







GRAF: Generative Radiance Fieldsfor 3D-Aware Image Synthesis(基于产生辐射场的三维图像合成)
思维导图:https://blog.csdn.net/weixin_53765004/article/details/137944206?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22137944206%22%2C%22source%22%3A%22weixin_53765004%22%7D
Abstract
虽然二维生成对抗网络能够实现高分辨率的图像合成,但是它们在很大程度上缺乏对三维世界和图像形成过程的理解。因此,他们不提供精确的控制相机的视点或对象的姿态。为了解决这个问题,最近的一些方法利用了中间基于体素的表示结合可微渲染。然而,现有的方法要么产生较低的图像分辨率,要么在相机和场景的分离属性方面存在不足,例如,物体的识别可能会因视点的不同而不同。在这篇文章中,我们提出了一个辐射场的生成模型,这个辐射场最近被证明是成功的,用于单个场景的新视图合成。与基于体素的表示相比,辐射场并不局限于对三维空间的粗糙离散化,而是允许在存在重建模糊的情况下优雅地分离相机和场景属性。 通过引入一个多尺度的基于补丁的鉴别器,我们演示了高分辨率图像的合成,同时从非定位的二维图像单独地训练我们的模型。我们系统地分析了我们的方法在几个具有挑战性的合成和真实世界的数据集。我们的实验表明,辐射场是一个强大的表示生成图像合成,导致三维一致的模型渲染高保真度。
三、Method
我们考虑了三维感知图像合成的问题,即在生成高保真图像的同时提供摄像机旋转和平移的显式控制。我们主张用场景的辐射场来表示场景,这样的连续表示可以很好地衡量图像的分辨率和内存消耗,同时允许基于物理的和无参数的投影映射。在接下来的文章中,我们首先简要回顾了构成生成辐射场(GRAF)模型基础的神经辐射场(NeRF)
3.1 Neural Radiance Fields
Neural Radiance Fields:
辐射场是从3D 位置和2D 观察方向到 RGB 颜色值的连续映射。Mildenhall提议使用神经网络来表示这种映射。更具体地说,他们首先使用固定位置编码将一个三维位置 x ∈ R3和一个观察方向 d ∈ S2映射到一个更高维的特征表示,该编码按元素方式应用于 x 和 d 的所有三个分量:
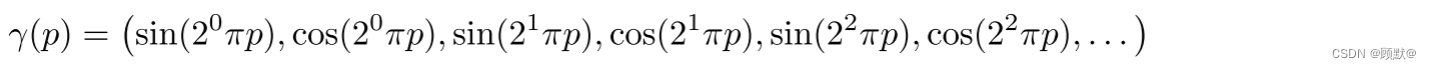
遵循最近的隐式模型,然后他们应用一个参数 θ 的多层感知器 fθ (·),将得到的特征映射为颜色值 c ∈ R^3和体积密度σ ∈ R ^+:
