






目录
一、决策树的创建
1.决策树概念
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由
结点
和
有向边
组成。结点有两种类型:
内部结点
和
叶节点
。内部结点表示一个特征或属性,叶节点表示一个类。

2.决策树的基本流程

3.决策树的目的
决策树学习的目的是为了产生一棵
泛化能力强
,
即
处理未见示例能力强的决策树
二、使用决策树进行分类
1.划分选择
决策树学习的关键在于
如何选择最优划分属性
。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本
尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
经典的属性划分方法:
–信息增益: ID 3
–增益率:C 4.5
–基尼指数:CART
2.信息增益
离散属性
a
有
V
个可能的取值
{
a
1
,
a
2
, ...,
a
V
}
,用
a
来进行划分,则会产生V
个分支结点,其中第
v
个分支结点包含了
D
中所有在属性
a
上取值为
a
v
的样本,记为
D
v
。则可计算出用属性
a
对样本集
D
进行划分所获得的“信息增益” :

一般而言,
信息增益越大
,则意味着使用属性
a
来进行划分所获得的“
纯度提升
”越大。
实现代码:
def chooseBestFeatureToSplit(dataSet):
#特征数量,-1是因为最后一列是类别标签
numFeatures = len(dataSet[0]) - 1
#计算数据集的原始香农熵
baseEntropy = calcShannonEnt1(dataSet)
bestInfoGain = 0.0 #信息增益赋初值0
bestFeature = -1 #最优特征的索引值
for i in range(numFeatures):
#获取dataSet的第i个所有特征存到featList中
featList = [example[i] for example in dataSet]
#print(featList) #每个特征的15项特征值列表
#创建set集合{},元素不可重复
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
#subDataSet划分后的子集
subDataSet = splitDataSet(dataSet,i,value)
#计算子集的概率=子集个数/整个训练样本数
prob = len(subDataSet)/float(len(dataSet))
#计算香农熵
newEntropy += prob * calcShannonEnt(subDataSet)
#计算信息增益
infoGain = baseEntropy - newEntropy
#print("第%d个特征的增益为%.3f" %(i,infoGain))
#C4.5算法:计算增益比(信息增益率)
#infoGain2 = (baseEntropy - newEntropy)/baseEntropy
if (infoGain >bestInfoGain):
bestInfoGain = infoGain #更新信息增益,找到最大的信息增益
bestFeature = i #记录信息增益最大的特征的索引值
return bestFeature #返回信息增益最大的特征的索引值3.增益率
可定义增益率:

其中

称为属性
a
的“固有值”
[Quinlan, 1993]
,
属性
a
的可能取值数目越多(即V
越大),则
IV(
a
)
的值通常就越大。
实现代码:
def calcShannonEnt1(dataSet, method = 'none'):
numEntries = len(dataSet)
labelCount = {}
for feature in dataSet:
if method =='prob': #当参数为prob时转而计算增益率
label = feature
else:
label = feature[-1]
if label not in labelCount.keys():
labelCount[label]=1
else:
labelCount[label]+=1
shannonEnt = 0.0
for key in labelCount:
numLabels = labelCount[key]
prob = numLabels/numEntries
shannonEnt -= prob*(log(prob,2))
return shannonEnt
#增益率
def chooseBestFeatureToSplit2(dataSet): #使用增益率进行划分数据集
numFeatures = len(dataSet[0]) -1 #最后一个位置的特征不算
baseEntropy = calcShannonEnt(dataSet) #计算数据集的总信息熵
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
newEntropyProb = calcShannonEnt1(featList, method='prob') #计算内部增益率
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 通过不同的特征值划分数据子集
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcGini(subDataSet)
newEntropy = newEntropy*newEntropyProb
infoGain = baseEntropy - newEntropy #计算每个信息值的信息增益
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature #返回信息增益的最佳索引4.基尼指数

