







前言:
激动的搓搓小手,从python基础到前端知识,经过一些列的打基础学习之后,终于要正式开启爬虫之旅,让我们一起由浅入深的学习吧~~
1. requests 概述
requests 作为一个专门为人类编写的 HTTP 请求库,其易用性很强,因此在推出之后就迅速成为 Pthon 中首选的 HTTP请求库。requests 库的最大特点是提供了简单易用的 API,让编程人员可以轻松地提高效率。
由于 requests 不是 Python 的标准库,因此在使用之前需要进行安装:
pip install requests(注意要加s,不然也会下载,但是啥也不是)>
通过 requests 可以完成各种类型的 HTT 请求,包括 HTTP、HTTPS、HTTP1.0、HTTP1.1 及各种请求方法。requests 库支持的HTTP 方法,可以理解为requests是对HTTP的封装。
requests支持的请求方法
| 请求方式 | 描述 |
| get | 发送一个 GET 请求,用于请求页面信息 |
| options | 发送一个 OPTIONS 请求,用于检查服务器端相关信息 |
| head | 发送一个 HEAD 请求,类似于 GET 请求,但只请求页面的响应头信息 |
| post | 发送一个 POST 请求,通过 body 向指定资源提交用户数据 |
| put | 发送一个 PUT 请求,向指定资源上传最新内容 |
| patch | 发送一个 PATCH 请求,同 PUT 类似,可以用于部分内容更新 |
| delete | 发送一个 DELETE 请求,向指定资源发送一个删除请求 |
requests 其实就是模拟浏览器封装一个http请求协议的字符串,所有的参数都是在服务于这个字符的构建;可以没有请求参数,可以没有请求体、也可以没有请求头,但必须有请求方式和url(即请求网址)。
>
请求方法有很多,具体使用哪一种请求方式呢?
这就需要看要爬取的网站,它的请求方式是什么,我们就用什么
>
如何查看请求方式与请求网址?
如下截图:进入淘宝网的首页,打开F12 -> 网络 ->点开taobao.com -> 标头里就会显示

2. requests的请求参数
请求头参数
常见的请求头参数:
● Host:指定请求的主机名和端口号。
● User-Agent:指定发起请求的用户代理(通常是浏览器)的信息。
● Accept:指定客户端能够接受的响应内容类型。
● Accept-Language:指定客户端能够接受的响应内容的语言。
● Accept-Encoding:指定客户端能够接受的响应内容的压缩算法。
● Referer:指定请求的来源页面的URL。
● Cookie:指定客户端的Cookie信息。
● Authorization:指定客户端的身份验证凭证,如基本认证或Bearer令牌。
● Content-Type:指定请求体的媒体类型。
● Content-Length:指定请求体的长度。
-------------------------------------------------------------------------------------------------------------------------
其中,爬虫一般最常用的是:
★ User-Agent:简称UA头
★ Referer:查询参数
★ Cookie:
-------------------------------------------------------------------------------------------------------------------------
为什么需求用到请求头参数?
前面有讲到requests是程序模拟封装一个http请求,大部分网站都需要特定的一些请求头参数,来识别是人工、还是程序来访问,如果没有该网站需要的请求参数,即默认你是代码程序,我们就拿不到想要的信息。
>
所以一起来学习一下反爬吧~~
★ UA反爬

User-Agent,简称UA头
● UA反爬是一种最简单的反爬方式,User-Agent是请求头(header)中最著名的一个参数
● ua反爬常用于get请求,参数查询。
ua反爬示例:
没有设置反爬的的网站,可以轻松获取到文本文件和图片、视频(如下requests响应的代码示例)。
>
上面的百度首页截图中,我们看到请求头里是有UA这个参数的。
简单做个对比,例如爬取百度首页的html文件:
以下代码中参数仍只有url的效果
import requests
res = requests.get("https://www.baidu.com/")
res.encoding=" utf8"
with open("baidu.html", "w",encoding="utf8") as f:
f.write(res.text)代码执行后,看看生成的html文件:

