内在含义:分类面能把间隔拉开
即$
max
2
∣
∣
w
∣
∣
\max \frac{2}{||w||}
max∣∣w∣∣2
为了好算,等价于
min
w
,
b
1
2
w
T
w
\min_{w,b}\frac{1}{2}w^Tw
w,bmin21wTw
s
.
t
.
(
w
T
x
j
+
b
)
y
j
≥
1
,
f
o
r
a
l
l
j
=
1...
n
s.t.(w^Tx_j+b)y_j\geq 1 ,for\,all \,j=1...n
s.t.(wTxj+b)yj≥1,forallj=1...n
现在问题就转化为了上述的QP问题<–显然目标函数对于w而言是凸函数,约束对w和b是线性的
当数据非线性可分怎么玩
以上SVM算法是基于线性可分假设的,当有一些错落的电视整个算法将崩溃,因为正类里面混有负类,负类里面混有正类,导致可行域是空集,故而我们找不到一个线性分类面把所有的数据分开
 对于有些样本分不开的情况,如何让它继续可行?
对于有些样本分不开的情况,如何让它继续可行?
加入松弛,允许分类误差;
则上述问题可描述为
min
w
,
b
,
ξ
j
1
2
w
T
w
+
C
∑
j
ξ
j
\min_{w,b,\xi_j}\frac{1}{2}w^Tw+C\sum_j\xi_j
w,b,ξjmin21wTw+Cj∑ξj
s
.
t
.
(
w
T
x
j
+
b
)
y
j
≥
1
−
ξ
j
,
f
o
r
a
l
l
j
=
1...
n
s.t.(w^Tx_j+b)y_j\geq 1-\xi_j,for\,all \,j=1...n
s.t.(wTxj+b)yj≥1−ξj,forallj=1...n
ξ
j
≥
0
,
f
o
r
a
l
l
j
=
1...
n
\xi_j\geq 0,for\,all \,j=1...n
ξj≥0,forallj=1...n
其中
ξ
j
\xi_j
ξj为松弛变量,C为惩罚因子,可见,如此描述的问题仍为QP问题,因为对于增加的
ξ
j
\xi_j
ξj,增加的是
ξ
j
\xi_j
ξj线性的目标函数,线性的约束,仍然可以保证全局极优,同时要注意,尽管我们允许了松弛,但是也要让我的松弛尽可能的小;在我们的可行域中,为了让分不开的数据尽量影响小,否则的话,
ξ
j
\xi_j
ξj都会走向正无穷,显然失去了意义
优化策略–对偶优化
对于上述两个QP问题,我们如何求解呢?
当然我们可以直接调用现成的QP工具包求解,但是采用对偶优化,能让我们清晰地看到SVM深刻地机器学习方法的内涵
(1)
min
w
,
b
1
2
w
T
w
\min_{w,b}\frac{1}{2}w^Tw
w,bmin21wTw
s
.
t
.
(
w
T
x
j
+
b
)
y
j
≥
1
,
f
o
r
a
l
l
j
=
1...
n
s.t.(w^Tx_j+b)y_j\geq 1 ,for\,all \,j=1...n
s.t.(wTxj+b)yj≥1,forallj=1...n
(2)
min
w
,
b
,
ξ
j
1
2
w
T
w
+
C
∑
j
ξ
j
\min_{w,b,\xi_j}\frac{1}{2}w^Tw+C\sum_j\xi_j
w,b,ξjmin21wTw+Cj∑ξj
s
.
t
.
(
w
T
x
j
+
b
)
y
j
≥
1
−
ξ
j
,
f
o
r
a
l
l
j
=
1...
n
s.t.(w^Tx_j+b)y_j\geq 1-\xi_j,for\,all \,j=1...n
s.t.(wTxj+b)yj≥1−ξj,forallj=1...n
ξ
j
≥
0
,
f
o
r
a
l
l
j
=
1...
n
\xi_j\geq 0,for\,all \,j=1...n
ξj≥0,forallj=1...n
对偶问题
min
x
f
(
x
)
\min_{x}f(x)
xminf(x)
s
.
t
.
g
(
x
)
≤
0
s.t.\,g(x)\leq0
s.t.g(x)≤0
h
(
x
)
=
0
h(x)=0
h(x)=0
等价于求解以下两层优化(解释见后述):
min
x
max
α
≥
0
,
β
L
(
x
,
α
,
β
)
\min_{x}\max_{\alpha\geq0,\beta}L(x,\alpha,\beta)
xminα≥0,βmaxL(x,α,β)
L
(
x
,
α
,
β
)
L(x,\alpha,\beta)
L(x,α,β)为拉格朗日函数:
L
(
x
,
α
,
β
)
=
f
(
x
)
+
α
g
(
x
)
+
β
h
(
x
)
,
其中
α
≥
0
(不等式乘子有约束)
,
β
(等式乘子无约束)
:
为拉格朗日乘子
L(x,\alpha,\beta)=f(x)+\alpha g(x)+\beta h(x),其中\alpha\geq 0( 不等式乘子有约束),\beta(等式乘子无约束):为拉格朗日乘子
L(x,α,β)=f(x)+αg(x)+βh(x),其中α≥0(不等式乘子有约束),β(等式乘子无约束):为拉格朗日乘子
推论:
max
α
≥
0
,
β
L
(
x
,
α
,
β
)
=
{
f
(
x
)
,
if
x
在可行域时
+
∞
,
if
o
t
h
e
r
w
i
s
e
:
h
(
x
)
≠
0
o
r
g
(
x
)
>
0
的时候
\max_{\alpha\geq0,\beta} L(x,\alpha,\beta)=\begin{cases} f(x), & \text{if } x 在可行域时 \\ +\infty, & \text{if } otherwise:h(x)\neq0 \,or\,g(x)>0的时候 \end{cases}
α≥0,βmaxL(x,α,β)={f(x),+∞,if x在可行域时if otherwise:h(x)=0org(x)>0的时候
为什么这个约束问题会等价于求解两层优化的无约束问题呢?