在候选属性集合
A
中,选择那个使得
划分后
基尼指数最小的属性作为最有划分属性。
实现代码:
#基尼指数
def calcGini(dataset):
feature = [example[-1] for example in dataset]
uniqueFeat = set(feature)
sumProb =0.0
for feat in uniqueFeat:
prob = feature.count(feat)/len(uniqueFeat)
sumProb += prob*prob
sumProb = 1-sumProb
return sumProb
def chooseBestFeatureToSplit3(dataSet): #使用基尼系数进行划分数据集
numFeatures = len(dataSet[0]) -1 #最后一个位置的特征不算
bestInfoGain = np.Inf
bestFeature = 0.0
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 通过不同的特征值划分数据子集
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcGini(subDataSet)
infoGain = newEntropy
if(infoGain < bestInfoGain): # 选择最小的基尼系数作为划分依据
bestInfoGain = infoGain
bestFeature = i
return bestFeature #返回决策属性的最佳索引三、代码实现
1.明确函数功能,定义函数
2.寻找递归结束条件(也就是边界条件,基线条件)
需要找出当参数为啥时,递归结束,之后直接把结果返回
3.找出函数的等价关系式(最重要的一步)
我们要不断缩小参数的范围,缩小之后,我们可以通过一些辅助的变量或者操作,使原函数的结果不变。
#利用决策树算法,对mnist数据集进行测试
import numpy as np
#计算熵
def calcEntropy(dataSet):
mD = len(dataSet)
dataLabelList = [x[-1] for x in dataSet]
dataLabelSet = set(dataLabelList)
ent = 0
for label in dataLabelSet:
mDv = dataLabelList.count(label)
prop = float(mDv) / mD
ent = ent - prop * np.math.log(prop, 2)
return ent
# # 拆分数据集
# # index - 要拆分的特征的下标
# # feature - 要拆分的特征
# # 返回值 - dataSet中index所在特征为feature,且去掉index一列的集合
def splitDataSet(dataSet, index, feature):
splitedDataSet = []
mD = len(dataSet)
for data in dataSet:
if(data[index] == feature):
sliceTmp = data[:index]
sliceTmp.extend(data[index + 1:])
splitedDataSet.append(sliceTmp)
return splitedDataSet
#根据信息增益 - 选择最好的特征
# 返回值 - 最好的特征的下标
def chooseBestFeature(dataSet):
entD = calcEntropy(dataSet)
mD = len(dataSet)
featureNumber = len(dataSet[0]) - 1
maxGain = -100
maxIndex = -1
for i in range(featureNumber):
entDCopy = entD
featureI = [x[i] for x in dataSet]
featureSet = set(featureI)
for feature in featureSet:
splitedDataSet = splitDataSet(dataSet, i, feature) # 拆分数据集
mDv = len(splitedDataSet)
entDCopy = entDCopy - float(mDv) / mD * calcEntropy(splitedDataSet)
if(maxIndex == -1):
maxGain = entDCopy
maxIndex = i
elif(maxGain < entDCopy):
maxGain = entDCopy
maxIndex = i
return maxIndex
# 寻找最多的,作为标签
def mainLabel(labelList):
labelRec = labelList[0]
maxLabelCount = -1
labelSet = set(labelList)
for label in labelSet:
if(labelList.count(label) > maxLabelCount):
maxLabelCount = labelList.count(label)
labelRec = label
return labelRec
#生成决策树
# featureNamesSet 是featureNames取值的集合
# labelListParent 是父节点的标签列表
def createFullDecisionTree(dataSet, featureNames, featureNamesSet, labelListParent):
labelList = [x[-1] for x in dataSet]
if(len(dataSet) == 0):
return mainLabel(labelListParent)
elif(len(dataSet[0]) == 1): #没有可划分的属性了
return mainLabel(labelList) #选出最多的label作为该数据集的标签
elif(labelList.count(labelList[0]) == len(labelList)): # 全部都属于同一个Label
return labelList[0]
bestFeatureIndex = chooseBestFeature(dataSet)
bestFeatureName = featureNames.pop(bestFeatureIndex)
myTree = {bestFeatureName: {}}
featureList = featureNamesSet.pop(bestFeatureIndex)
featureSet = set(featureList)
for feature in featureSet:
featureNamesNext = featureNames[:]
featureNamesSetNext = featureNamesSet[:][:]
splitedDataSet = splitDataSet(dataSet, bestFeatureIndex, feature)
myTree[bestFeatureName][feature] = createFullDecisionTree(splitedDataSet, featureNamesNext, featureNamesSetNext, labelList)
return myTree
#读取西瓜数据集2.0
def readWatermelonDataSet():
ifile = open("周志华_西瓜数据集2.txt")
featureName = ifile.readline() #表头
featureNames = (featureName.split(' ')[0]).split(',')
lines = ifile.readlines()
dataSet = []
for line in lines:
tmp = line.split('\n')[0]
tmp = tmp.split(',')
dataSet.append(tmp)
#获取featureNamesSet
featureNamesSet = []
for i in range(len(dataSet[0]) - 1):
col = [x[i] for x in dataSet]
colSet = set(col)
featureNamesSet.append(list(colSet))
return dataSet, featureNames, featureNamesSet
def main():
#读取数据
dataSet, featureNames = readWatermelonDataSet()
print(createDecisionTree(dataSet, featureNames))
if __name__ == "__main__":
main()
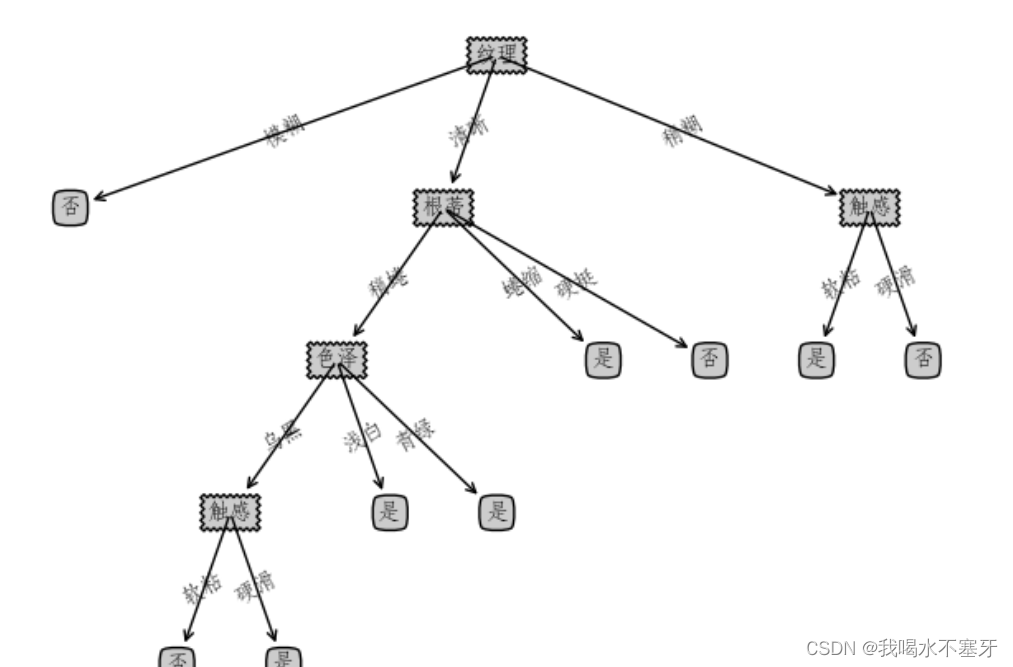
结果输出:














 2056
2056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









