







概述
并查集(Disjoint-set data structure,直译为不交集数据结构)是一种用来管理元素所属集合的数据结构,具体来说并查集是用来处理一系列没有重复元素的集合(不交集的集合)的合并和查询问题,并查集中的每一个集合都是一棵树,每一棵树的根节点是这棵树表示的集合的代表。它并查集支持两种基本的操作:
- 查询
- 合并
我们先不忙进入查询与合并的学习,在进行这两种基本操作之前,需要先进行并查集的初始化操作。
初始化
并查集是通过记录每个元素父节点的方式来判断该元素属于哪个集合,为此需要建立一个数组用来维护元素的父节点,对这个数组的初始化操作就是并查集初始化,通常元素的父节点初始化为其自身。
举个例子:假设有编号 0 , 1 , 2... , n − 1 0,1,2...,n-1 0,1,2...,n−1 这 n n n 个元素,我们需要对这 n n n 个元素建立并查集关系,首先我们就要进行初始化。我们同一个数组 p a [ ] pa[] pa[] 来存储每个元素的父节点,一开始将每个元素的父节点设为自己,C++ 的初始化参考代码如下,下方还有该例子的结构体实现。
vector<int> pa(n); // pa[i] 表示元素 i 的父亲节点
void init(int n) {
for (int i = 0; i < n; ++i) {
pa[i] = i;
}
}
// 并查集的结构体表示
struct dsu{
vector<size_t> pa;
dsu(size_t size_): pa(size_) {
iota(pa.begin(), pa.end(), 0);
};
};
查询
并查集初始化结束后,首先需要实现的就是查询操作,因为查询操作是合并的基础(合并中会再次提到)。查询操作 “查” 的是集合表示的树的根节点,我们使用的是递归的方法沿着树一层层的找父节点,直至找到根节点。查询的实现代码如下。
// 查询代码:
int dsu::find(int x) {
if (x == pa[x]) {
return x;
}
return find(pa[x]);
}
// 三元运算符实现
int dsu::find(int x) {
return x == pa[x] ? x : find(pa[x]);
}
以上的查询代码中,如果待查的节点和其父节点一致,说明该节点元素就是一个集合的全部元素,直接返回;否则递归查询该节点的父节点。
在查询某一个元素的根节点的过程中,如果经过的每一个元素都属于该集合,我们可以将其直接连到根节点上以加快后续的查询,这就是所谓的 压缩路径。并查集的查询操作中多用压缩路径的方法,毕竟可以加快后续的查询速度嘛。压缩路径的查询方法代码如下所示:
int find(int x) {
return x == pa[x] ? x : pa[x] = find(pa[x]);
