







文章目录
努力经营当下,直至未来明朗!
项目链接
网址:http://140.210.201.164:8080/online_OJ/index.html
在线OJ
一、背景介绍
在线OJ,即在线的网页版编程平台,这在目前是比较常见的且常用的,如LeetCode以及牛客网等都是类似的在线OJ平台。
当打开该网站之后就可以看到很多算法题,然后你就可以完成在线做题、在线提交,并可以立即看到运行是否通过。
二、项目核心功能
以LeetCode为例查看分析该项目的核心功能。LeetCode进入页面 -》 点击“题库” -》 会出现很多算法题,当我们点击某道题的时候就可以进入该题的详情页面,包含完整题目信息、输入输出示例以及代码编辑框(可以切换语言)、执行操作 -》 当点击提交之后就会出现运行结果,点击还能看到具体运行详情。
- 能够管理题目:保存很多题目信息,即 题干+测试用例
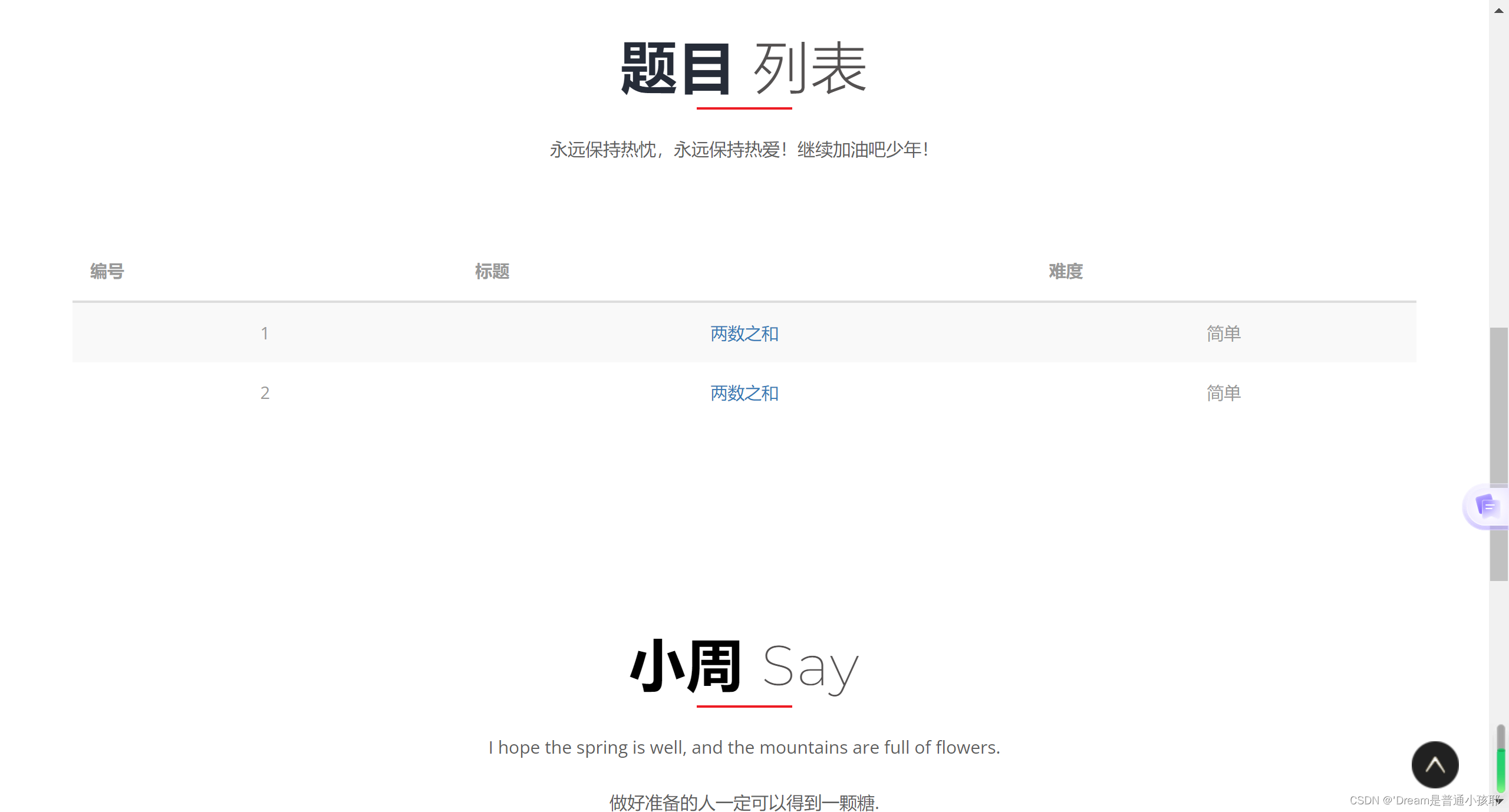
- 题目列表页:能够展示题目列表,即题目的名称
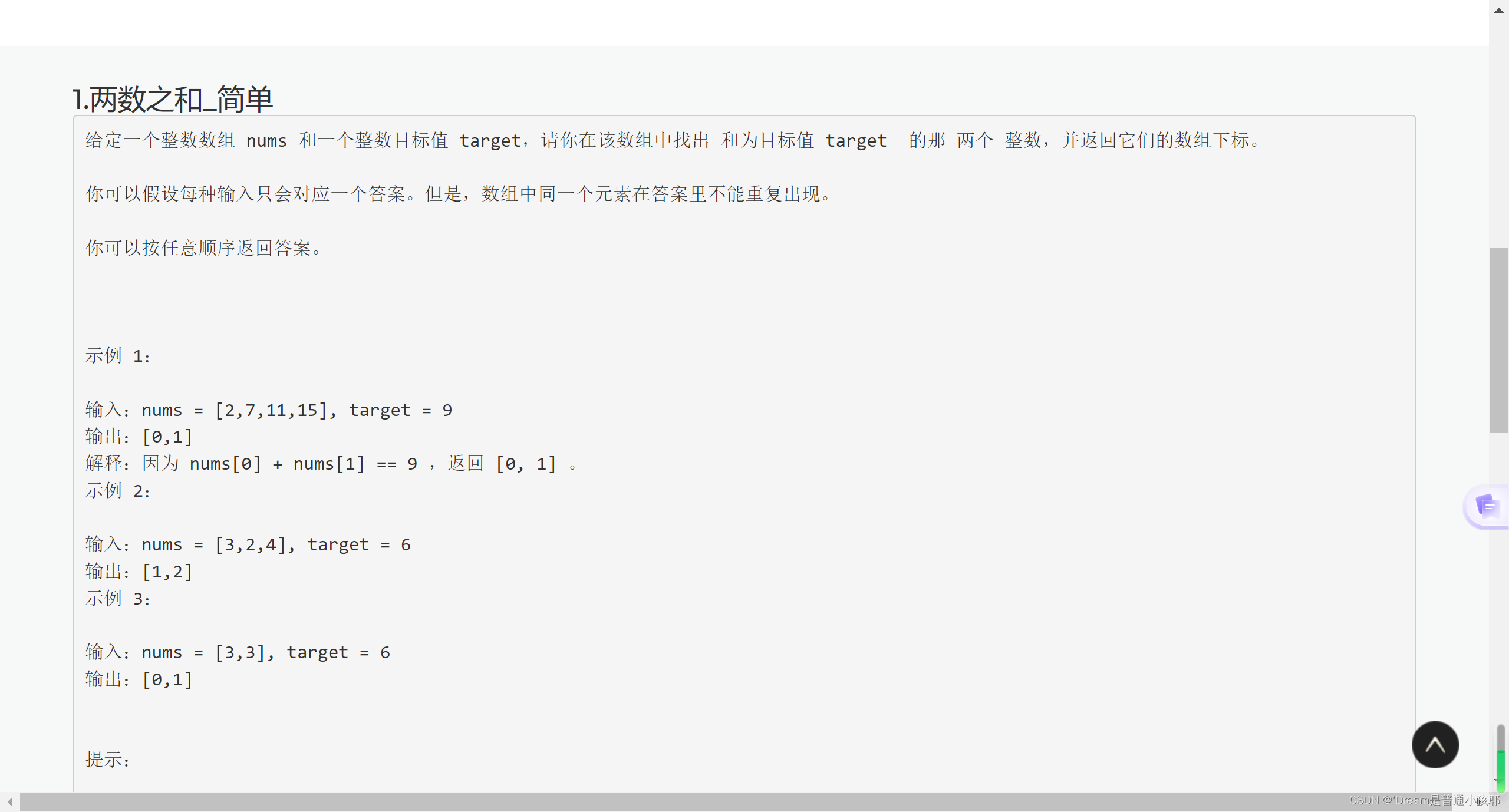
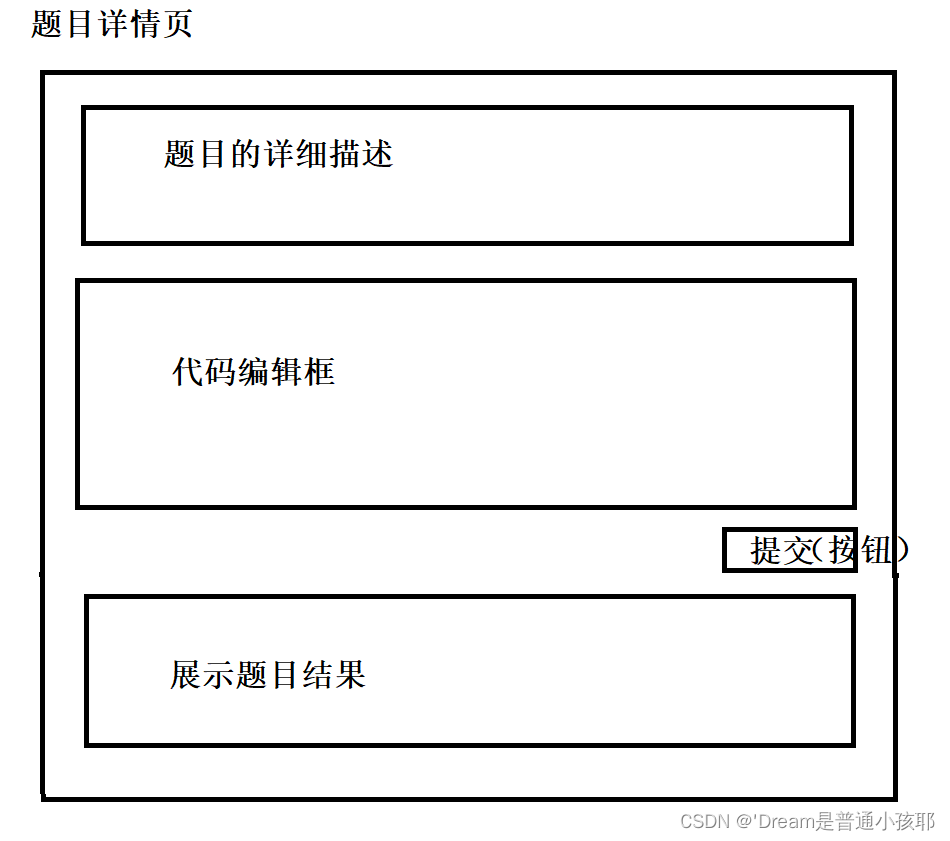
- 题目详情页:能够展示某个题目的详细信息 + 代码编辑框等信息
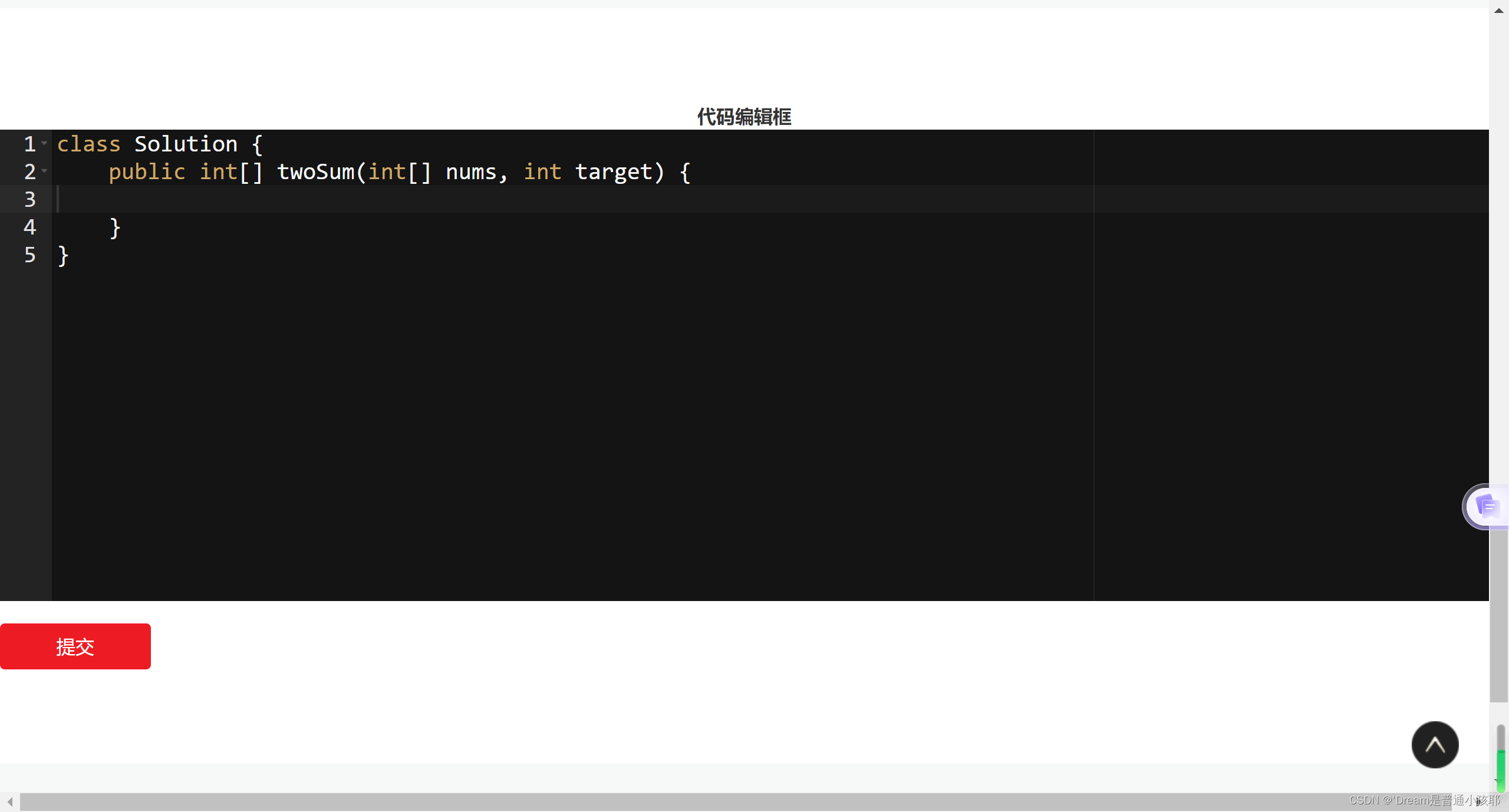
- 提交并运行题目:详情页中有一个“提交”按钮,点击按钮之后网页就会把当前的代码提交到服务器上,服务器就会执行代码,并给出一些是否通过用例的结果展示
- 查看运行结果:有另一个结果页面,能够展示上次提交的代码是否通过以及错误的用例信息。此时如果能够提供一些历史提交记录就更好了。
三、项目展示
-
主页
-
列表页
-
题目详情
-
代码编辑及提交
四、前置知识
一)IO流
-
在Java中,操作文件(读写)主要都是通过IO流相关的类来实现的。
-
Java标准库中,对于IO的操作提供了很多现成的类,这些类都是放在java.io的包中
-
标准库中的这些类大致可以分成两大类:
1)一类是操作字节的(以字节为单位进行读写)
2)一类是操作字符的(以字符为单位进行读写) -
字节是8个bit位的,字节是表示存储空间的基本单位。
字符表示的是一个“文字符号”,一个字符可能是由多个字节构成的。 -
需要根据文件的类型来决定是按照字节操作还是字符操作。二进制文件需要按照字节来操作,文本文件需要按照字符来操作。
-
如何区分一个文件是文本还是二进制呢?
简单的方法就是使用记事本打开看看是不是乱码,如果是乱码就是二进制文件,如果不是乱码就是文本文件。(因为记事本是默认按照文本的方式来解析文件的) -
针对字节为单位进行读写的类,统称为“字节流”。
字节流:InputStream(接口)、FileInputStream(类)、OutputStream、FileOutputStream -
针对字符为单位进行读写的类,统称为“字符流”。
字符流:Reader、FileReader、Writer、FileWriter -
实现简单实例(放到了test文件夹之下):
