









这篇是组会汇报3D HPE任务的PoseFormer方法时的部分内容,因为PoseFormer用到了transformer,故仔细学习了原文以及多位知乎大佬的讲解,最终形成了下述讲解稿。
transformer讲解总体架构
-
background:模型设计的出发点/特点,克服了过去模型的哪些难点?
-
以一个简单的翻译例子(“你是谁”->“Who are you”)对transformer模型总体架构(Encoder & Decoder)进行介绍。
-
对transformer各个重要部件(与poseformer这篇文章关联大的部分)进行详细介绍,包括以下内容:
- Positional Encoding
- 频率为什么设置的如此之小?
- 为什么sin和cos同时使用?
- 为什么是X+P?
- Self-Attention & Scaled Dot-Product Attention
- Multi-Head Attention
- Encoder: Add & Norm, Feed Forward
- 第一个Decoder的输入与Masked
- Positional Encoding
-
从Complexity per Layer, Sequential Operations, Maximum Path Length三方面对Self-Attention,Recurrent, Convolutional进行对比分析。
transformer讲解稿
以往模型的缺点+引出transformer
transformer是由论文《attention is all you need》提出的。在过去,对于序列建模和转换任务(比如机器翻译等),基本上都以编码器-解码器架构为基础(如图),利用含有GRU或LSTM的RNN结构来构建转换模型,但是应用RNN会有始终无法突破的一个局限:无法并行化计算,只能进行顺序结构的计算,进而导致模型训练会花费很长的时间。
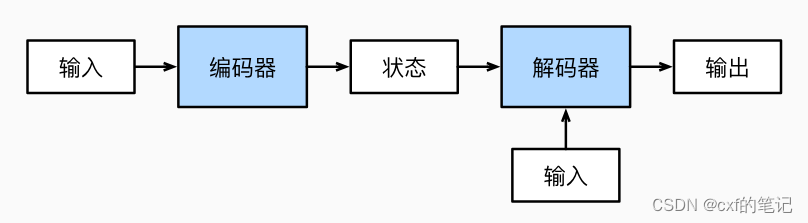
