









MindSpore入门–跑通DeepFM模型
A Practice of MindSpore – DeepFM
MindSpore入门–跑通DeepFM模型
本文开发环境如下
- ModelArts
- Notebook
- Ascend*8
本文主要内容如下
- 环境准备
- 数据准备
- 模型训练
- 发布算法
1. 环境准备
注意事项:
- 本次笔者基于Ascend进行8卡运行,并且配置了500G的云硬盘。8卡主要作用是防止内存溢出,导致预处理时进程被Killed
1.1 克隆仓库并进入到本地deepfm目录
git clone https://gitee.com/mindspore/models.git mindspore_models
cd mindspore_models/official/recommend/deepfm
可以使用find . -print|sed -e 's;[^/]*/;|--;g;s;--|; |;g'查看deepfm目录结构,目录结构如下所示。
.
|--Dockerfile
|--README.md
|--README_CN.md
|--ascend310_infer
| |--CMakeLists.txt
| |--build.sh
| |--inc
| | |--utils.h
| |--src
| | |--main.cc
| | |--utils.cc
|--default_config.yaml
|--eval.py
|--export.py
|--infer
| |--Dockerfile
| |--convert
| | |--convert_om.sh
| |--data
| | |--config
| | | |--deepfm_ms.pipeline
| |--docker_start_infer.sh
| |--mindrecord2bin.py
| |--mxbase
| | |--MxBaseInfer.h
| | |--MxDeepFmPostProcessor.h
| | |--build.sh
| | |--eval.py
| | |--infer.sh
| | |--main.cpp
| |--requirements.txt
| |--sdk
| | |--sample
| | | |--build.sh
| | | |--eval.py
| | | |--main.cpp
|--mindspore_hub_conf.py
|--modelart
| |--start.py
|--postprocess.py
|--preprocess.py
|--requirements.txt
|--scripts
| |--docker_start.sh
| |--run_distribute_train.sh
| |--run_distribute_train_gpu.sh
| |--run_eval.sh
| |--run_infer_310.sh
| |--run_standalone_train.sh
|--src
| |--__init__.py
| |--callback.py
| |--dataset.py
| |--deepfm.py
| |--model_utils
| | |--__init__.py
| | |--config.py
| | |--device_adapter.py
| | |--local_adapter.py
| | |--moxing_adapter.py
| |--preprocess_data.py
|--train.py
1.2 准备开发环境
pip3 install -r requirements.txt
2.数据准备
2.1 下载数据集
