







文章来源 | 恒源云社区(恒源云,专注 AI 行业的共享算力平台)
原文地址 | LLD: 内部数据指导的标签去噪方法
原文作者 | Mathor
大佬发文太勤快,再不搬运,我自己都不好意思了,所以今天给大家带来新的内容啦~
正文开始:
很多数据集中的标签都存在错误,即便它们是由人来标注的,错误标签的存在会给模型训练带来某些负面影响。目前缓解这种影响有诸如删除错误标签、降低其权重等方法。ACL2022有一篇名为《A Light Label Denoising Method with the Internal Data Guidance》的投稿提出了一种基于样本内部指导的方法解决这个问题
先前有研究表明同一类别的样本在本质上是相似和相关的,不同类别的样本存在明显差异。在文本分类任务中,两个有着相似内容的句子应该被预测为同一个类别,但是实际情况并不总是这样。当训练数据面临一定程度的噪声时,这个问题可能会更加严重,因为模型只收到标签的指导/监督。这就自然而然提出了一个问题:除了标签之外,我们能否从训练样本之间的关系寻求指导?
以文本分类数据为例,有 n n n个样本的数据集可以被定义为
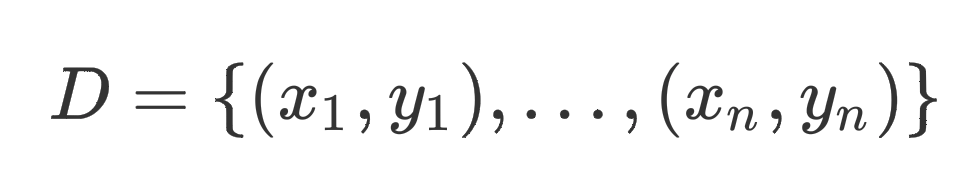
其中, y i ∈ c 1 , c 2 , … , c m y_i\in {c_1, c_2,…,c_m} yi∈c1,c2,…,cm表示共有 m m m类
CONTEXTUAL REPRESENTATION
我们首先需要一个指标判断两个句子是否相似。目前有两大类文本相似度计算方法,第一种是基于传统的符号表征,例如编辑距离、Jaccard Similarity Coeffieient以及Earth Mover’s Distance;第二种是将文本映射为稠密的向量,然后计算它们的向量相似度。第一种方法过于依赖token的表面信息,第二种方法需要使用外部数据对模型进行预训练,而这个外部数据和我们的任务数据可能不是同一领域的。因此作者基于Postive Pointwise Mutual Information (PPMI)提出了一个新的上下文表征方法
首先,我们用一个长度为2的滑动窗口统计数据集中所有token的共现矩阵 C C C。 C w i , w j C_{w_i, w_j} Cwi,wj表示前一个词是 w i w_i wi ,后一个词是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