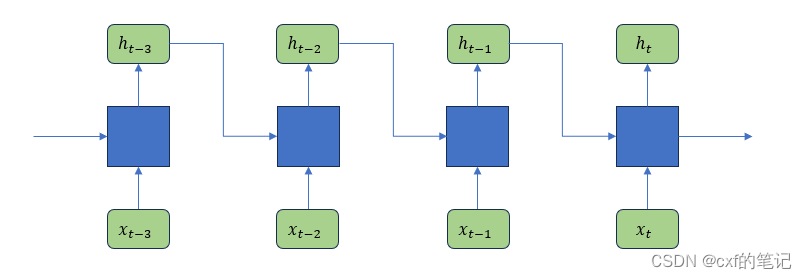
【我们来快速深入思考一下关于RNN的并行问题:RNN模型计算的时候(如图),当前单元结构的输出 h t h_{t} ht必须以 x t x_t xt和上一个单元的输出 h t − 1 h_{t-1} ht−1作为输入,才能计算得到结果。也即,下一个状态的输出依赖于上一个状态的输出结果,这种时序上的制约使其无法并行。
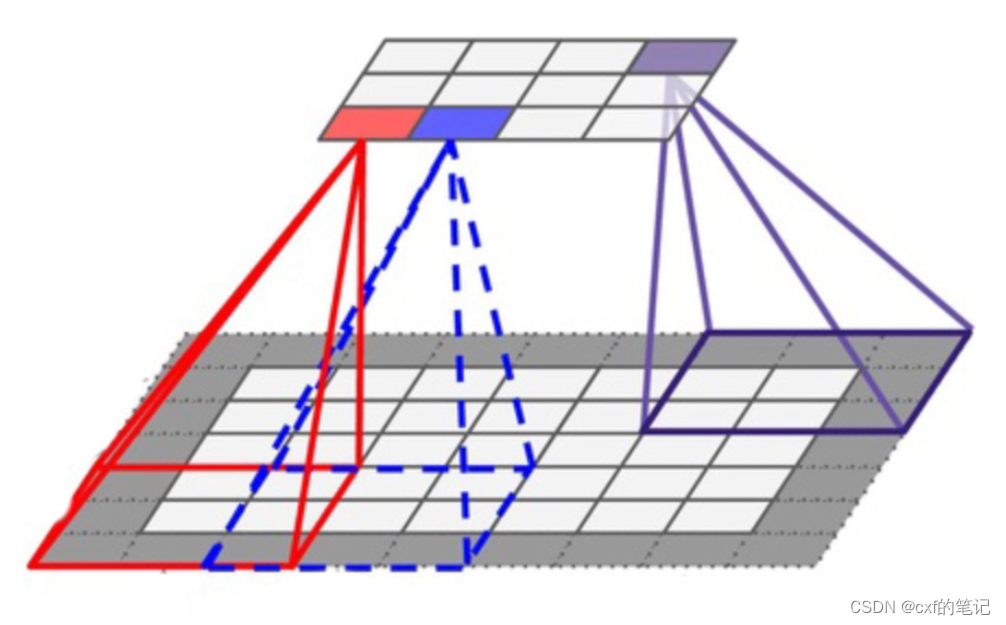
同时对比观察一下CNN:CNN模型中对一幅特征图的卷积运算,就是卷积核从左上到右下的循环浮点计算,整个循环过程中的运算相互独立且互不影响,而且不存在先后依赖顺序。使用cpu就是进行串行循环计算,而使用gpu则并行计算循环中的每一步并将结果汇总(如图)。】
为了减少顺序计算,前人提出了ByteNet and ConvS2S等卷积神经网络架构,但是这类架构学习远距离位置之间的依赖关系变得更加困难。(这里作者在此处标明有一篇文献理论研究,我没太仔细研究。但是可以明白的一点是,CNN会因每一个最终输出元素的感受野始终无法覆盖到全部输入序列,导致远距离的输入token之间的依赖关系难以习得)
此前已经有了注意力机制+循环网络的组合设计,作者为了更完美地解决RNN结构带来的顺序约束,索性彻底抛弃RNN和CNN结构,仅使用注意力机制来完成序列相关的任务,于是就提出了transformer。
transformer整体架构介绍
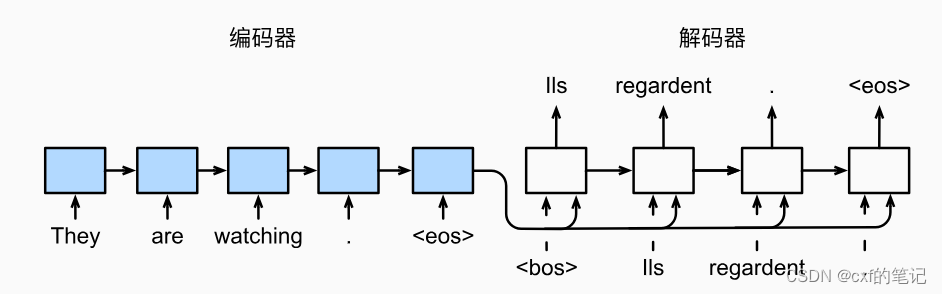
首先,我们先从整体上把握一下transformer的模型架构:
模型依然是按照Encoder+Decoder两步走,以“你是谁”作为序列输入,经过六层的编码器模块后,输出一个中间编码矩阵,之后每一级解码器模块利用上一级解码器的输出和中间编码矩阵进行计算输出,传给下一级解码器,最后经过一个线性映射和softmax层,输出预测结果“who are you”。