数据集下载地址Criteo Kaggle Display Advertising Challenge Dataset
- http://go.criteo.net/criteo-research-kaggle-display-advertising-challenge-dataset.tar.gz
注意事项
- 如果使用wget下载速度慢,可以使用迅雷等下载工具下载完成后再上传到服务器。
2.1.1 创建原始数据保存目录,并下载数据集
mkdir origin_data && cd origin_data
wget http://go.criteo.net/criteo-research-kaggle-display-advertising-challenge-dataset.tar.gz
2.1.2 检测数据集MD5(可跳过)
md5sum kaggle-display-advertising-challenge-dataset.tar.gz
会输出如下内容
df9b1b3766d9ff91d5ca3eb3d23bed27 kaggle-display-advertising-challenge-dataset.tar.gz
2.1.3 解压数据集
tar -zxvf kaggle-display-advertising-challenge-dataset.tar.gz
2.1.4 查看数据集目录结构
find . -print|sed -e 's;[^/]*/;|--;g;s;--|; |;g'
会输出如下内容
. |--readme.txt |--test.txt |--train.txt
2.1.5 数据预处理-转换为MindRecord
数据预处理
cd ../src
python -m preprocess_data --data_path=../ --dense_dim=13 --slot_dim=26 --threshold=100 --train_line_count=45840617 --skip_id_convert=0
会输出如下内容
{'enable_modelarts': 'Whether training on modelarts, default: False', 'data_url': 'Dataset url for obs', 'train_url': 'Training output url for obs', 'data_path': 'Dataset path for local', 'output_path': 'Training output path for local', 'device_target': 'device target, support Ascend, GPU and CPU.', 'dataset_path': 'Dataset path', 'batch_size': 'batch size', 'ckpt_path': 'Checkpoint path', 'eval_file_name': 'Auc log file path. Default: "./auc.log"', 'loss_file_name': 'Loss log file path. Default: "./loss.log"', 'do_eval': 'Do evaluation or not, only support "True" or "False". Default: "True"', 'checkpoint_path': 'Checkpoint file path', 'device_id': 'Device id', 'ckpt_file': 'Checkpoint file path.', 'file_name': 