使用字节流,实现把一个文件中的内容读取出来写到另一个文件中。
① 读写文件之前一定要先打开文件
② 循环进行读出、写入操作
③ 关闭文件
- 文件资源泄露相关问题:
① 一个进程能够同时打开的文件个数是存在上限的!!
② 受限于操作系统内核里面的实现。对于Linux来说,进程PCB中存在一个属性“文件描述符表”,其大小是存在上限的。
③ Linux中可以通过ulimit命令来查看/修改进程能够支持的最大文件个数。
二)进程和线程
-
进程也可以称为是“任务”,操作系统想要执行一个具体的“动作”就需要创建出一个对应的进程。
-
一个程序没有运行的时候,仅仅是一个“可执行的文件”,当程序跑起来的时候就变成了一个进程了。
-
为了实现“并发编程”(同时执行多个任务),就引入了“多进程编程”。即:把一个很大的任务拆分成若干个很小的任务,创建多个进程,每个进程分别负责其中的一部分任务。
-
但是“多进程”会带来一个问题:创建/销毁进程是比较重量(比较低效)的,因此又引入了线程。
-
每个线程是一个独立的执行流,一个进程包含了一个或多个线程,创建线程/销毁线程比创建/销毁进程更高效。因此,Java中大部分的并发编程都是通过多线程的方式来实现的。
-
进程相比于线程的优势:进程的“独立性”
① 操作系统上同一时刻运行中很多进程,如果某个进程挂了是不会影响到其他进程的(每个进程都有各自的地址空间)
② 相比之下,由于多个线程之间共用着一个进程的地址空间,此时如果某个线程挂了,很可能会把整个进程带走。 -
对于在线OJ项目,有一个服务器进程(运行着Servlet,接收用户请求并返回响应),而用户提交的代码其实也是一个独立的逻辑,那么这个逻辑是使用多线程好还是使用多进程好呢?
① 对于用户提交的代码,势必要通过 “多进程” 的方式来执行!!
② 因为对于用户提交的代码我们是不可控的,代码很可能是存在问题的,很可能一运行就会崩溃。如果使用多线程,就会导致用户代码直接把整个服务器进程都带走的糟糕情况。 -
多进程编程主要要做的事情:
① 站在操作系统的角度(Linux为例),提供了很多和多进程编程相关的接口如进程创建、进程终止、进程等待、进程程序替换、进程间通信等。
(Linux原生的API都是通过C语言风格的接口来提供的)
② 而在Java中对系统提供的这些操作进行了限制,最终给用户提供了两个操作:进程创建、进程等待。 -
进程创建:
① 创建出一个新的进程,让这个新的进程来执行一系列的任务
② 被创建出来的进程称为“子进程”,创建子进程的进程称为“父进程”
③ 项目中的服务器进程就相当于父进程,根据收到的用户发送过来的代码再创建出子进程
④ 一个父进程可以有多个子进程,但是一个子进程只能有一个父进程!
⑤ Runtime.exec方法:参数是一个字符串,表示一个可执行程序的路径,执行这个方法就会把指定路径的可执行程序创建出进程并执行。
(Runtime是Java中内置的一个类,在JVM中是单例)
⑥ 谈到多进程,经常会涉及“父进程、子进程”;但是注意对于多线程就没有“父线程、子线程”这种说法。
(实例见test目录下的TestExec)