}
在下图压缩路径图示中,根据左图有 p [ 4 ] = 3 , p a [ 5 ] = 3 , p [ 3 ] = 1 , p a [ 2 ] = 1 , p a [ 1 ] = 1 p[4] = 3, pa[5] = 3, p[3] = 1, pa[2] = 1, pa[1] = 1 p[4]=3,pa[5]=3,p[3]=1,pa[2]=1,pa[1]=1 这样的集合连接关系。我们在查询 4 这个元素的根节点时,通过以上的递归查询代码,我们依次会将元素 3 和 4 连接到根节点上。
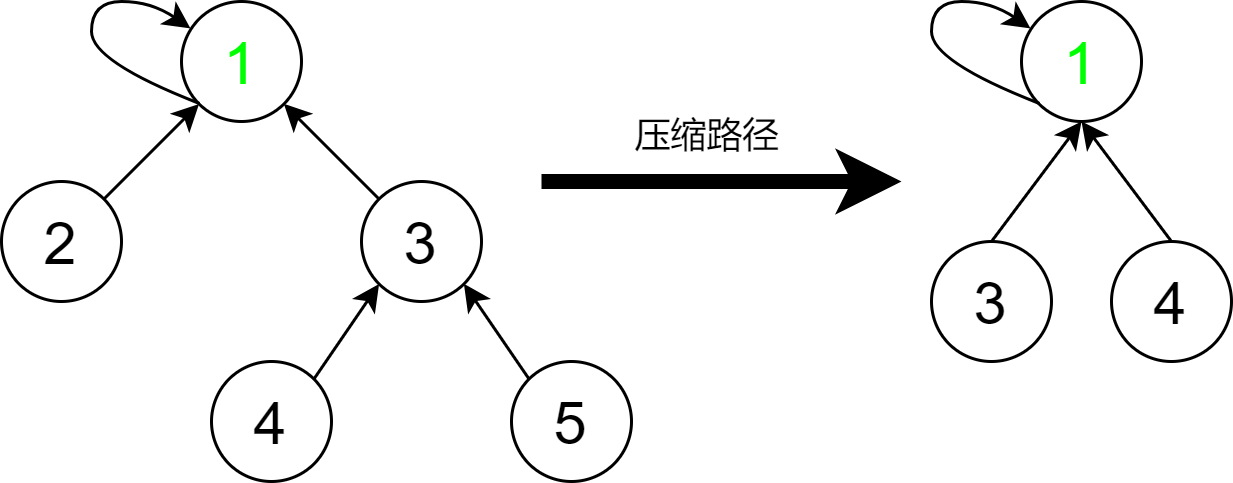
合并
在上面 “压缩路径” 中给出了一张连接好的集合关系图,那么我们是怎么将一个个孤立的点连接起来的呢?当然是合并啦。
合并两棵树(集合)只需要将一棵树的根节点合并到另一棵树的根节点即可。参考代码如下:
void dsu::union(int x, int y) {
pa[find(x)] = find(y);
}
启发式合并
在进行合并时,选择哪棵树的根节点作为合并后的根节点会影响到未来的复杂度。在这里选择将节点较少或深度较小的树连到另一棵树,以免发生退化。图示将集合a合并到集合b会发生退化,若选择将节点较少或深度较小的树连到另一棵树,如 “b合并到a” 所示,则会避免退化的发生。
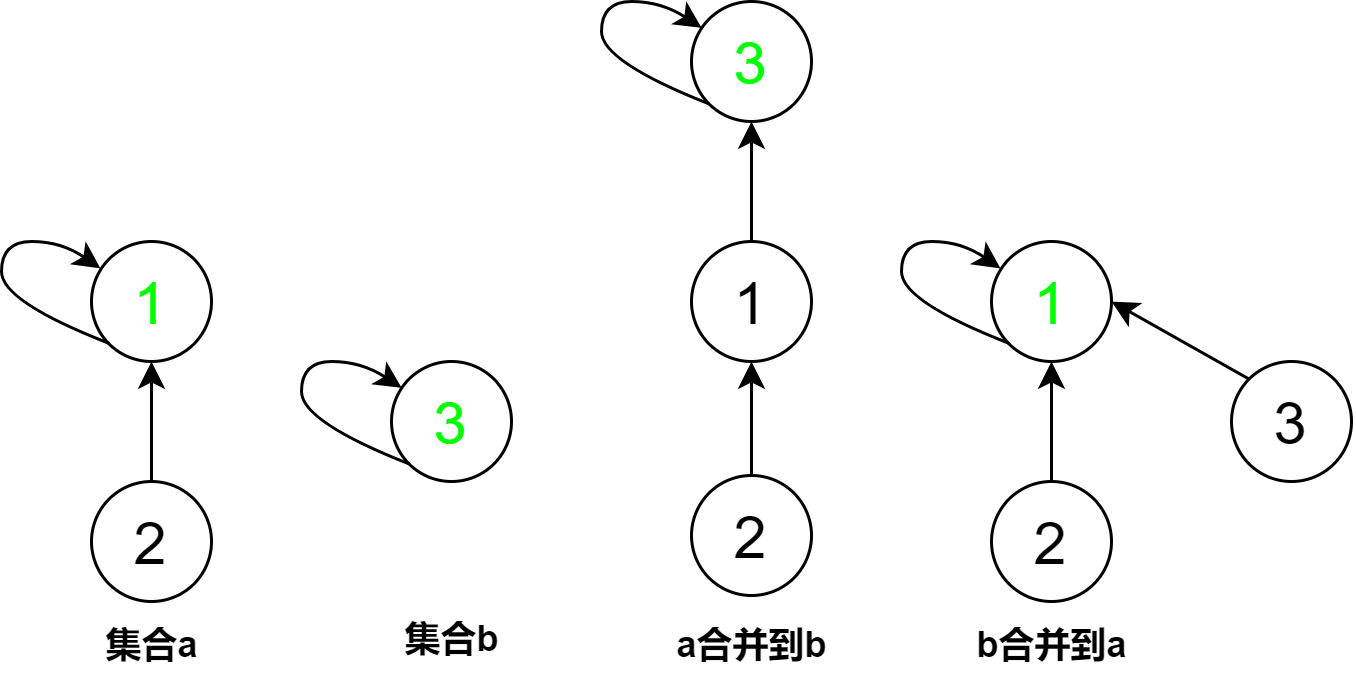
启发式合并方法通常有两种,一种是按照节点数来安排树之间的合并,另一种是按照树的高度来合并。并查集题目选择哪种启发式合并方法还是不用启发式方法要适具体情况而言,好像是废话,当然可以不使用任何启发式合并方法,对时间复杂度有要求的当然要考虑使用了。
节点数启发式合并
节点数启发式合并就是将节点数较小的树或者集合合并到节点数较大的树或集合中,示例代码如下。
struct dsu{
vector<int> pa, nums; // nums[i] 表示以 i 为根节点的节点个数
dsu(int size_): pa(size_), nums(size_, 1) {
iota(pa.begin(), pa.end(), 0);
}
void unite(int x, int y) {
x = find(x), y = find(y);
if (x == y) {
return;
}
// 找到节点数少,将少的合并到节点多的的根节点
if (nums[x] < nums[y]) swap(x, y);
pa[y] = x;
nums[x] += nums[y];
}
};
高度启发式合并
高度启发式合并就是将高度较小的树或者节点集合合并到高度较大的树或集合中,合并图及示例代码如下。

struct dsu{
vector<int> pa, height; // height[i] 表示以 i 为根节点的高度