'output file name.', 'file_format': 'file format', 'result_path': 'Result path', 'label_path': 'label path', 'dense_dim': 'The number of your continues fields', 'slot_dim': 'The number of your sparse fields, it can also be called catelogy features.', 'threshold': 'Word frequency below this will be regarded as OOV. It aims to reduce the vocab size', 'train_line_count': 'The number of examples in your dataset', 'skip_id_convert': 'Skip the id convert, regarding the original id as the final id.'} {'batch_size': 16000, 'checkpoint_path': '/cache/train/deepfm-5_2582.ckpt', 'checkpoint_url': '', 'ckpt_file': '/cache/train/deepfm-5_2582.ckpt', 'ckpt_file_name_prefix': 'deepfm', 'ckpt_path': '/cache/train', 'config_path': '/home/ma-user/work/DeepFM-kewei/mindspore_models/official/recommend/deepfm/src/model_utils/../../default_config.yaml', 'convert_dtype': True, 'data_emb_dim': 80, 'data_field_size': 39, 'data_format': 1, 'data_path': '../', 'data_url': '', 'data_vocab_size': 184965, 'dataset_path': '/cache/data', 'deep_layer_args': [[1024, 512, 256, 128], 'relu'], 'dense_dim': 13, 'device_id': 0, 'device_target': 'Ascend', 'do_eval': 'True', 'enable_modelarts': False, 'enable_profiling': False, 'epsilon': 5e-08, 'eval_callback': True, 'eval_file_name': './auc.log', 'file_format': 'AIR', 'file_name': 'deepfm', 'init_args': [-0.01, 0.01], 'keep_checkpoint_max': 50, 'keep_prob': 0.9, 'l2_coef': 8e-05, 'label_path': '', 'learning_rate': 0.0005, 'load_path': '/cache/checkpoint_path', 'loss_callback': True, 'loss_file_name': './loss.log', 'loss_scale': 1024.0, 'output_path': '/cache/train', 