






本篇为「时间序列分析」系列推文的最后一篇。
1 协整的概念
「协整」(cointegrated)描述的是两个及以上时间序列变量之间的关系。
若一个时间序列变量的阶差分是平稳的,则称该变量为阶单整;若多个阶时间序列变量的线性组合的单整阶数小于,则称这些变量具有协整关系,记作;由线性组合的系数组成的向量称作「协整向量」(cointegrating vector)。
对于两个变量来说,若它们的线性组合的单整阶数小于它们自身,则它们的阶数必然相同;
对于多个变量来说,若它们的线性组合的单整阶数小于它们自身,但它们的阶数并不一定完全相等,则称它们具有「多重协整」(multicointegration)关系。举例来说,和是,记它们的一阶单整的线性组合为;若又和是,则、、三个变量的线性组合就可以是平稳的,即线性组合阶数小于它们各自的阶数。
2 误差修正模型
误差修正模型是协整关系的一个应用。以双变量为例,和从长期来看存在均衡关系,那么它们当期值会根据它们前期值之间的差进行修正。可以使用以下表达式进行描述:
402 Payment Required
式中是和的一个线性组合。假设和是平稳序列,则必然也是平稳的,即和存在协整关系。
在上式右侧加上和的滞后项:
则上式是一个VAR模型;
3 Engle-Granger检验
Engle-Granger协整检验的步骤如下:
「第一步」:确定每个变量的单整阶数。
ADF检验可以用来进行单位根检验。单位根个数即时间序列变量的单整阶数。
「第二步」:估计协整向量。
假设和具有协整关系。因为和的线性组合是平稳序列,即,也即,因此可以使用OLS方法估计协整向量。
为常数,不影响单整阶数;模型残差的单整阶数也就是线性组合后的单整阶数。
采用DF或ADF的形式对残差进行单位根检验:
虽然形式相同,但协整检验的临界值与DF或ADF检验不同,原因在于只是误差的估计值而非实际值。临界值可在以下链接中查看:http://citeseer.ist.psu.edu/viewdoc/download;jsessionid=64E6EE352E1DE391B0A75E071486F7F1?doi=10.1.1.456.4786&rep=rep1&type=pdf。
若的单位根个数少于和,则和具有协整关系。
「第三步」:估计误差修正模型。
若和具有协整关系,则可以建立误差修正模型。
因为和的线性组合等于,而是常数可以合并到模型的截距项中去,因此在模型中可以使用代替线性组合:
上式可以和VAR一样进行估计。
4 案例
这里的案例取自参考书的对应内容。示例数据可在公众号后台发送关键词「示例数据」获取,文件名为134.Coint6.xls。
读取示例数据,包括y、z、w三个变量:
library(readxl)
data = read_xls("134.Coint6.xls")
matplot(data, type = "l")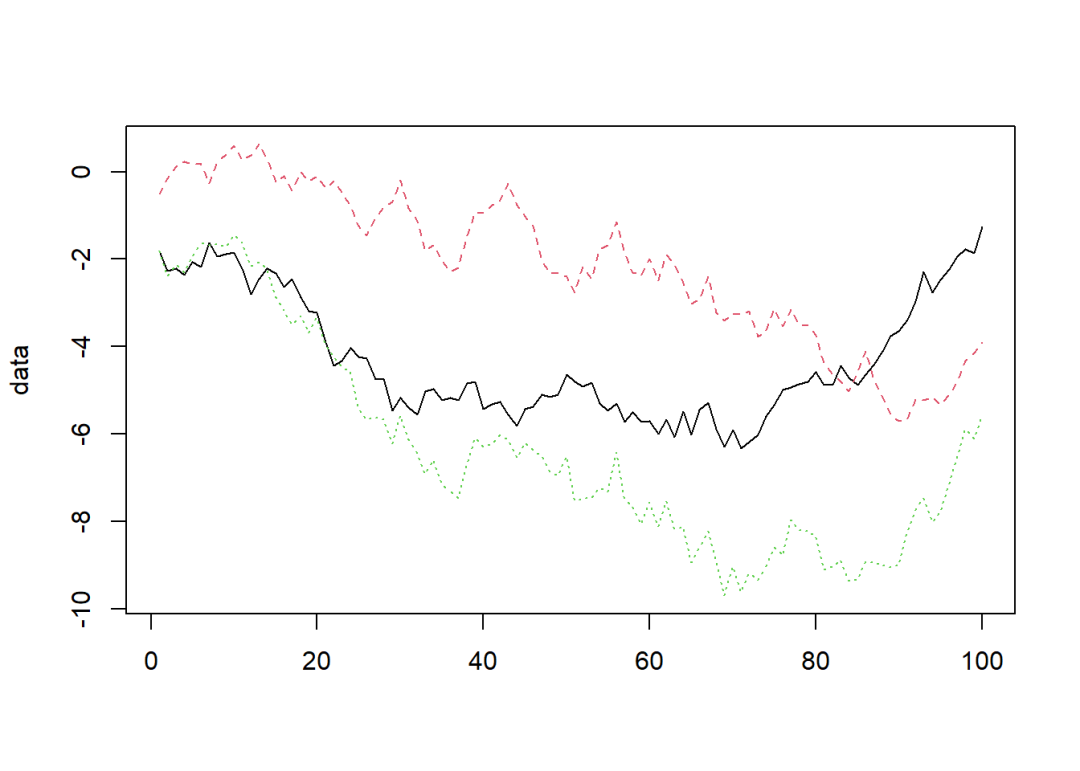