对于拉格朗日函数
L
(
x
,
α
,
β
)
=
f
(
x
)
+
α
g
(
x
)
+
β
h
(
x
)
L(x,\alpha,\beta)=f(x)+\alpha g(x)+\beta h(x)
L(x,α,β)=f(x)+αg(x)+βh(x),其中的等式约束来说,因为乘子
β
\beta
β,其正负没有约束,无论取得x是使得
h
(
x
)
h(x)
h(x)大于0还是小于0;
β
\beta
β都可以取对应的正无穷或者负无穷使得内层的max
β
h
(
x
)
\beta h(x)
βh(x)正无穷大,那么外层的min根本就不起作用了,所有必须有
β
h
(
x
)
=
0
\beta h(x)=0
βh(x)=0,同时,若g(x)大于0,其乘子
α
\alpha
α大于等于0;也可以选
α
\alpha
α正无穷大使得内层max正无穷大,这样外层的min也不起作用了,肯定不是原问题的解
强对偶:
充分条件,当原问题是凸的时候,它一定是满足强对偶的,一定可以取到等号
d
∗
=
max
α
≥
0
,
β
min
x
L
(
x
,
α
,
β
)
=
min
x
max
α
≥
0
,
β
L
(
x
,
α
,
β
)
=
p
∗
d^*=\max_{\alpha\geq0,\beta}\min_{x}L(x,\alpha,\beta)=\min_{x}\max_{\alpha\geq0,\beta}L(x,\alpha,\beta)=p^*
d∗=α≥0,βmaxxminL(x,α,β)=xminα≥0,βmaxL(x,α,β)=p∗
成立条件 — KKT条件
∇
x
L
(
x
∗
,
α
∗
,
β
∗
)
=
0
\nabla_x L(x^*,\alpha^*,\beta^*)=0
∇xL(x∗,α∗,β∗)=0
α
∗
≥
0
\alpha^* \geq0
α∗≥0
g
(
x
∗
)
≤
0
g(x^*)\leq0
g(x∗)≤0
h
(
x
∗
)
=
0
h(x^*)=0
h(x∗)=0
上述四个条件分别表示拉格朗日函数对x的梯度为0;
α
∗
≥
0
\alpha^* \geq0
α∗≥0是乘子约束要求显然是要满足的,剩下两个为解在可行域里的要求,这也是朴素自然的
所以最重要的是下面这个条件,
α
∗
g
(
x
∗
)
=
0
\alpha^*g(x^*)=0
α∗g(x∗)=0
它表示了
{
α
∗
>
0
==>
g
(
x
∗
)
=
0
约束被激活
g
(
x
∗
)
<
0
==>
α
∗
=
0
约束未被激活
\begin{cases} \alpha^* >0 & \text{==> }g(x^*)=0 约束被激活\\ g(x^*)<0 & \text{==> } \alpha^*=0 约束未被激活 \end{cases}
{α∗>0g(x∗)<0==> g(x∗)=0约束被激活==> α∗=0约束未被激活
SVM原问题与对偶问题求解
SVM模型凸优化的KKT条件成立,凸优化问题与原问题等价
原问题:
min
w
,
b
1
2
w
T
w
\min_{w,b}\frac{1}{2}w^Tw
w,bmin21wTw
s
.
t
.
(
w
T
x
j
+
b
)
y
j
≥
1
,
f
o
r
a
l
l
j
=
1...
n
s.t.(w^Tx_j+b)y_j\geq 1 ,for\,all \,j=1...n
s.t.(wTxj+b)yj≥1,forallj=1...n
拉格朗日函数:
L
(
w
,
b
,
α
)
=
1
2
w
T
w
−
∑
j
α
j
[
(
w
T
x
j
+
b
)
y
j
−
1
]
L(w,b,\alpha)=\frac{1}{2}w^Tw-\sum_j\alpha_j[(w^Tx_j+b)y_j-1]
L(w,b,α)=21wTw−j∑αj[(wTxj+b)yj−1]
α
≥
0
,
∀
j
\alpha \geq0,\forall j
α≥0,∀j
拉格朗日对偶函数:是拉格朗日函数关于x取得的最小值
L
(
α
)
=
inf
w
,
b
∈
D
L
(
w
,
b
,
α
)
=
1
2
w
T
w
−
∑
j
α
j
[
(
w
T
x
j
+
b
)
y
j
−
1
]
L(\alpha)=\text{inf}_{w,b\in D }L(w,b,\alpha)=\frac{1}{2}w^Tw-\sum_j\alpha_j[(w^Tx_j+b)y_j-1]
L(α)=infw,b∈DL(w,b,α)=21wTw−j∑αj[(wTxj+b)yj−1]
α
≥
0
,
∀
j
\alpha \geq0,\forall j
α≥0,∀j
即如果拉格朗日函数关于w,b无下界,则对偶函数取值为负无穷,对偶函数构成了原问题最优值p*的下界,即对于任意的
α
≥
0
\alpha\geq0
α≥0都有
L
(
α
)
≤
p
∗
L(\alpha)\leq p^*
L(α)≤p∗
拉格朗日函数讨论
min
x
max
α
≥
0
,
β
L
(
x
,
α
,
β
)
\min_{x}\max_{\alpha\geq0,\beta}L(x,\alpha,\beta)
xminα≥0,βmaxL(x,α,β)为广义拉格朗日函数的极小极大问题:即线max拉格朗日乘子之后再min x;化为对偶问题,拉格朗日极大极小问题,想将两步优化的顺序倒过来,先min x,再max拉格朗日乘子,那么目标函数值是变大了还是变小了呢?