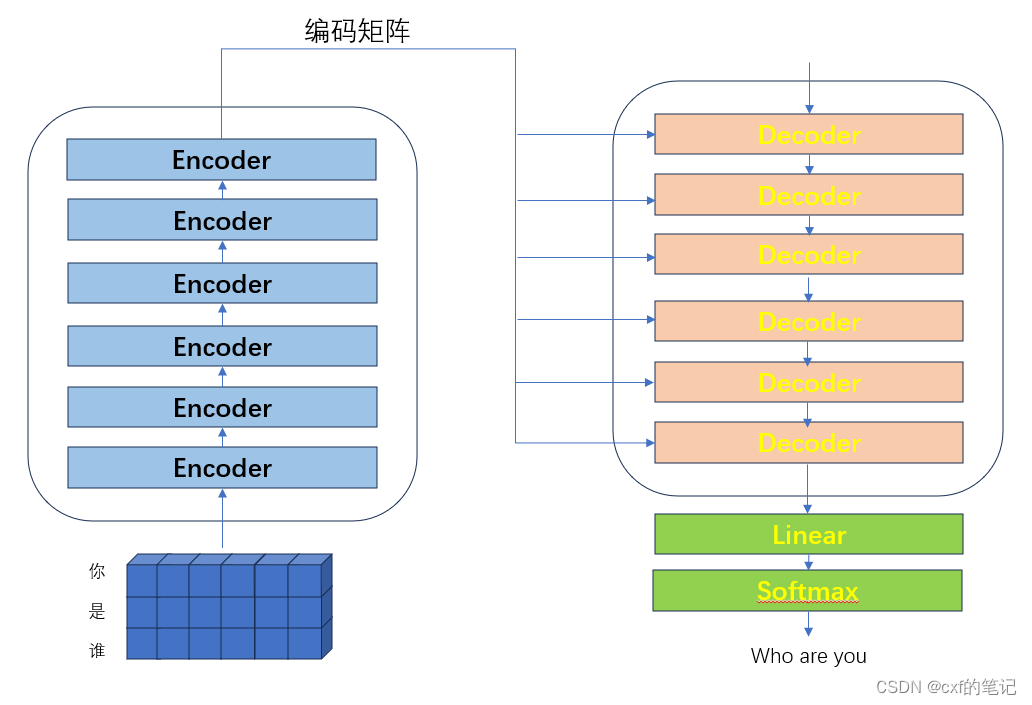
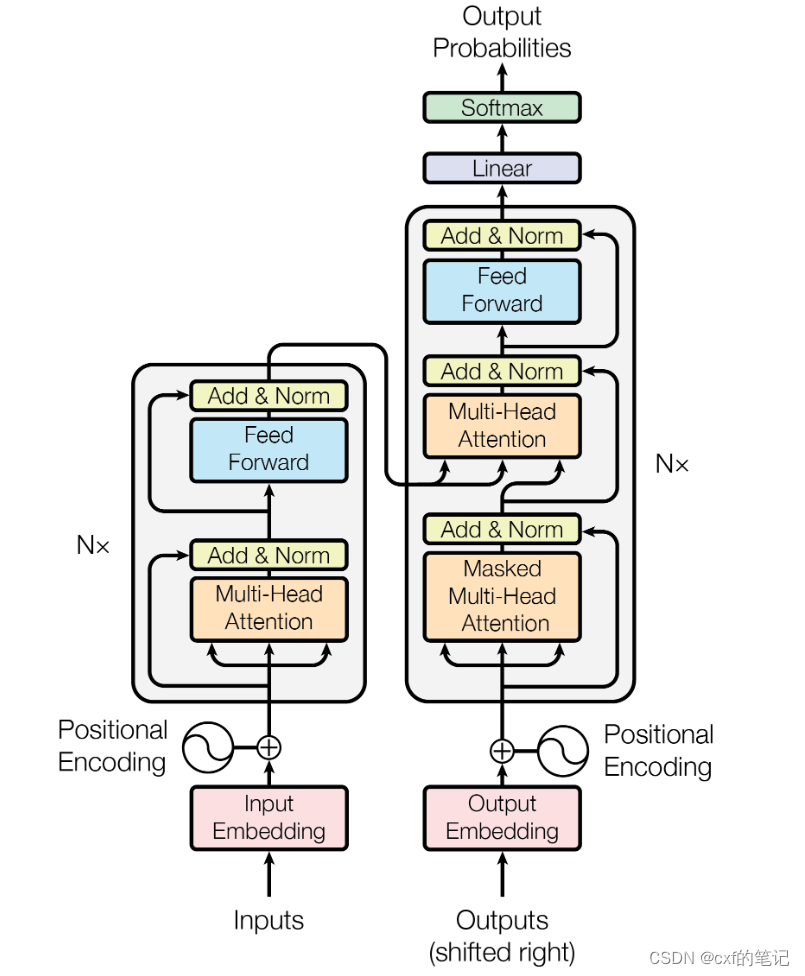
接下来我们详细了解transformer的每一个部分。
transformer中的输入:位置编码
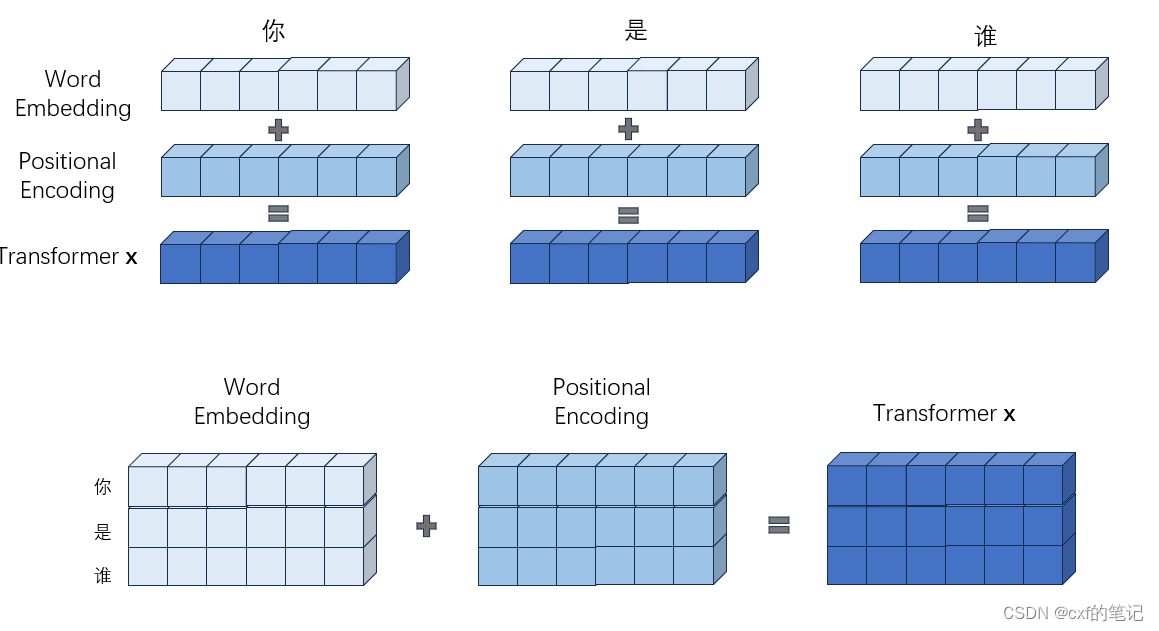
先从输入开始:对于非结构化的序列信息(如文本等),需要先转化为结构化数据(向量)才能输入至网络。我们需要对序列进行词嵌入+位置编码。
为什么要位置编码?这个是因为到transformer架构因为并行计算而缺失了对原始序列数据的时序/顺序关注,所以使用位置编码来注入绝对+相对的位置信息。
词嵌入忽略,重点来看位置编码:我们一般立马可能想到以下几种编码方案:
- 整数编码:1,2,3,…。问题在于:可能遇见比训练时所用的序列更长的序列,不利于模型泛化;位置表示无界,随着序列长度的增加,位置值会越来越大,(我认为)不利于计算。
- 有界小数编码:【0,1】区间进行等间隔划分,匹配每个tokens,但当序列长度不同时,token间的相对距离是不一样的。
- 二进制编码:如输入序列每个词元的维度d=2,序列为a1, a2, a3, a4, 则对应编码可以为00, 01, 10,11。这样编码出的位置向量,处在一个离散的空间中,不同位置间的变化是不连续的,不够“优美”
上述的想法多多少少都有不同的问题,论文作者是这样进行位置编码的:
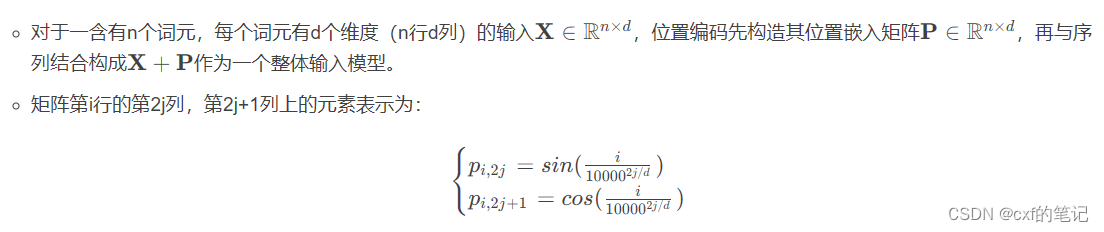
我们以n*d = 200*150的位置编码矩阵为例,计算得到位置编码矩阵如下图(代码略):
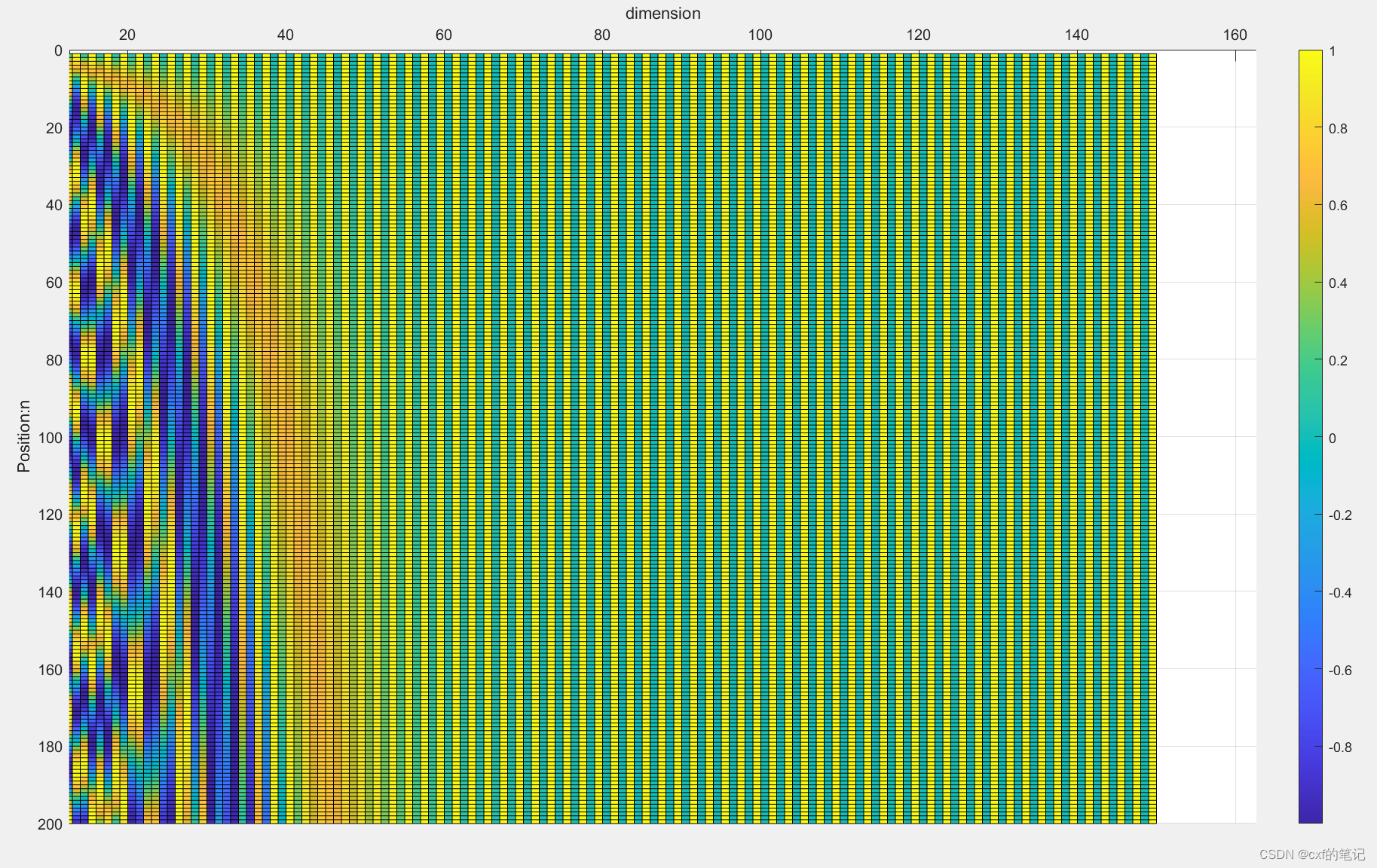
根据三角函数频率 ω j = 1 1000 0 2 j / d \omega_{j} = \frac{1}{10000^{2j/d}} ωj=100002j/d1。取出某一个向量/词元,频率随维度增加而变小。这其实也类似于二进制编码,越往低位走(越往左边走),频率变化的越慢。