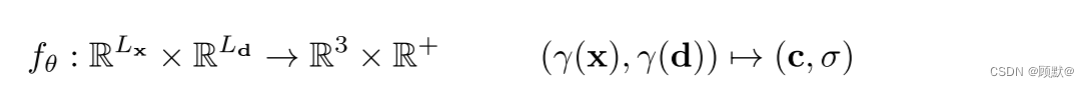 与直接使用 x 和 d 作为多层感知器 fθ (·)的输入相比,位置编码 γ (·)能够更好地拟合高频信号。我们通过消融研究证实了这一点。由于体积颜色 c 随观察方向的变化比随3D 位置的变化更为平滑,所以观察方向通常使用较少的组件进行编码,即 Ld < Lx。
与直接使用 x 和 d 作为多层感知器 fθ (·)的输入相比,位置编码 γ (·)能够更好地拟合高频信号。我们通过消融研究证实了这一点。由于体积颜色 c 随观察方向的变化比随3D 位置的变化更为平滑,所以观察方向通常使用较少的组件进行编码,即 Ld < Lx。
Volume Rendering:
为了绘制辐射场 fθ (·)的二维图像,米尔登霍尔等人使用数值积分近似难以处理的体积投影积分。更正式地,设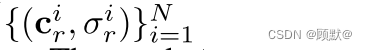
表示沿照相机射线 r 的 N 个随机样本的颜色和体积密度值。rendering operator(呈现操作符 ):π (·),将这些值映射到 RGB 颜色值 cr:
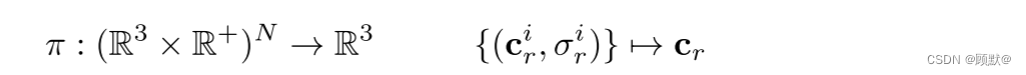
RGB 颜色值 cr 是使用 alpha 合成获得的
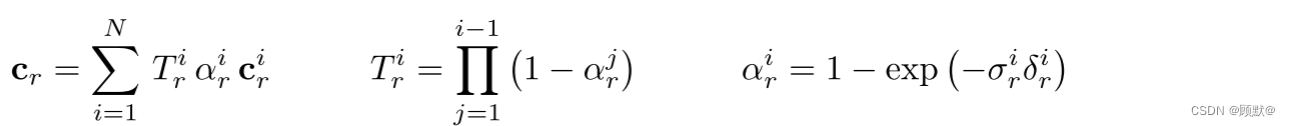
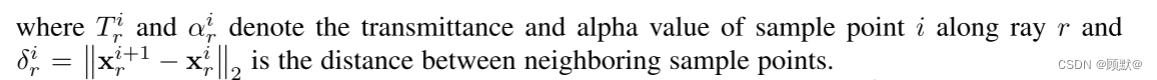
给定一组单个静态场景的二维图像,米尔登霍尔等人通过最小化观测值和预测值之间的重建损失(平方差之和)来优化神经辐射场 fθ (·)的参数 θ。给定 θ,可以通过对每个像素/光线调用 π (·)来合成新的视图。
3.2 Generative Radiance Fields
在这项工作中,我们感兴趣的辐射场作为表示的三维感知图像合成。与NeRF相反,我们不假设单个场景的大量姿势图像。相反,我们的目标是通过训练未定位的图像来学习一个新的场景合成模型。更具体地说,我们利用一个对抗性的框架来训练辐射场生成模型(GRAF)。
下图显示了我们模型的概况。生成器 Gθ 以摄像机矩阵 K、摄像机姿态 ξ、二维采样模式 ν 和形状/外观码 zs ∈ Rm/za ∈ R^n 为输入,预测图像补丁 P。鉴别器 Dφ 将合成的补丁 P’ 与从实际图像 I 中提取的补丁 P 进行比较。在推理时,我们为每个图像像素预测一个颜色值。然而,在训练时间,这太昂贵了。因此,我们预测一个固定大小的 K × K 像素片,它被随机缩放和旋转以提供整个辐射场的梯度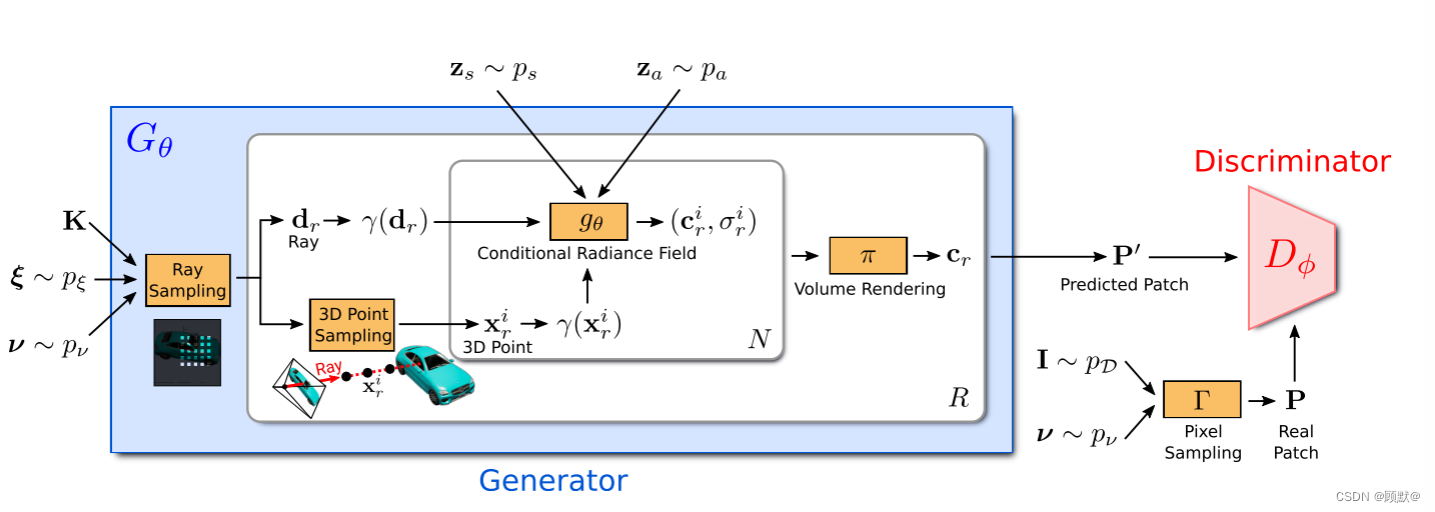