我们说是变小了,有弱对偶保证其成立
d
∗
=
max
α
≥
0
,
β
min
x
L
(
x
,
α
,
β
)
≤
min
x
max
α
≥
0
,
β
L
(
x
,
α
,
β
)
=
p
∗
d^*=\max_{\alpha\geq0,\beta}\min_{x}L(x,\alpha,\beta)\ \leq \min_{x}\max_{\alpha\geq0,\beta}L(x,\alpha,\beta)=p^*
d∗=α≥0,βmaxxminL(x,α,β) ≤xminα≥0,βmaxL(x,α,β)=p∗
证明如下:
记
g
(
x
)
=
min
y
f
(
x
,
y
)
,显然它
≤
f
(
x
,
y
)
记g(x)=\min_{y}f(x,y) ,显然它\leq f(x,y)
记g(x)=yminf(x,y),显然它≤f(x,y)
故有
g
(
x
)
≤
f
(
x
,
y
)
∀
y
故有g(x)\leq f(x,y)\,\, \forall\, y
故有g(x)≤f(x,y)∀y
max
x
g
(
x
)
≤
max
x
f
(
x
,
y
)
,
∀
y
,
因为对所有的
y
都小于等于,故而:
\max_{x}g(x)\leq \max_{x}f(x,y),\forall\,\,y,因为对所有的y都小于等于,故而:
xmaxg(x)≤xmaxf(x,y),∀y,因为对所有的y都小于等于,故而:
max
x
g
(
x
)
≤
min
y
max
x
f
(
x
,
y
)
\max_{x}g(x)\leq \min_{y}\max_{x}f(x,y)
xmaxg(x)≤yminxmaxf(x,y)
将记的g(x)代会可得:
max
x
min
y
f
(
x
,
y
)
≤
min
y
max
x
f
(
x
,
y
)
\max_{x}\min_{y}f(x,y)\leq \min_{y}\max_{x}f(x,y)
xmaxyminf(x,y)≤yminxmaxf(x,y)
所有弱对偶条件必然成立:
d
∗
=
max
α
≥
0
,
β
min
x
L
(
x
,
α
,
β
)
≤
min
x
max
α
≥
0
,
β
L
(
x
,
α
,
β
)
=
p
∗
d^*=\max_{\alpha\geq0,\beta}\min_{x}L(x,\alpha,\beta)\ \leq \min_{x}\max_{\alpha\geq0,\beta}L(x,\alpha,\beta)=p^*
d∗=α≥0,βmaxxminL(x,α,β) ≤xminα≥0,βmaxL(x,α,β)=p∗
对偶求解
线性可分条件下
原问题:
min
w
,
b
max
α
≥
0
L
(
w
,
b
,
α
)
=
1
2
w
T
w
−
∑
j
α
j
[
(
w
T
x
j
+
b
)
y
j
−
1
]
\min_{w,b}\max_{\alpha\geq0}L(w,b,\alpha)=\frac{1}{2}w^Tw-\sum_j\alpha_j[(w^Tx_j+b)y_j-1]
w,bminα≥0maxL(w,b,α)=21wTw−j∑αj[(wTxj+b)yj−1]
α
≥
0
,
∀
j
\alpha \geq0,\forall j
α≥0,∀j
对偶问题:
max
α
≥
0
min
w
,
b
L
(
w
,
b
,
α
)
=
1
2
w
T
w
−
∑
j
α
j
[
(
w
T
x
j
+
b
)
y
j
−
1
]
\max_{\alpha\geq0}\min_{w,b}L(w,b,\alpha)=\frac{1}{2}w^Tw-\sum_j\alpha_j[(w^Tx_j+b)y_j-1]
α≥0maxw,bminL(w,b,α)=21wTw−j∑αj[(wTxj+b)yj−1]
α
j
≥
0
,
∀
j
\alpha_j\geq0,\forall j
αj≥0,∀j
先对对偶问题的内层进行优化:
∂
L
(
w
,
b
,
α
)
∂
w
=
w
−
∑
j
α
j
x
j
y
j
=
0
→
w
=
∑
j
α
j
x
j
y
j
\frac{\partial{L(w,b,\alpha)}}{\partial{w}}=w-\sum_{j}\alpha_jx_jy_j=0 \rightarrow w=\sum_{j}\alpha_jx_jy_j
∂w∂L(w,b,α)=w−j∑αjxjyj=0→w=j∑αjxjyj
∂
L
(
w
,
b
,
α
)
∂
b
=
−
∑
j
α
j
y
j
=
0
→
∑
j
α
j
y
j
=
0
\frac{\partial L(w,b,\alpha)}{\partial b}=-\sum_j\alpha_jy_j=0 \rightarrow \sum_{j}\alpha_jy_j=0
∂b∂L(w,b,α)=−j∑αjyj=0→j∑αjyj=0
将内层优化的驻点代入对偶问题:
max
α
≥
0
L
(
α
)
=
1
2
(
∑
i
α
i
x
i
y
i
)
T
(
∑
j
α
j
x
j
y
j
)
−
∑
j
α
j
[
(
(
∑
i
α
i
x
i
y
i
)
T
x
j
+
b
)
y
j
−
1
]
\max_{\alpha\geq0}L(\alpha)=\frac{1}{2}(\sum_i\alpha_ix_iy_i)^T(\sum_j\alpha_jx_jy_j)-\sum_j\alpha_j[((\sum_i\alpha_ix_iy_i)^Tx_j+b)y_j-1]
α≥0maxL(α)=21(i∑αixiyi)T(j∑αjxjyj)−j∑αj[((i∑αixiyi)Txj+b)yj−1]
=
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
−
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
−
∑
j
α
j
y
j
b
+
∑
j
α
j
=\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_jx_i^Tx_j-\sum_i\sum_j\alpha_iy_i\alpha_jy_jx_i^Tx_j-\sum_j\alpha_jy_jb+\sum_j\alpha_j
=21i∑j∑αiyiαjyjxiTxj−i∑j∑αiyiαjyjxiTxj−j∑αjyjb+j∑αj
此处
∑
j
α
j
y
j
b
=
0
\sum_{j}\alpha_jy_jb=0
∑jαjyjb=0
max
α
≥
0
L
(
α
)
=
−
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
+
∑
j
α
j
\max_{\alpha\geq0}L(\alpha)=-\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_jx_i^Tx_j+\sum_j\alpha_j
α≥0maxL(α)=−21i∑j∑αiyiαjyjxiTxj+j∑αj
亦即:
min
α
≥
0
L
(
α
)
=
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
−
∑
j
α
j
\min_{\alpha\geq0}L(\alpha)=\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_jx_i^Tx_j-\sum_j\alpha_j
α≥0minL(α)=21i∑j∑αiyiαjyjxiTxj−j∑αj
s
.
t
.
∑
j
α
j
y
j
=
0
,
α
j
≥
0
s.t. \sum_j\alpha_jy_j=0,\alpha_j\geq0
s.t.j∑αjyj=0,αj≥0
线性可分情况下对偶问题:
max
α
≥
0
L
(
α
)
=
−
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
+
∑
j
α
j
\max_{\alpha\geq0}L(\alpha)=-\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_j\textbf{x}_i^T\textbf{x}_j+\sum_j\alpha_j
α≥0maxL(α)=−21i∑j∑αiyiαjyjxiTxj+j∑αj
s
.
t
.