我们不禁思考:为什么频率常数部分要设置为如此小的值
1
10000
\frac{1}{10000}
100001?:因为如果设置的较大(设置一个合理的数使
1
1000
0
2
j
/
d
−
>
1
2
j
\frac{1}{10000^{2j/d}}->\frac{1}{2^{j}}
100002j/d1−>2j1),使得d列个sin,cos函数绘制在d维空间中的高维图形中存在重合部分,那就出大问题了!不同位置的编码可能出现完全相同的结果!
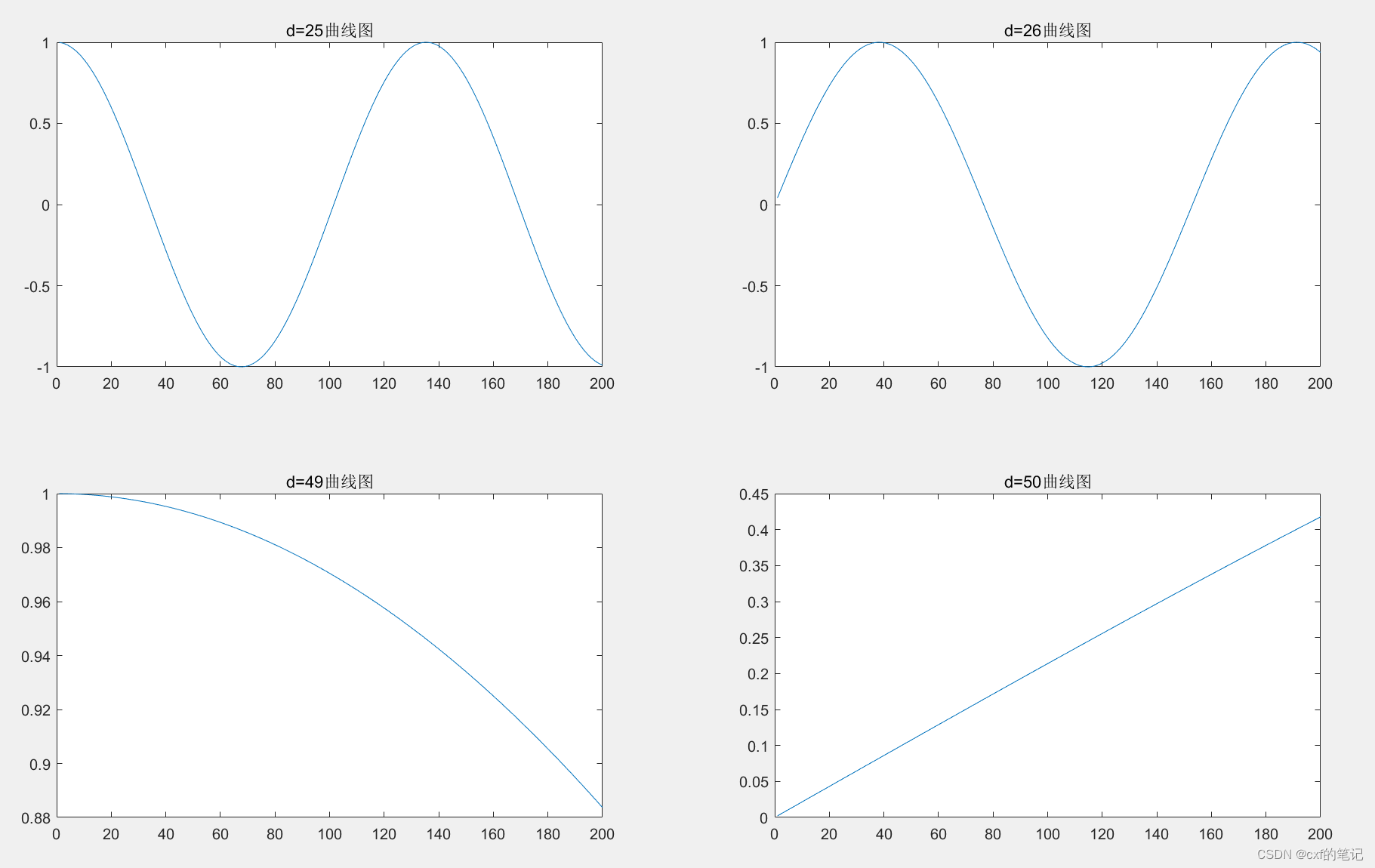
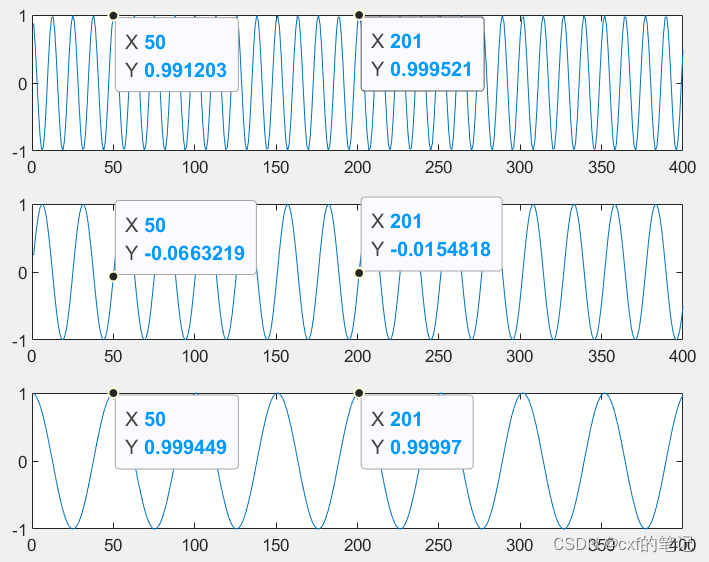
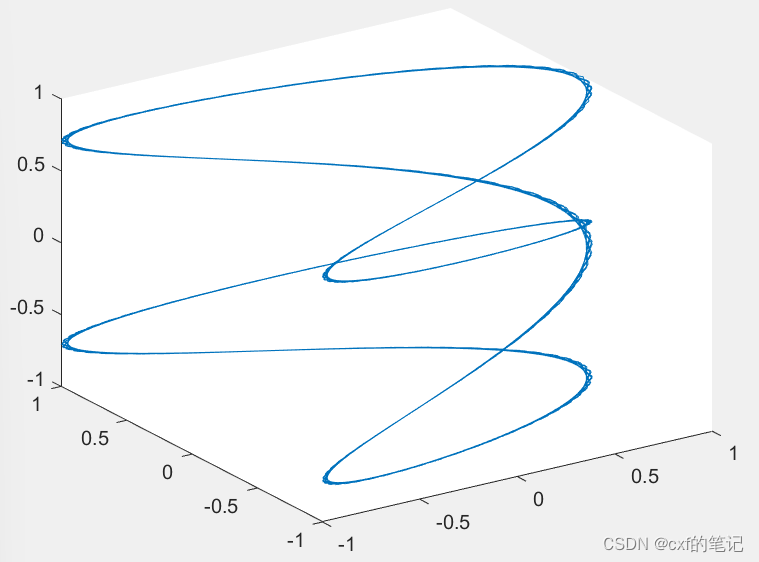
举一个简单的例子,长度为400的序列中每个元素的维度d=3时,绘图如下所示:可以看出,标记的两个位置的结果在各个维度上都相同了!进一步将三条曲线合成到三维空间,发现其实曲线是有重合迹象的。所以说,要想序列中每个token都有独一无二的绝对位置表示,那个频率常数必须要小!
事实上,只要保证各个维度上的正弦函数的周期的最小公倍数(也即公共周期)的长度小于序列长度,就不会有重合了。
我下面的代码编写和作图还是有一些错误,但是大致思想就是这样,我先不改了【狗头】
% 400*3的位置编码矩阵: 频率常数设置较大,且满足:该数^(2/d) = 2
d = 3;
t = linspace(1,400,400)
s1 = cos(1/2^(1) .* t);
s2 = sin(1/2^(2) .* t);
s3 = cos(1/2^(3) .* t);
figure;
subplot(3,1,1)
plot(t,s1);
subplot(3,1,2)
plot(t,s2);
subplot(3,1,3)
plot(t,s3);