该图: 生成辐射场。生成器 Gθ 以摄像机矩阵 K、摄像机姿态 ξ、二维采样模式 ν 和形状/外观码 zs ∈ Rm/za ∈ Rn 为输入,预测图像补丁 P’。我们使用平板符号来说明 R 射线和每条射线 N 个样本。注意,条件辐射场 gθ 是唯一具有可训练参数的分量。鉴别器 Dφ 将合成的补丁 P’ 与从实际图像 I 中提取的实际补丁 P 进行比较。在训练时,我们使用大小为 K × K 像素的稀疏二维采样模式来提高计算和存储效率。在推理时,我们为目标图像中的每个像素预测一个颜色值。
3.2.1 Generator
我们从一个位姿分布中取样摄像机的姿态 ξ = [ R | t ]。在我们的实验中,我们在上半球的相机位置,相机面向坐标系的起点,使用一个均匀分布。根据数据集的不同,我们也会均匀地改变摄像机到原点的距离。我们选择 K,使得主要点位于图像的中心。
V = (u,s)决定了我们要生成的虚 K × K 补丁 P (u,s)的中心 u = (u,v)∈ R^2,标度 s ∈ R + 。这使我们能够使用卷积鉴别器独立于图像分辨率。我们从图像域 Ω 上的均匀分布中随机抽取补丁中心 u~ U (Ω) ,从均匀分布 s~ U ([1,S ])中抽取补丁尺度 s,其中 S = min (W,H)/K,W 和 H 表示目标图像的宽度和高度。此外,我们确保整个补丁是在图像域 Ω 内。分别从形状和外观分布中提取了形状和外观变量 zs 和 za。在我们的实验中,我们对 ps 和 pa 都使用了一个标准的正态分布/高斯分布。
Ray Sampling:
K × K 贴片 P (u,s)由一组二维图像坐标确定
它描述了图像域 Ω 中贴片的每个像素的位置,如图
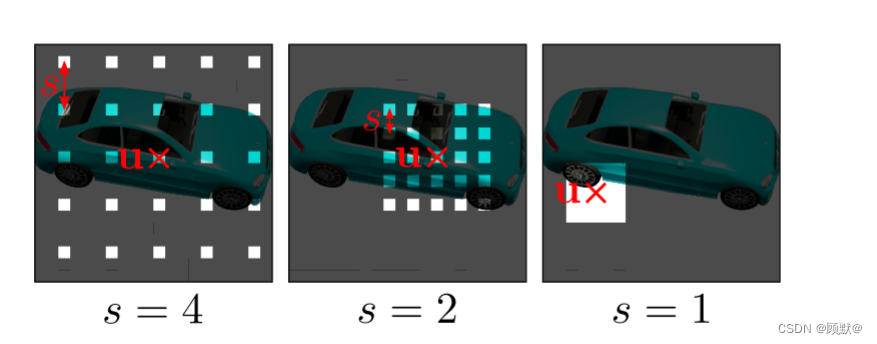
图3:给定摄像机姿态 ξ,根据 ν = (u,s)对光线进行采样,确定 K × K 补丁的连续二维平移 u ∈ R^2和标度 s ∈ R ^+ 。这使我们能够使用卷积鉴别器独立于图像分辨率。
这些坐标是实数,而不是离散的整数,使我们能够不断评估辐射场。相应的三维射线由 P (u,s)、摄像机姿态 ξ 和内参矩阵 K 唯一确定。我们用 r 表示像素/射线索引,用 dr 表示归一化的3D 射线,用 R 表示射线数,其中训练期间 R = K^2,推断期间 R = WH。
3D Point Sampling:
对于辐射场的数值积分,我们沿着每个射线 r 采样 N 个点
使用NeRF中的分层抽样方法,见附录详细资料。
Conditional Radiance Field:
辐射场由一个具有参数 θ 的深度全连通神经网络表示,该神经网络映射位置编码三维位置 x ∈ R^3,视方向 d ∈ S ^2,得到 RGB 颜色值 c 和体积密度 σ: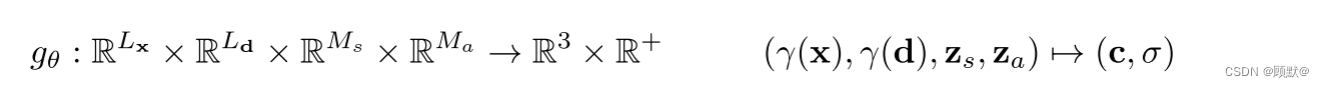
gθ 是以两个附加的潜码为条件的: 一个形状码 zs ∈ R^(Ma) 决定物体的形状,一个外观码 za ∈ R ^ (Ma) 决定物体的外观。因此我们称 gθ 为条件辐射场.
