







序列到序列–视频到文本
摘要
现实世界的视频往往具有复杂的动态性;生成开放域视频描述的方法应该对时间结构敏感,并且允许可变长度的输入(帧序列)和输出(字序列)。为了解决这个问题,我们提出了一种新的端到端序列对序列模型来生成视频字幕。为此,我们开发了递归神经网络,特别是LSTM,它在图像字幕生成方面显示了最先进的性能。我们的LSTM模型基于视频句子对进行训练,并学习将视频帧序列与单词序列相关联,以便在视频片段中生成事件描述。我们的模型自然能够学习框架序列的时间结构以及生成句子的序列模型,即。E语言模型。我们评估了我们模型的几个变体,这些变体在一组标准的YouTube视频和两个电影描述数据集(M-VAD和MPII-MD)上利用了不同的视觉特征。
1. 介绍
用自然语言文本描述视觉内容最近受到越来越多的关注,尤其是用一句话描述图像[8,5,16,18,20,23,29,40]。尽管视频描述在人机交互、视频索引和为盲人描述电影等方面有着重要的应用,但到目前为止,人们对它的关注较少。当图像描述处理可变长度的单词输出序列时,视频描述还必须处理可变长度的帧输入序列。视频描述的相关方法已通过整体视频表示[29,28,11]、帧集合[39]或固定数量输入帧的子采样[43]解决了可变长度输入问题。相比之下,本文提出了一种端到端训练的序列到序列模型,该模型能够学习输入序列中的任意时间结构。我们的模型是顺序到顺序的,从某种意义上说,它是按顺序读取帧并按顺序输出单词。在开放域视频中生成描述的问题很困难,这不仅是因为对象、场景、动作及其属性的多样性,还因为很难确定突出的内容并在上下文中适当地描述事件。为了了解什么是值得描述的,我们的模型从视频剪辑和用自然语言描述所描述事件的成对句子中学习。我们使用长短时记忆(LSTM)网络[12],这是一种递归神经网络(RNN),在语音识别[10]和机器翻译[34]等类似的序列到序列任务中取得了巨大成功。由于视频和语言固有的顺序性,LSTM非常适合生成视频中事件的描述。
这项工作的主要贡献是提出了一个新的模型,S2VT,它学习直接将一个帧序列映射到一个单词序列。图1描述了我们的模型。堆叠LSTM首先对帧逐个编码,将应用于每个输入帧的强度值的卷积神经网络(CNN)的输出作为输入。一旦所有帧都被读取,模型就会逐字生成一个句子。帧的编码、解码和单词表示是从并行语料库中联合学习的。为了对视频中通常显示的活动的时间方面进行建模,我们还计算了连续帧对之间的光流[2]。流量图像也通过CNN传递,并作为输入提供给LSTM。流CNN模型已被证明有利于活动识别[31,8]。
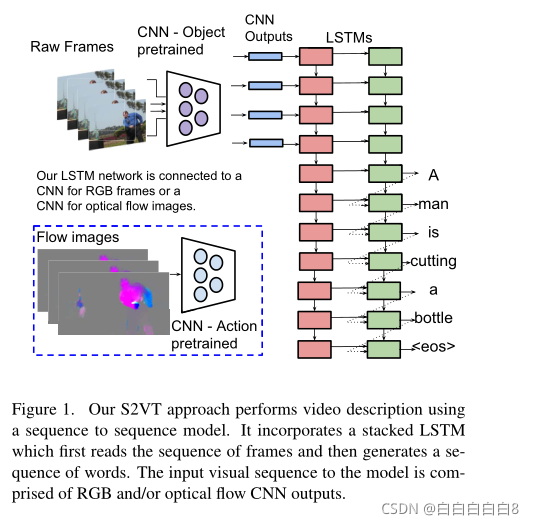
图1。我们的S2VT方法使用序列到序列模型执行视频描述。它包含一个堆叠的LSTM,该LSTM首先读取帧序列,然后生成一个单词序列。模型的输入视觉序列由RGB和/或光流CNN输出组成。
据我们所知,这是第一种使用一般序列到序列模型的视频描述方法。这使得我们的模型能够(a)处理可变数量的输入帧,(b)学习并使用视频的时间结构,(c)学习语言模型以生成自然的语法句子。我们的模型是联合学习和端到端学习的,结合了强度和视觉流输入,不需要明确的注意模型。我们证明了S2VT在三个不同的数据集上实现了最先进的性能,一个标准的Y ouTube语料库(MSVD)[3]和M-V AD[37]和MPII电影描述[28]数据集。我们的实现(基于Caffe[15]深度学习框架)可在github上获得。https://github. com/vsubhashini/caffe/tree/recurrent/examples/s2vt。
2. 相关工作
关于视频字幕的早期工作考虑使用元数据[1]标记视频,并将字幕和视频聚类[14,25,42]用于检索任务。以前的几种生成句子描述的方法[11,19,36]使用了两个阶段的管道,首先识别语义内容(主语、动词、宾语),然后基于模板生成句子。这通常涉及训练单个分类器来识别候选对象、动作和场景。然后,他们使用概率图形模型将视觉自信与语言模型相结合,以估计视频中最可能的内容(主语、动词、宾语、场景),然后使用这些内容生成句子。虽然这通过分离内容生成和表面实现简化了问题,但它需要选择一组相关的对象和动作来识别。此外,基于模板的句子生成方法不足以模拟人类描述中使用的丰富语言。使用哪些属性以及如何有效地组合它们以生成良好的描述。相反,我们的方法通过学习直接将视频映射到完整的人类提供的句子,同时学习以视觉特征为条件的语言模型,避免了内容识别和句子生成的分离。
我们的模型借鉴了[8,40]中的图像字幕生成模型。他们的第一步是通过从CNN中提取特征来生成图像的固定长度矢量表示。下一步学习将该向量解码为组成图像描述的单词序列。虽然原则上可以使用任何RNN来解码序列,但由此产生的长期依赖性可能会导致性能低下。为了缓解这个问题,LSTM模型被用作序列解码器,因为它们更适合于学习远程依赖关系。此外,由于我们使用可变长度视频作为输入,我们使用LSTM作为序列到序列转换器,遵循[34]的语言翻译模型。
在[39]中,LSTM用于通过汇集单个帧的表示来生成视频描述。他们的技术为视频中的帧提取CNN特征,然后平均汇集结果,得到代表整个视频的单一特征向量。然后,他们使用LSTM作为序列解码器,根据该向量生成描述。这种方法的一个主要缺点是,这种表示完全忽略了视频帧的顺序,并且无法利用任何时间信息。[8]中的方法还使用LSTM生成视频描述;然而,他们采用了一种两步方法,即使用CRF获得活动、对象、工具和位置的语义元组,然后使用LSTM将该元组翻译成句子。此外,[8]中的模型适用于烹饪视频的有限领域&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