补充✨
配置环境变量的方法:
此电脑 -> 右键 “属性” -> 搜索“环境变量” -> 点击“系统…" -> 点击”环境变量“ -> 修改”用户or系统“都可以 -> 点击“Path” -> 添加路径就行
注✨:
① 用户环境变量,只针对当前用户生效;系统环境变量,针对所有用户都生效。
② Path就意味着操作系统会去哪些目录中查找命令对应的可执行文件
补充✨
- 一个进程在启动的时候就会自动地打开三个文件:(是由操作系统控制的)
① 标准输入:对应到键盘
② 标准输出:对应到显示器
③ 标准错误:对应到显示器- 虽然子进程启动之后同样也打开了这三个文件,但是由于子进程并没有和IDEA的终端关联,因此在IDEA中是看不到子进程的输出的。要想获取到输出,就需要在代码中手动获取到。
- 进程等待:

通过上面的代码确实可以创建出子进程,但是此时父子进程之间是“并发执行”的关系。
而往往是需要让父进程知道子进程的执行状态的,这可以通过进程等待来完成。
如:在当前的项目中,需要让用户提交代码、编译并执行代码结束之后再把响应返回给用户。
即:父进程等待子进程执行完毕之后再执行后续的代码。

五、项目实现
一)创建项目
- 创建一个Maven项目,并引入相关的依赖。
1)主要需要的是MySQL connector的jar包以及Servlet相关的jar包。
2)需要的jar包可以参考中央仓库(记得进行收藏,经常使用)
mysql connector选择5.1.49
servlet选择3.1.0
<!-- 引入相关依赖:mysql、servlet-->
<dependencies>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<!-- https://mvnrepository.com/artifact/javax.servlet/javax.servlet-api -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
- 在main目录下创建new directory:webapp -> WEB-INF -> web.xml(文件) -> 然后在web.xml中导入以下代码
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd" >
<web-app>
<display-name>Archetype Created Web Application</display-name>
</web-app>
二)封装类(编译运行模块)
1. CommandUtil类
- 将经常使用的方法等封装到一个类中以便实现代码的复用。
- 在main.java包中创建CommandUtil类来实现方法的封装。
- CommandUtil类实现run方法,其中主要包含以下四个功能:
① 通过Runtime类得到runtime实例,执行exec方法
② 获取到标准输出,并写入到指定文件中
③ 获取到标准错误,并写入到指定文件中
④ 等待子进程结束,拿到子进程的状态码并返回
- idea默认是utf8编码方式,Windows简体中文系统默认是gbk编码, 而linux上编码方式统一是utf8。
2. Task类
-
基于实现的CommandUtil来实现一个完整的“编译运行”这样子的模块Task。当然,该模块又会涉及到其他类。
输入:用户提交的代码
输出:程序编译运行的结果 -
Task类实现compileAndRun方法主要注意的问题:
① 注意参数和返回值类型:源代码和编译运行结果
② 需要创建子进程调用javac进行编译,但是注意:在进行编译的时候需要的是一个.java文件,当前是通过String的方式来进行传参的。所以:将question里的code写入到一个.java文件中。
③ Java中类名要与文件名保持一致,即code字符串中的类名就需要和写入的文件名一致。约定:类名和文件名都叫Solution。 -
为什么要设置这么多的临时文件呢?
其实最主要的目的是为了进行“进程间的通信”。进程之间是存在独立性的,一个进程很难影响其他的进程。
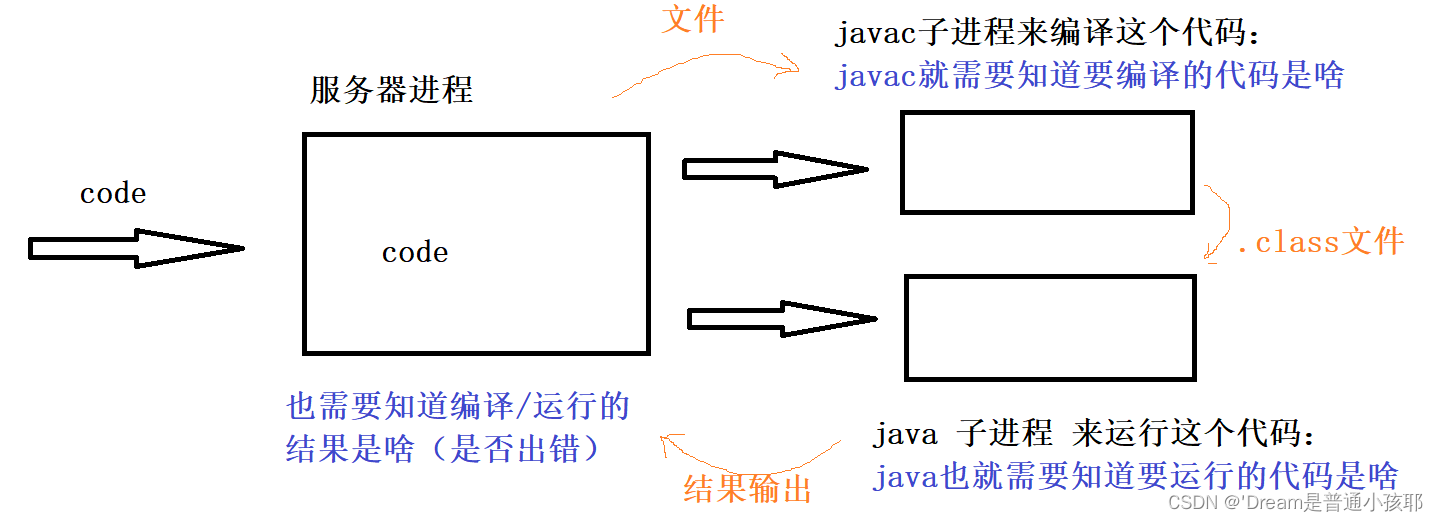
补✨
① Linux系统中提供的进程间通信手段有很多种,但是我们采取的是一个简单粗暴的方式,即:通过文件来进行。
(由于javac和java这俩进程的代码都是别人写好的,咱们控制不了,所以此处也只能是通过“文件”的方式来进行进程之间的通信)② Linux系统中提供的进程间通信手段如:管道、消息队列、信号量、信号、socket、文件等
(实际开发中最常见的进程间通信手段是socket网络编程)
③ 临时文件对于测试、调试都是有用的。
④ 终端输出的信息编码方式默认和系统保持一致。
- 注意:在进行命令行构造的时候,javac编译中的-d是将生成的.class文件保存到指定路径下,以免后续找不到文件。java运行中的-classpath指定文件的查找目录。
- 对于javac进程来说,其标准输出我们并不关注,而是关注标准错误。一旦编译出错,内容就会通过标准错误来反馈出来。
3. FileUtil类
- 对于读写文件的操作进行进一步封装:提供两个方法,一个方法负责读取整个文件的内容,返回一个字符串;另一个方法负责写入整个字符串到文件中。
- 对于要读写的文件,即之前定义的临时文件,都是文本文件,所以这里使用字节流更合适一些。
对于文本文件来说,字节流和字符流都是可以进行读写的。但是字符流会省事儿很多,字节流可能会比较麻烦(需要手动处理编码格式,尤其是文件中包含中文的时候)
- 注意:
① String是一个不可变的对象,在进行字符串拼接(+=)操作时,其实就是在创建一个新的String对象,需要把旧的内容拷贝过去。
② 所以需要进行字符串拼接可以使用StringBuilder(异步、线程不安全)、StringBuffer(同步、线程安全)
③ 多个线程同时修改同一个变量才会触发线程安全问题。
④ 局部变量是在栈上的,而每个线程都有自己的栈,所以局部变量不太涉及线程安全问题。
三)题目管理模块
将题目信息给保存到数据库中,在main目录下创建一个db.sql文件
1. 设计数据表
创建一个“题目表”oj_table
① 题目的序号:id,作为题目表的自增主键
② 题目的标题:title
③ 题目的难度:level
④ 题目的描述:description,也就是题干等详细信息
⑤ 题目的代码模板:templateCode,给用户展示的初始代码,用户要在该初始代码模板的基础上进行开发
⑥ 题目的测试用例:testCode
2. DBUtil类
将数据库相关操作封装到DBUtil类中
注意单例模式是存在线程安全的,如懒汉模式,所以此时进行加锁操作synchronized。(但是要注意为了避免多次加锁就提前进行判断一次)
3. Problem类、ProblemDao类
-
dao包表示数据访问对象这样的一个特殊的包
-
Problem类是一个实体类,里面存放了题目表中的相关信息,一个实例就对应着表中的一条数据记录。
-
还需要针对表进行增删改查操作,所以创建一个ProblemDao类来负责“增删改查”操作。
-
ProblemDao类中主要实现以下四个功能:
① 针对管理员:新增题目、删除题目
② 针对普通用户:查询题目列表、 查询题目详情
对于修改操作其实也是针对管理员的,但是此时先不进行修改操作的实现,如果要实现其实也就是jdbc那套代码。 -
因为前端实现分页功能稍微复杂一些,所以在进行列表页显示的时候就暂时不考虑分页显示。
-
数据库往往是一个比较重要的模块,但是也比较脆弱。而数据库中的数据是存储在磁盘上的。当我们进行大规模操作的时候,如(select * from 表名)就可能会把数据库服务器给卡死了,即CPU、磁盘、网络带宽很可能是一下就被吃满的(分页查询以及非*查询可以解决部分这些问题)
-
在构造数据库的时候,其他字段其实都比较好办,但是对于“测试用例代码”是不好处理的!! 其他字段都可以从力扣等网站上进行直接拷贝,但是测试用例是没办法进行直接拷贝的。
所以:就靠我们自己去设计测试用例。 -
测试用例的思路:
① 测试用例的代码其实就是一个main方法,用户提交代码之后就让两部分代码进行拼接,然后去执行该类就行。然
② 后在该main方法中会创建Solution的实例,并且调用用户提交的核心方法,在调用核心方法的时候传入不同的参数,然后进行编译运行,对结果进行判定。
③ 如果返回结果符合预期就打印“Test OK”;如果不符合预期就打印“Test Failed”,同时打印出出错的详情 -
在进行测试的时候,测试用例其实是多多益善的。开发人员在进行项目开发、代码编写过程中进行的主要功能测试是“冒烟测试”(最简单的测试),针对每个方法进行测试的测试风格是“单元测试”。
四)设计服务器提供的API
通过一些HTTP风格的接口 可以和网页的前端进行交互。
- 要设计哪些网页(有哪几个页面,都是干啥的)
1)题目列表页:功能就是展示当前题目的列表 =》 向服务器请求,题目的列表
2)题目详情页:功能有3个
① 展示题目的详细要求 =》 向服务器请求,获取指定题目的详细信息
② 能够有一个代码编辑框,让用户来编写代码(这个过程不需要和服务器交互,纯前端实现)
③ 有一个提交按钮,点击提交按钮就能把用户编辑的代码给发到服务器上,服务器进行编译和运行,并返回结果。 =》 向服务器发送用户当前编写的代码,并且获取到结果
上面两个是最核心的页面,除此之外,还可以提供一个题目管理页(给管理员使用,不开放给普通用户),管理员通过该页面进行新增题目 / 删除题目 =》 向服务器提交新增题目 / 删除题目 的请求
- 具体设计这些前后端交互的API
1)目前比较流行的前后端交互方式主要是通过JSON格式来组织的,但是JSON格式的解析其实还是比较麻烦的,需要引入第三方库来帮助我们完成。Java中处理JSON的第三方库很多,此处就使用Jackson。
2)同样是通过中央仓库来查找相关依赖的,然后将依赖导入pom.xml。(此时选择的是2.13.0)
1. 向服务器请求,题目列表
- 请求和响应格式