figure;
plot3(s1,s2,s3);
我们可能还会想:为什么要同时引入sin和cos,而不是只用其中一种? 诶!这个就涉及到了相对位置关系的计算了。如果能sin和cos一起用,给定确定的位置偏移 δ \delta δ,根据线性投影原理,位置 i + δ i+\delta i+δ处的位置编码可以用位置 i i i处的位置编码来表示,如下述公式推导:(其中,那个变换矩阵实际就是旋转矩阵的转置)
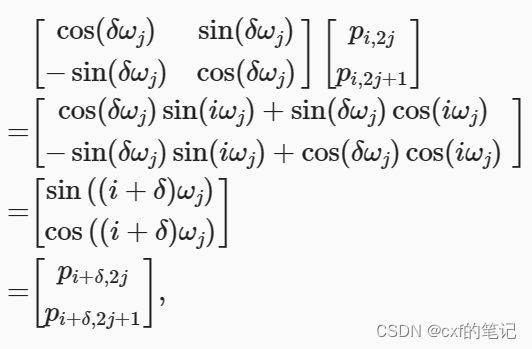
至此,输入的嵌入/编码问题我们已经解决了:最终输入到网络中的形式为 X + P \mathbf{X} + \mathbf{P} X+P,诶?为什么是直接加法而不是concat? 实际上两者本质上是等效的。
transformer之自注意力 & 缩放点积注意力
transformer中的self-attention机制可以在进行并行运算的同时,每次运算可以顾及到序列中的所有tokens。
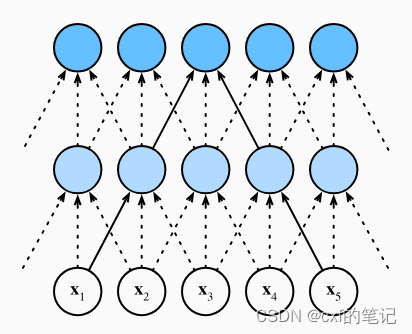
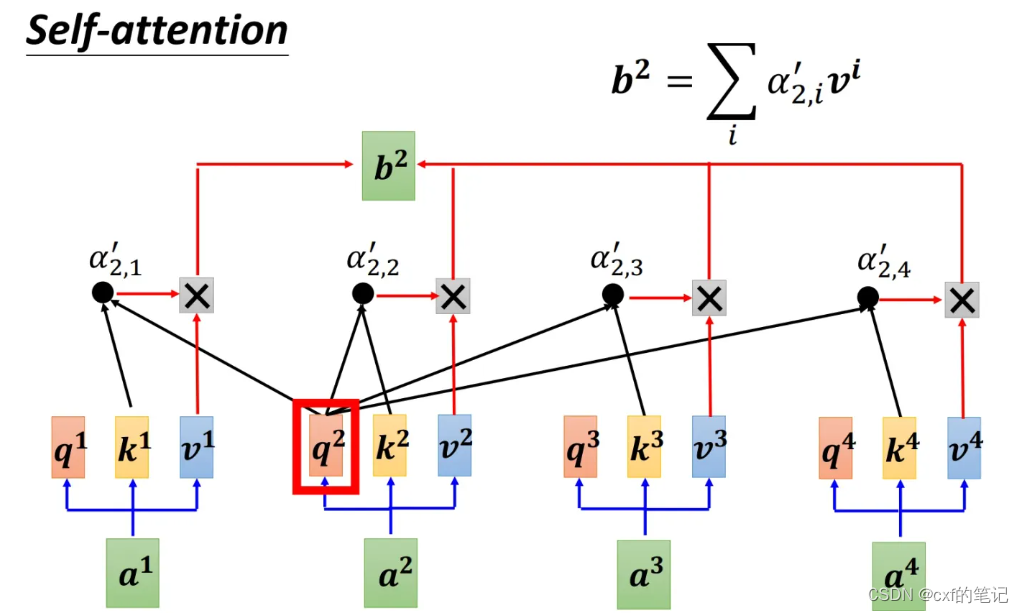
具体的实现方法如下:对于序列中的每个token,都会生成query,key,value三个向量。如图, a 2 a^2 a2要计算生成 b 2 b^{2} b2时, a 2 a^2 a2的query先分别与所有token的key做计算,这样得到了四个权重数值,然后各个权重依次与对应的value相乘,最后求和,得到 b 2 b^{2} b2的结果。
上述过程中,query相当于“查询”,key相当于“关键词”,value相当于“数据库”(里面有很多数据项)。当我们进行特定的“查询”时,需要一一根据各数据库的关键词来有选择地挑选每个数据库中的数据(对value进行加权求和)。
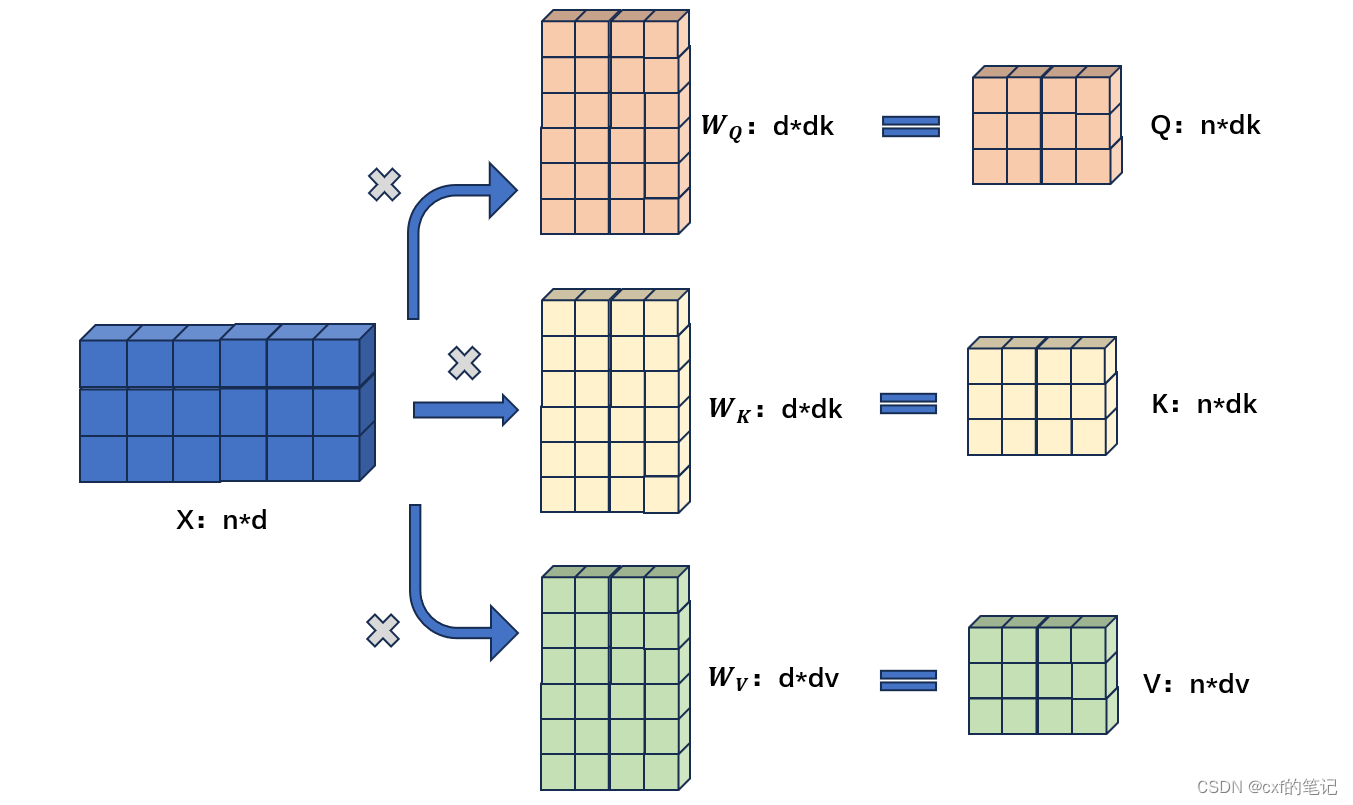
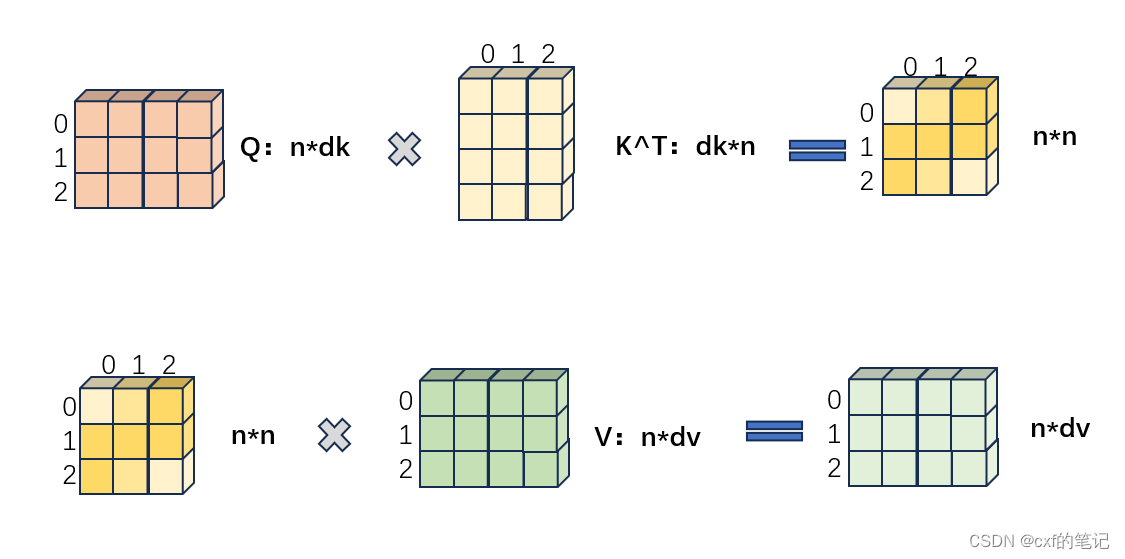