我们的条件辐射场 gθ 的网络结构如图所示。我们首先从 x 和形状代码 z 的位置编码计算一个形状编码 h。密度头 σθ 将此编码转换为体积密度 σ。为了预测三维位置 x 处的颜色 c,我们将 h 与 d 的位置编码和外观编码 za 连接起来,并将得到的向量传递给颜色头 cθ。我们独立于视点 d 和外观代码 za 计算 σ,以鼓励多视点一致性,同时从外观中分离形状。这鼓励网络使用潜在代码 zs 和 za 分别建模形状和外观,并允许在推断期间分别操作它们。更正式地说,我们有: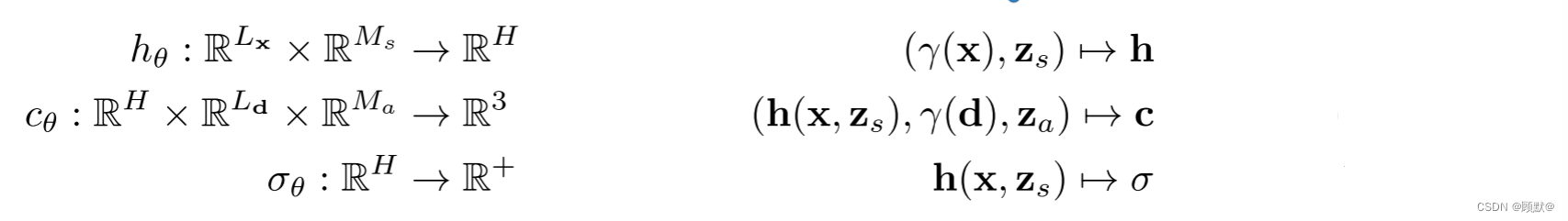
所有的映射(hθ,cθ 和 σθ)都是使用具有 ReLU 激活的完全连通网络来实现的。为了避免符号混乱,我们使用相同的符号 θ 来表示每个网络的参数。
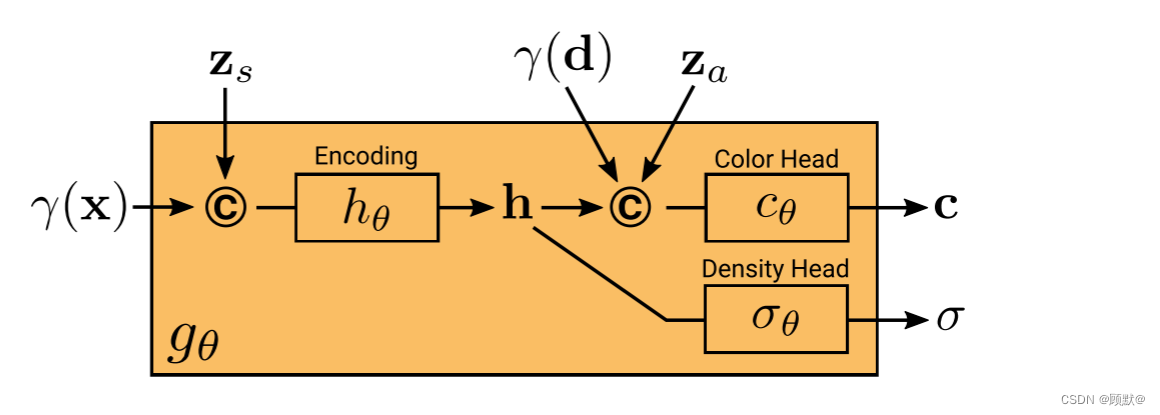
图: 条件辐射场。当体积密度 σ 完全取决于3D 点 x 和形状编码 z 时,预测的颜色值 c 还取决于视向 d 和外观编码 za,建模视相关的外观,例如,反射率。
Volume Rendering:
给定沿着光线 r 的所有点的颜色和体积密度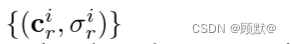
利用方程rendering operator,我们得到了对应于光线 r 的像素的颜色 cr ∈ R^3.结合所有 R 射线的结果,我们将预测的补丁表示为 P’
3.2.2 Discriminator
鉴别器 Dφ 是作为一个卷积神经网络实现的。它将预测的补丁 P’ 与从数据分布 pD 中提取的实际图像中提取的补丁 P 进行比较。为了从实际图像 I 中提取 K × K 贴片,我们首先从相同的分布中提取 ν = (u,s) ,然后再从上面的分布中提取生成贴片。然后,我们通过使用双线性插值在二维图像坐标 P (u,s)上查询 I 来对真正的补丁 p 进行采样。下面我们用 Γ (I,ν)来表示这种双线性采样运算。注意,我们的鉴别器类似于 PatchGAN ,除了我们允许连续位移 u 和标度 s,而 PatchGAN 使用 s = 1。进一步需要注意的是,我们并没有基于 s 减少真实图像的样本,而是在稀疏位置查询 I 以保留高频细节,见图3。
在实验上,我们发现一个具有共享权重的单一鉴别器对于所有的斑块都是足够的,即使这些补丁是在不同尺度的随机位置采样的。注意,缩放决定了补丁的接收字段。为了便于培训,我们从更大的接收字段补丁开始,以捕获全局上下文。然后,我们逐步抽样带有较小接收字段的补丁来细化局部细节。