- 在api包中创建ProblemServlet类进行代码编写
以上代码是设置HTTP响应的body部分
① HTTP协议的报头中就要求通过Content-Length来描述body的长度(长度不需要咱们手动设置,Servlet的库已经自动完成了)
② 通过Content-Type来描述body的类型,在Servlet中需要咱们进行手动设置
③ JSON格式的数据的Content-Type:application/json;charset=utf8(后面的字符集根据实际情况来写就行)
[注意位置!!]

在实际工作中,很多时候开发的功能是需要前后端相互配合的,此时首先要做的工作就是来约定前后端交互的接口。
2. 向服务器请求,获取指定题目的详细信息

3. 向服务器发送用户当前编写的代码,并且获取到结果
-
请求和响应格式:

-
一大段代码发送给服务器,该怎么发呢?
① GET,就需要把代码放到URL中,通过query string来发。
这是完全OK的,但是要注意,需要针对代码中的字符进行urlencode
② POST,就把代码放到body中即可 -
GET和POST没有本质区别:
GET能做的事情,POST也能做。 -
GET通常body是空的,但是也完全可以不为空
POST通常没有query string,但是也完全可以有。 -
针对编译运行来说,请求和响应都是JSON格式的数据,为了方便解析和构造,就可以创建两个类来对应JSON结构。(名字进行对应之后方便Jackson库处理)
-
给内部类加上static之后就说明:当前内部类的实例就不依托于外部类的实例。如果不加static,就必须先创建外部类实例,再创建内部类实例。
-
注意:二进制数据转文本数据要指定编码方式