很明显,没有爬取到完整的html信息
下面我们修改代码:将get参数中添加UA(直接从F12 -> network -> 请求表头里复制ua)
import requests
res = requests.get("https://www.baidu.com/",
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"})
with open("baidu.html", "w",encoding="utf8") as f:
f.write(res.text)
代码执行后,再用浏览器打开html文件:与我们直接访问百度首页就是一样的,说明爬取成功

★ Referer反爬(防盗链)
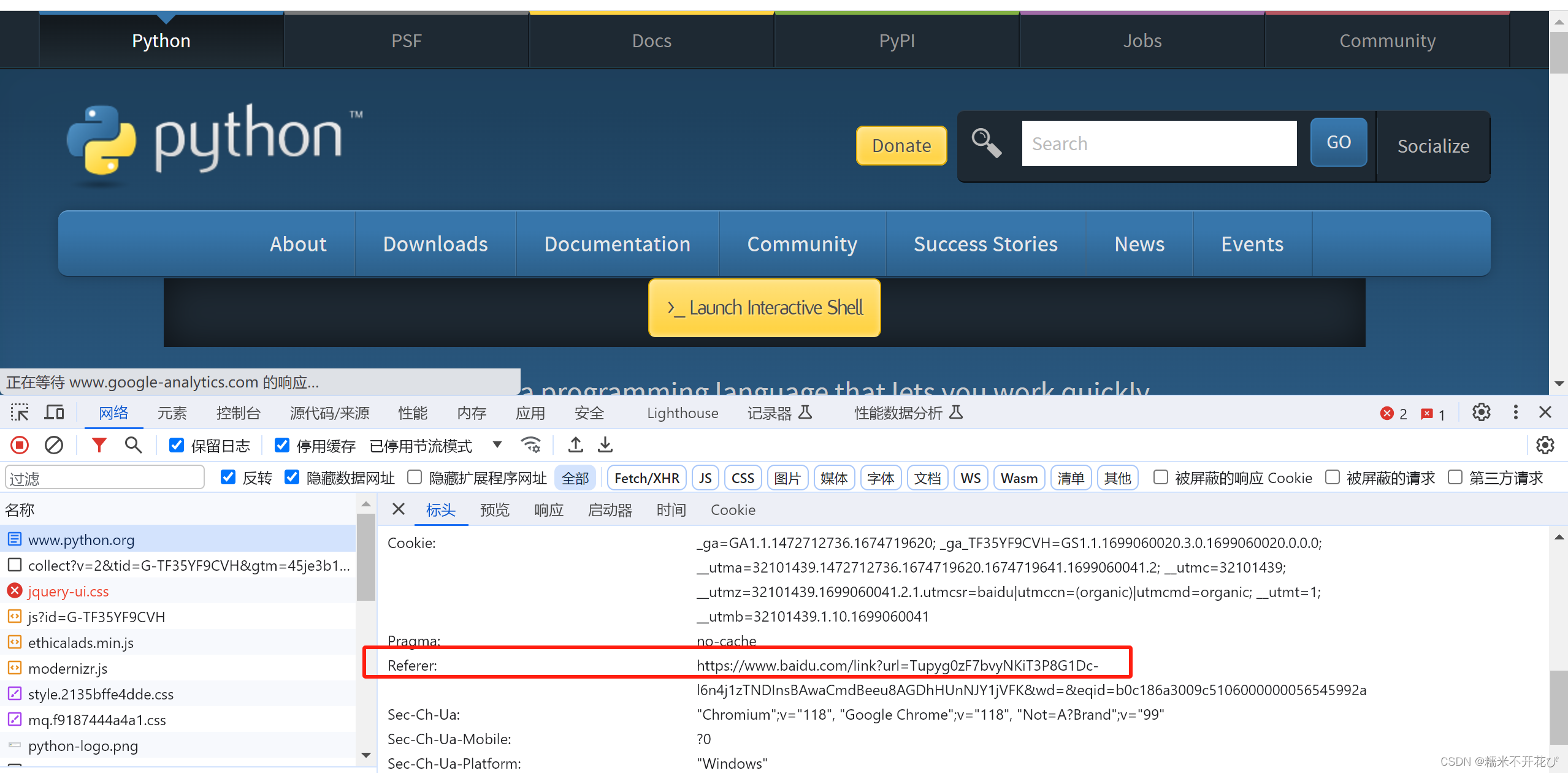
● Referer是请求头中常见的一个参数,指的是请求网址的来源
● Referer反爬常用于get请求,参数查询。
例如上面截图:
我从百度中搜索“python官网”然后点击访问,Referer会显示“www.baidu.com/link?url”
>
Referer有什么用?
比如说一家公司在不同的网站平台上做广告投放,想要知道每个平台的投入与产出比,就可以从访问来源中统计。
-------------------------------------------------------------------------------------------------------------------------
下面来看一个豆瓣的案例: https://movie.douban.com/explore
Referer反爬示例:
在F12 -> 网络,点击全部时,会看到一堆请求,我们要的是这个网站里的所有数据
之前已经学习过ajax异步请求,所以在f12里筛选一下“Fatch/XHR”,能看到有一个ajax的请求url
我们直接用ajax的的url,直接拿数据,爬下来后就不用解析了(ajax是纯数据)

