







引言
在信息爆炸的今天,推荐系统已成为帮助用户在海量数据中发现感兴趣的内容的重要工具。本文将详细介绍我们如何使用Python和Flask框架,结合机器学习技术,构建一个基于用户喜好的电影推荐系统。
导入所需的库
在Python脚本的开始部分,导入所需的库和模块:
#数据处理库
import pandas as pd
#机器学习库,用于TF-IDF向量化和余弦相似度计算
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
#Flask Web框架,用于创建Web应用和路由
from flask import Flask, request, jsonify, render_template数据来源与预处理
数据来源
我们的数据集是通过爬虫技术从豆瓣电影网站排行榜250top爬取的,生成一个csv格式的表格,共203条电影信息。
爬虫代码:
#导入模块
import requests
import parsel
import csv
f = open('电影推荐8.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'电影',
'导演演员',
'年份',
'国家',
'电影类型',
'评分',
'评价',
'详细链接',
])
#写入表头
csv_writer.writeheader()
#请求链接
url = 'https://movie.douban.com/top250?start=175&filter='
#伪装模拟
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36'
}
#发送请求
response = requests.get(url=url,headers=headers)
#转成可解析对象
selector = parsel.Selector(response.text)
#css选择器:根据标签属性提取内容
#获取所有电影数据标签
lis = selector.css('.grid_view li')
#for循环遍历,把所有元素提取出来
for li in lis:
title = li.css('.hd a span:nth-child(1)::text').get()#电影名