-
Java库中支持utf8、UTF8、utf-8、UTF-8写法,但是mysql配置文件中只支持utf8、UTF8两种写法,此处需要进行注意一下。
-
类对象.class就类似于反射,JSON字符串与类对象中的属性相对应。
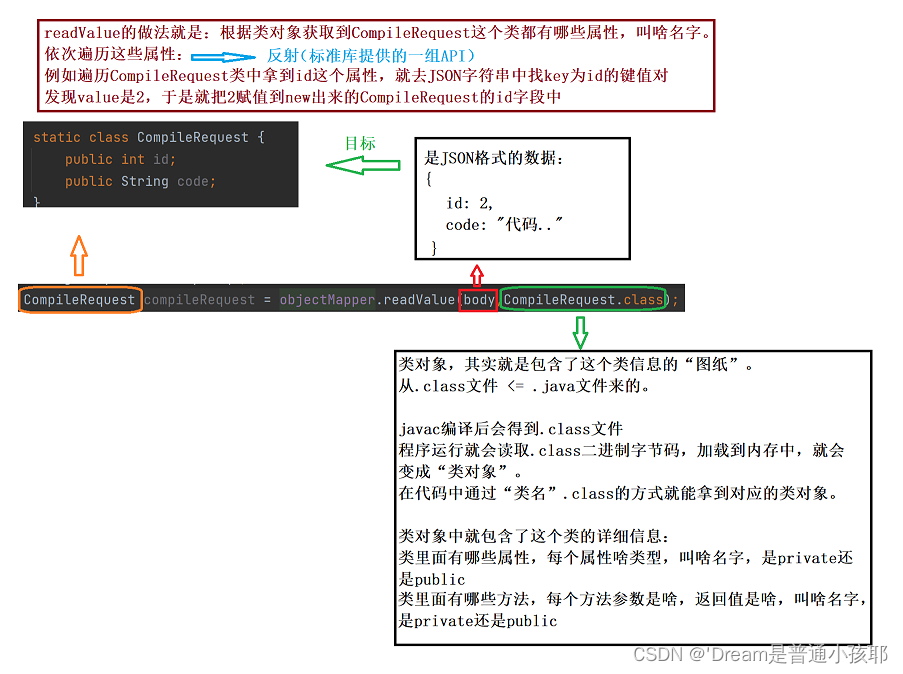
-
合并测试代码和用户提交的代码:
把testCode给放到Solution的最后一个}之前就行
1)先在requestCode(提交的代码)中查找最后一个 } 的位置:lastIndexOf
2)根据刚才的查找结果,进行字符串的截取。
假设最后一个 } 的下标是100,就按照subString(0,100)这样子来截取,目的就是排除最后一个 }
(因为是前闭后开的形式,即:[0,100))
3)把刚才的截取结果拼接上测试用例的代码,然后再拼接上一个 } 就行了。
注:直接去length()-1的位置的字符,是否就是 } ??
这是不一定的,因为用户在进行代码提交的时候说不定在后面会加上空格以及换行等。
-
如果用户输入的是非法请求,如id不存在或者是code是空字符串/非法字符串,那肿么办呢?
我们可以做的就是尽量提高代码的鲁棒性和认错能力。 -
目前代码中还存在另一个问题:每次有一个请求过来,都会生成一组临时文件存储在tmp中(每个请求一组文件)。但是如果同一时刻有n个请求一起过来,那么这些请求的临时文件的名字和所在的目录都是一样的,此时多个请求之间就会出现“相互干扰”的情况(非常类似于线程安全问题)。
解决方案:
1)加锁:但是同一时刻只能处理一个用户的请求,这并不是最佳解决方案
2)更好的办法就是让每个请求都有一个自己的目录来生成这些临时文件,此时互相之间就不会相互干扰了。
所以:我们要做的就是让每个请求创建的WORK_DIR目录都不相同。
① 使用id作为标识,但是这不太好,因为此时id就成为了全局变量,一旦出问题影响太多。
② 最佳方案就是使用UUID作为“唯一标识”。每次请求生成一个UUID,这个UUID一定是在全球范围内唯一的。
按照现在的做法,每个请求都会生成一个UUID命名的目录,那随着时间的推移,请求越来越多,磁盘上的这些临时文件不就越来越多了嘛?持续下去不久会把磁盘占满吗?
答:
① 确实是会存在这样的情况,但是也没关系,每个临时目录中的东西也不是很多,磁盘上可以存储很多这样子的目录。
② 另外,还可以进行定期删除。
真实的服务器其实就是类似的,会无时无刻地在生成一些临时的数据(如打印的日志文件),如果日积月累也是会越来越多的,所以可以定期删除(每天删除一次,仅保留近三天的日志)。
“定期删除” 是手动删除吗?会不会就给忘了?
① 不是手动删除的,操作系统支持一个功能“定时任务”(Linux:crontab,Windows也有)
② 线上服务器都有监控程序,监控磁盘的剩余空间,如果发现磁盘空间快满了,也是会提前给程序员提示报警的。
- 相对路径以及当前工作路径的获取:
System.out.println(System.getProperty("user.dir"));
// 获取当前工作路径
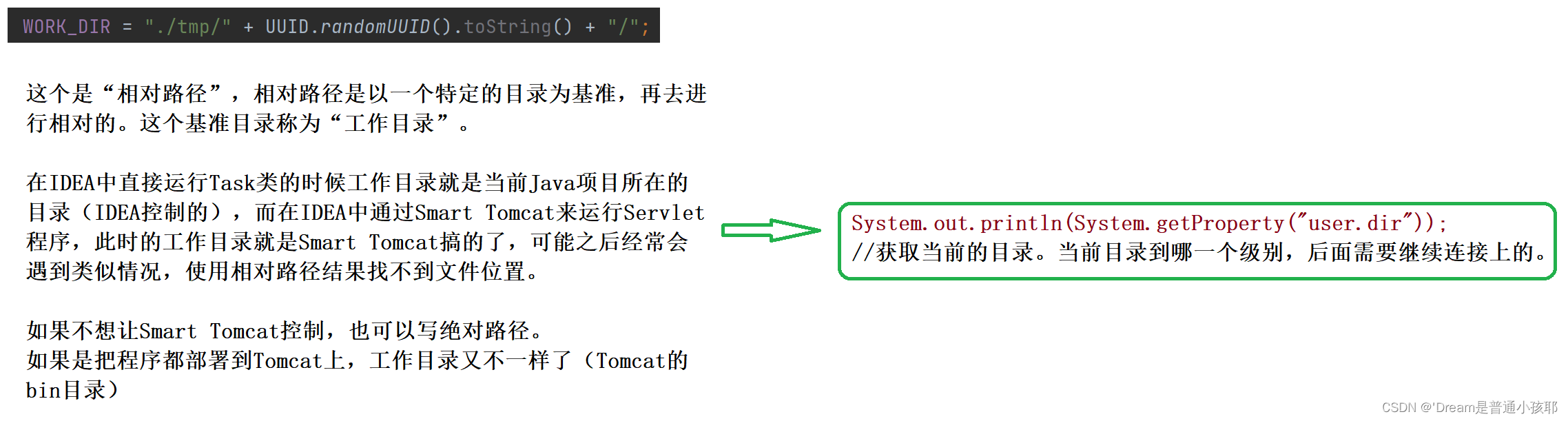
进行功能的验证(tomcat)
-
Servlet程序需要部署到tomcat上:
1)直接打一个war包,手动拷贝到webapps目录
2)直接使用IDEA插件smart tomcat来完成
(可以参考:Servlet部署到Tomcat上) -
另外,可以在部署完成后使用postman进行验证。
五)前端实现
- 制作网页不一定非得“从零开始写”,可以去网上找一些现成的网页模板,基于模板来进行修改。直接修改的难度是远小于从零出发的。
- 网页模板:直接从网上搜“免费网页模板”就可以找到很多类似的网站。
- 页面的初步设计:
大概需要几个页面,每个页面都干啥,大概是啥样的。
1. 题目列表页
展示出当前有哪些题目,点击某个题目就可以跳转到题目的详情页。
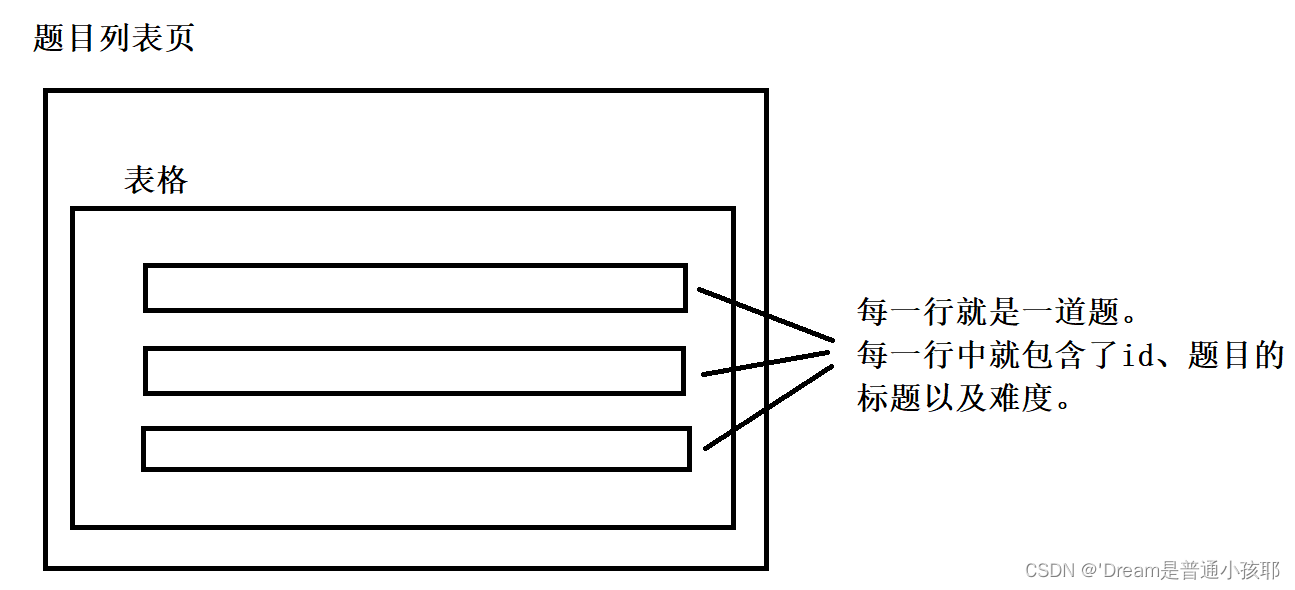
2. 题目的详情页
展示题目的具体信息。
注意:
平时工作中,最好也把要修改的重要的内容先进行备份,万一要是啥改坏了,随时可以进行恢复回来。
-
将下载好的网页模板复制到该项目的webapp目录下(src -> main -> webapp)。使用VSCode打开index.html文件并进行修改。
-
JS中原生的ajax是通过XMLHttpRequest类来实现的,用起来比较麻烦,所以更推荐使用其他第三方库提供的封装版本(自己封装的也是可以的),此处使用jQuery提供的ajax。
$是jQuery中定义的一个特殊变量,jQuery提供的各种API都是$这个变量的方法。 -
在验证题目列表页的时候,发现了一个重要的问题:当点击题目标题的时候,会发现得到的内容不是一个完整的页面,而仅仅只是一个JSON数据,这是不合理的,应该给用户一个页面才对。
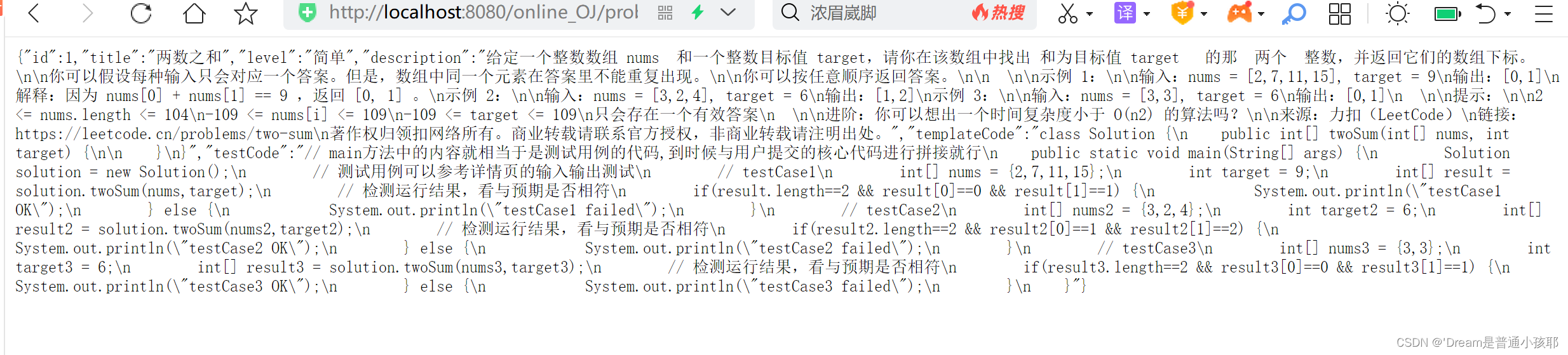
解决方法:
① 再添加一个页面problemDetail.html,该路径也是在题目列表页的a标签中填写的地址,同时把题目的id通过query string 传过去。
② 即形如problemDetail.html?id=2跳转到另外一个页面,在该页面中,拿到query string中的id的值的页面再通过ajax 的方式来获取到题目的详情(即给服务器发送请求problem?id=2),然后再显示到屏幕上。 -
前端中有一种常见的布局方式“栅格式布局”(在有flex布局之前,当时的布局还挺麻烦的,主要是基于浮动/table,于是就有一些第三方库实现了“栅格布局”),典型代表“bootstrap”。
① 和flex布局有点儿像,先一行一行布局,再一列一列布局。
② 有一个最外层的父元素container<div class="container"> </div>
③ 父元素中有很多行
<div class="row mt-5"> </div>
mt-5:margin-top,5表示边距的大小(单位不是px,而是人家库中内部约定的尺寸) ④ 每一行中还有一些列
<div class="col sm-10 pb-5"> </div>
sm-10:把一行分成12个网格,数字就表示占几份,相当于设定元素的宽度。
pb-4:padding bottom
-
会发现题目的描述都挤到一行里了,原因是数据库中对题目要求的描述都是使用\n来表示换行的,而HTML不识别\n, HTML中的换行是
标签。