dsu(int size_): pa(size_), height(size_, 0) {
iota(pa.begin(), pa.end(), 0);
}
void unite(int x, int y) {
x = find(x), y = find(y);
if (x == y) {
return;
}
// 找到高度低的树,将低的合并到高度高的的根节点
if (height[x] < height[y]) swap(x, y);
pa[y] = x;
if (height[x] == height[y]) height[x] += 1;
}
};
并查集模板
以上就是并查集的查询与合并的基础操作,接下来给的是以一个二维数组建立并查集的模板,类似的题目可供取用。
class UnionFind {
private:
vector<int> pa; // 定义父节点数组
vector<int> nums; // 启发式合并需要的数组,这里用的是节点数量数组
public:
// 初始化 以一个int类型的二元数组为例进行初始化
UnionFind(vector<vector<int>>& grid) {
int m = grid.size(), n = grid[0].size();
pa.resize(m*n);
nums.resize(m*n);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
nums[i][j] = 1;
pa[i * n + j] = i * n + j;
}
}
}
int find(int x) {
return pa[x] == x ? x : pa[x] = pa[find(x)];
}
void unite(int x, int y) {
x = find(x), y = find(y);
if (x == y) {
return;
}
// 找到节点数少的树,将少的合并到节点多的的根节点
if (nums[x] < nums[y]) swap(x, y);
pa[y] = x;
nums[x] += nums[y];
}
};
并查集的建立
- 如何抽象出并查集模型?说白了就是给一个题目,如何判断出是否可以使用并查集来解题?
- 并查集初始化后,如何根据题目提供的信息建立元素之间的联系?
- 还有就是不同题目并查集建立的谁和谁的连接呢,就是连接点的找寻问题。
以上三个问题,将在并查集应用一节中 【并查集(下)应用篇】 进行分析。
参考文章
1、并查集
2、算法学习笔记(1) : 并查集















 1206
1206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