info_list = li.css('.bd p:nth-child(1)::text').getall()#获得电影信息
director = info_list[0].strip().split(' ')[0].replace('导演: ','').split(' ')[0]#导演
year = info_list[1].strip().split(' / ')[0]#年月份
country = info_list[1].strip().split(' / ')[1]#国家
film_type = info_list[1].strip().split(' / ')[2]#电影类型
fraction = li.css('.star .rating_num::text').get()#评分
evaluate = li.css('.star span:nth-child(4)::text').get().replace('人评价', '')#评价
href = li.css('.hd a::attr(href)').get()#详细链接
print(info_list[1])
dit = {
'电影' : title,
'导演演员' : director,
'年份' : year,
'国家' : country,
'电影类型' : film_type,
'评分' : fraction,
'评价' : evaluate,
'详细链接': href,
}
# 写入数据
csv_writer.writerow(dit)这是数据集大致的信息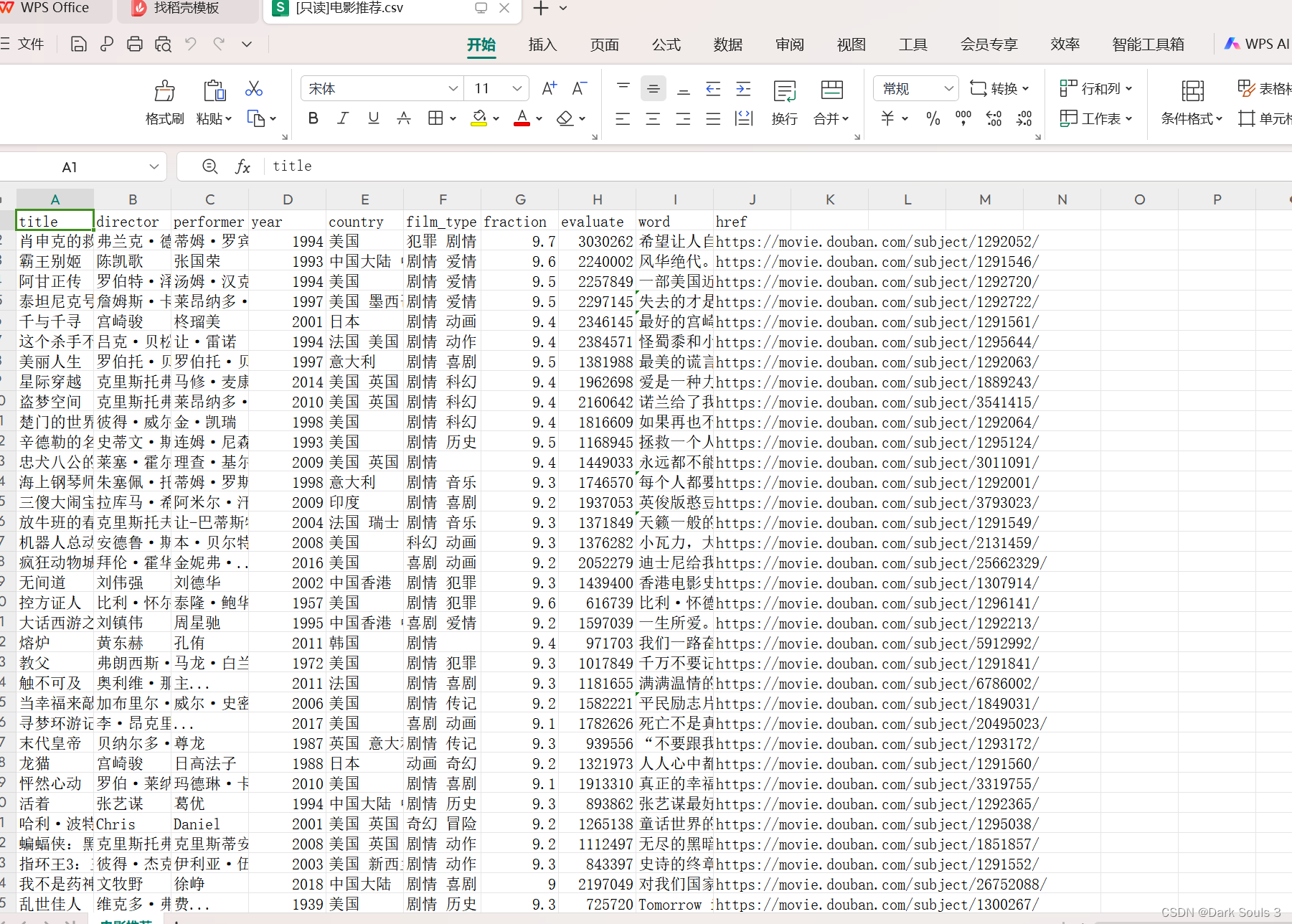 :
:
读取CSV文件
# 1. 读取数据编码GBK
df = pd.read_csv('电影推荐.csv', encoding='gbk')这里假设文件名为'电影推荐.csv',使用Pandas的read_csv函数读取数据,指定编码为'gbk'以正确处理中文字符
数据预处理
数据预处理是构建推荐系统的关键步骤。我们首先对抓取的数据进行清洗,包括去除空白字符、转换为小写等,以确保数据的一致性和质量。例如,我们对电影标题列进行了如下处理:
# 2. 数据预处理
# 确保所需的列名存在
title_column = 'title'