∑
j
α
j
y
j
=
0
,
α
j
≥
0
s.t. \sum_j\alpha_jy_j=0,\alpha_j\geq0
s.t.j∑αjyj=0,αj≥0
对于
α
\alpha
α而言也是QP问题,可直接调程序包求解
那么如何求w和b呢?【这个问题等到描述完线性不可分情况再里阐述】
线性不可分条件下
min
w
,
b
,
ξ
j
1
2
w
T
w
+
C
∑
j
ξ
j
\min_{w,b,\xi_j}\frac{1}{2}w^Tw+C\sum_j\xi_j
w,b,ξjmin21wTw+Cj∑ξj
s
.
t
.
(
w
T
x
j
+
b
)
y
j
≥
1
−
ξ
j
,
f
o
r
a
l
l
j
=
1...
n
s.t.(w^Tx_j+b)y_j\geq 1-\xi_j,for\,all \,j=1...n
s.t.(wTxj+b)yj≥1−ξj,forallj=1...n
ξ
j
≥
0
,
f
o
r
a
l
l
j
=
1...
n
\xi_j\geq 0,for\,all \,j=1...n
ξj≥0,forallj=1...n
原问题:
min
w
,
b
,
ξ
max
α
j
,
γ
j
≥
0
L
(
w
,
b
,
,
ξ
,
α
,
γ
)
=
1
2
w
T
w
+
C
∑
j
ξ
j
−
∑
j
α
j
[
(
w
T
x
j
+
b
)
y
j
+
ξ
j
−
1
]
−
∑
j
γ
j
ξ
j
\min_{w,b,\xi}\max_{\alpha_j,\gamma_j\geq0}L(w,b,,\xi,\alpha,\gamma)=\frac{1}{2}w^Tw+C\sum_j\xi_j-\sum_j\alpha_j[(w^Tx_j+b)y_j+\xi_j-1]-\sum_j\gamma_j\xi_j
w,b,ξminαj,γj≥0maxL(w,b,,ξ,α,γ)=21wTw+Cj∑ξj−j∑αj[(wTxj+b)yj+ξj−1]−j∑γjξj
α
j
,
γ
j
≥
0
,
∀
j
\alpha_j,\gamma_j\geq0,\forall j
αj,γj≥0,∀j
对偶问题:
max
α
j
,
γ
j
≥
0
min
w
,
b
,
ξ
L
(
w
,
b
,
,
ξ
,
α
,
γ
)
=
1
2
w
T
w
+
C
∑
j
ξ
j
−
∑
j
α
j
[
(
w
T
x
j
+
b
)
y
j
+
ξ
j
−
1
]
−
∑
j
γ
j
ξ
j
\max_{\alpha_j,\gamma_j\geq0}\min_{w,b,\xi}L(w,b,,\xi,\alpha,\gamma)=\frac{1}{2}w^Tw+C\sum_j\xi_j-\sum_j\alpha_j[(w^Tx_j+b)y_j+\xi_j-1]-\sum_j\gamma_j\xi_j
αj,γj≥0maxw,b,ξminL(w,b,,ξ,α,γ)=21wTw+Cj∑ξj−j∑αj[(wTxj+b)yj+ξj−1]−j∑γjξj
α
j
,
γ
j
≥
0
,
∀
j
\alpha_j,\gamma_j\geq0,\forall j
αj,γj≥0,∀j
先对对偶问题的内层进行优化:
∂
L
(
w
,
b
,
,
ξ
,
α
,
γ
)
∂
w
=
w
−
∑
j
α
j
x
j
y
j
=
0
→
w
=
∑
j
α
j
x
j
y
j
\frac{\partial{L(w,b,,\xi,\alpha,\gamma)}}{\partial{w}}=w-\sum_{j}\alpha_jx_jy_j=0 \rightarrow w=\sum_{j}\alpha_jx_jy_j
∂w∂L(w,b,,ξ,α,γ)=w−j∑αjxjyj=0→w=j∑αjxjyj
∂
L
(
w
,
b
,
,
ξ
,
α
,
γ
)
∂
b
=
−
∑
j
α
j
y
j
=
0
→
∑
j
α
j
y
j
=
0
\frac{\partial L(w,b,,\xi,\alpha,\gamma)}{\partial b}=-\sum_j\alpha_jy_j=0 \rightarrow \sum_{j}\alpha_jy_j=0
∂b∂L(w,b,,ξ,α,γ)=−j∑αjyj=0→j∑αjyj=0
∂
L
(
w
,
b
,
,
ξ
,
α
,
γ
)
∂
ξ
j
=
C
−
α
j
−
γ
j
=
0
→
C
=
α
j
+
γ
j
\frac{\partial L(w,b,,\xi,\alpha,\gamma)}{\partial \xi_j}=C-\alpha_j-\gamma_j=0 \rightarrow C=\alpha_j+\gamma_j
∂ξj∂L(w,b,,ξ,α,γ)=C−αj−γj=0→C=αj+γj
将内层优化的驻点代入对偶问题:
max
α
,
γ
≥
0
L
(
α
,
γ
)
=
1
2
(
∑
i
α
i
x
i
y
i
)
T
(
∑
j
α
j
x
j
y
j
)
+
C
∑
j
ξ
j
−
∑
j
α
j
[
(
(
∑
i
α
i
x
i
y
i
)
T
x
j
+
b
)
y
j
+
ξ
j
−
1
]
−
∑
j
γ
j
ξ
j
\max_{\alpha,\gamma\geq0}L(\alpha,\gamma)=\frac{1}{2}(\sum_i\alpha_ix_iy_i)^T(\sum_j\alpha_jx_jy_j)+C\sum_j\xi_j-\sum_j\alpha_j[((\sum_i\alpha_ix_iy_i)^Tx_j+b)y_j+\xi_j-1]-\sum_j\gamma_j\xi_j
α,γ≥0maxL(α,γ)=21(i∑αixiyi)T(j∑αjxjyj)+Cj∑ξj−j∑αj[((i∑αixiyi)Txj+b)yj+ξj−1]−j∑γjξj
