






论文:BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
论文地址:https://arxiv.org/pdf/1810.04805
项目地址:GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
文本简要介绍一下BERT这个广受追捧的NLP领域模型的基本原理
PyTorch框架的BERT模型简要实现请看文章:
一、摘要:
BERT模型是Google推出的一个自监督双向预训练模型,所谓自监督指的是它训练时通过从输入数据本身生成伪标签来训练模型,而不需要人工标注的数据。双向则是它与GPT等模型相比的一个显著特点,即它可以从左到右和从右到左的理解文本信息,充分考虑了上下文信息,可以更加准确地捕捉词义的变化。
BERT基于Transformer模型,它由多个编码器(Encoder)层组成。在每个编码器层中,每个token都会接收到来自句子中所有其他token的信息。而且BERT是一个预训练模型,在下游任务的微调时,只需要加入一个额外的输出层就可以实现不同的任务。
BERT在概念上简单,在实证上强大。它在十一个自然语言处理任务上取得了新的最高成绩,包括将GLUE分数提高到80.5%(绝对提高了7.7个百分点),MultiNLI准确度提高到86.7%(绝对提高了4.6个百分点),SQuAD v1.1问答测试F1提高到93.2(绝对提高了1.5个百分点),SQuAD v2.0测试F1提高到83.1(绝对提高了5.1个百分点)。
二、BERT模型详解:
1、NLP两种任务:
(1)句子级任务:如自然语言推理和释义等,旨在通过整体分析来预测句子之间的关系。
(2)标记级任务:例如命名实体识别和问答,其中需要模型在标记级产生细粒度输出。
2、预训练模型的两种使用策略:
(1)基于特征:如ELMo,使用特定于任务的架构,其中包括作为附加特征的预训练表示。
(2)微调方法,如生成预训练变换器(OpenAI GPT),引入了最小的任务特定参数,并通过简单地微调所有预训练参数来对下游任务进行训练。
二者的预训练期间具有相同的目标函数。
3、单向策略的局限性:
标准语言模型的单向性限制了在预训练期间可以使用的架构的选择。例如,在OpenAI GPT中,作者使用左-右架构,其中每个token只能处理Transformer自我关注层中的先前token。这种限制对于句子级任务来说是次优的,当将基于微调的方法应用于问答等令牌级任务时,可能会非常有害,因为在这些任务中,从两个方向结合上下文至关重要。
4、BERT采用的训练方法:
4.1、第一个任务是掩码预测MLM:
BERT不使用传统的从左到右或从右到左的语言模型来预训练BERT,而是使用掩码预测任务,可以融合上下文信息,训练一个双向Transformer模型。
具体使用方法:
为了训练深度双向表示,需要屏蔽一定比例的输入词语,然后预测这些被屏蔽的词语(将词语替换为【MASK】),这个比例控制在15%。但是由于在预训练时将15%的词语替换为【MASK】,但是在微调时是没有【MASK】的,因此,如果直接这样预训练,会导致预训练与微调不匹配,所以,需要修改:对于第i个词语,有80%概率替换为【MASK】,10%概率换为随机标记,10%概率不变。这样做的好处是:(1)模型对上下文的理解:如果所有被遮蔽的单词都被替换为【MASK】标记,模型可能会过度关注【MASK】标记而忽略上下文信息。通过保持一部分单词不变或替换为随机单词,模型被迫关注上下文信息来预测原始单词,从而提高了模型提取语义关系的能力。(2)训练数据的多样性:通过随机替换一部分被遮蔽的单词为词汇表中的任意单词,BERT模型学会了在不同情况下预测单词,这增加了训练数据的多样性,并使模型更加健壮。(3)使得模型“明白”输入数据中包含真实的单词:通过在15%的被遮蔽单词中保持10%的单词不变,模型可以学习到输入数据中包含真实的单词,这有助于缓解预训练阶段有【MASK】标记而下游任务没有【MASK】标记的不一致问题。(4)4.模型的泛化能力:这种策略迫使模型不仅要在【MASK】位置上工作,还要时刻准备处理随机替换的情况,即检查句子的正确性,这提高了模型提取语义效果的能力。
4.2、第二个任务是句子对是否是相邻语句的判断任务NSP:
该任务是为了理解句子之间的关系,捕捉句子间的语义联系,单个任务中融合了主题预测和连贯性预测。
具体使用方法:
在选择每个预训练样本的句子A和B时,有50%的时间B是实际跟随A的下一句(标记为IsNext),而另外50%的时间它是一个从语料库中随机选择的句子(标记为NotNext)
5、BERT模型架构:
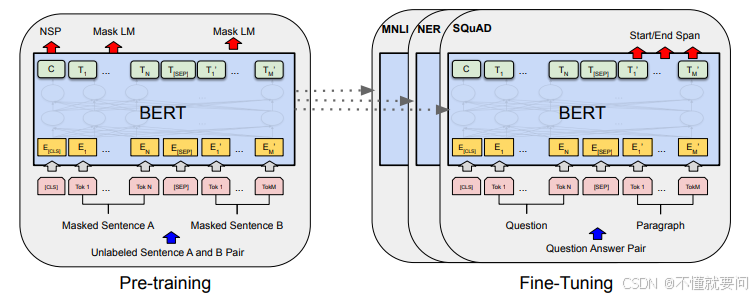
BERT模型的输入可以是一个句子,也可以是两个句子组成的句子对。对于输入,要做一定的处理:首先,要在句子的最前面加入【CLS】标识作为对整个输入句子对的完整信息概括(Why?因为Transformer的注意力机制),在第一个句子的结束位置,需要加上【SEP】作为间隔符,然后跟第二个句子,在第二个句子的结尾部分同样需要加上【SEP】作为结束符。为了标识不同的句子,BERT引入了token_type_ids来对句子进行区分,token_type_ids与inputs_ids形状一致,在对应的位置上,第一个句子的每一个token对应的token_type_ids为0,第二个句子的每一个token对应的token_type_ids为1。
BERT模型的主要结构是很多个Transformer架构的Encoder,这一部分已经有很多文章介绍了,只要学会了基础的Transformer结构,BERT的实现就不难理解。在我之前的文章有介绍Trasnformer架构的理解与实现:
Transformer简单编码实现_transformer decoder layers-CSDN博客
最后他会输入【CLS】标识对应的token的隐藏层表示,在下游任务中可以使用有监督数据训练一个输出层即可。
6、BERT的嵌入处理:
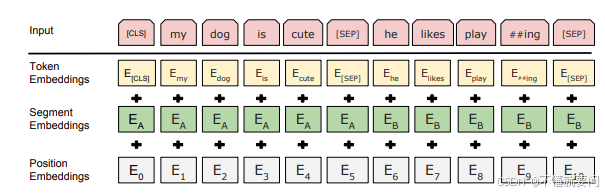
BERT的输入嵌入有三部分构成:词嵌入、段落嵌入和位置嵌入,和普通的Transformer不同的是加了一个段落嵌入,这个嵌入的作用是标识不同的句子,也就是要使用token_type_ids,具体实现为:
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
位置嵌入还是采用一维绝对位置编码:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.dropout(x + self.pe[:, :x.size(1)].detach())词嵌入和普通Transformer架构的实现一模一样。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