当我的参数有ajax的请求url时,并且加上ua头时:
返回信息显示,使用了不正确的请求方式,因此没有获得ajax数据

可以看到,无论从页面点击什么,都会带着一个ajax的请求头,
即“https://movie.douban.com/explore”

所以程序中也是一样,想要拿到所有的ajxa数据,也需要带着ajax的请求头,完整代码如下:
import requests
#Referer反爬:
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Referer": "https://movie.douban.com/explore" }
res = requests.get("https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%7D&uncollect=false&tags=",
headers=headers )
# print(res.text) #直接得到一个json格式的字符串
#方式1:进行反序列化,转为字典格式;不推荐
# import json
# data = json.loads(res.text)
# print("data字典:",data)
#反序列化方式2:可以不用import json
print(res.json())
print(type(res.json())) #查看数据类型
经过以上步骤,得到了json或者字典,但是内容太多,很多是我们不需要的
接下来开始数据解析:
import requests
import json
#Referer反爬:
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Referer": "https://movie.douban.com/explore" }
res = requests.get("https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%7D&uncollect=false&tags=",
headers=headers )
# print(res.text) #直接得到一个json格式的字符串
#方式1:进行反序列化,转为字典格式;不推荐
# data = json.loads(res.text)
# print("data字典:",data)
#反序列化方式2:可以不用import json
# print(res.json())
# print(type(res.json()))
#数据解析:提取电影名
for item in res.json()["items"]:
if item.get("title"):
print(item.get("title"))
#输出:
生命 都浪费在青春上
当邪恶潜伏时
惩罚
吹响悠风号 合奏比赛篇
本日公休
《视与听》250佳(Sight & Sound Poll 2012 Critics’ Top 250 Films)
神奇的莫里斯
戏梦空间params参数
params是将请求的查询参数放在请求头中
params参数指的就是f12--载荷里的查询字符串参数
>
例如:
接着上面的代码,在豆瓣网将电影“类型”选为喜剧,得到一个新的喜剧对应的ajax的请求url