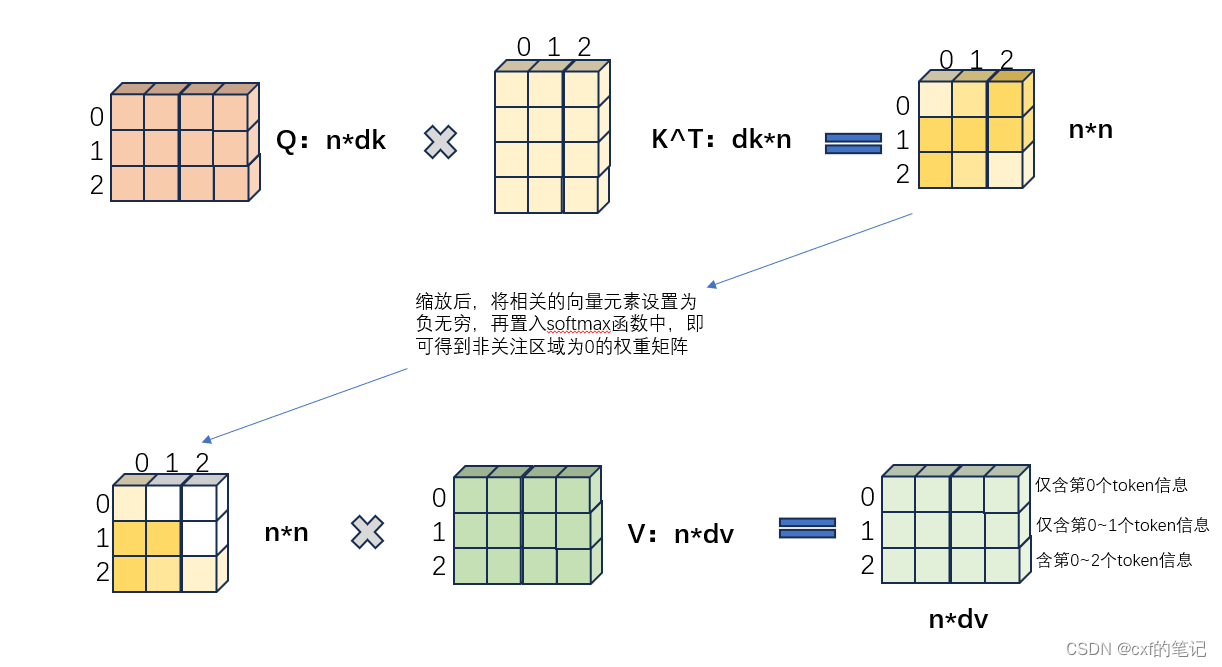
具体实现过程中:对于一个n*d的输入(每一行数据代表序列中的一个token),分别乘以 W Q ( s h a p e = d × d k ) , W K ( s h a p e = d × d k ) , W V ( s h a p e = d × d v ) W_{Q}(shape = d \times d_{k}),W_{K}(shape = d \times d_{k}),W_{V}(shape = d \times d_{v}) WQ(shape=d×dk),WK(shape=d×dk),WV(shape=d×dv)以生成对应的Q=query ( s h a p e = n × d k ) (shape = n \times d_{k}) (shape=n×dk),K=key ( s h a p e = n × d k ) (shape = n \times d_{k}) (shape=n×dk),V=value ( s h a p e = n × d k ) (shape = n \times d_{k}) (shape=n×dk),之后Q与K做矩阵相乘,经由softmax后算出了“权重值”。
(假设查询和键的所有元素都是独立的随机变量,并且都满足零均值和单位方差。为确保无论向量长度如何, 点积的方差在不考虑向量长度的情况下仍然是1, 故将点积除以 d k \sqrt{d_k} dk,这样放缩后,再使用softmax就能使最后的权重分布在0~1之间更均匀)
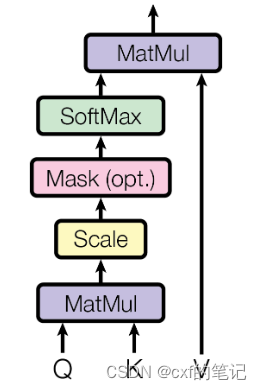
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V ∈ R n × d v Attention(\mathbf{Q,K,V}) = softmax(\frac{\mathbf{QK}^{T}}{\sqrt{d_{k}}})\mathbf{V} \in \mathbb{R}^{n \times d_v} Attention(Q,K,V)=softmax(dkQKT)V∈Rn×dv
