







线性回归求解的两种表示(最小化均方误差和基于高斯分布的极大似然估计) - 知乎【式3 ,4不是很理解,有点模糊】
----------------------------2022年11月26日16:34:05-----------------------------------------
【模式识别】最小风险贝叶斯决策_番茄发烧了的博客-CSDN博客_最小风险贝叶斯决策
概率学派和统计学派
对于概率看法不同:频率学派和贝叶斯学派 =-=有趣
摘一些有趣的东西:
【链接2】
① 频率学派
他们认为世界是确定的。他们直接为事件本身建模,也就是说事件在多次重复实验中趋于一个稳定的值p,那么这个值就是该事件的概率。
他们认为模型参数是个定值,希望通过类似解方程组的方式从数据中求得该未知数。这就是频率学派使用的参数估计方法-极大似然估计(MLE),这种方法往往在大数据量的情况下可以很好的还原模型的真实情况。
② 贝叶斯派
他们认为世界是不确定的,因获取的信息不同而异。假设对世界先有一个预先的估计,然后通过获取的信息来不断调整之前的预估计。 他们不试图对事件本身进行建模,而是从旁观者的角度来说。因此对于同一个事件,不同的人掌握的先验不同的话,那么他们所认为的事件状态也会不同。
他们认为模型参数源自某种潜在分布,希望从数据中推知该分布。对于数据的观测方式不同或者假设不同,那么推知的该参数也会因此而存在差异。这就是贝叶斯派视角下用来估计参数的常用方法-最大后验概率估计(MAP),这种方法在先验假设比较靠谱的情况下效果显著,随着数据量的增加,先验假设对于模型参数的主导作用会逐渐削弱,相反真实的数据样例会大大占据有利地位。极端情况下,比如把先验假设去掉,或者假设先验满足均匀分布的话,那她和极大似然估计就如出一辙了。
经验风险最小化与结构风险最小化是对于损失函数而言的。可以说经验风险最小化只侧重训练数据集上的损失降到最低;而结构风险最小化是在经验风险最小化的基础上约束模型的复杂度,使其在训练数据集的损失降到最低的同时,模型不至于过于复杂,相当于在损失函数上增加了正则项,防止模型出现过拟合状态。这一点也符合奥卡姆剃刀原则:如无必要,勿增实体。
① 极大似然估计(MLE)
-她是频率学派模型参数估计的常用方法。
-顾名思义:似然,可以简单理解为概率、可能性,也就是说要最大化该事件发生的可能性
-她的含义是根据已知样本,希望通过调整模型参数来使得模型能够最大化样本情况出现的概率。
② 最大后验概率估计(MAP)
-她是贝叶斯派模型参数估计的常用方法。
-顾名思义:就是最大化在给定数据样本的情况下模型参数的后验概率
-她依然是根据已知样本,来通过调整模型参数使得模型能够产生该数据样本的概率最大,只不过对于模型参数有了一个先验假设,即模型参数可能满足某种分布,不再一味地依赖数据样例(万一数据量少或者数据不靠谱呢)。
最大后验估计相对于最大似然估计可以看作多了参数的直接观测值。
【链接3】
用均方误差最小化求解线性回归,和假设预测误差符合高斯分布,然后利用高斯分布的极大似然估计求解线性回归,最后得到的结果相同
【链接4】
正则化项(解靠近零,模型简单),l1范数(解稀疏)和l2范数(解平滑)对应的其实是拉普拉斯分布和正态分布取对数的表现
【链接5】

这个很简单,漂亮啊,之前只是机械的记忆,现在可以稍微真正理解一下【公式推导真的魅力】
朴素贝叶斯就是利用最小化错误率来做的,其本质是在求类条件概率时,假设
是相互独立的【不然计算量太大了没法搞吖】。之前PR的作业题就是假设类条件概率符合二维正态分布来求的决策平面【决策平面说的高大上,其实就只是下面提到的后验概率相等的点(高维简称面)】
对于最小错误率规则,确定了最小错误率也就确定了决策边界。也就是两个后验概率相等的点。
解释:这里说的一开始没读懂,但是其意思就是说x<b时,x属于w1,反之属于w2.(这里针对线性,非线性无非就是多了几个分界点,分段说一下即可)
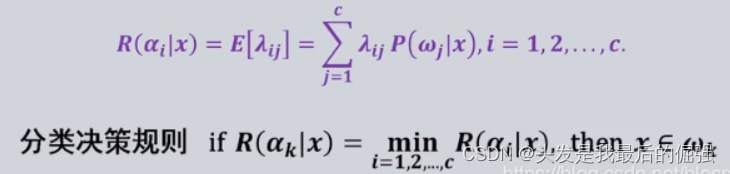
流感的例子很清晰,也告诉我们其实最小风险错误率就是在错误率上加了权重(风险),错误率是多种概率的求和(可以说是全部概率的求和,正确的那个可以风险给0不就好了嘛【诶!果然就是这样】)。
文章最后对于协方差,先验概率的分类讨论没有细看,暂时用不到吧应该【侥幸,主要是有点看不进去】














 3740
3740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