import requests
import json
url = "https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%22%E7%B1%BB%E5%9E%8B%22:%22%E5%96%9C%E5%89%A7%22%7D&uncollect=false&tags=%E5%96%9C%E5%89%A7"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Referer": "https://movie.douban.com/explore" }
res = requests.get(url,headers=headers,)
##数据解析:提取排行前20的喜剧电影
for item in res.json()["items"]:
if item.get("title"):
print(item.get("title"))
#输出:
高分经典喜剧片榜
二手杰作
芭比
疯狂动物城
我不是药神
寻梦环游记
学爸
绿皮书
你好,李焕英
怦然心动
哪吒之魔童降世
三傻大闹宝莱坞
让子弹飞
功夫
触不可及
大话西游之大圣娶亲
关于我和鬼变成家人的那件事
满江红
飞屋环游记
宇宙探索编辑部但是,我又想获取悬疑电影怎么办?又重新去改一个ajax对应的悬疑请求url吗?
这时候简单的方式来了,可以使用params查询参数(如上f12--载荷请求截图)
想要获取什么类型的电影,只需要改查询参数tags对应的属性值即可,更加灵活方便
import requests
import json
#url只需要截止到?,问号后面的查询参数
url = "https://m.douban.com/rexxar/api/v2/movie/recommend?"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Referer": "https://movie.douban.com/explore" }
res = requests.get(url,headers=headers,
params={#查询参数,需要写成键值对
"count": "20",
"tags": "悬疑"} )
#数据解析:提取排行前20的悬疑电影
for item in res.json()["items"]:
if item.get("title"):
print(item.get("title"))
#输出:
高分经典悬疑片榜
拯救嫌疑人
电锯惊魂10
消失的她
一个和四个
最后的真相
盗梦空间
关于我和鬼变成家人的那件事
满江红
看不见的客人
唐人街探案3
唐人街探案
唐人街探案2
哈利·波特与火焰杯
误杀
禁闭岛
消失的爱人
威尼斯惊魂夜
蝴蝶效应
扬名立万请求体参数
模拟请求体发送数据
上面的栗子中,都是简单的get请求获取数据
post也是一种常见的请求,根据之前的http协议学习:
我们了解到,post请求是将请求参数放在请求头中,将请求数据放在请求体中的,所以爬取网站时,如果该网站时post请求,那么在代码程序中,我们也需要响应的请求体数据。
向服务器发送数据,常使用的是post请求方法
-------------------------------------------------------------------------------------------------------------------------
来看个栗子:使用data参数将请求数据放在请求体
有道智云.AI开发平台,文本翻译_机器翻译_在线翻译-有道智云AI开放平台
使用在线翻译,点击“翻译”按钮时,浏览器同步发起一个ajax的post请求