=
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
−
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
−
∑
j
α
j
y
j
b
+
∑
j
α
j
+
C
∑
j
ξ
j
−
∑
j
α
j
ξ
j
−
∑
j
γ
j
ξ
j
=\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_jx_i^Tx_j-\sum_i\sum_j\alpha_iy_i\alpha_jy_jx_i^Tx_j-\sum_j\alpha_jy_jb+\sum_j\alpha_j+C\sum_j\xi_j-\sum_j\alpha_j\xi_j-\sum_j\gamma_j\xi_j
=21i∑j∑αiyiαjyjxiTxj−i∑j∑αiyiαjyjxiTxj−j∑αjyjb+j∑αj+Cj∑ξj−j∑αjξj−j∑γjξj
【此处
∑
j
α
j
y
j
b
=
0
,
C
−
α
j
−
γ
j
=
0
\sum_{j}\alpha_jy_jb=0,C-\alpha_j-\gamma_j=0
∑jαjyjb=0,C−αj−γj=0
C
∑
j
ξ
j
−
∑
j
α
j
ξ
j
−
∑
j
γ
j
ξ
j
C\sum_j\xi_j-\sum_j\alpha_j\xi_j-\sum_j\gamma_j\xi_j
C∑jξj−∑jαjξj−∑jγjξj
C
∑
j
ξ
j
−
∑
j
(
α
j
+
γ
j
)
ξ
j
=
∑
j
(
C
−
α
j
+
γ
j
)
ξ
j
=
0
C\sum_j\xi_j-\sum_j(\alpha_j+\gamma_j)\xi_j=\sum_j(C-\alpha_j+\gamma_j)\xi_j=0
C∑jξj−∑j(αj+γj)ξj=∑j(C−αj+γj)ξj=0】
亦即
min
α
,
γ
L
(
α
,
γ
)
=
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
−
∑
j
α
j
\min_{\alpha,\gamma}L(\alpha,\gamma)=\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_jx_i^Tx_j-\sum_j\alpha_j
α,γminL(α,γ)=21i∑j∑αiyiαjyjxiTxj−j∑αj
s
.
t
.
∑
j
α
j
y
j
=
0
,
α
j
≥
0
s.t. \sum_j\alpha_jy_j=0,\alpha_j\geq0
s.t.j∑αjyj=0,αj≥0
s
.
t
.
∑
j
α
j
y
j
=
0
,
α
j
,
γ
j
≥
0
,
C
−
α
j
−
γ
j
=
0
s.t. \sum_j\alpha_jy_j=0,\alpha_j,\gamma_j\geq0,C-\alpha_j-\gamma_j=0
s.t.j∑αjyj=0,αj,γj≥0,C−αj−γj=0
等价于:
min
α
,
γ
L
(
α
,
γ
)
=
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
−
∑
j
α
j
\min_{\alpha,\gamma}L(\alpha,\gamma)=\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_jx_i^Tx_j-\sum_j\alpha_j
α,γminL(α,γ)=21i∑j∑αiyiαjyjxiTxj−j∑αj
s
.
t
.
∑
j
α
j
y
j
=
0
,
C
≥
α
j
≥
0
s.t. \sum_j\alpha_jy_j=0,C\geq\ \alpha_j\geq0
s.t.j∑αjyj=0,C≥ αj≥0
显然,上述问题仍为QP问题,对于乘子变量全是线性约束,目标函数是二次函数,可直接调程序包求解;那么如何求w和b呢?
求解w,b
线性可分条件下
求解对偶问题:
max
α
≥
0
L
(
α
)
=
−
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
+
∑
j
α
j
\max_{\alpha\geq0}L(\alpha)=-\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_j\textbf{x}_i^T\textbf{x}_j+\sum_j\alpha_j
α≥0maxL(α)=−21i∑j∑αiyiαjyjxiTxj+j∑αj
s
.
t
.
∑
j
α
j
y
j
=
0
,
α
j
≥
0
s.t. \sum_j\alpha_jy_j=0,\alpha_j\geq0
s.t.j∑αjyj=0,αj≥0
可以解得所有的
α
\alpha
α,我们在对对偶问题的内层进行优化时有:
∂
L
(
w
,
b
,
α
)
∂
w
=
w
−
∑
j
α
j
x
j
y
j
=
0
→
w
=
∑
j
α
j
x
j
y
j
\frac{\partial{L(w,b,\alpha)}}{\partial{w}}=w-\sum_{j}\alpha_jx_jy_j=0 \rightarrow w=\sum_{j}\alpha_jx_jy_j
∂w∂L(w,b,α)=w−j∑αjxjyj=0→w=j∑αjxjyj
所以可得w的求法
w
=
∑
j
α
j
x
j
y
j
\textbf{w}=\sum_{j}\alpha_j\textbf{x}_jy_j
w=∑jαjxjyj
那么b咋求?