解决方案:
① 让服务器返回的数据中,\n都替换成<br>(在后端代码ProblemServlet.java中,获取到题目详情之后,使用replaceAll进行替换)
② 给页面的标签里套一层<pre>标签,<pre>标签中的内容是可以识别\n的 -
注意:ajax中把对象转成字符串的操作,data处传入的是字符串
data: JSON.stringify(body)
-
在点击“提交”之后,返回的数据是乱码的。主要是编码问题,Windows默认是GBK,而页面浏览器的默认编码方式是UTF8。

解决方案:
① 当部署到云服务器上之后该问题就不用考虑了。
② 如果本地想看的话,就可以找到当前路径(控制台上有打印)的tmp目录底下进行查看。 -
另外,在点击“提交”之后,代码不能编译。查看服务器生成的临时问阿金,就发现是提交过来的代码本来就是错误的(最后的内容是编辑框的初始代码,而不是当前代码)。
经过“fn+f12”的console验证,发现innerHTML确实得不到当前的实时代码。
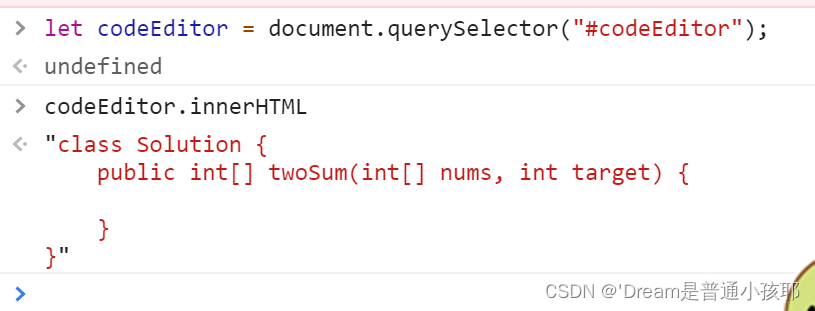
解决方案:
为了查看codeEditor的哪个属性可以看到实时代码,就在console中使用dir(codeEditor)进行查看,发现使用value属性可以看到提交的实时代码。因此在构造请求的时候使用value来替换innerHTML。 -
代码编辑框不能按tab键进行缩进,也没有代码提示。
解决方案:
引入第三方库ace.js,这就是一个前端版本的代码编辑器。其安装非常简单,只要在页面中引入对应的地址即可。 -
在引入了第三方代码库ace之后,每次刷新都会清空之前写好的代码。因为ace.js会重新绘制页面(绘制div #editor),原来写的textarea就没有了。
解决方法:
① 在页面加载的时候,通过editor.setValue(yourCode);来设置代码模板到编辑器中。
② 在提交代码的时候,需要通过let yourCode = editor.getValue();的方式来获取代码。 -
在点击题目列表页的题目的时候,期望是重新打开一个页面,而不是进行页面的替换,此时给a标签加上一个
a.target = '_blank'; -
问题及解决:
① 问题:在进行ace代码编辑框嵌入的过程中,一旦嵌入编辑框之后,题目的详细信息就无法显示,点击提交按钮也没有任何反映。
② 经过排查:发现代码编辑框嵌入后其他信息无法显示是因为zce代码编辑框嵌入的时候传参错误导致的,一定要注意参数要对应到之前在html里加的那个div的id。而点击提交没有反映是因为获取代码时的函数getValue()写错了字母。
六、代码安全性问题
-
当前系统存在一个很重要的“代码安全性”的问题:在线OJ系统需要去执行一段用户提交的代码,但是用户提交的代码是存在安全隐患的。如:以下的代码:
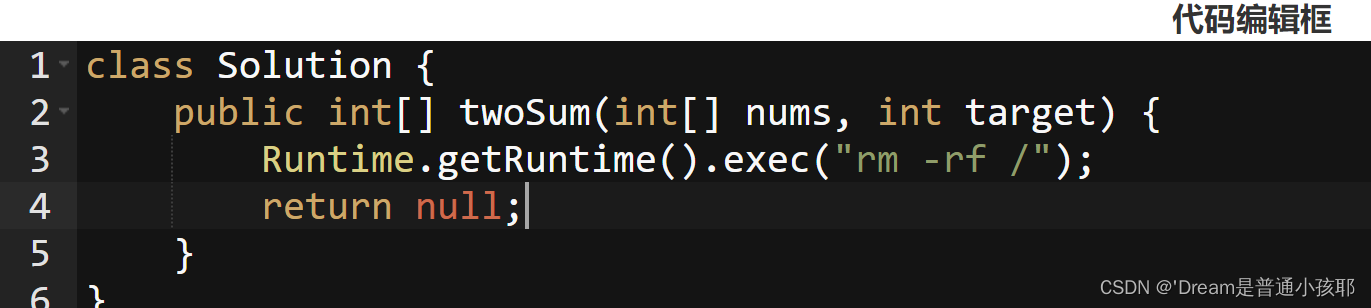
① Runtime能够执行一个程序是比较危险的。
② 代码中可能存在一些“读写文件”操作,也是比较危险的。黑客可以通过写文件操作直接把一个病毒程序写到你的机器上。
③ 代码中如果存在一些“网络”操作,也是比较危险的。 -
我们应该要禁止用户执行这些“危险操作”,而禁止的前提是去识别出这些操作。
-
一个简单粗暴的办法就是:使用一个黑名单,把有危险代码的特征都放到黑名单中。在获取到用户提交的代码时,就查找一下看当前是否命中了黑名单,如果命中了就提示出错,不去编译执行。
-
在后端代码Task.java中,在将code写入到Solution.java文件之前进行安全性判断。
-
通过这个黑名单的方式,只能简单粗暴的处理掉一批明显的安全漏洞,但是还是存在安全隐患,那么有没有更彻底的方法来解决该问题呢?
① 使用docker(现在非常广泛使用的技术),相当于一个“轻量级虚拟机”。
② 每次用户提交的代码,都给这个代码分配一个docker容器,让用户提交的代码在容器内执行。此时哪怕该代码包含恶意操作,最多也只是将docker容器搞坏了,对我们的物理机是没有任何影响的。
③ docker的设计天然就是很轻量的,一个容器可以随时创建,也可以随时删除。
七、项目部署
-
在pom.xml中加上 packaging以及build 标签
-
Maven进行打包操作,然后open in找到target目录下打包好的war包
-
打开Xshell连接上服务器,打开Tomcat所在目录,并且切换到webapps目录下(可以使用
ll进行目录的查看),然后将war包拖拽过来,然后可以使用ll进行查看,是会自动进行解压缩的。此时就可以使用外网IP进行访问了。 -
此时发现:题目列表那儿啥都没有。因为数据库还没有部署,需要将数据库也部署到外网上。切换到Xshell,然后
cd ~到主目录,输入mysql -uroot -p(注意:默认密码是“”),然后将sql语句进行复制粘贴上去,此时数据库建立完成。 -
但是此时数据库中是没有任何数据的,添加数据又比较麻烦,所以可以将ProblemDao.java(其中有插入用例的操作)进行打jar包, 但是注意要修改DBUtil.java中的数据库密码。
-
手动打jar包:File -> Project Structure -> Artifacts -> 点击"+" -> JAR -> From… -> 选择Main Class以及Directory(最好选择根目录)-> 完成之后:Build -> Build Artifacts -> Build -> 然后在out目录就有刚才打包好的jar包 -> open in -> explorer -> 然后直接拖拽到服务器主目录中即可(注:按exit可以退出数据库,也可以直接复制会话) -> 输入 java -jar jai报名.jar即可