#post请求
import requests
res = requests.post("https://aidemo.youdao.com/trans",
params = {},
headers = {},
data = {
"q":" China",
"from": "Auto",
"to": "Auto"
})
print("josn值:",res.text)
print(res.json()["web"][0]["value"]) #字符串切片,取翻译后的值
#输出:
josn值: {"returnPhrase":["China"],"query":" China","errorCode":"0","l":"en2zh-CHS","tSpeakUrl":"https://openapi.youdao.com/ttsapi?q=%E4%B8%AD%E5%9B%BD&langType=zh-CHS&sign=22B02CEC7A03D9012A265F9E3E1C323B&salt=1699076181277&voice=4&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false&osType=api","web":[{"value":["中国","瓷器","瓷料"],"key":"China"},{"value":["中国公开赛","中国网球公开赛","中国网球公然赛","附评语"],"key":"China Open"},{"value":["中国国际航空","中国国际航空公司","中国国航","中国航空"],"key":"Air China"}],"requestId":"2b3ec7a4-9fb1-4774-89e9-422b39794cf8","translation":["中国"],"mTerminalDict":{"url":"https://m.youdao.com/m/result?lang=en&word=+China"},"dict":{"url":"yddict://m.youdao.com/dict?le=eng&q=+China"},"webdict":{"url":"http://mobile.youdao.com/dict?le=eng&q=+China"},"basic":{"exam_type":["初中","高中","CET4","CET6","考研"],"us-phonetic":"ˈtʃaɪnə","phonetic":"ˈtʃaɪnə","uk-phonetic":"ˈtʃaɪnə","uk-speech":"https://openapi.youdao.com/ttsapi?q=+China&langType=en&sign=07EC79A260B03AE6B45765AC2D2067B7&salt=1699076181277&voice=5&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false&osType=api","explains":["n. 中国","adj. 中国的;中国制造的","n. (china) 瓷器","adj. (china) 瓷制的"],"us-speech":"https://openapi.youdao.com/ttsapi?q=+China&langType=en&sign=07EC79A260B03AE6B45765AC2D2067B7&salt=1699076181277&voice=6&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false&osType=api"},"isWord":true,"speakUrl":"https://openapi.youdao.com/ttsapi?q=+China&langType=en-USA&sign=07EC79A260B03AE6B45765AC2D2067B7&salt=1699076181277&voice=4&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false&osType=api"}
['中国', '瓷器', '瓷料']
利用requests模拟一个即使翻译软件功能:
import requests
wd = input("请输入翻译内容:")
res = requests.post("https://aidemo.youdao.com/trans",
params = {},
headers = {},
data = {
"q": wd,
"from": "Auto",
"to": "Auto"
})
print("josn值:",res.text)
print(res.json()["web"][0]["value"]) #字符串切片,取翻译后的值
#输出:
请输入翻译内容:今天天气不错
josn值: {"returnPhrase":["今天天气不错"],"query":"今天天气不错","errorCode":"0","l":"zh-CHS2en","tSpeakUrl":"https://openapi.youdao.com/ttsapi?q=It%27s+a+nice+day.&langType=en-USA&sign=12956283E1E8FBCFF6E584B90080B5FE&salt=1699076657102&voice=4&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false&osType=api","web":[{"value":["The weather is good today","Today's weather","Weather good today","It&rsquo"],"key":"今天天气不错"},{"value":["it's a nice day today"],"key":"这是今天天气不错"},{"value":["You look nice today"],"key":"你看今天天气不错啊"}],"requestId":"78c0fba4-43e8-4972-9208-1e420d358fbb","translation":["It's a nice day."],"mTerminalDict":{"url":"https://m.youdao.com/m/result?lang=zh-CHS&word=%E4%BB%8A%E5%A4%A9%E5%A4%A9%E6%B0%94%E4%B8%8D%E9%94%99"},"dict":{"url":"yddict://m.youdao.com/dict?le=eng&q=%E4%BB%8A%E5%A4%A9%E5%A4%A9%E6%B0%94%E4%B8%8D%E9%94%99"},"webdict":{"url":"http://mobile.youdao.com/dict?le=eng&q=%E4%BB%8A%E5%A4%A9%E5%A4%A9%E6%B0%94%E4%B8%8D%E9%94%99"},"basic":{"explains":["The weather is good today.","It's a fine day today.","Today is a nice day."]},"isWord":true,"speakUrl":"https://openapi.youdao.com/ttsapi?q=%E4%BB%8A%E5%A4%A9%E5%A4%A9%E6%B0%94%E4%B8%8D%E9%94%99&langType=zh-CHS&sign=12EAA2E153DC61191296F3163F0C9969&salt=1699076657102&voice=4&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false&osType=api"}
['The weather is good today', "Today's weather", 'Weather good today', 'It&rsquo']★ cookie反爬
简单来说,Cookie就是服务器存储在客户端的一种方式,用于跟踪和识别用户。它可以存储各种类型的数据,如用户的身份认证信息、用户的偏好设置、购物车内容等。
当客户端发送请求时,会自动将相应的Cookie信息附加到请求头中,服务器通过读取这些Cookie信息来识别和追踪用户。服务器可以根据Cookie中的数据,提供个性化的服务,如自动登录、记住用户的偏好设置等。
需要注意的是,Cookie是存储在客户端的,因此它可以被客户端修改或删除。服务器需要对Cookie进行适当的验证和保护,以确保数据的完整性和安全性。
Cookie应用demo
抓取雪球网股票信息:https://xueqiu.com/
# Cookie应用demo:抓取雪球网股票信息
import requests
url = 'https://stock.xueqiu.com/v5/stock/batch/quote.json?symbol=SH000001,SZ399001,SZ399006,SH000688,SH000016,SH000300,BJ899050,HKHSI,HKHSCEI,HKHSTECH,.DJI,.IXIC,.INX'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Referer":"https://xueqiu.com/",
}
res = requests.get(url,headers=headers)
print(res.text)
#输出:
{"error_description":"遇到错误,请刷新页面或者重新登录帐号后再试","error_uri":"/v5/stock/batch/quote.json","error_data":null,"error_code":"400016"}