href_column = 'href'
if title_column not in df.columns:
print(f"列名 {title_column} 不存在。")
exit()
df[title_column] = df[title_column].astype(str).str.strip().str.lower()
df[href_column] = df[href_column].astype(str) # 确保 href 列是字符串类型特征提取与模型选择
数据标注工具:
- 描述:在本项目中,数据标注是通过编写Python脚本来完成的,利用Pandas库进行数据的读取、清洗和转换。
- 功能:Pandas提供了丰富的数据操作功能,包括但不限于数据过滤、转换、合并等,非常适合进行数据预处理和标注。
- 使用:通过编写特定的数据处理逻辑,如将电影的年份和评分转换为字符串格式,并将国家、类型等信息合并为一个特征字符串,实现了数据的标注。
标签格式:
- 描述:标签格式是指数据集中用于描述每个电影特征的数据结构和格式。
- 特征字符串:在本项目中,标签格式是通过将电影的多个属性合并为一个特征字符串来实现的。这个特征字符串包括国家、类型、年份和评分。
- 目的:这种标签格式的目的是为了在TF-IDF特征提取过程中,能够将电影的多个属性作为一个整体来考虑,从而更准确地计算电影之间的相似度。
选择使用TF-IDF算法:
-
文本数据的适用性:TF-IDF是一种广泛用于文本数据的算法,它能够量化文本中单词的重要性。在电影推荐系统中,电影的描述、类型、国家和评分等信息可以被视为文本数据。
-
简单性和效率:TF-IDF算法相对简单,易于实现,并且计算效率高。对于推荐系统来说,能够快速处理大量数据并给出推荐结果是很重要的。
-
特征表示的无偏性:TF-IDF通过考虑词频(TF)和逆文档频率(IDF),减少了常见词的影响,提高了稀有词的权重,这有助于捕捉到更能代表电影特性的词汇。
-
无需复杂的模型训练:与基于深度学习的模型相比,TF-IDF不需要大量的训练数据和复杂的训练过程,这在数据量不是特别大的情况下是一个优势。
