







ResNeXt-Tensorflow
使用Cifar10数据集的ResNeXt在Tensorflow上的实现。
如果你想查看原作者的代码,请参考此链接https://github.com/facebookresearch/ResNeXt
要求
Tensorflow 1.x
Python 3.x
tflearn(如果你觉得全局平均池比较容易,你应该安装tflearn)
架构比较
ResNet
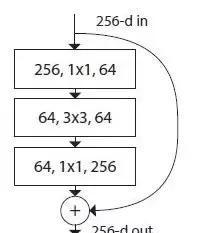
ResNeXt
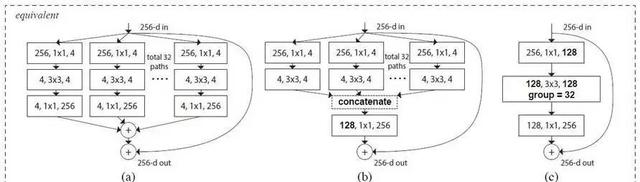
我实施了(b)
(b)是分割 + 变换(Bottleneck)+ 拼接 + 转换 + 合并
问题
什么是“分割”?
def split_layer(self, input_x, stride, layer_name):
with tf.name_scope(layer_name) :
layers_split = list()
for i in range(cardinality) :
splits = self.transform_layer(input_x, stride=stride, scope=layer_name + '_splitN_' + str(i))
layers_split.append(splits)
return Concatenation(layers_split)
基数是指你想要分割多少次
什么是“变换”?
def transform_layer(self, x, stride, scope):
with tf.name_scope(scope) :
x = conv_layer(x, filter=depth, kernel=[1,1], stride=stride, layer_name=scope+'_conv1')
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
x = conv_layer(x, filter=depth, kernel=[3,3], stride=1, layer_name=scope+'_conv2')
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch2')
return x
什么是“转换”?
def transition_layer(self, x, out_dim, scope):
with tf.name_scope(scope):
x = conv_layer(x, filter=out_dim, kernel=[1,1], stride=1, layer_name=scope+'_conv1')
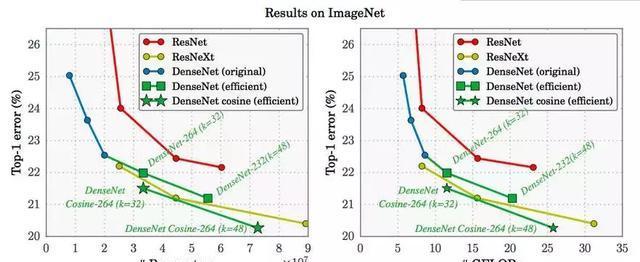
结果比较(ResNet、DenseNet、ResNet)
相关作品
DenseNet (https://github.com/taki0112/Densenet-Tensorflow)
参考
分类数据集结果(http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html)
Densenet-Tensorflow
使用Cifar10、MNIST数据集的Densenet(https://arxiv.org/abs/1608.06993)在Tensorflow上的实现。
实现本论文的代码是Densenet.py。
有一些细微的区别是,我用的是AdamOptimizer。
如果你想查看原作者的代码或其他实现,请参考此链接(https://github.com/liuzhuang13/DenseNet)
tflearn(如果你对全局平均池(global average pooling)能够很好地掌握,那你就应该安装tflearn。
但是,我使用的是tf.layers将它实现的,因此你也不必过分担心。
我使用tf.contrib.layers.batch_norm
defBatch_Normalization(x, training, scope):
witharg_scope([batch_norm],
scope=scope,
updates_collections=None,
decay=0.9,
center=True,
scale=True,
zero_debias_moving_mean=True) :
returntf.cond(training,
lambda :batch_norm(inputs=x, is_training=training, reuse=None),
lambda :batch_norm(inputs=x, is_training=training, reuse=True))
理念
什么是全局平均池(global average pooling)?
defGlobal_Average_Pooling(x, stride=1) :
width=np.shape(x)[1]
height=np.shape(x)[2]
pool_size= [width, height]
return tf.layers.average_pooling2d(inputs=x, pool_size=pool_size, strides=stride)
# The stride value does not matter
如果你使用的是tflearn,请参考此链接(http://tflearn.org/layers/conv/#global-average-pooling)
defGlobal_Average_Pooling(x):
returntflearn.layers.conv.global_avg_pool(x, name='Global_avg_pooling')
什么是密集连接(Dense Connectivity)?