3.2.3 Training and Inference(训练和推理)
让I从数据分布 pD 表示一个图像,让 pν 表示随机补丁上的分布(见3.2.1节)。我们使用 R1 正则化 的非饱和 GAN 损耗(non-saturating GAN loss)来训练我们的模型
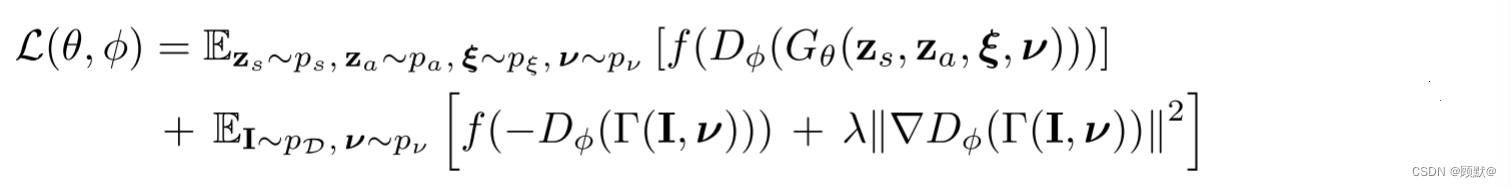
其中 f (t) =-log (1 + exp (- t))和 λ 控制正则化器的强度。我们在我们的鉴别器中使用谱归一化和实例归一化,并使用 RMSprop训练我们的方法,其批量大小为8,生成器和鉴别器的学习速率分别为0.0005和0.0001。在推理中,我们随机抽取 zs,za 和 ξ,并预测图像中所有像素的颜色值。
四、 Experiments
五、结论
我们引入了生成辐射场(GRAF)用于高分辨率的三维感知图像合成。结果表明,与基于体素的方法相比,我们的框架能够生成具有更好的多视点一致性的高分辨率图像。然而,我们的结果仅限于单个对象的简单场景。我们相信结合归纳偏差,例如深度图或对称性,将允许我们的模型扩展到未来更具挑战性的现实世界场景。
Broader Impact更广泛的影响
3D 感知图像合成是一个相对较新的研究领域,尚未扩展到生成复杂的现实世界场景,阻碍了社会的直接应用。然而,我们的工作朝着这一目标迈出了重要的一步,因为它能够实现超过642像素分辨率的高保真重建,同时不需要3D 监督作为输入。从长远来看,我们希望我们的研究能够促进3D 感知生成模型在虚拟现实、数据增强或机器人技术等应用中的应用。例如,自动驾驶汽车等智能系统需要大量数据进行训练和验证,而使用静态离线数据集无法收集这些数据。我们相信,建立我们的世界的生成,照片真实和大规模三维模型将最终允许成本效益的数据收集和模拟。虽然许多用例是可能的,但是我们相信这些类型的模型特别有利于缩小现实世界和合成数据之间现有的领域差距。然而,使用生成模型也需要小心。虽然生成逼真的3D 场景是非常有趣的,但它也承担着操纵和创造误导性内容的风险。特别是,能够创建3D 一致性假图像的模型可能会提高假内容的可信度,并可能会欺骗依赖于多视点一致性的系统,例如现代人脸识别系统。因此,我们认为,社区发展能够明确区分合成内容和现实世界内容的方法同样重要。我们看到这方面的进展令人鼓舞。















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