最终,“权重”结果与values相乘,得到注意力机制作用后的结果:
transformer之多头注意力
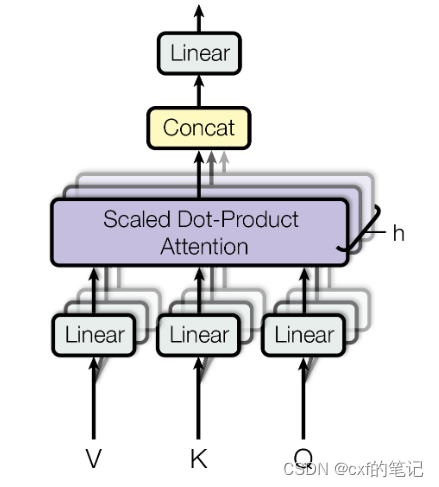
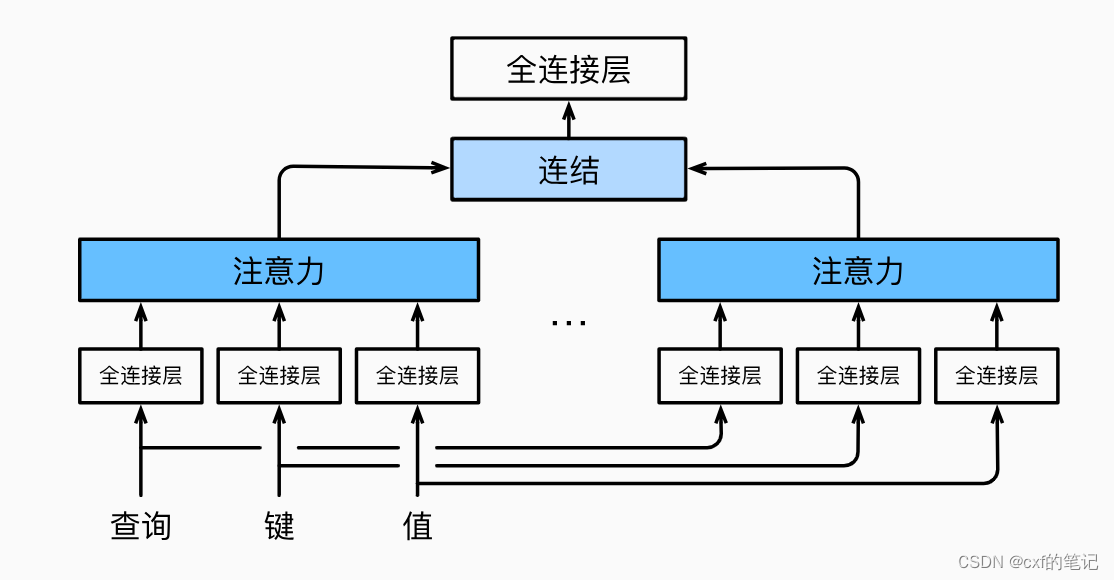
在实践中,当给定相同的查询、键和值的集合时,执行单一的注意力函数有点类似于“学习到一种行为/知识”。如果能同时多学点不同类型的知识,再将不同的行为/知识组合起来, 会不会效果更好呢?确实如此:作者将查询、键和值h次线性投影到dk、dk和dv维度,并行地使用h次自注意力,最后在进行concat输出,这样的做法确实对模型表现更有益。
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O MultiHead(Q,K,V) = Concat(head_1, ..., head_h)W^{O} MultiHead(Q,K,V)=Concat(head1,...,headh)WO
w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) where ~head_i = Attention(QW_{i}^{Q}, KW_{i}^{K}, VW_{i}^{V}) where headi=Attention(QWiQ,KWiK,VWiV)
transformer中Encoder结构内的其他细节
-
注意拐弯的箭头(Add):残差链接。残差链接可以有效减缓深度网络的网络退化问题。
- 什么是网络退化?理想来讲,加深网络的层数,是希望深层的网络的表现能比浅层好,或者是希望它的表现至少和浅层网络持平(相当于直接复制浅层网络的特征),可有时一昧加深网络反而会让网络表现水平下降。