# 3. 特征提取
# 将'国家', '类型', '年份', 和 '评分' 合并为一个特征字符串
df['features'] = df['country'] + ' ' + df['film_type'] + ' ' + df['year'].astype(str) + ' ' + df['fraction'].astype(str)
# 使用TF-IDF算法提取文本特征
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(df['features'])
cosine_similarity 的作用:
-
相似度度量:
cosine_similarity是一个用于计算两个非零向量之间夹角余弦值的函数,它可以用来衡量向量之间的相似度。在文本分析中,它常用于比较文档或句子的相似性。 -
特征空间映射:在TF-IDF向量化之后,文本数据被转换为数值型特征向量。
cosine_similarity计算这些向量之间的相似度,从而在特征空间中映射出文档之间的关系。 -
推荐系统核心:在推荐系统中,
cosine_similarity用于找出与用户输入或喜好相似的其他项,从而提供个性化推荐。
通过计算TF-IDF特征向量之间的余弦相似度,我们能够找出与用户喜欢的电影最相似的其他电影。
# 计算电影之间的相似度矩阵
cosine_sim = cosine_similarity(tfidf_matrix)推荐函数实现
我们定义了一个recommend_movies函数,该函数接受用户输入的电影名称,并返回相似度最高的前10部电影作为推荐。以下是函数的基本逻辑:
#5.推荐函数
def recommend_movies(df, cosine_sim, title_column, user_input):
# 清除用户输入的电影名称两边的空白字符,转换为小写
user_input_processed = user_input.strip().lower()
# 找到用户喜欢的电影的索引
mask = df[title_column].str.lower() == user_input_processed
if mask.sum() != 1:
print(f"数据库中没有找到电影: '{user_input}'. 请确保输入正确。")
return pd.DataFrame()