-
此时需要重新打war包并将原来部署的war包rm后重新拖进去,然后就可以使用外网进行网页的访问了。
-
问题以及解决方案:
① 问题:在本地数据库中插入数据等的操作是成功的,但是部署到服务器上之后,对数据库的新增等操作是无效的。

② 解决方案:
其实问题的原因是编码方式的不匹配,为了能够支持中文字符,在创建数据库时应该要指定编码方式为utf8mb4.
所以删除数据库后重新创建数据库并指定编码方式就可以很好地解决该问题了。


八、项目代码
-
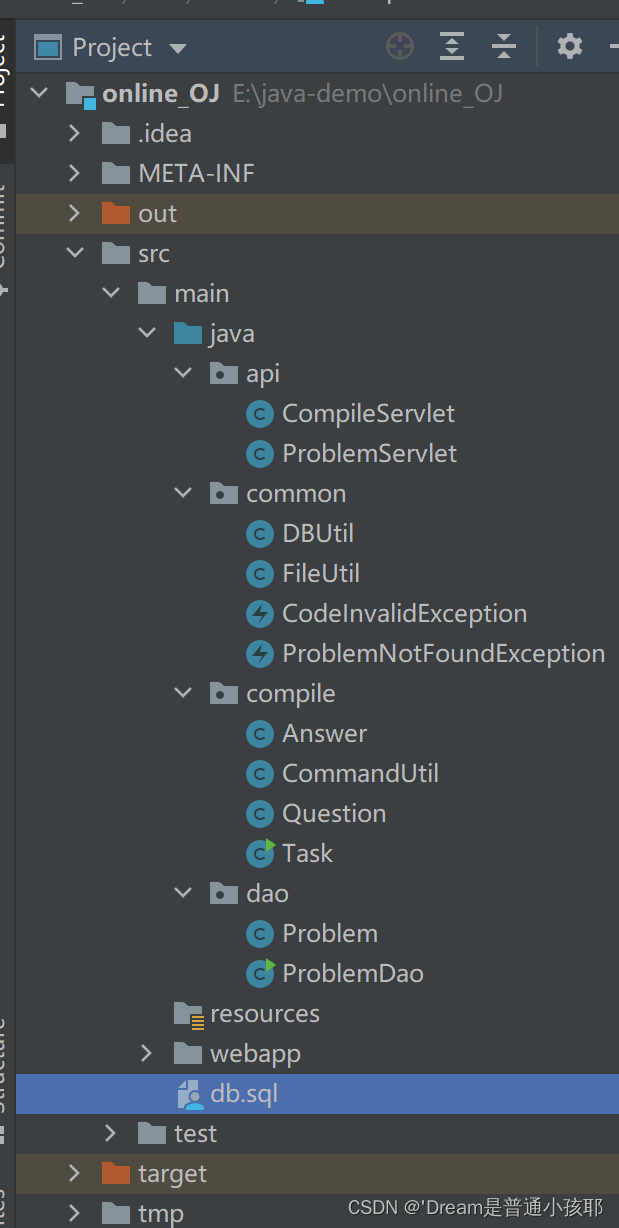
总体目录结构
-
项目代码:项目代码
1)在线OJ项目的核心支撑(服务器后台):
① 基于多进程编程的方式,创建了一个CommandUtil类,来封装创建进程完成任务的工作。
② 创建Task类,把整个编译运行过程进行封装。
③ 创建了数据库和数据表,设计了题目的存储方式。
④ 封装了数据库操作(Problem和ProblemDao)。
⑤ 设计了前后端交互的API。
⑥ 实现了这些前后端交互的API。
2)前端部分:
① 题目列表页
② 题目的详情页
九、项目小结
-
了解项目基本需求:
① 题目列表页
② 题目详情页
③ 代码编辑框
④ 提交给服务器编译运行
⑤ 展示结果 -
多进程编程
封装了一个CommandUtil类,就可以创建进程执行一个具体的任务,同时把输出结果记录到指定文件中。 -
创建Task类,调用 CommandUti 封装了一个完整的“编译运行”过程,后面又给Task类扩充了一个基于黑名单的安全代码校验。
-
设计数据库,封装了数据库操作,主要有Problem和ProblemDao两类。
-
设计前后端交互的接口
① 获取题目列表
② 获取题目详情
③ 编译运行 -
基于Servlet来实现这些接口
-
引入了前端代码模板,基于代码模板进行了修改,创建了两个页面:
① 题目列表页inde.html
② 题目详情页problemDetail.html -
通过JS代码实现了前端调用HTTP API的过程
-
引入ace.js 让代码编辑框变得更加易用
-
部署到云服务器上
-
注:可以进行功能的扩充,如
1)题目的录入:录入/删除题目 (管理员页面)
2)登录注册
3)提交记录的保存
4)通过率统计
5)提交评论
6)点赞收藏题目
















 3373
3373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