什么是Densenet架构?
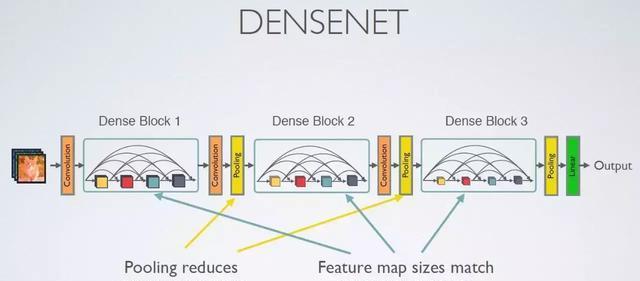
池化减少了特征映射的大小
特征映射大小在每个块内匹配
defDense_net(self, input_x):
x =conv_layer(input_x, filter=2*self.filters, kernel=[7,7], stride=2, layer_name='conv0')
x =Max_Pooling(x, pool_size=[3,3], stride=2)
x =self.dense_block(input_x=x, nb_layers=6, layer_name='dense_1')
x =self.transition_layer(x, scope='trans_1')
x =self.dense_block(input_x=x, nb_layers=12, layer_name='dense_2')
x =self.transition_layer(x, scope='trans_2')
x =self.dense_block(input_x=x, nb_layers=48, layer_name='dense_3')
x =self.transition_layer(x, scope='trans_3')
x =self.dense_block(input_x=x, nb_layers=32, layer_name='dense_final')
x =Batch_Normalization(x, training=self.training, scope='linear_batch')
x =Relu(x)
x =Global_Average_Pooling(x)
x = Linear(x)
什么是密集块(Dense Block)?
defdense_block(self, input_x, nb_layers, layer_name):
withtf.name_scope(layer_name):
layers_concat=list()
layers_concat.append(input_x)
x =self.bottleneck_layer(input_x, scope=layer_name+'_bottleN_'+str(0))
layers_concat.append(x)
for i inrange(nb_layers-1):
x =Concatenation(layers_concat)
x =self.bottleneck_layer(x, scope=layer_name+'_bottleN_'+str(i +1))
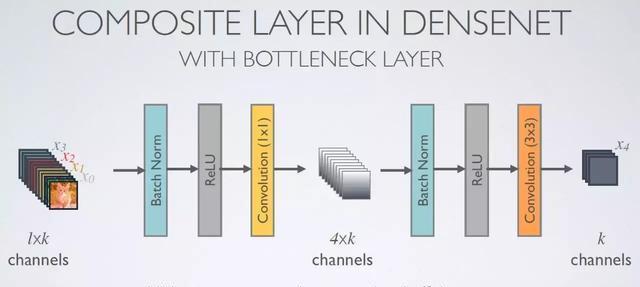
什么是Bottleneck 层?
defbottleneck_layer(self, x, scope):
withtf.name_scope(scope):
x =Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x =conv_layer(x, filter=4*self.filters, kernel=[1,1], layer_name=scope+'_conv1')
x =Drop_out(x, rate=dropout_rate, training=self.training)
x =Batch_Normalization(x, training=self.training, scope=scope+'_batch2')
x =conv_layer(x, filter=self.filters, kernel=[3,3], layer_name=scope+'_conv2')
什么是转换层(Transition Layer)?
deftransition_layer(self, x, scope):
x =conv_layer(x, filter=self.filters, kernel=[1,1], layer_name=scope+'_conv1')
x =Average_pooling(x, pool_size=[2,2], stride=2)
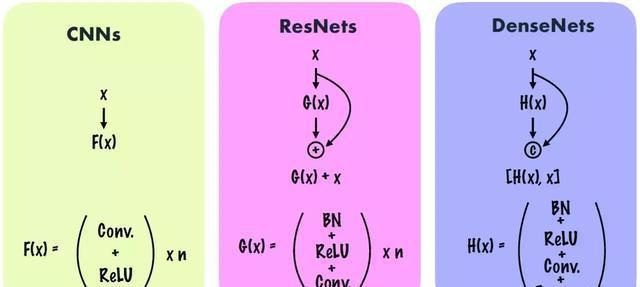
结构比较(CNN、ResNet、DenseNet)
结果
(MNIST)最高测试精度为99.2%(该结果不使用dropout)。
密集块层数固定为4个。
for i inrange(self.nb_blocks) :
# original : 6 -> 12 -> 48
x =self.dense_block(input_x=x, nb_layers=4, layer_name='dense_'+str(i))
x =self.transition_layer(x, scope='trans_'+str(i))
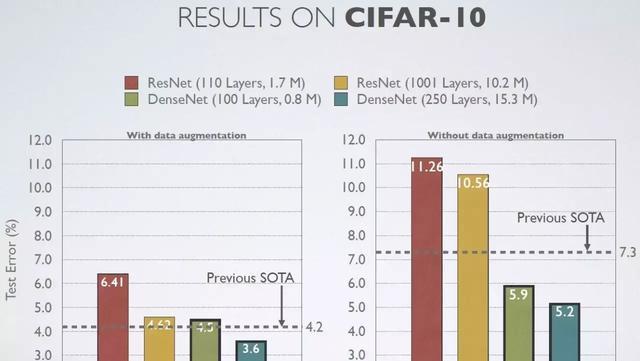
CIFAR-10
CIFAR-100
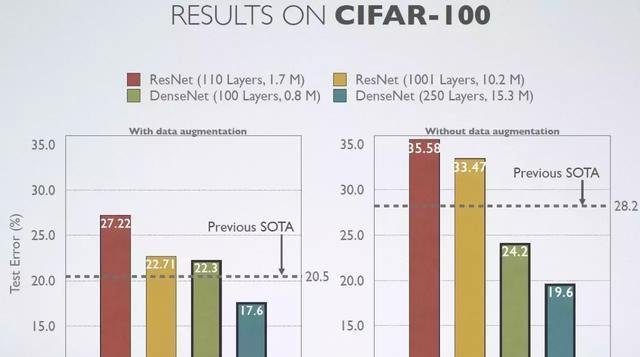
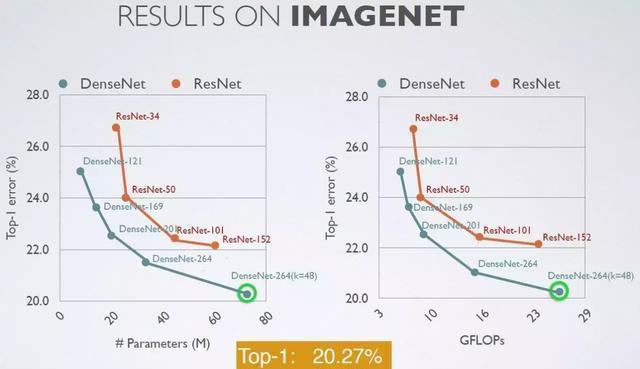
Image Net















 3199
3199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