idx = df[mask].index[0]
# 获取相似度分数
sim_scores = sorted(range(len(cosine_sim[idx])), key=lambda i: cosine_sim[idx][i], reverse=True)
# 排除用户已经看过的那部电影本身
sim_scores = sim_scores[1:]
# 返回相似度最高的前10部电影(如果存在)
top10_indices = sim_scores[:10]
recommendations = df.iloc[top10_indices]
return recommendationsFlask Web应用
我们使用Flask框架创建了一个简单的Web应用,用户可以通过网页提交他们喜欢的电影名称,并获取推荐结果。
前端页面设计
前端页面是用户与我们的推荐系统交互的接口。我们设计了一个简单直观的界面,使用户能够轻松地获取电影推荐。
页面布局
我们的前端页面布局简洁明了,主要由以下几个部分组成:
- 标题区域:页面顶部显示推荐系统的名称。
- 搜索框:用户可以输入他们喜欢的电影名称。
- 提交按钮:用户输入电影名称后,点击此按钮提交请求。
- 推荐结果显示区域:显示系统推荐的10部电影列表。
用户交互
用户只需在搜索框中输入电影名称并点击提交按钮,系统就会返回推荐的10部电影。结果将以列表的形式展示,包括每部电影的名称、评分、简介和链接。
前端技术栈
我们使用了以下前端技术来构建用户界面:
- HTML:用于构建页面的结构
- JavaScript:实现复杂的用户交互
以下是html代码:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>电影推荐系统</title>
<style>
body { font-family: Arial, sans-serif; }
#recommendationsResult ul { list-style-type: none; padding: 0; }
#recommendationsResult li { margin: 5px 0; }
</style>
</head>
<body>
<h1>请输入您看过并喜欢的电影名称来获取推荐:</h1>