这就需要回到我们上面说要重点关注的KKT条件的第五个
α
∗
g
(
x
∗
)
=
0
\alpha^*g(x^*)=0
α∗g(x∗)=0
它表示了
{
α
∗
>
0
==>
g
(
x
∗
)
=
0
约束被激活
g
(
x
∗
)
<
0
==>
α
∗
=
0
约束未被激活
\begin{cases} \alpha^* >0 & \text{==> }g(x^*)=0 约束被激活\\ g(x^*)<0 & \text{==> } \alpha^*=0 约束未被激活 \end{cases}
{α∗>0g(x∗)<0==> g(x∗)=0约束被激活==> α∗=0约束未被激活
在SVM模型中,也就是必有:
α
j
(
(
w
T
x
j
+
b
)
y
j
−
1
)
=
0
\alpha_j((w^Tx_j+b)y_j-1)=0
αj((wTxj+b)yj−1)=0
{
α
j
>
0
==>
(
w
T
x
j
+
b
)
y
j
=
1
约束被激活
(
w
T
x
j
+
b
)
y
j
>
1
==>
α
j
=
0
约束未被激活
\begin{cases} \alpha_j>0 & \text{==> }(w^Tx_j+b)y_j=1 约束被激活\\ (w^Tx_j+b)y_j>1 & \text{==> } \alpha_j=0 约束未被激活 \end{cases}
{αj>0(wTxj+b)yj>1==> (wTxj+b)yj=1约束被激活==> αj=0约束未被激活
所以我们选择[一个即可]对于
α
j
>
0
\alpha_j>0
αj>0的样本,例如
α
k
>
0
\alpha_k>0
αk>0,其对应的样本为
(
x
k
,
y
k
)
(x_k,y_k)
(xk,yk);
有
(
w
T
x
k
+
b
)
y
k
=
1
(w^Tx_k+b)y_k=1
(wTxk+b)yk=1,两边同时乘以
y
k
y_k
yk,可得:
w
T
x
k
+
b
=
y
k
w^Tx_k+b=y_k
wTxk+b=yk
b
=
y
k
−
w
T
x
k
b=y_k-w^Tx_k
b=yk−wTxk
求解对偶问题的意义–SVM机器学习内涵所在
如前所述,我们原问题本身就是一个QP问题,直接调用相应的求解程序包即可求解,接下来,我们从求解w,b的方式来看为什么需要转换为对偶问题:
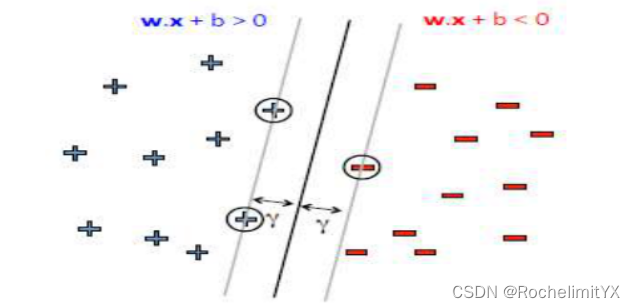
由上述,必有以下式子成立:
α
j
(
(
w
T
x
j
+
b
)
y
j
−
1
)
=
0
\alpha_j((w^Tx_j+b)y_j-1)=0
αj((wTxj+b)yj−1)=0
根据线性可分假设,如果分对了,也就是样本点在分类面类,
(
w
T
x
j
+
b
)
y
j
>
1
(w^Tx_j+b)y_j>1
(wTxj+b)yj>1,此时样本
(
x
j
,
y
j
)
(x_j,y_j)
(xj,yj)对应的
α
j
=
0
\alpha_j=0
αj=0,根据线性可分假设,它不可能有分错的,所以当
α
j
>
0
\alpha_j>0
αj>0样本
(
x
j
,
y
j
)
(x_j,y_j)
(xj,yj)位于分类面上;由
w
=
∑
j
α
j
x
j
y
j
\textbf{w}=\sum_{j}\alpha_j\textbf{x}_jy_j
w=∑jαjxjyj可知,对于那些
α
j
=
0
\alpha_j=0
αj=0对应的样本,是不会出现在上述求和计算式中的,对w的值没有任何影响,同时根据计算b的讨论,想要算出b也必须使用一个
α
k
>
0
\alpha_k>0
αk>0,其对应的样本为
(
x
k
,
y
k
)
(x_k,y_k)
(xk,yk),所以说但凡是
α
j
=
0
\alpha_j=0
αj=0对应的样本来说,他们对SVM模型的确定是无用的,只有落在Margin上的样本点才是可能有用的,即支撑向量,只留下支撑向量,其它的数据都可以丢掉,如果我们预先能找到数据的支撑,就可以把很多的数据都丢掉,而结果是完全一样的
线性不可分条件下
求解对偶问题:
min
α
,
γ
L
(
α
,
γ
)
=
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
x
i
T
x
j
−
∑
j
α
j
\min_{\alpha,\gamma}L(\alpha,\gamma)=\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_jx_i^Tx_j-\sum_j\alpha_j
α,γminL(α,γ)=21i∑j∑αiyiαjyjxiTxj−j∑αj
s
.
t
.
∑
j
α
j
y
j
=
0
,
C
≥
α
j
≥
0
s.t. \sum_j\alpha_jy_j=0,C\geq\ \alpha_j\geq0
s.t.j∑αjyj=0,C≥ αj≥0
可以解得所有的
α
\alpha
α和
γ
\gamma
γ,我们在对对偶问题的内层进行优化时有:
∂
L
(
w
,
b
,
,
ξ
,
α
,
γ
)
∂
w
=
w
−
∑
j
α
j
x
j
y
j
=
0
→
w
=
∑
j
α
j
x
j
y
j
\frac{\partial{L(w,b,,\xi,\alpha,\gamma)}}{\partial{w}}=w-\sum_{j}\alpha_jx_jy_j=0 \rightarrow w=\sum_{j}\alpha_jx_jy_j
∂w∂L(w,b,,ξ,α,γ)=w−j∑αjxjyj=0→w=j∑αjxjyj
所以可得w的求法
w
=
∑
j
α
j
x
j
y
j
\textbf{w}=\sum_{j}\alpha_j\textbf{x}_jy_j
w=∑jαjxjyj
那么b咋求?
这一样需要回到我们上面说要重点关注的KKT条件的第五个
α
∗
g
(
x
∗
)
=
0
\alpha^*g(x^*)=0
α∗g(x∗)=0
它表示了
{
α
∗
>
0
==>
g
(
x
∗
)
=
0
约束被激活
g
(
x
∗
)
<
0
==>
α
∗
=
0
约束未被激活
\begin{cases} \alpha^* >0 & \text{==> }g(x^*)=0 约束被激活\\ g(x^*)<0 & \text{==> } \alpha^*=0 约束未被激活 \end{cases}
{α∗>0g(x∗)<0==> g(x∗)=0约束被激活==> α∗=0约束未被激活
在非线性可分SVM模型中,也就是必有:
α
j
(
(
w
T
x
j
+
b
)
y
j
−
1
+
ξ
j
)
=
0
\alpha_j((w^Tx_j+b)y_j-1+\xi_j)=0
αj((wTxj+b)yj−1+ξj)=0
γ
j
ξ
j
=
0
\gamma_j\xi_j=0
γjξj=0
所以我们选择[一个即可]对于
C
>
α
j
>
0
C>\alpha_j>0
C>αj>0的样本,例如
C
>
α
k
>
0
C>\alpha_k>0
C>αk>0,此时可知
γ
j
=
C
−
α
j
≠
0
;
又
γ
j
ξ
j
=
0
;
ξ
j
=
0
\gamma_j=C-\alpha_j \neq0;又\gamma_j\xi_j=0;\xi_j=0
γj=C−αj=0;又γjξj=0;ξj=0其对应的样本为
(
x
k
,
y
k
)
(x_k,y_k)
(xk,yk);
有
(
w
T
x
k
+
b
)
y
k
=
1
(w^Tx_k+b)y_k=1
(wTxk+b)yk=1,两边同时乘以
y
k
y_k
yk,可得:
w
T
x
k
+
b
=
y
k
w^Tx_k+b=y_k
wTxk+b=yk
b
=
y
k
−
w
T
x
k
b=y_k-w^Tx_k
b=yk−wTxk
求解对偶问题的意义–SVM机器学习内涵所在
和讨论线性可分条件下的支撑向量一样,我们现在来讨论非线性可分条件下的支撑向量是啥?