实际上,三个变量是通过模拟得到的,均为1阶单整。这里假设事先不知道其单整阶数,进行ADF检验。以变量y为例:
library(urca)
model.11 = ur.df(data$y, type = "drift",
lags = 8, selectlags = "BIC")
summary(model.11)
## Value of test-statistic is: -0.6457 0.2288
##
## Critical values for test statistics:
## 1pct 5pct 10pct
## tau2 -3.51 -2.89 -2.58
## phi1 6.70 4.71 3.86
dy = diff(data$y)
model.12 = ur.df(dy, type = "drift",
lags = 8, selectlags = "BIC")
summary(model.12)
## Value of test-statistic is: -6.4483 20.8026
##
## Critical values for test statistics:
## 1pct 5pct 10pct
## tau2 -3.51 -2.89 -2.58
## phi1 6.70 4.71 3.86
根据ADF检验可知,
y含有单位根,而一阶差分dy是平稳的,因此可以判断y的单整阶数为1;ADF检验请参考本系列的两篇推文:时间序列分析(6)| DF检验;时间序列分析(7)| ADF检验
使用OLS方法估计协整向量:
model.1 = lm(y ~ z + w, data = data)
summary(model.1)
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.04843 0.08422 -0.575 0.567
## z -0.92731 0.02434 -38.095 <2e-16 ***
## w 0.97688 0.01827 53.463 <2e-16 ***
model.2 = lm(z ~ y + w, data = data)
summary(model.2)
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.05896 0.08788 0.671 0.504
## y -1.01082 0.02653 -38.095 <2e-16 ***
## w 1.02549 0.01570 65.324 <2e-16 ***
model.3 = lm(w ~ y + z, data = data)
summary(model.3)
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.08524 0.08449 -1.009 0.316