'result_path': './preprocess_Result', 'save_checkpoint': True, 'save_checkpoint_steps': 1, 'skip_id_convert': 0, 'slot_dim': 26, 'test_num_of_parts': 3, 'threshold': 100, 'train_epochs': 5, 'train_line_count': 45840617, 'train_num_of_parts': 21, 'train_url': '', 'weight_bias_init': ['normal', 'normal']} Please check the above information for the configurations
2.2.1 开始训练
python train.py \
--dataset_path='train' \
--ckpt_path='./checkpoint' \
--eval_file_name='auc.log' \
--loss_file_name='loss.log' \
--device_target=Ascend \
--do_eval=True > ms_log/output.log 2>&1 &
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hb2BCiNx-1644501708766)(C:%5CUsers%5C25122%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220206210219019.png)]
模型评估
python eval.py \
--dataset_path='train' \
--checkpoint_path='./checkpoint/deepfm-5_2582.ckpt' \
--device_target=Ascend > ms_log/eval_output.log 2>&1 &
OR
bash scripts/run_eval.sh 0 Ascend /dataset_path /checkpoint_path/deepfm.ckpt
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SRtB7qrq-1644501708767)(C:%5CUsers%5C25122%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220206210320733.png)]
导出MindIR
python export.py --ckpt_file ./checkpoint/deepfm-5_2582.ckpt --file_name deepfm_kewei --file_format MINDIR
cd scripts
bash run_infer_310.sh ../mindir ../train n 0
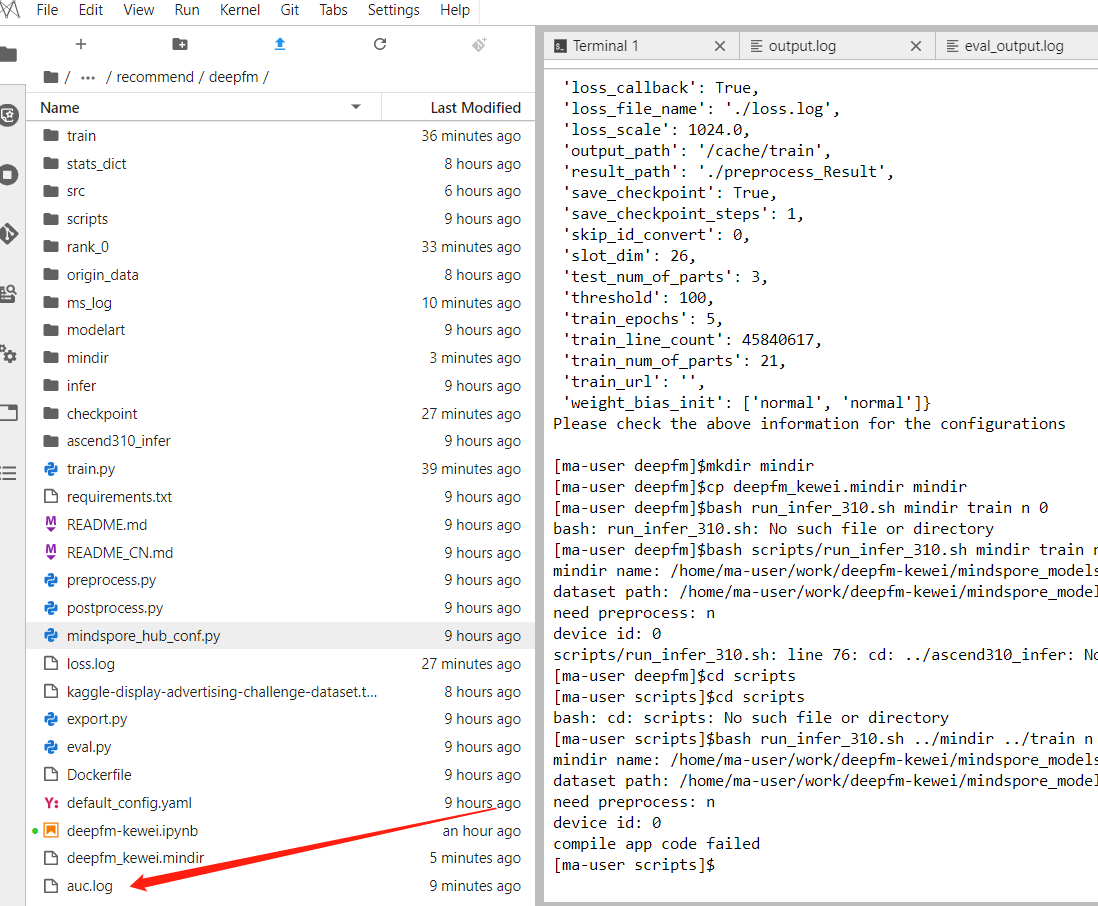
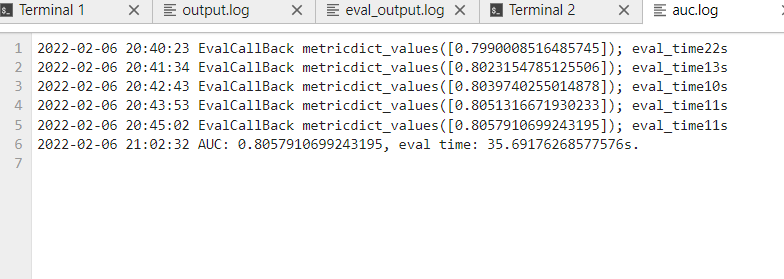
模型在notebook调通之后,我们就可以在modelarts部署deepfm的算法了。
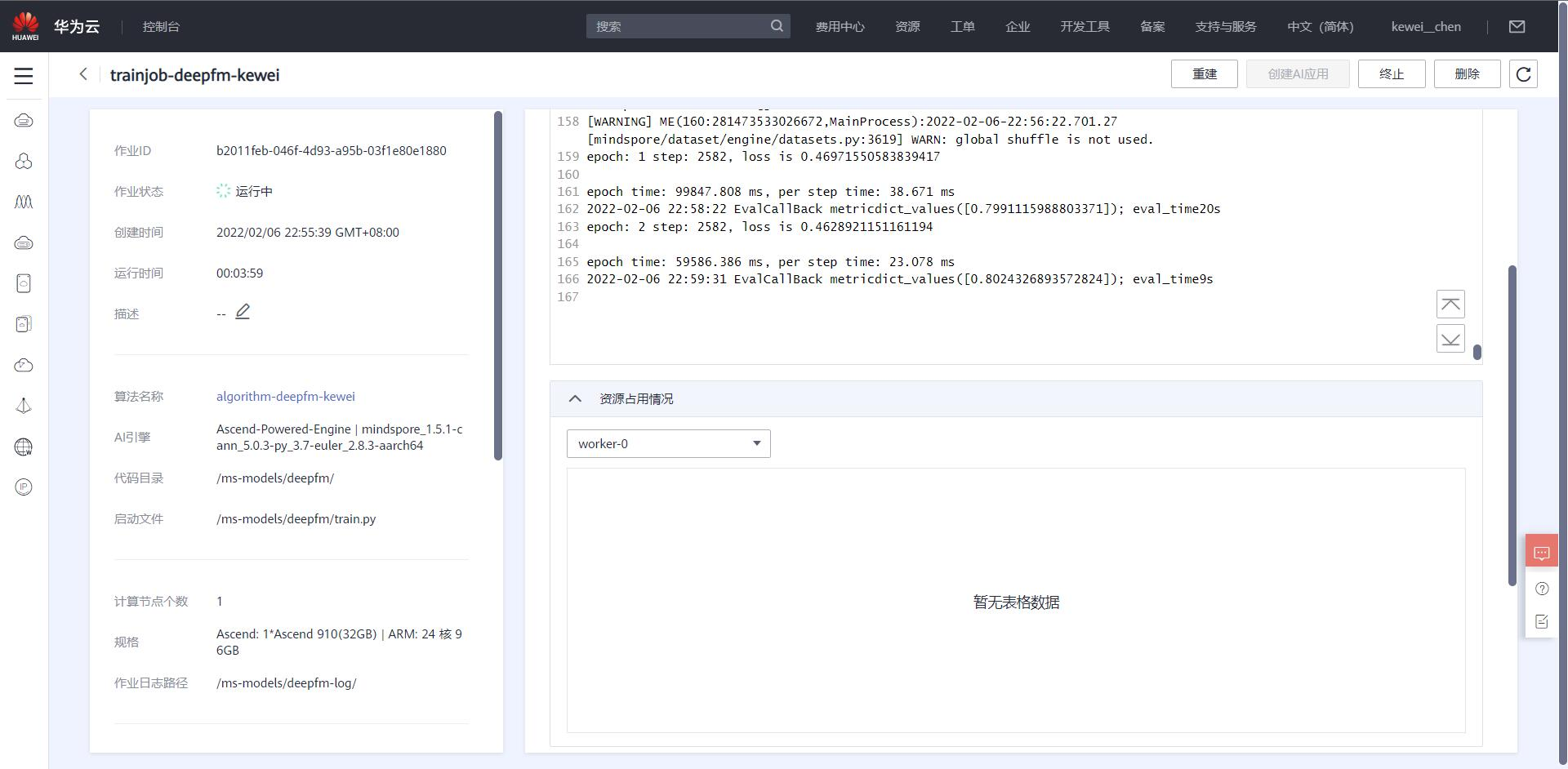
3。发布算法
我已将算法发布到AI Gallery,供大家训练使用。

















 1191
1191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