<input type="text" id="movieInput" placeholder="电影名称">
<button id="recommendButton">获取推荐</button>
<div id="recommendationsResult"></div>
// JavaScript代码,用于处理用户点击事件并调用后端API
<script>
document.getElementById('recommendButton').addEventListener('click', function() {
var userInput = document.getElementById('movieInput').value.trim();
if (userInput) {
fetch('/recommendations', {
method: 'POST',
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({ title: userInput })
})
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.json();
})
.then(data => {
if (data.error) {
document.getElementById('recommendationsResult').innerText = data.error;
} else {
var resultList = document.getElementById('recommendationsResult');
resultList.innerHTML = '<ul>'; // 开始列表
data.forEach(function(movie) {
// 假设返回的数据中包含 href 字段
resultList.innerHTML += '<li><a href="' + movie.href + '" target="_blank">' + movie.title + ' - 分数: ' + movie.fraction + '</a></li>'; // 列表项
});
resultList.innerHTML += '</ul>'; // 结束列表
}
})
.catch(error => {
console.error('Error:', error);
document.getElementById('recommendationsResult').innerText = '没有该电影或者找不到推荐的给你';
});
} else {
alert('请输入电影名称');
}
});
</script>
</body>
</html>为什么选择Flask:
-
轻量级:Flask是一个轻量级的Web框架,它易于上手和使用,特别适合小型项目和快速开发。
-
灵活性:Flask提供了足够的灵活性,允许开发者根据自己的需求添加所需的功能,而不是强迫使用一套固定的模式。
-
简洁性:Flask的API设计简洁直观,使得代码易于编写和维护。
-
社区支持:Flask拥有一个活跃的社区,提供了大量的扩展和插件,可以轻松地扩展Web应用的功能。
-
部署简单:Flask应用的部署相对简单,可以很容易地在多种环境中运行。
-
适合原型开发:由于其轻量级和灵活性,Flask非常适合快速开发原型和概念验证。
代码实现过程:
1.在终端输入flask run
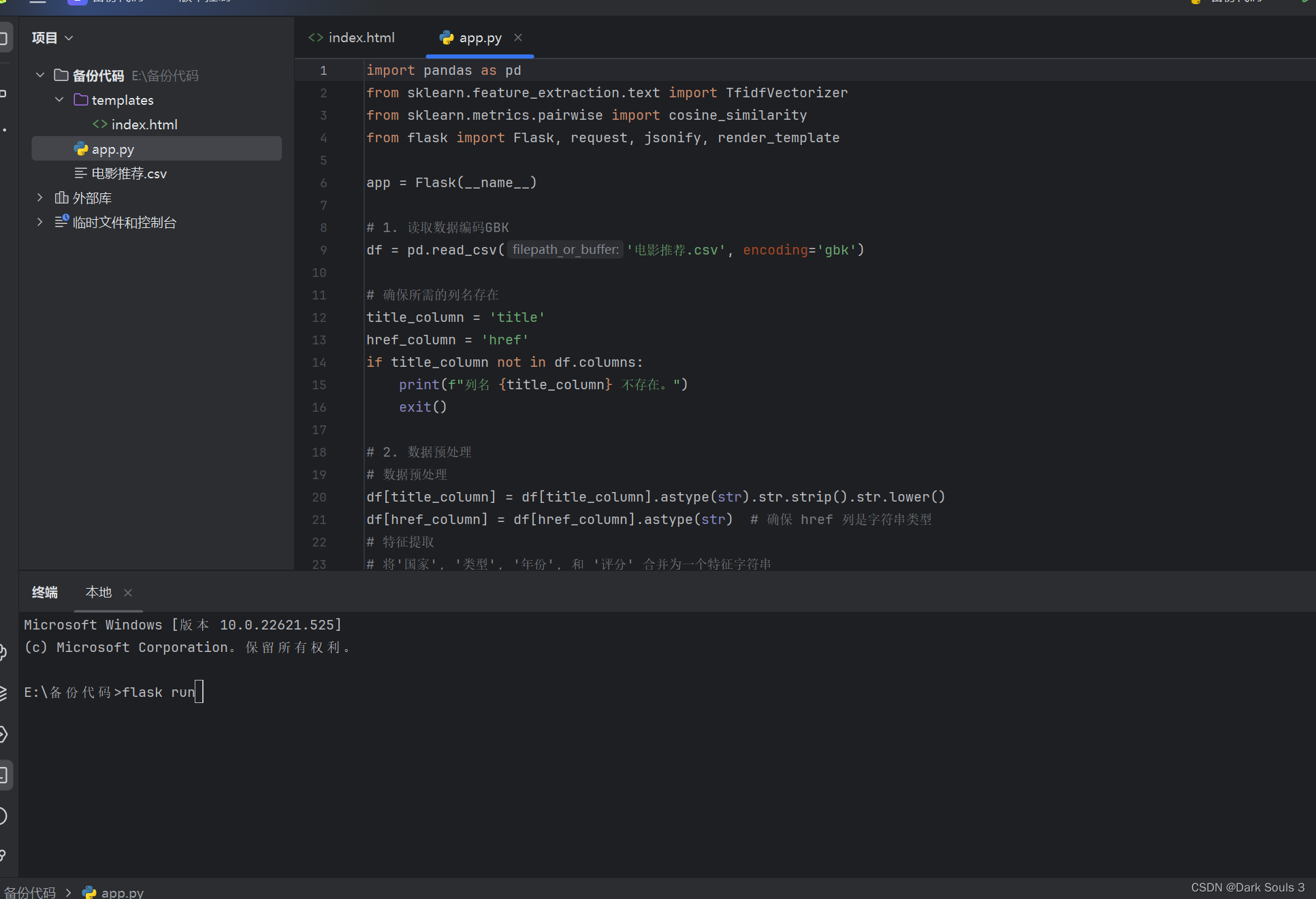
2.终端显示:
3.点击链接跳转到页面:
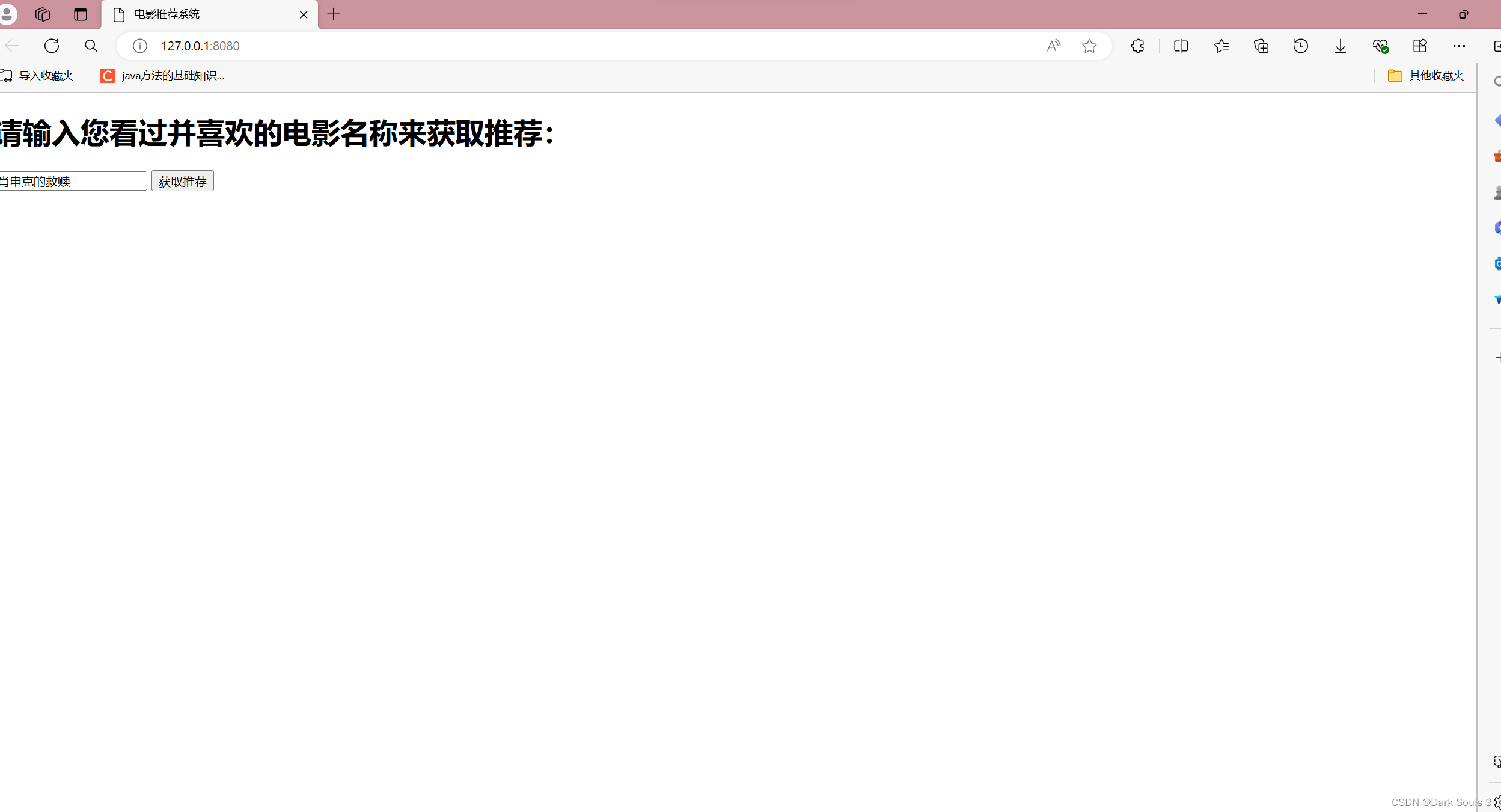
4.点击获取推荐:
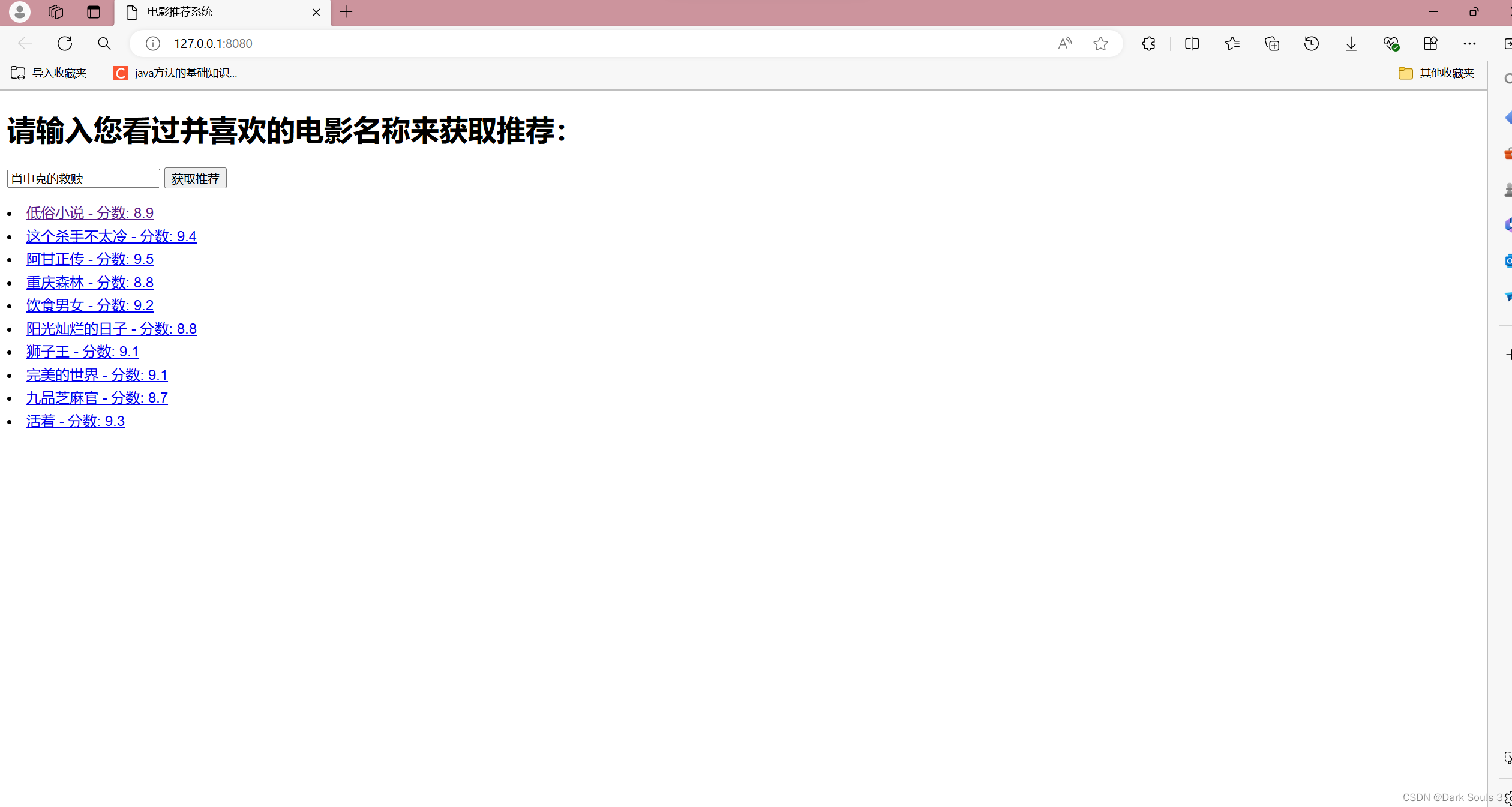
5.点击任意一部电影会跳转到相应的电影详细页面:
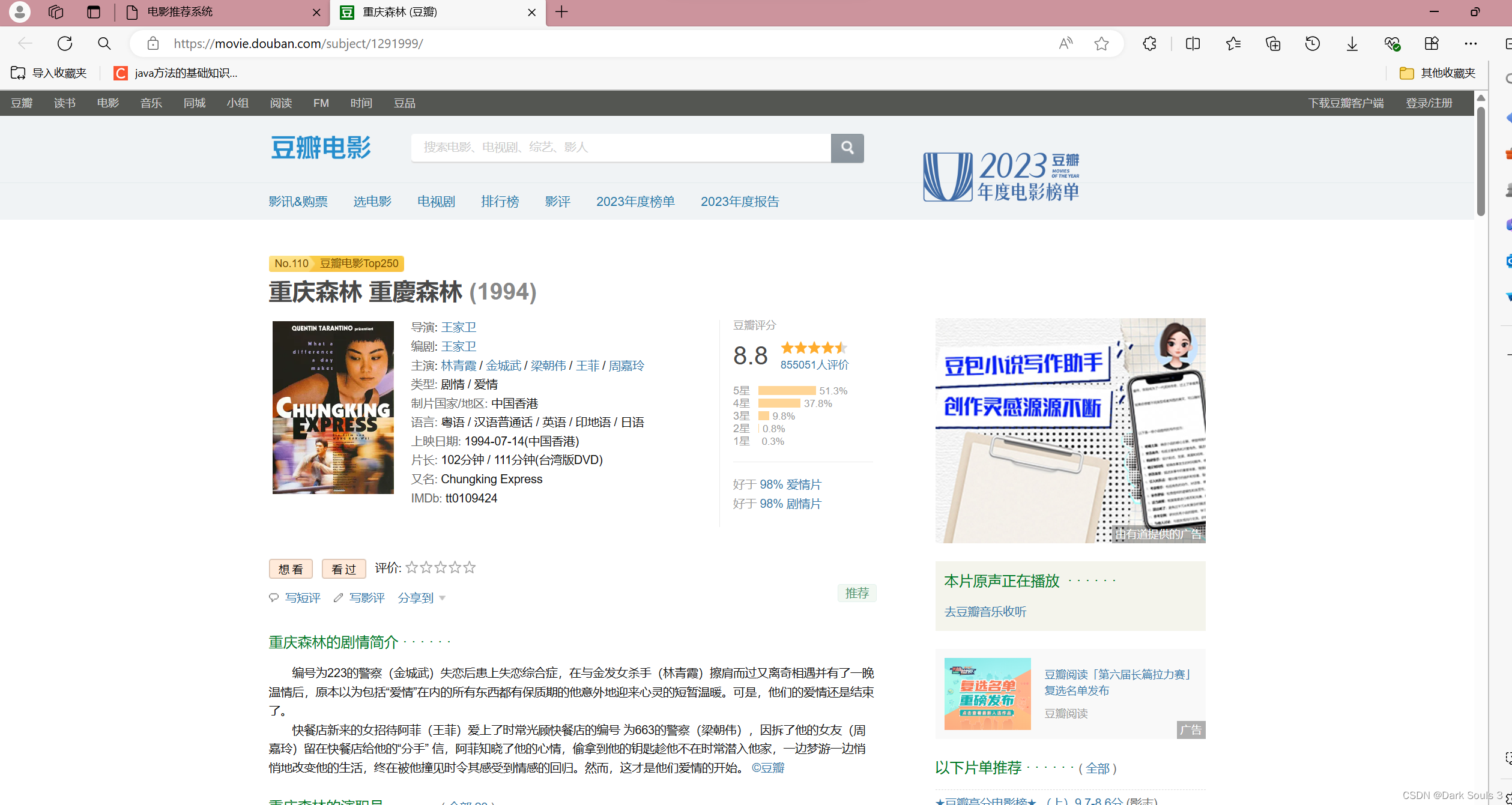
总结与展望
通过本文的介绍,我们展示了如何从零开始构建一个基于Flask和机器学习的电影推荐系统。从数据的抓取、预处理到特征提取,再到模型的实现和Web应用的部署,每一步都是推荐系统开发过程中不可或缺的部分。
在未来的工作中,我们计划引入更复杂的推荐算法,如协同过滤或深度学习模型,以提高推荐的准确性和个性化程度。同时,我们也将探索如何利用用户反馈来优化推荐结果。















 1445
1445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