- 网络退化的原因可能是:在MobileNet V2的论文中提到,由于非线性激活函数Relu的存在,每次输入到输出的过程都几乎是不可逆的,这也造成了许多不可逆的信息损失。要让之不退化,根本原因就是如何做到恒等映射 H ( x ) = x H(x) = x H(x)=x,ReLU的应用让网络很难学到恒等映射。
- ResNet把学习恒等映射问题转化为了学习残差,这样就很好解决了难点。
-
Norm,采用的是layer norm,这里不多细解释原因了
- Feed Forward
This consists of two linear transformations with a ReLU activation in between.
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x) = max(0, xW_{1} + b_{1})W_{2} + b_{2}
FFN(x)=max(0,xW1+b1)W2+b2
- 第一个decoder的输入和第一个encoder的输入一致,即为序列的嵌入向量,输入后首先要进行掩蔽多头自注意力模块,其过程如下图所示:
理论分析

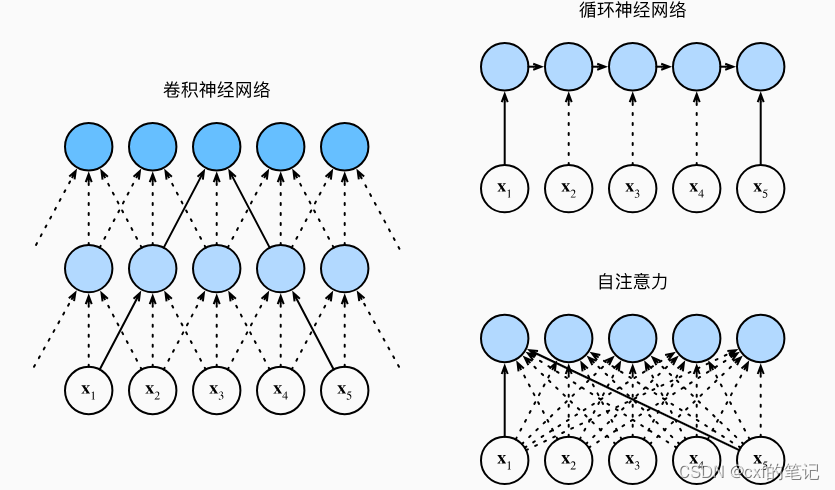
在这里,我们将仔细分析自注意力和RNN,CNN结构上的不同特点。
- 每一层的计算复杂度:假设有n个token,每个token维度为d。当token数小于维度d的时候,自注意力优于RNN循环层和CNN卷积层
- 顺序计算:自注意力层以固定数量的顺序执行操作连接所有位置,而循环层则需要O(n)个顺序操作
- 路径最大长度:在模型的输入序列中任何位置组合之间的这些路径越短,就越容易学习长距离依赖关系。自注意力位置之间的路径为固定值,而循环层需要O(n)
















 681
681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









