







ResNeXt
S. Xie,R. Girshick,P. Dollar,Z. Tu 和 K. He 在《深度神经网络的聚集残差变换》中提出了一个代号为 ResNeXt 的 ResNet 变体,它具有以下构建块:
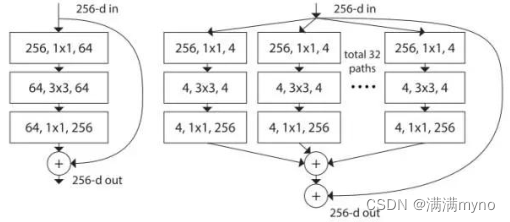
左图:《用于图像识别的深度残差学习》中所提及的构建块,右图: ResNeXt 构建块 基数=32
这可能看起来很熟悉,因为它非常类似于《IEEE 计算机视觉与模式识别会议论文集》中《Going deeper with convolutions》的 Inception 模块,它们都遵循“拆分-转换-合并”范式,除了在这个变体中,不同路径的输出通过将它们相加在一起而被合并,而在《Going deeper with convolutions》中它们是深度连接的。另一个区别是,在《Going deeper with convolutions》中,每个路径彼此互不相同(1x1,3x3 和 5x5 卷积),而在此架构中,所有路径共享相同的拓扑。
作者介绍了一个称为 “基数(cardinality)”的超参数——独立路径的数量,以提供调整模型容量的新方式。实验表明,可以通过增加基数,而不是深度或宽度,来更加有效地获得准确度。作者指出,与 Inception 相比,这种新颖的架构更容易适应新的数据集/任务,因为它具有一个简单的范式,且只有一个超参数被调整,而 Inception 却具有许多超参数(如每个路径中卷积层内核大小)待调整。
这个新颖的构建块有如下三种等效形式:
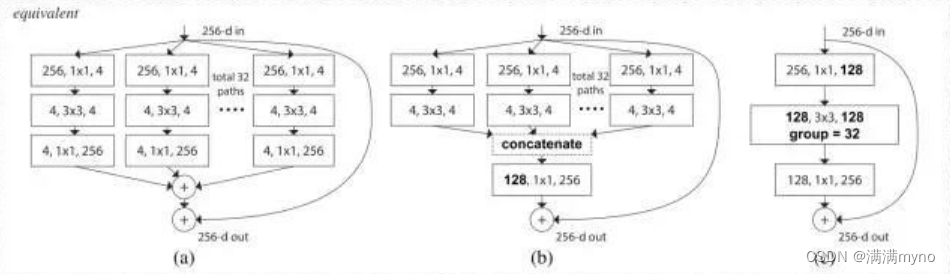
实际上,“分割-变换-合并”通常是通过点分组卷积层来完成的,它将其输入分成特征映射组,并分别执行正常卷积,其输出被深度级联,然后馈送到 1x1 卷积层。
Densely Connected CNN
Huang 等在《密集卷积网络》中提出了一种称为 DenseNet 的新型架构,进一步利用近路连接的效果—将所有层直接互连在一起。在这种新颖的架构中,每层的输入由所有较早层的特征映射组成,其输出传递给每个后续层。特征映射与深度级联聚合。
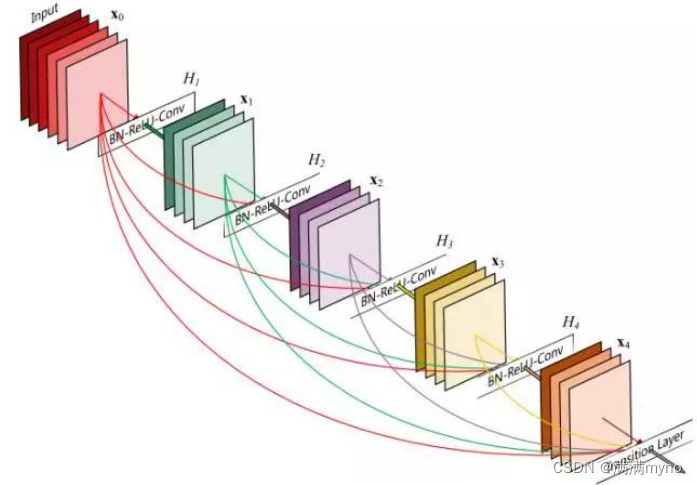
深度神经网络的聚集残差变换》的作者除了应对梯度消失问题外,还认为这种架构还鼓励特征重用,从而使得网络具有高度的参数效率。一个简单的解释是,在《用于图像识别的深度残差学习》和《深度残差网络中的身份映射》中,身份映射的输出被添加到下一个块,如果两层的特征映射具有非常不同的分布,这可能会阻碍信息流。因此,级联特征映射可以保留所有特征映射并增加输出的方差,从而鼓励特征重用。

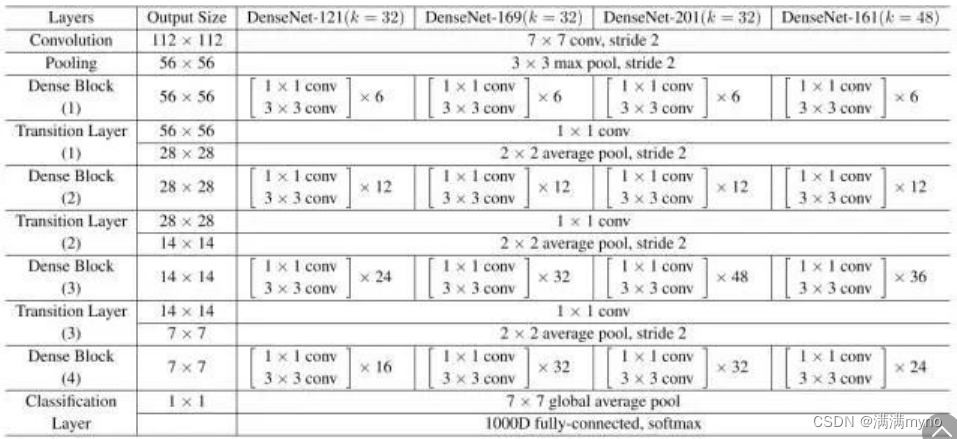
遵循这个范式,我们知道第 l 层将具有 k *(l-1)+ k_0 个输入特征映射,其中 k_0 是输入图像中的通道数。作者使用一个称为增长率(k)的超参数,防止网络生长过宽,他们还使用 1x1 卷积瓶颈层,以减少昂贵的 3x3 卷积之前的特征映射的数量。整体结构如下表所示:
















 1124
1124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