代码中只参数只有url、ua头、Referer时,无法获取我们想要的ajax数据,提示需要登录
所以试试cookie,一般如果cookie不是动态的,就没啥问题
cookie可以写在外面,也可以直接写在get请求参数中,由于cookie太长,我就直接在外面写一个变量了:
# Cookie应用demo:抓取雪球网股票信息
import requests
url = 'https://stock.xueqiu.com/v5/stock/batch/quote.json?symbol=SH000001,SZ399001,SZ399006,SH000688,SH000016,SH000300,BJ899050,HKHSI,HKHSCEI,HKHSTECH,.DJI,.IXIC,.INX'
cookie = 'xq_a_token=e2f0876e8fd368a0be2b6d38a49ed2dd5eec7557; xqat=e2f0876e8fd368a0be2b6d38a49ed2dd5eec7557; xq_r_token=2a5b753b2db675b4ac36c938d20120660651116d; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTcwMDY5OTg3NSwiY3RtIjoxNjk5MDg2NDU2NTQ1LCJjaWQiOiJkOWQwbjRBWnVwIn0.Q107JIRxiX0Tz3IPqFLOfgnmMQWvx7ZZTv7hZYNOdKtgmwJsHiI880ukjFb2hvDAysZ91dY044fS4VUlhZZc7fw1IUPucVrHbX7OuANkG3DfbdLxapOaVXPvOdPj3rTc7Bjn4-hJdOmNelwfHAZhyU9LRftF6bpeVwy2rzBdFdFqo6OxUhodlDWPToWGQvAmpaK_E-nA4RK7M42wZ9tJgcLGhwpejuQG7qq9_1Hdll_hzJ9prJMLPuTSB_1O0N_CyLKD8p4WS5TbKRSVJ4SAuV7EqLyBD-Kl54HlIbsJ4oENNLi34PhEwScQ-eqGTV5xKlap98HNVzJb1UABpuUCRg; cookiesu=521699086503990; u=521699086503990; device_id=a7b6e84ed8003501929459cce54590c6; Hm_lvt_1db88642e346389874251b5a1eded6e3=1699086505; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1699086505'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Referer":"https://xueqiu.com/",
"cookie":cookie,
}
res = requests.get(url,headers=headers)
print(res.text)
#输出:
{"data":{"items":[{"market":{"status_id":8,"region":"CN","status":"休市","time_zone":"Asia/Shanghai","time_zone_desc":null,"delay_tag":0},"quote":{"symbol":"SH000001","code":"000001","exchange":"SH","name":"上证指数","type":12,"sub_type":null,"status":1,"current":3030.8,"currency":"CNY","percent":0.71,"chg":21.39,"timestamp":1698994800000,"time":1698994800000,"lot_size":100,"tick_size":0.01,"open":3012.4654,"last_close":3009.4058,"high":3040.9807,"low":3012.4654,"avg_price":3030.8,"volume":26848634700,"amount":3.293004775006E11,"turnover_rate":0.62,"amplitude":0.95,"market_capital":4.699311E13,"float_market_capital":2.523988507636488E13,"total_shares":15505183449,"float_shares":4346738837349,"issue_date":661536000000,"lock_set":0,"current_year_percent":-1.89},"others":{"cyb_switch":true},"tags":[]},……此处省略这次通过cookie拿到了ajax数据,接下来开始解析json,提取想要的数据了,这里不再进行演示
3. requests的响应信息
响应基本信息
基本的响应信息:
● print(respone.status_code) :查看响应状态码
● print(respone.headers) :查看响应头信息
● print(respone.text) :查看响应体,文本形式
● print(respone.text) :查看响应体,json形式
>
一个简单的示例1:针对淘宝网的访问及信息爬取
除了url,没有任何其他参数就拿到了响应体,说明没有设置任何反爬
import requests
res = requests.get("https://www.taobao.com")
print(type(res)) #查看类型
print(res.status_code) #查看响应状态码,200请求成功,但是不一定代表返回数据是对的
print("响应头:",res.headers) #查看响应头信息
# print(res.text) #查看响应体
print(res.content) #查看响应体,获取字节数据,需要解码
#将响应头信息写入一个html文件
with open("taobao.html","w",encoding="utf8") as f:
f.write(res.text)
#输出:
<class 'requests.models.Response'>
200
响应头: {'Server': 'Tengine', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Date': 'Thu, 02 Nov 2023 21:43:36 GMT', 'Vary': 'Accept-Encoding, Ali-Detector-Type, X-Host, Accept-Encoding, Origin', 'x-server-id': '28c3d6b2523ca52c32ad72931842b19a2e5405bb8534349f9a42b88811b0899418860f5b9ea54579', 'x-air-hostname': 'air-ual033061022013.center.na610', 'x-air-trace-id': 'dde5cb1816989614160005005e', 'Cache-Control': 'max-age=0, s-maxage=140', 'x-node': 'b44e142ceed1a8733ed2bd14af20ac84', 'x-eagleeye-id': 'dde5cb1816989614160005005e', 'x-retmsg': 'ok', 'x-content-type': 'text/html; charset=utf-8', 'streaming-parser': 'open', 'x-retcode': 'SUCCESS', 'etag': 'W/"17924-v6YjhaxB8NyxVo/ldSbpSvOUclk"', 'x-readtime': '116', 'x-via': 'cn4354.l1, ens-cache7.cn4354, l2ea120-8.l2, cache5.l2ea120-8, wormholesource033039148051.center.na610', 'x-air-source': 'proxy', 'x-xss-protection': '1; mode=block', 'Strict-Transport-Security': 'max-age=31536000', 'Ups-Target-Key': 'air-ual.vipserver', 'X-protocol': 'HTTP/1.1', 'EagleEye-TraceId': 'dde5cb1816989614160005005e', 'Ali-Swift-Global-Savetime': '1698961416', 'Via': 'cache5.l2ea120-8[223,181,200-0,C], cache37.l2ea120-8[183,0], cache10.cn5692[0,0,200-0,H], cache21.cn5692[2,0]', 'Age': '20', 'X-Cache': 'HIT TCP_MEM_HIT dirn:11:223312708', 'X-Swift-SaveTime': 'Thu, 02 Nov 2023 21:43:36 GMT', 'X-Swift-CacheTime': '140', 'x-air-pt': 'pt0', 'Timing-Allow-Origin': '*', 'EagleId': '7084249716989614367663592e'}响应头信息写入执行后,自动生成html文件:

