






一维特征输入实例
1、反向传播
先进行前馈运算(forward),然后反向传播算出损失函数对权重的倒数(即梯度),进而可以进行更新权重w。
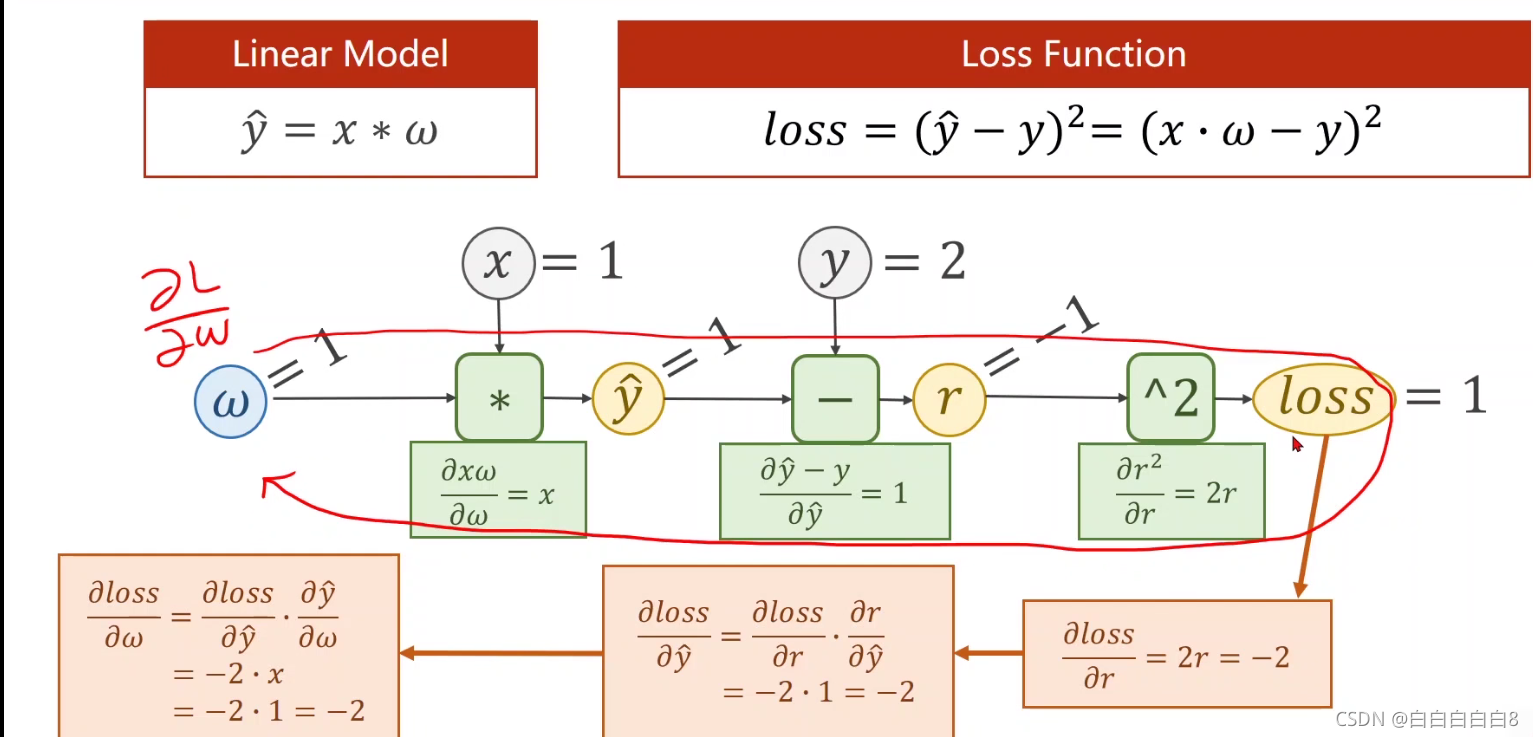
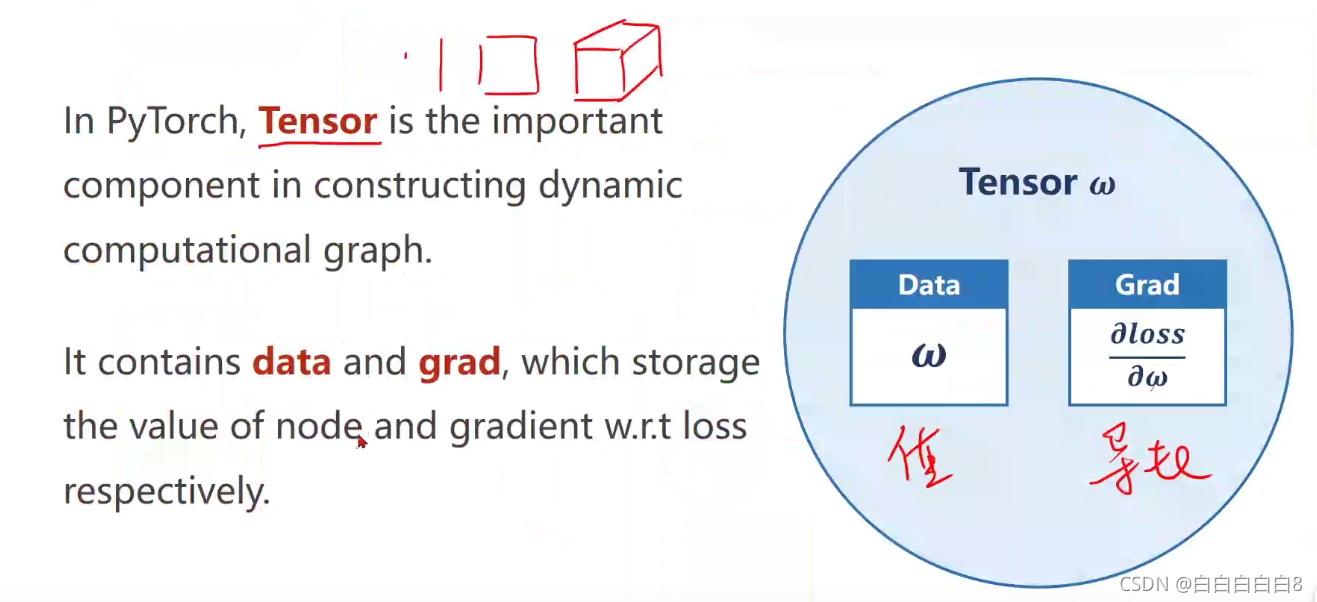
在PyTorch中,张量是构造动态计算图的重要组成部分,它包含data和grad,分别存储nodę和梯度w.rt损失的值。
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0]) # 张量
w.requires_grad = True # 计算梯度
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print('predict (before training)', 4, forward(4).item())
for i in range(100):
for x, y in zip(x_data, y_data):
ls = loss(x, y) # 张量,取值需要用ls.item()
ls.backward()
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_() # 通过backwaard()计算得到的梯度将被累加。所以更新后,请记住将梯度设置为零!!!
print("progress:", i, ls.item())
print('predict (after training)', 4, forward(4).item())
2、Logistic Regression(逻辑斯蒂回归)
分类问题(计算每种标签y的概率)
| x(hours) | y(pass/fail) |
| 1 | 0 (fail) |
| 2 | 0(fail) |
| 3 | 1(pass) |
| 4 | ? (需要进行预测) |
函数值在(0,1)之间
交叉熵(Cross-entropy) 用以计算两个分布之间的差异性的大小