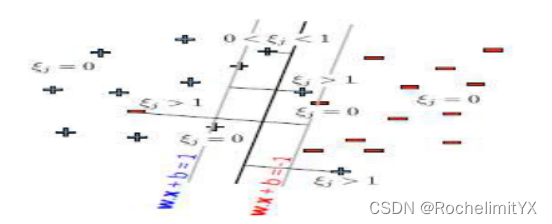
由上述,必有以下式子成立:
α
j
(
(
w
T
x
j
+
b
)
y
j
−
1
+
ξ
j
)
=
0
\alpha_j((w^Tx_j+b)y_j-1+\xi_j)=0
αj((wTxj+b)yj−1+ξj)=0
γ
j
ξ
j
=
0
\gamma_j\xi_j=0
γjξj=0
对于训练数据集中的每一个样本
(
x
j
,
y
j
)
(x_j,y_j)
(xj,yj),针对解得的
α
∗
\alpha^*
α∗,总有当
α
j
=
0
\alpha_j=0
αj=0时,这个样本不会对f(x)有任何影响,因为由
w
=
∑
j
α
j
x
j
y
j
\textbf{w}=\sum_{j}\alpha_j\textbf{x}_jy_j
w=∑jαjxjyj可知,对于那些
α
j
=
0
\alpha_j=0
αj=0对应的样本,是不会出现在上述求和计算式中的,对w的值没有任何影响,同时根据计算b的讨论,想要算出b也必须使用一个
C
>
α
k
>
0
C>\alpha_k>0
C>αk>0,其对应的样本为
(
x
k
,
y
k
)
(x_k,y_k)
(xk,yk),所以说但凡是
α
j
=
0
\alpha_j=0
αj=0对应的样本来说,他们对SVM模型的确定是无用的,当
α
j
n
e
q
0
\alpha_jneq0
αjneq0时,必有
(
w
T
x
j
+
b
)
y
j
−
1
+
ξ
j
=
0
(w^Tx_j+b)y_j-1+\xi_j=0
(wTxj+b)yj−1+ξj=0,显然这样的样本对w和b都有影响,是所谓支撑向量;
而且进一步有,如果
α
j
<
C
\alpha_j<C
αj<C时,由
C
=
α
j
+
γ
j
C=\alpha_j+\gamma_j
C=αj+γj,
γ
j
>
0
\gamma_j>0
γj>0,又
γ
j
ξ
j
=
0
\gamma_j\xi_j=0
γjξj=0,
所以
(
w
T
x
j
+
b
)
y
j
=
1
(w^Tx_j+b)y_j=1
(wTxj+b)yj=1,也就是这个样本位于最大间隔的边界上;
如果
α
j
=
C
\alpha_j=C
αj=C时,由
C
=
α
j
+
γ
j
C=\alpha_j+\gamma_j
C=αj+γj,
γ
j
=
0
\gamma_j=0
γj=0,此时如果解得的对应样本的对应的
ξ
j
≤
1
\xi_j\leq1
ξj≤1,根据
(
w
T
x
j
+
b
)
y
j
=
1
−
ξ
j
(w^Tx_j+b)y_j=1-\xi_j
(wTxj+b)yj=1−ξj,即
1
≥
(
w
T
x
j
+
b
)
y
j
≥
0
1\geq(w^Tx_j+b)y_j\geq0
1≥(wTxj+b)yj≥0根据线性可分假设,这样的样本也是分对了的,但是位于最大间隔的内部;如果解得的对应样本的对应的
ξ
j
>
1
\xi_j>1
ξj>1,根据
(
w
T
x
j
+
b
)
y
j
=
1
−
ξ
j
(w^Tx_j+b)y_j=1-\xi_j
(wTxj+b)yj=1−ξj,即
(
w
T
x
j
+
b
)
y
j
<
0
(w^Tx_j+b)y_j<0
(wTxj+b)yj<0根据线性可分假设,这样的样本也是分错了的;
综上,我们得到支撑向量,位于最大间隔边界上的点,位于边界内的点,分错了的点
依然地只留下支撑向量,其它的数据都可以丢掉,如果我们预先能找到数据的支撑,就可以把很多的数据都丢掉,而结果是完全一样的
再看SVM目标函数
可将目标函数视为损失加正则的模式;
min
w
,
b
,
ξ
j
1
2
w
T
w
+
C
∑
j
ξ
j
\min_{w,b,\xi_j}\frac{1}{2}w^Tw+C\sum_j\xi_j
w,b,ξjmin21wTw+Cj∑ξj
s
.
t
.
(
w
T
x
j
+
b
)
y
j
≥
1
−
ξ
j
,
f
o
r
a
l
l
j
=
1...
n
s.t.(w^Tx_j+b)y_j\geq 1-\xi_j,for\,all \,j=1...n
s.t.(wTxj+b)yj≥1−ξj,forallj=1...n
ξ
j
≥
0
,
f
o
r
a
l
l
j
=
1...