编码和解码
respone.text:表示获取字符、文本文件;常见的html文件,网页的响应信息都属于文本文件
respone.content:表示获取字节、二进制文件;常见图片、视频、音频都属于二进制文件
下载图片、视频
一个简单的示例:下载百度单张百度图片
#百度图片获取:百度上图片右键-复制图片地址
res = requests.get("https://img1.baidu.com/it/u=2740509008,2914545216&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=666")
print(res.text)
#写入时就要用wb,不能再用w
with open("壁纸.jpg","wb") as f:
f.write(res.content)
#输出:这里输出信息省略,是一堆特别长的二进制……以文本文件查看时,一堆乱码:

重新修改代码:
#百度图片获取:百度上图片右键-复制图片地址
res = requests.get("https://img1.baidu.com/it/u=2740509008,2914545216&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=666")
# print(res.text) #打印后是一堆乱码
print(res.content) #因为图片属于二进制文件,所以只能获取字节信息
#写入时就要用wb,不能再用w
with open("壁纸.jpg","wb") as f:
f.write(res.content)
获取视频文件,方式与获取图片一样:
获取视频的url时,直接f12--元素中,查找.mp4可以快速找到对应视频的url
这样就将一个视频下载到本地了,直接用本地的视频软件打开即可观看















 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