Loss Function for Binary Classification(二分类的损失函数)
Mini-Batch Loss Function for Binary Classification(二元分类的小批量损失函数)

import torch.nn.functional as F
import torch
# Prepare dataset
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
# Design model using Class inherit from nn. Module
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1) # input and output is 1 dimension
def forward(self, x):
y_pred = F.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
# Construct loss and optimizer using PyTorch API
criterion = torch.nn.BCELoss(size_average=False) # BCELoss 二分类交叉熵损失函数 (Binary cross entropy loss function)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 返回一个优化器类。
# Training cycle forward, backward, update
for i in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print('第' + str(i) + '轮,loss=' + str(loss.item()))
optimizer.zero_grad()
loss.backward()
optimizer.step() # 进行一次优化
多维特征输入实例
分类问题dataset:

逻辑斯蒂模型:
单个sample:

mini-batch(N sample):
import numpy as np
import pandas as pd
import torch
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
# 1、导入数据
xy = np.loadtxt('./dataset/diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
# 2、模型设计
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x)) # 第一层输出作为第二层输入
x = self.sigmoid(self.linear3(x)) # 第二层输出作为第三层输入
return x
# 实例化模型
model = Model()
# 3、定义 损失函数和优化器
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for i in range(100):
# forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(i, loss.item())
# backward
optimizer.zero_grad() # 梯度置零,也就是把loss关于weight的导数变成0.
loss.backward()
optimizer.step()
以上用到的数据集链接: https://pan.baidu.com/s/1Z_JlE4R6psuFb0G1Uq4MXA
提取码: 3uxw
加载数据集
DataLoader: batch size--n, shuffle=True

import numpy as np
import pandas as pd
from torch.utils.data import Dataset # Dataset是一个抽象类,我们可以定义从这个类继承的类。
from torch.utils.data import DataLoader # DataLoader是一个类,用于帮助我们在Py Torch中加载数据。
import torch
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
# 1、导入数据
# 自定义diabetesDataSet类,用以继承Dataset抽象类
class diabetesDataSet(Dataset):
def __init__(self, filepath):
super(diabetesDataSet, self).__init__()
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # 读取矩阵第一维度的长度,即样本数量
self.x_data = torch.from_numpy(xy[:, :-1]) # 截取矩阵全部行,除最后一列外的所有列
self.y_data = torch.from_numpy(xy[:, [-1]]) # 截取矩阵全部行,以及最后一列
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
data = diabetesDataSet('./dataset/diabetes.csv') # 实例化类
train_data = DataLoader(dataset=data, shuffle=True, batch_size=32, num_workers=2) # 加载器进行初始化
# 2、模型设计
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x)) # 第一层输出作为第二层输入
x = self.sigmoid(self.linear3(x)) # 第二层输出作为第三层输入
return x
# 实例化模型
model = Model()
# 3、定义 损失函数和优化器
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_data, 0): # 下标从0开始 [(0,item1),(1,item2),...]
input_data, label = data
y_pred = model(input_data)
loss = criterion(y_pred, label)
print(epoch, i, loss.item())
# backward
optimizer.zero_grad()
loss.backward()
# update
optimizer.step()
















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