n
\xi_j\geq 0,for\,all \,j=1...n
ξj≥0,forallj=1...n
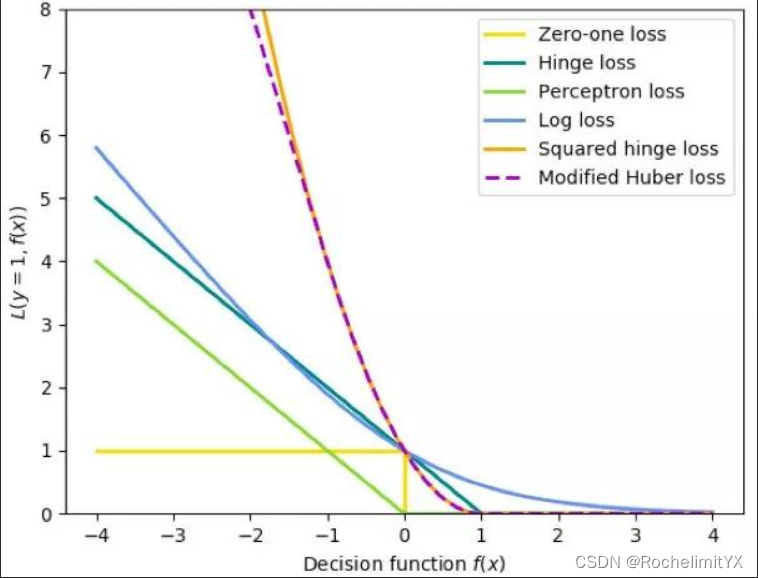
且可以将上述问题用hinge损失重写为
min
w
,
b
,
ξ
j
1
2
w
T
w
+
C
∑
j
max
(
0
,
1
−
(
w
T
x
j
+
b
)
y
j
)
\min_{w,b,\xi_j}\frac{1}{2}w^Tw+C\sum_j\max(0,1-(w^Tx_j+b)y_j)
w,b,ξjmin21wTw+Cj∑max(0,1−(wTxj+b)yj)
此处损失还可以为其它形式:
核化技巧
如数据非线性可分时,该怎样使用SVM?
朴素自然的思想:变非线性为线性–核方法
在低维空间计算获得高维空间的计算结果,满足高维,才能在高维下线性可分。 我们需要引入一个新的概念:核函数。它可以将样本从原始空间映射到一个更高维的特质空间中,使得样本在新的空间中线性可分。这样我们就可以使用原来的推导来进行计算,只是所有的推导是在新的空间,而不是在原来的空间中进行,即用核函数来替换当中的内积。
对偶问题
min
α
,
γ
L
(
α
,
γ
)
=
1
2
∑
i
∑
j
α
i
y
i
α
j
y
j
K
(
x
i
,
x
j
)
−
∑
j
α
j
\min_{\alpha,\gamma}L(\alpha,\gamma)=\frac{1}{2}\sum_i\sum_j\alpha_iy_i\alpha_jy_jK(x_i,x_j)-\sum_j\alpha_j
α,γminL(α,γ)=21i∑j∑αiyiαjyjK(xi,xj)−j∑αj
K
(
x
i
,
x
j
)
=
Φ
(
x
i
)
.
Φ
(
x
j
)
K(x_i,x_j)=\Phi(x_i).\Phi(x_j)
K(xi,xj)=Φ(xi).Φ(xj)
s
.
t
.
∑
j
α
j
y
j
=
0
,
C
≥
α
j
≥
0
s.t. \sum_j\alpha_jy_j=0,C\geq\ \alpha_j\geq0
s.t.j∑αjyj=0,C≥ αj≥0
即通过一个非线性转换后的两个样本间的内积。具体地,𝐾(𝑥, 𝑧)是一个核函数,或正定核,
意味着存在一个从输入空间到特征空间的映射,对于任意空间输入的𝑥, 𝑧 有:𝐾(𝑥, 𝑧) = 𝜙(𝑥) ⋅ 𝜙(𝑧)
注记:原问题或者对偶问题的x不能是单一出现的,只能是以内积的形式
典型核函数:
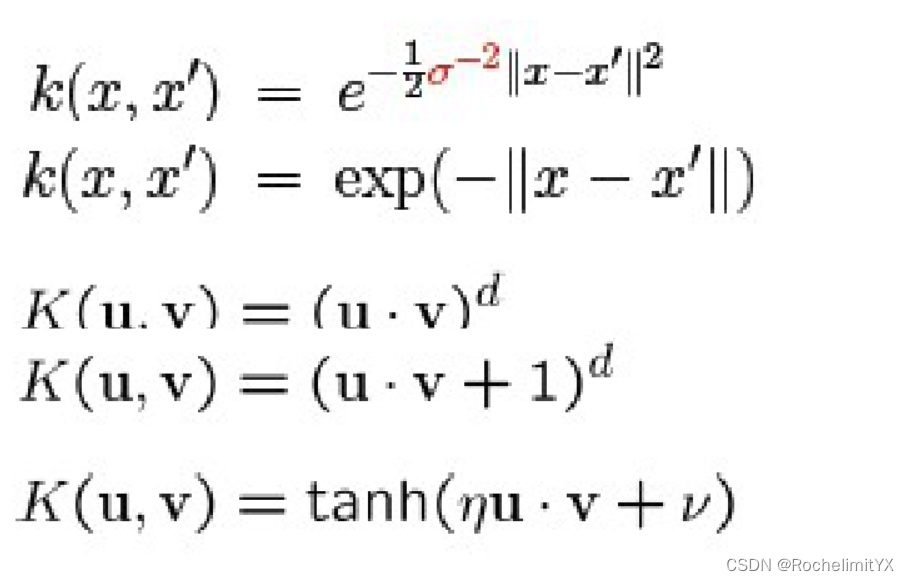
求解w,b
w
=
∑
j
α
j
y
j
Φ
(
x
j
)
\textbf{w}=\sum_j\alpha_jy_j\Phi(x_j)
w=∑jαjyjΦ(xj)
b
=
y
k
−
w
.
Φ
(
x
j
)
,
其中
k
满足
,
C
>
α
k
>
0
,
任选一个样本即可
b=y_k-w.\Phi(x_j),其中k满足,C>\alpha_k>0,任选一个样本即可
b=yk−w.Φ(xj),其中k满足,C>αk>0,任选一个样本即可
f
(
x
)
=
s
i
g
n
(
w
.
Φ
(
x
)
+
b
)
f(x)=sign(\textbf{w}.\Phi(x)+b)
f(x)=sign(w.Φ(x)+b)
小结
支撑向量机作为传统机器学习方法的集大成者,其在数学理论的正确性核优美性是我们所追求的,在对偶问题下看清SVM作为机器学习方法的本质内涵,更应该是我们所推崇的,接下来的一篇将继续SVM,探讨由核函数引出的超参数调整方法以及其引发的统计学习理论的快速发展,使得机器学习有了深刻的理论支持,就如那支撑向量之于训练数据集的重要性一样。















 2049
2049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