## y 0.99007 0.01852 53.463 <2e-16 ***
## z 0.95347 0.01460 65.324 <2e-16 ***对残差进行单位根检验:
e3 = residuals(model.3)
plot(e3, type = "l")
summary(ur.df(e3, lags = 8, selectlags = "BIC"))
## Value of test-statistic is: -5.2984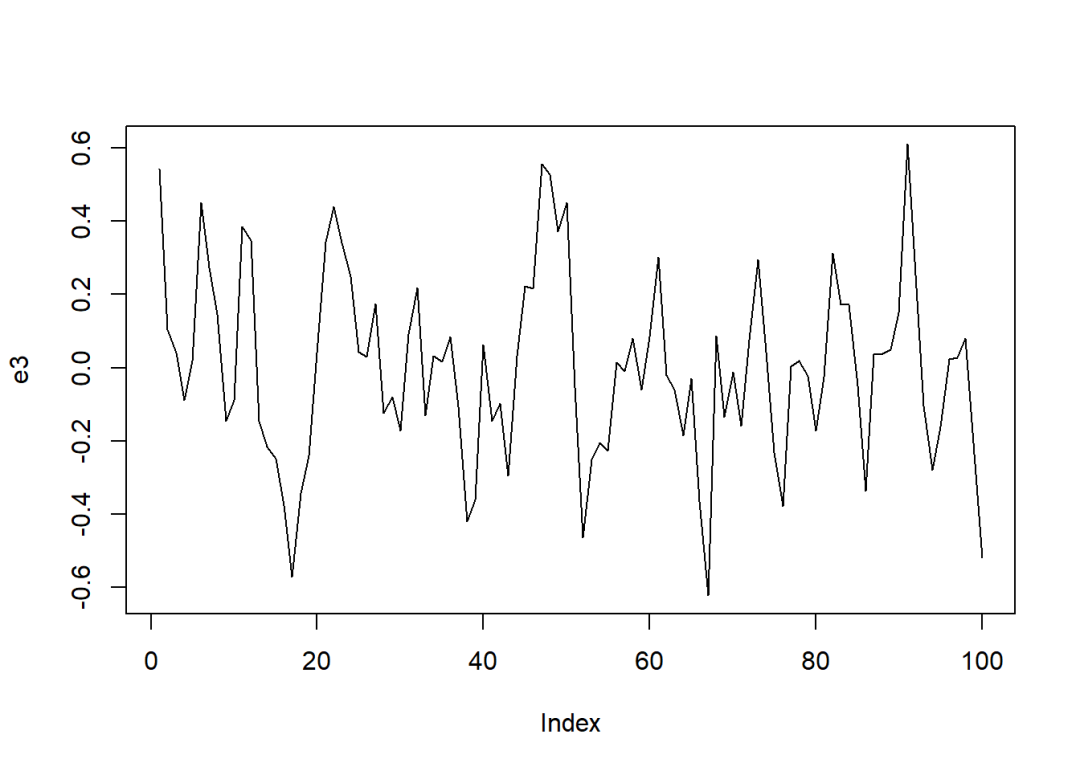
本例中的5%显著水平下的临界值为-3.828,因此可以拒绝存在单位根的原假设,即可以认为
e3是平稳序列。
建立误差修正模型并估计:
library(vars)
d.data = apply(data, 2, diff) # 差分
colnames(d.data) <- c("dy", "dz", "dw")
model = VAR(d.data, p = 1, type = "const",
exogen = e3[1:99])
## Estimated coefficients for equation dy:
## =======================================
## Call:
## dy = dy.l1 + dz.l1 + dw.l1 + const + exo1
##
## dy.l1 dz.l1 dw.l1 const exo1
## 0.178276649 0.312995255 -0.367720385 0.006065021 0.417973964
##
##
## Estimated coefficients for equation dz:
## =======================================
## Call:
## dz = dy.l1 + dz.l1 + dw.l1 + const + exo1
##
## dy.l1 dz.l1 dw.l1 const exo1
## 0.14593872 0.26246246 -0.31262789 -0.04221498 0.07409731
##
##
## Estimated coefficients for equation dw:
## =======================================
## Call:
## dw = dy.l1 + dz.l1 + dw.l1 + const + exo1
##
## dy.l1 dz.l1 dw.l1 const exo1
## 0.1557652 0.3012198 -0.4195309 -0.0398010 -0.0690757

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









